Привет, Хабр! Вдоволь наотдыхавшись после длинных праздников, мы снова готовы причинять вам пользу всеми доступными способами. Коллегам из IT-департамента всегда есть что рассказать, и сегодня мы делимся с вами докладом Александра Призова, системного администратора Яндекс.Денег, с митапа JavaJam.
Как мы выстроили поток обратной связи для обнаружения проблемных релизов с помощью Graphite и Moira. Расскажем, как собирать и анализировать метрики о количестве ошибок в приложении.
— Всем привет, меня зовут Александр Призов, я работаю в отделе автоматизации эксплуатации в Яндекс.Деньгах, и сегодня я расскажу вам о том, как мы собираем, обрабатываем, анализируем информацию о нашей системе.
У вас, наверное, мог возникнуть вопрос, почему доклад называется The Second Way (название доклада на митапе — прим. ред). Все достаточно просто. В основе DevOps лежит ряд принципов, которые, условно, разделены на три группы.
Первый путь — принцип потока. Второй путь включает в себя принцип обратной связи. Третий путь — непрерывное обучение и экспериментирование.
Как правило, в терминах разработки и эксплуатации программных продуктов под обратной связью подразумевается телеметрия, которую мы собираем о нашей системе, и наиболее распространенным случаем является сбор и обработка метрик.
Для чего нам нужны эти метрики? С помощью метрик мы получаем обратную связь от системы и можем знать, в каком состоянии находится наша система, всё ли идет хорошо, как наши изменения повлияли на ее работу, и необходимо ли какое-то вмешательство для решения тех или иных проблем.
Какие метрики мы собираем?
Мы собираем метрики с трех уровней.
Бизнес-уровень включает в себя показатели, интересные, с точки зрения каких-либо бизнес-задач. Например, мы можем получить ответы на вопросы, такие, сколько пользователей у нас зарегистрировано, как часто пользователи логинятся в нашу систему, какое количество активных пользователей у нашего мобильного приложения.
Следующий уровень — уровень приложения. Метрики данного уровня чаще всего просматриваются разработчиками, потому что эти показатели дают ответ на вопрос, как хорошо работает наше приложение, как быстро оно обрабатывает запросы, есть ли просадки в производительности. Сюда включаются время ответа, количество запросов, длина очереди и ещё много чего.
И, наконец, уровень инфраструктуры. Здесь все предельно ясно. С помощью этих метрик мы можем оценить количество потребляемых ресурсов, как их спрогнозировать и выявить проблемы, связанные с инфраструктурой.
Теперь в двух словах опишу то, как мы эти метрики отправляем, обрабатываем и где храним. Рядом с приложением у нас находится коллектор метрик. В нашем случае это сервис Heka, который слушает порт UDP и ожидает на вход метрики в формате StatsD.
Формат StatsD выглядит следующим образом:

То есть мы определяем название метрики, указываем значение этой метрики, это 1, 26 и так далее, и указываем его тип. Всего у StatsD порядка четырех или пяти типов. Если вам вдруг интересно, вы можете сами детально посмотреть описание этих типов.

После того, как приложение отправило данные Heka, метрики агрегируются за определенное время. В нашем случае это 30 секунд, после чего Heka отправляет данные в carbon-c-relay, которая осуществляет функцию фильтрации, маршрутизации, модификации метрик, который, в свою очередь, отправляет метрики в наш storage, мы используем clickhouse (да, он не тормозит), а также в Moira. Если кто не знает, это такой сервис, который позволяет настроить определенные триггеры для метрик. О Moira я поговорю чуть позже. Итак, мы просмотрели, какие метрики мы собираем, как мы их отправляем и обрабатываем. И следующим логичным этапом является анализ этих метрик.
Как мы анализируем метрики?
Приведу реальную ситуацию, где анализ метрик дал нам ощутимые результаты. В качестве примера возьмем наш релизный процесс. В общем виде он включает в себя следующие этапы.
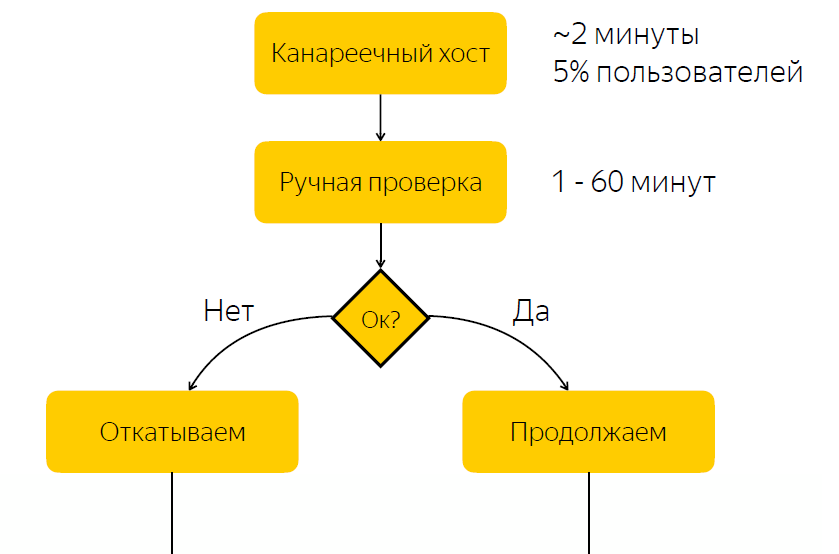
Релиз развертывается на канареечный хост. На него приходится порядка пяти процентов пользовательского трафика. После того, как релиз на канареечный хост завершен, мы оповещаем ответственного за релиз о том, что ему следует проверить все ли в порядке с релизом. И он должен дать реакцию, среагировать на этот релиз и нажать на кнопку с решением о том, стоит ли этот релиз катить дальше, либо его следует откатывать.
Не трудно догадаться, что в данной схеме имеется существенный недостаток, а именно то, что мы ожидаем реакции ответственного. Если ответственный в настоящий момент по каким-то причинам не может оперативно среагировать, то если релиз у нас с багами, то какое-то время пять процентов трафика приходит на проблемную ноду. Если с релизом все в порядке, то мы попросту тратим время на ожидание, и тем самым тормозим релизный процесс.
Без багов — тормозим релизный процесс
С багами — аффектим пользователей
С пониманием этой проблемы мы решили выяснить, можно ли автоматизировать процесс принятия решения о том, является ли релиз проблемным или нет.
Мы, конечно же, обратились к нашим разработчикам, чтобы понять, как происходит проверка релиза. Оказалось, и кажется достаточно логичным, что основным индикатором того, что релиз проблемный, является увеличение количества ошибок в логах этого приложения.
Как поступали разработчики? Они открывали Kibana, делали выборку по уровню ERROR блока приложения, и в случае, если они видели списки, то считали, что с приложением что-то идет не так. Стоит упомянуть, что логи нашего приложения хранятся в Elastic, и, кажется, что всё выглядит достаточно просто. Логи у нас в Elastic, нам осталось только сформировать запрос в Elastic, сделать выборку и понять на основе этих данных, является ли релиз проблемным или нет. Но это решение нам показалось не очень хорошим.
Почему не Elastic?
В первую очередь, мы обеспокоились о том, что мы могли не оперативно получать данные из Elastic. Бывают такие случаи, например, при нагрузочном тестировании, когда у нас идет большой поток данных, а кластер может не справляться, и, в конечном счете, происходит задержка в отправке логов примерно 10-15 минут.
Также были второстепенные причины, например, отсутствие унифицированного названия для индексов. Это нужно было учитывать в средстве автоматизации. А также приложения на разных платформах могли иметь разный формат логов.
Мы задумались, почему бы не попробовать сделать какие-то метрики, на основе которых мы можем принимать решение, является релиз проблемным или нет. В то же время, мы не хотели обременять наших разработчиков, чтобы они вносили изменения в кодовую базу. И, как нам кажется, мы нашли довольно-таки элегантное решение с помощью добавления дополнительного appender в log4j.
Как это выглядит
<?xml version="1.0" encoding="UTF-8" ?>
<Configuration status="warn" name="${sys:application.name}" >
<Properties>
<Property name="logsCountStatsDFormat">app_name.logs.%level:1|c</Property>
</Properties>
...
<Appenders>
<Socket name="STATSD" host="127.0.0.1" port="8125" protocol="UDP">
<PatternLayout pattern="${logsCountStatsDFormat}"/>
</Socket>
</Appenders>
<Loggers>
<Root level="INFO">
<AppenderRef ref="STATSD"/>
</Root>
</Loggers>
</Configuration>Сначала мы определяем формат метрики, которую отправляем. Ниже описан дополнительный appender, который отправляет записи в формате, который у нас указан выше, в порт 8125 по UDP, то есть в Heka. Что нам это дает? Log4j на каждую запись в логе отправляет метрику типа Counter, с заданным уровнем записи ERROR, INFO, WARN и так далее.
Однако мы быстро осознали, что отправка метрики на каждую запись в логах может создавать достаточно существенную нагрузку, и написали библиотеку, которая агрегирует метрики за определенное время и отправляет уже агрегированную метрику в сервис Heka. Собственно, этот appender мы добавляем в loggers, и с помощью данного подхода мы теперь знаем, сколько наше приложение пишет логов разбивки по уровням, имеем унифицированное название для метрик, вне зависимости от того, какая платформа используется. Мы с легкостью можем понять, сколько ошибок в логе приложения. И, наконец, мы смогли автоматизировать процесс принятия решения о проблемном релизе.
Автоматизация
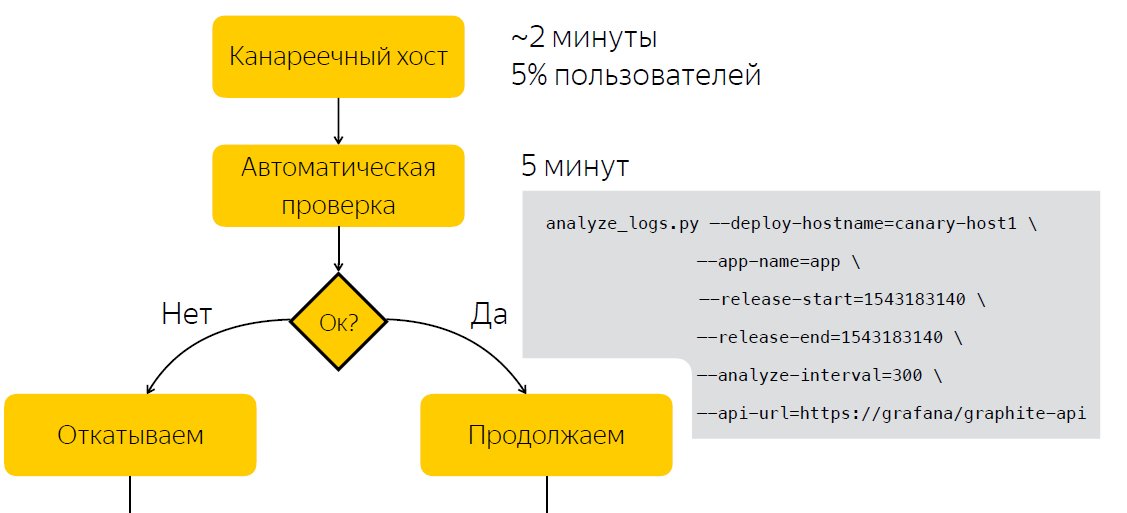
Вместо ручной проверки после релиза мы ждем пять минут, после чего собираем данные о количестве записей в логах приложения. После запускаем скрипт, который на основе двух выборок, до релиза и после, принимает решение, является ли релиз проблемным. Тем самым мы сократили количество времени, которое тратим на принятие решения, до пяти минут.
Помимо того, что информация о количестве ошибок в логах полезна во время релиза, приятным бонусом для нас оказалось то, что она также полезна в процессе эксплуатации. Так, например, мы можем визуализировать количество ошибок в логах в Grafana и фиксировать аномальные всплески в логах приложений.
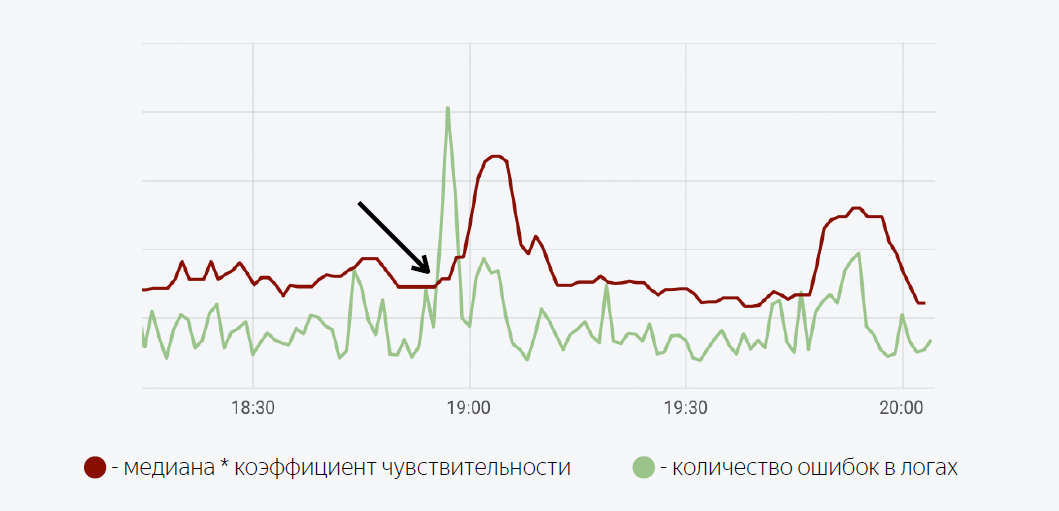
Здесь используется достаточно простая математическая модель. Зеленая линия — это количество ошибок в логах приложения. Темно-красная — это медиана, умноженная на коэффициент чувствительности. В случае, когда количество ошибок в логах пересекают медиану, у нас срабатывает триггер, при срабатывании которого отправляется нотификация через Moira.

Как я и обещал, расскажу немного про Moira, как это работает. Мы определяем целевые метрики, которые мы хотим наблюдать. Это количество ошибок и скользящая медиана, а также условия, при которых этот триггер сработает, то есть когда количество ошибок в логах превышает медиану, умноженную на коэффициент чувствительности. При срабатывании триггера разработчику приходит уведомление о том, что зафиксирован аномальный всплеск ошибок в приложении, и следует предпринять какие-то действия.

Что мы имеем в итоге? Мы разработали общий механизм для всех наших backend-приложений, которые позволяют получить информацию о количестве записей в логах заданного уровня. Также с ��омощью метрик о количестве ошибок в логах приложения мы смогли автоматизировать процесс принятия решения о том, является релиз проблемным или нет. А также написали библиотеку для log4j, которой вы можете воспользоваться, если захотите попробовать подход, который я описывал. Ссылка на библиотеку чуть ниже.
На этом у меня, пожалуй, все. Спасибо.
