Привет, Habr!
В первой части был рассмотрен протокол обмена пейджерными сообщениями POCSAG. Были рассмотрены цифровые сообщения, перейдем теперь к более «полноценным» сообщениям в формате ASCII. Тем более, что декодировать их интереснее, т.к. на выходе будет читаемый текст.

Для тех кому интересно, как это работает, продолжение под катом.
Сначала сигнал надо принять, для чего воспользуемся тем же самым rtl-sdr приемником и программой HDSDR. Мы уже знаем из первой части, что пейджинговые сообщения могут быть цифровые (содержание только цифры 0-9, букву U — «ugrent», пробел и пару скобок) и буквенно-цифровые, содержание полноценные ASCII-символы. Естественно, мы не знаем заранее тип сообщения (декодировать их «на слух» пока еще не получается), поэтому при записи просто выбираем сообщение подлиннее.

Программа преобразования wav-файла в битовый поток уже рассматривалась, поэтому сразу покажем результат — пейджинговое сообщение целиком выглядит вот так:

Некоторые особенности видны сразу невооруженным глазом — например видно, что стартовая последовательность 01010101010101 повторяется дважды. Т.е. это сообщение не только более длинное, но и по сути состоит из двух «склеенных» вместе, впрочем стандарт это не запрещает.
Для начала напомним краткое содержание предыдущей части. Пейджинговое сообщение начинается с длинного заголовка 0101010101, за которым следует последовательность «пакетов», показанных на картинке как Batch1..N:
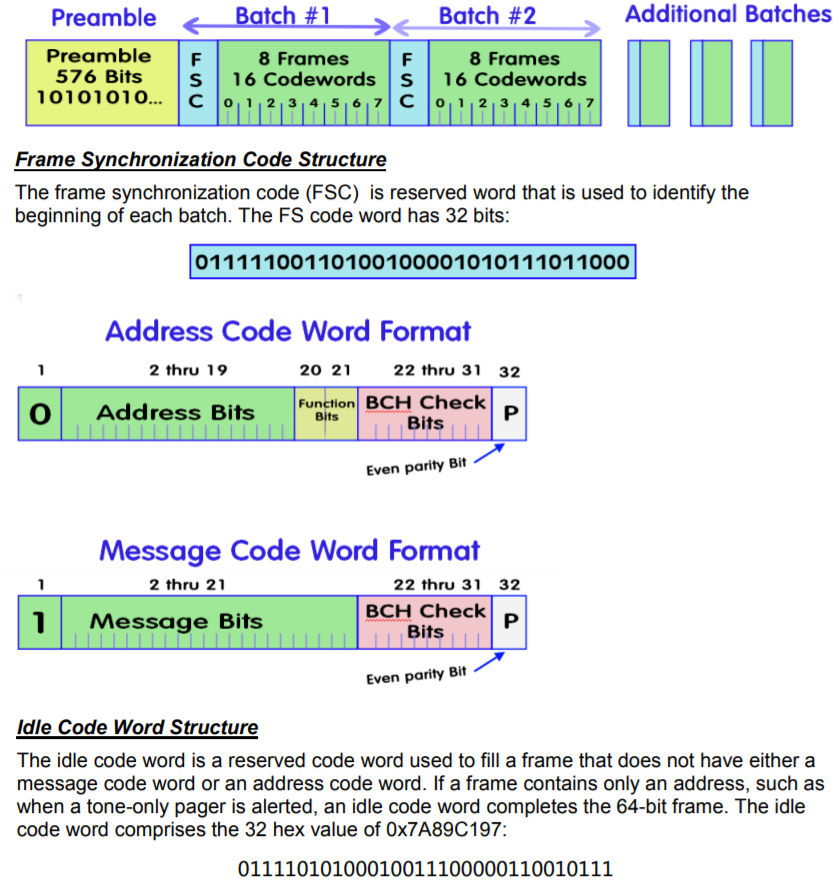
Каждый пакет начинается со стартовой последовательности Frame Sync Code (01111100...), за которой идут 32-битные блоки. Каждый блок может хранить либо адрес, либо тело сообщения.
В предыдущий раз мы рассматривали только цифровые сообщения, теперь же нас интересуют сообщения ASCII. Первым делом, нужно научиться их различать. Для этого нам понадобится поле «Function Bits» — если эти 2 бита равны 00, то сообщение цифровое, если 11, то текстовое.
Как видно из рисунка, на поле сообщения отводится 20 бит, что как раз идеально ложится в 5 4-х битных BCD-кода, если сообщение цифровое. А вот если сообщение текстовое, то текста в 20 бит много не уместить, да и 20 не делится ни на 7, ни на 8. Можно предположить, что первая версия протокола (а он был создан аж в 1982г) поддерживала только цифровые сообщения (да и вряд ли первые пейджеры тех лет на nixie-трубках могли отобразить больше), а уже затем, в следующую версию, была добавлена поддержка ASCII. Но т.к. стандарт формата нарушать было уже нельзя, поступили проще — битовый поток просто объединяется как есть (из каждого сообщения извлекается 20 бит и добавляется в конец буфера), а уже затем, в конце, все это декодируется на символы.
Рассмотрим один блок принятого сообщения (пробелы добавлены для наглядности):
В первой строке «0» в первом бите указывает на то, что это поле адреса, а «11» в битах 20-21 указывает, что это сообщение символьное. Далее просто берем 20 бит из каждой строки и складываем их вместе.
Получаем такую битовую последовательность:
В протоколе POCSAG используется 7-битный ASCII, так что просто делим строку на блоки по 7 бит:
Пытаемся декодировать коды символов (таблица ASCII легко гуглится в интернете), и… получаем на выходе мусор. Еще раз открываем документацию и находим малозаметную фразу «ASCII characters are placed from left to right (MSB to LSB). The LSB is transmitting first.». Т.е. сначала передается младший бит, а потом уже старший — для корректного декодирования ASCII-кодов 7-битные строки нужно перевернуть.
Чтобы не делать это вручную, пишем код на Python:
В результате, получаем такую последовательность (биты, коды символов, и сами символы):
Объединяем символы вместе и получаем строку: "(03-feb-2019 13:31:45 *476) AWZ". Как и обещалось в начале статьи, текст вполне читабельный.
Кстати, еще один интересный момент в том, что как можно видеть, в протоколе используется 7-битный ASCII. Символы кирилицы не помещаются в этот диапазон, так что вопрос, как в пейджеры прошивали русский язык, остается открытым. Если кто знает, напишите в комментариях.
Разумеется, протокол разобран не полностью, но самая интересная часть сделана, а дальше остается рутина, которая уже не так интересна. Как минимум, нет декодирования адресов получателей (capcodes), и не реализована поддержка кода коррекции ошибок (BCH Check Bits) — это позволило бы исправлять до 2х «испорченных» при передаче бит. Впрочем, цели сделать полноценный декодер и не стояло — такие декодеры уже есть, и еще один вряд ли нужен.
Желающие попробовать декодировать сообщения с помощью rtl-sdr, могут сделать это самостоятельно с помощью бесплатной программы PDW. Она не требует инсталляции, после запуска необходимо перенаправить выход HDSDR на вход PDW с помощью программы Virtual Audio Cable и выбрать в аудио-настройках PDW соответствующее устройство.
Результат работы программы выглядит примерно так:

На этом тему пейджинговых сообщений можно считать закрытой. Желающие изучить тему более подробно, могут изучить исходные коды программы multimon-ng, которая может декодировать множество протоколов, в том числе POCSAG и FLEX.
В первой части был рассмотрен протокол обмена пейджерными сообщениями POCSAG. Были рассмотрены цифровые сообщения, перейдем теперь к более «полноценным» сообщениям в формате ASCII. Тем более, что декодировать их интереснее, т.к. на выходе будет читаемый текст.
Для тех кому интересно, как это работает, продолжение под катом.
Прием сигнала
Сначала сигнал надо принять, для чего воспользуемся тем же самым rtl-sdr приемником и программой HDSDR. Мы уже знаем из первой части, что пейджинговые сообщения могут быть цифровые (содержание только цифры 0-9, букву U — «ugrent», пробел и пару скобок) и буквенно-цифровые, содержание полноценные ASCII-символы. Естественно, мы не знаем заранее тип сообщения (декодировать их «на слух» пока еще не получается), поэтому при записи просто выбираем сообщение подлиннее.
Программа преобразования wav-файла в битовый поток уже рассматривалась, поэтому сразу покажем результат — пейджинговое сообщение целиком выглядит вот так:
Некоторые особенности видны сразу невооруженным глазом — например видно, что стартовая последовательность 01010101010101 повторяется дважды. Т.е. это сообщение не только более длинное, но и по сути состоит из двух «склеенных» вместе, впрочем стандарт это не запрещает.
Декодирование
Для начала напомним краткое содержание предыдущей части. Пейджинговое сообщение начинается с длинного заголовка 0101010101, за которым следует последовательность «пакетов», показанных на картинке как Batch1..N:
Каждый пакет начинается со стартовой последовательности Frame Sync Code (01111100...), за которой идут 32-битные блоки. Каждый блок может хранить либо адрес, либо тело сообщения.
В предыдущий раз мы рассматривали только цифровые сообщения, теперь же нас интересуют сообщения ASCII. Первым делом, нужно научиться их различать. Для этого нам понадобится поле «Function Bits» — если эти 2 бита равны 00, то сообщение цифровое, если 11, то текстовое.
Как видно из рисунка, на поле сообщения отводится 20 бит, что как раз идеально ложится в 5 4-х битных BCD-кода, если сообщение цифровое. А вот если сообщение текстовое, то текста в 20 бит много не уместить, да и 20 не делится ни на 7, ни на 8. Можно предположить, что первая версия протокола (а он был создан аж в 1982г) поддерживала только цифровые сообщения (
Рассмотрим один блок принятого сообщения (пробелы добавлены для наглядности):
0 0001010011100010111111110010010
1 00010100000110110011 11100111001
1 01011010011001110100 01111011100
1 11010001110110100100 11011000100
1 11000001101000110100 10011110111
1 11100000010100011011 11101110000
1 00110010111011001101 10011011010
1 00011001011100010110 10011000010
1 10101100000010010101 10110000101
1 00010110111011001101 00000011011
1 10100101000000101000 11001010100
1 00111101010101101100 11011111010В первой строке «0» в первом бите указывает на то, что это поле адреса, а «11» в битах 20-21 указывает, что это сообщение символьное. Далее просто берем 20 бит из каждой строки и складываем их вместе.
Получаем такую битовую последовательность:
00010100000110110011010110100110011101001101000111011010010011000001101000
11010011100000010100011011001100101110110011010001100101110001011010101100
000010010101000101101110110011011010010100000010100000111101010101101В протоколе POCSAG используется 7-битный ASCII, так что просто делим строку на блоки по 7 бит:
0001010 0000110 1100110 1011010 0110011 1010011 ...Пытаемся декодировать коды символов (таблица ASCII легко гуглится в интернете), и… получаем на выходе мусор. Еще раз открываем документацию и находим малозаметную фразу «ASCII characters are placed from left to right (MSB to LSB). The LSB is transmitting first.». Т.е. сначала передается младший бит, а потом уже старший — для корректного декодирования ASCII-кодов 7-битные строки нужно перевернуть.
Чтобы не делать это вручную, пишем код на Python:
def parse_msg(block):
msgs = ""
for cw in range(16):
cws = block[32 * cw:32 * (cw + 1)]
# Skip the idle word
if cws.startswith("0111101010"):
continue
if cws[0] == "0":
addr, type = cws[1:19], cws[19:21]
print(" Addr:" + addr, type)
else:
msg = cws[1:21]
print(" Msg: " + msg)
msgs += msg
# Split long string to 7 chars blocks
bits = [msgs[i:i+7] for i in range(0, len(msgs), 7)]
# Get the message
msg = ""
for b in bits:
b1 = b[::-1] # Revert string
value = int(b1, 2)
msg += chr(value)
print("Msg:", msg)
print()
В результате, получаем такую последовательность (биты, коды символов, и сами символы):
0101000 40 (
0110000 48 0
0110011 51 3
0101101 45 -
1100110 102 f
1100101 101 e
1100010 98 b
0101101 45 -
0110010 50 2
0110000 48 0
0110001 49 1
0111001 57 9
0100000 32
0110001 49 1
0110011 51 3
0111010 58 :
0110011 51 3
0110001 49 1
0111010 58 :
0110100 52 4
0110101 53 5
0100000 32
0101010 42 *
0110100 52 4
0110111 55 7
0110110 54 6
0101001 41 )
0100000 32
1000001 65 A
1010111 87 W
1011010 90 Z
Объединяем символы вместе и получаем строку: "(03-feb-2019 13:31:45 *476) AWZ". Как и обещалось в начале статьи, текст вполне читабельный.
Кстати, еще один интересный момент в том, что как можно видеть, в протоколе используется 7-битный ASCII. Символы кирилицы не помещаются в этот диапазон, так что вопрос, как в пейджеры прошивали русский язык, остается открытым. Если кто знает, напишите в комментариях.
Выводы
Разумеется, протокол разобран не полностью, но самая интересная часть сделана, а дальше остается рутина, которая уже не так интересна. Как минимум, нет декодирования адресов получателей (capcodes), и не реализована поддержка кода коррекции ошибок (BCH Check Bits) — это позволило бы исправлять до 2х «испорченных» при передаче бит. Впрочем, цели сделать полноценный декодер и не стояло — такие декодеры уже есть, и еще один вряд ли нужен.
Желающие попробовать декодировать сообщения с помощью rtl-sdr, могут сделать это самостоятельно с помощью бесплатной программы PDW. Она не требует инсталляции, после запуска необходимо перенаправить выход HDSDR на вход PDW с помощью программы Virtual Audio Cable и выбрать в аудио-настройках PDW соответствующее устройство.
Результат работы программы выглядит примерно так:
На этом тему пейджинговых сообщений можно считать закрытой. Желающие изучить тему более подробно, могут изучить исходные коды программы multimon-ng, которая может декодировать множество протоколов, в том числе POCSAG и FLEX.
