Comments 87
У AMD тоже проверяется подпись, если мне не изменяет память.
{kind=link}
В плане безопасности UEFI, говорят, лучшие прошивки у HP и Dell — сказывается то, что они ещё являются и крупными игроками на корпоративном рынке. Оперативно латают дыры и вообще, такого ужаса, как «прошивка при затирании переменных не генерирует дефолтные, превращая устройство в тыкву» у них не встречается.
Lenovo вообще славится тем, что можно программно из их железок делать кирпичи.
Как раз из недавнего Сломать ноутбуки Lenovo ThinkPad можно одной настройкой BIOS
Эти компиляторы позволяют испускать предопределённый поток ассемблерных инструкций машинного кода
звучит как «испускать лучи ненависти в сторону правильно работающего микропроцессора».
GOD MODE UNLOCKED — Hardware Backdoors in x86 CPUs
у Cannonlake – больше 10 млрд.
Откуда дровишки?(с)
i3-8121U — единственный представитель микроархитектуры Cannon Lake, представляет собой крошечный двух-ядерный чип.
ark.intel.com/products/136863/Intel-Core-i3-8121U-Processor-4M-Cache-up-to-3-20-GHz-
Для сравнения — 22-ядерный Xeon E5 (Broadwell) имеет чуть более 7 миллиардов транзисторов.
Intel's 10 nanometer FinFET silicon fabrication is coming together at a slower than expected rate, however when it does, it could vastly enlarge the canvas for the company's chip designers, according to a technical report by Tech Insights. The researchers removed the die of an Intel «Cannon Lake» Core i3-8121U processor inside a Lenovo Ideapad330, and put it under their electron microscope.
Its summary mentions quite a few juicy details of the 10 nm process. The biggest of these is the achievement of a 2.7-times increase in transistor density over the current 14 nm node, enabling Intel to cram up to 100.8 million transistors per square millimeter. A 127 mm² die with nothing but a sea of transistors, could have 12.8 billion transistors.
Конечно, 12,8 млрд транзисторов — это грубая оценка, сделанная в предположении, что вся площадь кристалла заполнена транзисторами, но все-таки.
intel закрыла разработку 10nm.
Если верить английской Википедии, это не совсем так (по крайней мере, Intel это отрицает), и процессоры Intel Core i3-8121U все-таки производятся по 10-нанометровой технологии, пусть и в ограниченных количествах.
Cannon Lake (microarchitecture) — Wikipedia
Cannon Lake was initially expected to be released in 2016, but the release was pushed back to 2018.[6] Intel demonstrated a laptop with an unknown Cannon Lake CPU at CES 2017[7][8] and announced that Cannon Lake based products will be available in 2018 at the earliest.
At CES 2018 (January 9–12, 2018) Intel announced that it had started shipping mobile Cannon Lake CPUs at the end of 2017 and would ramp up production in 2018.[9][10][11]
On April 26, 2018 in its report on first-quarter 2018 financial results Intel stated it was currently shipping low-volume 10 nm product and expects 10 nm volume production to shift to 2019.[12] In July 2018, Intel announced that volume production of Cannon Lake would be delayed yet again, to late H2 2019. [13]
The first laptop featuring a Cannon Lake CPU, namely Intel Core i3-8121U, a dual core CPU with HyperThreading and Turbo Boost but without an integrated GPU, was released in May, 2018 in very limited quantities.[14][15]
According to non-official sources the 10nm process technology for Cannon Lake had too low yields to be profitable, and thus a future 10nm process will have an increased structure size in order to increase yields.[16]
A more recent rumour states that Intel «pulled the plug on their struggling 10nm process».[17] However, Intel has denied these claims.[18]
Обратите внимание на подчеркнутый мною текст.
Им нужно было показать инвесторам, что у них запущен 10nm «в срок» (ага, после кучи переносов) — они это сделали.
Что-то путное будет не раньше конца следующего года, а сколько там нанометров напишут — одни маркетологи знают…
Команда на языке ассемблера это текст. Машинная инструкция — цепочка кодов.
Верно.
Ассемблер это (в основном) мнемоническое обозначение машинных кодов.
Строго говоря, в такой строгости нет реальной необходимости. Учитывая, что ассемблер мапится в коды почти один-в-один вполне можно позволить использовать оба термина как взаимозаменяемые (исключая ситуации/контексты, в которых различие между ними действительно имеет значение).
Правильные термины — это важно, но не стоит забывать, что это не некая абсолютная важность, соблюдать которую необходимо любой ценой. Это важно только потому, что нужно чтобы все понимали, о чём речь. И пока все всё понимают и без строгого использования верных терминов — требование строгости выглядит банальным занудством.
Нет, это просто обычное легаси — так уж исторически сложилось. Кроме того, попытка использовать максимально точные термины любой ценой приводит к сленгу, который очень напоминает юридический/бюрократический/научный, и который намного сложнее воспринимать. Иными словами — всё хорошо в меру, а перегибы (в любую сторону) ни к чему хорошему не приводят.
Использование правильного термина «машинные инструкции» — это совсем не перегиб и занудство, а исторически сложилось говорить неправильно — это, видимо, в вашем окружении.
Вообще, занудство — хорошее качество для программиста.
Окей, вернёмся к частному: покажите, пожалуйста, каким образом использование конкретно в этой статье правильного термина как-то улучшит понимание сути статьи читателями? В каком месте некорректный термин ввёл читателей в заблуждение?
Как по мне — перевод от частного к общему делаете именно Вы. Я всё время говорю о том, что есть текущий контекст (частное), и его не стоит игнорировать в пользу абстрактно правильных идей (общего). Использование корректных терминов, безусловно, идея правильная. Но конкретно в данном случае реальной необходимости на этом настаивать нет — потому что исходя из содержимого статьи и широкораспространённого в русскоязычной IT-среде понимания термина ассемблер все всё поняли корректно.
Контекст очень важен, и игнорировать его не лучшая идея. Когда я обсуждаю текущий проект с другими разработчиками я могу сказать "база юзеров", и все отлично поймут, что это сокращение от "база данных", что в данном проекте традиционной базы данных как таковой нет т.к. данные лежат в трёх json-файлах, и что я имел в виду один конкретный файл из этих трёх (в котором данные с профайлами юзеров — хотя формально в остальных двух файлах данные тоже относятся к юзерам). Конечно, я могу сказать то же самое терминологически точно, напр. "файл слеш-data-слеш-db-слеш-users-точка-json содержащий список объектов описывающих профиль юзера в формате json", но, честное слово, никто из участников дискуссии не поблагодарит меня за "точность" в описании если они будут вынуждены прослушивать эту конструкцию каждый раз вместо "неточной" фразы "база юзеров". И даже если бы я использовал вышеупомянутое "точное" определение, всегда найдётся зануда, который попросит уточнять, что "слеш" это "прямой слеш", чтобы не спутали случайно с "обратный слеш", и что "объект описывающий профиль юзера" это недостаточно точно т.к. не указано какие поля и с каким содержимым содержит данный объект, и что путь к файлу это недостаточно точно без указания сервера на котором он находится, и наверняка ещё что-нибудь.
И, поймите правильно, я сам зануда, так что вопрос не в занудстве как таковом, а в том, есть ли реальный смысл занудствовать, какая от этого польза в данном конкретном случае. Если её нет — не надо занудствовать, пожалуйста.
Учитывая, что ассемблер мапится в коды почти один-в-один вполне можно позволить использовать оба термина как взаимозаменяемые
Это не совсем так, потому что современные ассемблеры понимают и сложные макроинструкции, и ветвления, и вызов процедур и размещение данных и абстраткные данные (структуры, например).
Возможно на базе этих процессоров производители строят другие архитектуры процессоров. Но тогда надо разделять эти потоки.
Не удивлюсь, что когда-нибудь, когда производители станут более открытыми, будет возможным написание микрокода процессора тупо под задачу с целью оптимизации энергопотребления, т.е. буквально под числодробилки будет перелопачиваться архитектура процессора. Очень жаль что этого мы можем тупо не дождаться, ибо бабло побеждает разум.
Это просто пример, наверное с таким же успехом это могла бы быть команда mul.Нет, не могла бы. Через микрокод идут только хитровывернутые команды, выполняющиеся десятки тактов. Но никак не mul и не mov.
Потому что там практически все команды определены микрокодомНаоборот. Через микрокод пропускается очень небольшой процент редких инструкций. Хотя, поскольку многие из них связаны с безопасностью, это всё равно страшно, да.
будет возможным написание микрокода процессора тупо под задачу с целью оптимизации энергопотребления, т.е. буквально под числодробилки будет перелопачиваться архитектура процессора.Не будет в силу вышеописанного. Любая команда на микрокоде примерно на порядок медленнее, чем «простая» инструкция — даже если она ничего не делает.
Конвейер длинный, на каком-то из первых этапов декодирования идёт обращение к базе микрокода, типа «а есть ли микрокод к вот этому опкоду».
Ящитаю, что там нет никаких проверок типа «а есть ли», там тупо опкоду mul соответствует микрокод длиной в одну команду mul. Так тупо быстрее (ну, ценой буквально +100500 байт во флэш-памяти микрокодов).
Насколько я помню таблицу опкодов, если mov и простейшие операции (add/adc/sub/sbb/cmp/or/and/xor) ещё можно выцепить маской по паре бит, то вот конкретно mul со всеми вариантами разрядности и знаковости — это отдельный геморрой.
Ящитаю, что там нет никаких проверок типа «а есть ли», там тупо опкоду mul соответствует микрокод длиной в одну команду mul.
Вы путаете микрокод и микрооперации (МОП). Декодеры превращают инструкции в 1 или несколько микроопераций. К ПЗУ микрокода (Microcode Sequencer ROM — MSROM) происходит обращение лишь в сложных случаях, операциях типа MOVSB или например если инструкция требует > 4 МОП.
В таких случаях декодеры отключатся и выполнение идёт из MSROM.
Обычные инструкции MUL/DIV это один МОП.
Обычные инструкции MUL/DIV это один МОП.Как минимум, если операнд в памяти, нужно разбить на микрооперацию загрузки и собственно умножения.
Как минимум, если операнд в памяти, нужно разбить на микрооперацию загрузки и собственно умножения.
Раньше так и делали, и load-op инструкции были в 2 МОП.
Сейчас это один МОП.
Тогда какой смысл в МОПах, если их кол-во приближается к кол-ву CISC-инструкций?
Смысл сделать их количество меньше чем количество CISC-инструкций =)
МОП-ы благодаря macrofusion могут содержать две отдельные инструкции — например cmp+jmp.
Skylake запускает 4 МОП за такт, но команд может быть больше.
Обычные инструкции MUL/DIV это один МОП.Только div на следующем этапе заменяется на подпрограмму из MSROM. Тупо потому, что, в отличие от mul, у ALU нет соответствующего блока! Там целая подпрограмма запускается — от этого и не фиксированное время исполнения и прочее.
Только div на следующем этапе заменяется на подпрограмму из MSROM. Тупо потому, что, в отличие от mul, у ALU нет соответствующего блока!
В разных процессорах по разному.
На AMD всего 1-2 МОП
www.agner.org/optimize/instruction_tables.pdf стр 93, например.
На Intel Skylake IDIV генерирует десяток микроопераций.
Не смотря на это в Интел блок для деления имеется (radix 16 divider со времён Penryn) — он висит на порту 0
«Improvements in the Intels Coret2 Penryn Processor Family Architecture and Microarchitecture»
citeseer.ist.psu.edu/viewdoc/download;jsessionid=13CD375361DAF8C4C188F1D3C67730F0?doi=10.1.1.217.155&rep=rep1&type=pdf
Так же можете почитать тут
www.imm.dtu.dk/~alna/pubs/ARITH20.pdf
Во всех описанных вами статьях очень чётко видно, что аппаратной реализации деления нет ни в одном процессоре. Во всех аппаратно реализован вспомогательный алгоритм, а собственно деление — реализовано поверх него, итеративно.
Если в процессоре есть уже микрокод — то его как раз для подобных вещей логично задействовать…
1. не перекодировать.
2. никто не мог декодировать т.к. все без спецификаций это было бы изрядной проблемой. Да и компилить было бы проблематично. Проблема решаема, но тем не менее…
Конвейер длинный, на каком-то из первых этапов декодирования идёт обращение к базе микрокода, типа «а есть ли микрокод к вот этому опкоду».Это было бы не глупо, а очень глупо. Не забудьте, что x86 — это CISC, а современные процессоры — суперскаляры. К микрокоду может обращаться только один декодер из двадцати (да-да, в современных CPU не два, не три, но двадцать декодеров… вернее 16+4 — подумайте почему так).
Так тупо быстрее (ну, ценой буквально +100500 байт во флэш-памяти микрокодов).Так вы уж определитесь — «ценой буквально +100500 байт во флеш-памяти микрокодов» или «тупо быстрее». Вас не смущает разница между этими числами примерно так на порядок (не двоичный — в 10 раз)? Декодер должен обрабатывать 3-4 инструкции за один такт, а обращение к кешу L1 (по размеру он сравним с микрокодов) — занимает в современных CPU больше одного такта!
P.S. Многие не осознают того, что обозначают частоты в 3-4GHz и миллиарды транзисторов для разработчиков CPU. А обозначают они одну простую вещь: вы не можете позволить себе иметь большие блоки, работающие на полной тактовой частоте. Можете сделать 100 или даже 1000 мини-блоков, каждый из которых будет состоять из нескольких тысяч транзисторов. А можете сделать да, большой блок из 100500 транзисторов (как кеш L3) — но тогда этот блок даже на частоте процессора не сможет работать, хорошо, если 1/3 или 1/4 «осилит»…
А можете сделать да, большой блок из 100500 транзисторов (как кеш L3) — но тогда этот блок даже на частоте процессора не сможет работать, хорошо, если 1/3 или 1/4 «осилит»…
? Сейчас же вроде все кэши работают на частоте CPU. Вроде бы во времена Slot 1 были процессоры с половинной частотой кэша.
www.anandtech.com/show/399/4
ПС вполне себе согласуются. L1 кэш сидит на 256 бит шине способной в пределе проталкивать до 32 байт/так, работает с частотой процессора 3-5 ГГц и соответственно выдает ПС за 100 ГБ/сек для каждого физического ядра. На оптимизированном коде можно получить близко к этому теоретическому пределу: тест
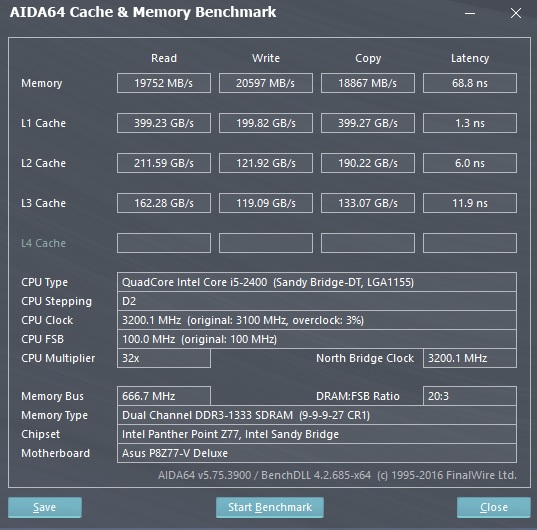{kind=link}
L2 работает обычно где-то в 2 раза медленнее из-за особенностей работы шины и сихронизации между уровнями кэшей.
Вот L3 кэши уже другая история — там и шина более узкая и делится между ядрами и работают они как раз не на полной частоте ядра, а на собственной сниженной. Что у Intel (Uncore), что у AMD.
А можно объяснить для тех, кто не железячник?
Но… как, Берримор, как? Инструкции в x86 все имеют разную длину, от одного байта аж до 15 — а мы хотим несколько инструкций декодировать параллельно.
Решение — просто до генимальности: у нас есть два вида декодеров. «Предварительные», простые, умеют ответить на два вопроса — «а сколько байт занимает инструкция?» и «какого класса эта инструкция?» — и запускаются на все 16 байт от
RIP до RIP+15. А на следующем такте мы уже можем напустить более сложные декодеры на инструкции, зная их класс и длину — в параллель, как и положено. Причём «первичные декодеры» должны отработать за один такт (иначе нам на следующем такте не удастся «сдвинуть» окно), а вот уже декодеры, которые декодируют инструкцию «по настоящему» — могут это делать не один так, а и два и пять… в зависимости от процессора.Вообще надо сказать, что декодер на x86 — это одна из самых сложных, ресурсоёмких, и критически важных для обеспечения приемлемой скорости работы часть процессора… а туда хотят встроить обращение к микрокоду «почём зря».
Почему как вы думаете Ryzen отказался от всех AMD-специфических 3DNow! и всяких XOP-инструкций? Они ж вроде не такие сложные были? Ответ: да — для ALU они не были уж очень сложными, но их очень тяжело декодировать. Добавьте сюда их малопопулярность… и вывод очевиден…
Почему как вы думаете Ryzen отказался от всех AMD-специфических 3DNow! и всяких XOP-инструкций? Они ж вроде не такие сложные были? Ответ: да — для ALU они не были уж очень сложными, но их очень тяжело декодировать. Добавьте сюда их малопопулярность… и вывод очевиден…
По сути вы правы, но хочу немного уточнить:
Поддержка этих инструкций действительно требовала ресурсов кристалла в основном именно для декодирования, но и плюс затраты (нельзя назвать несущественными) на внешне небольшую разницу в поведении.
При этом рынок всё равно требует поддержки Intel-овских кодов. Получалось что AMD приходилось носить два "чемодана с батарейками", причем это затраты не только внутри кристалла, но и на всех этапах дизайна / разработки / верификации.
/офф
i7-690 — 80 записей в таблице с эррата
самосгораемый атом- 250.
И по каждой выпускать новый степпинг, отзывая проданные.
Ох уж эти идеалисты
При таком количестве транзисторов неудивительно, что современные процессоры x86 испещрены недокументированными инструкциями и аппаратными уязвимостями.
Звучит весьма противоречиво
сложно переплетающийся лабиринт новых и античных технологий
Нет, вы опять за свое? :) Что у нас там из античных технологий? Литье бронзы, гончарное дело, колесницы и рабский труд. Но никаких процессоров х86.
З.Ы. Уже вкатили минус. Наверно заслужил. Но в ролике как раз про реализацию «безопасности» в Эльбрусах. :)
При таком количестве транзисторов неудивительно, что современные процессоры x86 испещрены недокументированными инструкциями и аппаратными уязвимостями. Среди недокументированных, – обнаруженных почти случайно, – инструкций: ICEBP (0xF1), LOADALL (0x0F07), apicall (0x0FFFF0) [1], которые позволяют разблокировать процессор для несанкционированного доступа к защищённым областям памяти.
Ну что за глупости. Количество транзисторов тут совершенно ни при чём, тем более что значительная их доля — это кеш-память, а вовсе не логика.
По поводу инструкций — не знаю насчёт apicall, но вот 0xF1 явно никто прятать не собирался, а LOADALL вполне штатно используется (или использовалось по крайней мере) биосами.
Бэкдоры в микрокоде ассемблерных инструкций процессоров x86