TL;DR: автор собрал коллектор NetFlow/sFlow из GoFlow, Kafka, ClickHouse, Grafana и костыля на Go.
Здравствуйте, я эксплуататор и очень люблю знать, что происходит в инфраструктуре. А ещё я люблю лезть в чужие дела, и в этот раз залез в сеть.
Предположим, у вас есть своё сетевое оборудование и мешок торчащих в интернет монолитов, микросервисов и монолитов микросервисов с их зависимостями в виде баз данных, кэшей и FTP-серверов. И иногда некоторые обитатели этого мешка начинают в сети шалить.
Вот лишь некоторые примеры таких шалостей:
- резервное копирование вне предписанного окна в 40 потоков;
- ошибки конфигурации, посылающие приложение в одном ДЦ в кэш другого ДЦ;
- вопросы приложения в соседней стойке к тому же кэшу “дай мне вот этот полумегабайтный объект из кэша" двести раз в секунду.
SNMP счётчики с портов коммутаторов или ВМ дадут только приблизительно понять, что происходит, а хочется точности и быстроты анализа проблем. На помощь приходят протоколы NetFlow/IPFIX и sFlow, которые генерируют богатую информацию о трафике прямо с сетевого оборудования. Осталось её куда-то сложить и как-то обработать.
Из имеющихся NetFlow коллекторов были рассмотрены следующие:
- flow-tools — не понравился хранением в файлах (долго делать выборки, особенно оперативные в процессе реакции на инцидент) или MySQL (иметь там таблицу в миллиарды строк кажется довольно безрадостной затеей);
- Elasticsearch + Logstash + Kibana — очень ресурсоёмкая связка, до 6 ядер пожилого 2.2 ГГц CPU на приём 5000 потоков (flows) в секунду. Однако, Kibana позволяет натыкать какие угодно фильтры в браузере, что ценно;
- vflow — не понравился выходным форматом (JSON, который без модификации невозможно сложить в тот же Elasticsearch);
- коробочные решения — не понравились либо высокой ценой, либо малым отличием от выбранного.
А выбрано было описанное в презентации Louis Poinsignon на RIPE 75. Общая схема простого коллектора получилась такая:
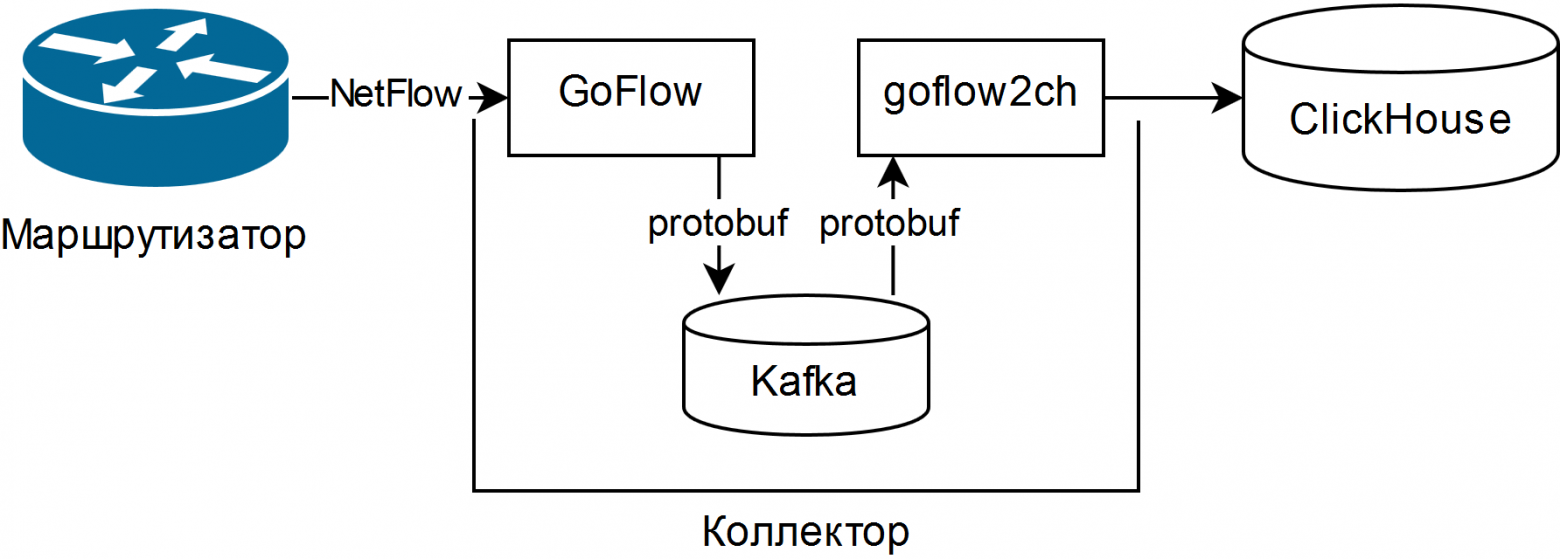
GoFlow разбирает NetFlow/sFlow пакеты и складывает их в локальную Kafka в формате protobuf. Самописная “лопата” goflow2ch вынимает сообщения из Kafka и перекладывает их в Clickhouse пачками для большей производительности. В схеме совершенно не рассматривается вопрос высокой доступности, но для каждого компонента есть или штатные, или более-менее простые внешние способы её обеспечения.
Испытания показали, что затраты CPU на разбор и сохранение тех же 5000 потоков в секунду составляют примерно четверть ядра CPU, а занимаемое дисковое пространство в среднем 11-14 байт на слегка усечённый поток.
Для отображения информации используется либо Web UI для ClickHouse под названием Tabix, либо плагин для Grafana.
Плюсы схемы:
- возможность задать произвольные вопросы о состоянии сети при помощи диалекта SQL;
- нетребовательность к ресурсам и горизонтальная масштабируемость. Подойдут старые/медленные процессоры и магнитные жёсткие диски;
- при необходимости собирается полноценный data pipeline для анализа сетевых событий, в том числе в реальном времени при помощи Kafka Streams, Flink или аналогов;
- возможность смены хранилища на произвольное минимальными средствами.
Минусов тоже порядочно:
- чтобы задавать вопросы, нужно неплохо знать SQL и его ClickHouse-диалект, готовых отчётов и графиков нет;
- множество новых движущихся частей в виде Kafka, Zookeeper и ClickHouse. Два первых на Java, что может вызывать отторжение по религиозным мотивам. Лично для меня сие проблемой не было, так как всё это уже так или иначе использовалось в организации;
- придётся писать код. Либо “лопату”, перекладывающую данные из Kafka в ClickHouse, либо адаптер для записи прямо из GoFlow.
Встреченные особенности:
- следует обязательно настраивать ротацию по размеру данных в Kafka и ClickHouse, а потом проверять, что она действительно работает. В Kafka есть лимит на размер партиции лога, а в ClickHouse — партицирование по произвольному ключу. Новая партиция каждый час и удаление лишних партиций каждые 10 минут неплохо работают для оперативного мониторинга и делаются скриптом буквально из нескольких строк;
- “лопата” выигрывает от использования consumer groups, позволяющих добавлять больше “лопат” в целях масштабирования и отказоустойчивости;
- Kafka позволяет не терять данные при падении “лопаты” или самого ClickHouse (например, от тяжёлого запроса и/или некорректно ограниченных ресурсов), но лучше, конечно, внимательно настроить БД;
- если будете собирать sFlow, помните, что некоторые коммутаторы по умолчанию меняют частоту выборки пакетов на ходу, и она указывается для каждого потока.
В итоге из компонентов с открытым исходным кодом и синей изоленты получен инструмент наблюдения за обстановкой в сети как в плюс-минус реальном времени, так и в исторической перспективе. Несмотря на свою наколеночность, он уже помог уменьшить время решения нескольких инцидентов в разы.
