Comments 184
Если способ округления из статьи правильный, значит ли это, что в стандартной функции atof используется неправильный?
В моем алгоритме решается следующая задача. Имеется, допустим, двоичное число (float) y=1.00100111100111010011011*2^-21, значение которого равно десятичному представимому числу x=4.7731452512794022565370082855225e-7. Надо правильно округлить это число до N (произвольных) десятичных значащих цифр и представить полученное число в нормализованном двоичном коде. Например, для N=7, наше округленное число будет равно Xr=4.773145e-7. Его двоичный эквивалент равен y=1.00000000010000011001101e-21. Значение этого числа равно десятичному представимому числу X=4.77314472391299204900860786438E-7, которое является ближайшим к правильно округленному числу Xr.
Надо правильно округлить это число до N (произвольных) десятичных значащих цифр и представить полученное число в нормализованном двоичном коде.
Зачем? Объясните, ради какой практической надобности может понадобиться преобразовывать двоичное число в десятичное, потом округлять, а потом снова преобразовывать в двоичное?
Функция atof преобразует строку в значение типа double.
В моем алгоритме решается следующая задача. Имеется, допустим, двоичное число (float) y=1.00100111100111010011100*2^-21, значение которого равно десятичному представимому числу x=5.50624235984287224709987640380859375E-7. Надо правильно округлить это число до N (произвольных) десятичных значащих цифр и представить полученное число в нормализованном двоичном коде. Например, для N=7, наше округленное число будет равно Xr=5.506242e-7. Его двоичный эквивалент равен y=1.00100111100111010011011*2^-21. Значение этого числа равно десятичному представимому числу X=5,5062417914086836390197277069092e-7E-7, которое является ближайшим к правильно округленному числу Xr. Заметьте, что x≠X.
наше округленное число будет равно Xr=5.506242e-7
X=5,5062417914086836390197277069092e-7, которое является ближайшим к правильно округленному числу Xr
Это неправда.
double a = atof("5.506242e-7");
printf("%.35e\n", a);
// 5.50624199999999978808254419426759796e-07А, да.
Так а чем вас стандартный способ не устраивает, который ниже предложили ("умножение числа и последующее после округления деление")?
float a = atof("5.50624235984287224709987640380859375e-7");
double multiplier = pow(10, 7 + 6);
float rounded = floor(a * multiplier + 0.49999997f) / multiplier;
printf("%.31e\n", rounded);
// 5.5062417914086836390197277069092e-07Имеется, допустим, двоичное число (float)
Ок.
Надо правильно округлить это число до N (произвольных) десятичных значащих цифр
Округлением обычно занимаются при выводе результатов. printf обычно используют, или
и представить полученное число в нормализованном двоичном коде.
Использовать округленные значения в дальнейших расчетах? Зачем?
1,12345678987658000000E56 + 4,12345678987654000000E56--7,92721801979018000000E+42 = -5,2469135797532E+56.
Вас ответ устраивает?
Если это окончательный результат, то на погрешность можно закрыть глаза, а если результат умножить на E+56, то ответ будет мало походить на ноль.
Я думаю, что в случае, когда в алгоритме присутствует вычитание, желательно аргументы перед вычитанием округлить в десятичном эквиваленте. К чему может привести катастрофическая отмена хорошо описано в многочисленных источниках.
а данные снабжены информацией о числе верных знаков
Где кроется эта информация о десятичных верных знаках в двоичном числе формата double?
От того, что вы умножите результат на миллиарды, вы получите ответ с погрешностью, увеличенной в миллиарды раз
О чем и речь. А если бы перед вычитанием числа были правильно округлены, мы, в нашем примере, получили бы 0. И какое бы число на 0 ни умножай, в результате будет 0.
Не всегда ее нужно носить и преобразовывать вместе с числами, так как эта информация просчитывается при доказательстве устойчивости и сходимости, например, той же разностной схемы.
К примеру, для МКР, которым решают классическую задачу — дифференциальное уравнение с частными производными — эллептическое уравление, заданное на квадрате, если разбить этот квадрат сеткой с шагом 0.1, полученное решение будет менее чем на 0.01 отличаться от точного. То есть точность — два знака после запятой.
Эта информация известна мне, как разработчику алгоритма, из теоретических выкладок, я ее в программу даже засовывать не буду, а в сопроводиловке напишу — «программа считает два знака точно, потому что использует схему второго порядка точности».
Когда нужно, чтобы числа правильно считались в символьном смысле, арифметику с плавающей запятой просто не используют — используют либо арифметику с неограниченным числом знаков и рациональными дробями, как матлаб какой-нибудь,
либо арифметику с фиксированной запятой — там правильное округление уже заложено.
Есть ли в этом какой-то практический смысл, в сложении чисел, отличающихся на 14 порядков? Пролететь 1 млрд км туда, потом еще 1 мм, потом 1 млрд км обратно —
перемещение будет 1 мм? ;)
Мне что-то подсказывает, что Вы с упорством, достойном лучшего применения, используется IEEE574 не по назначению.
И какое упорство достойно лучшего применения, чем стремление сделать вычисления более точными и более быстрыми (читай простыми)? Вы не предложили ни одной работающей программы, решающей проблему правильного округления десятичных чисел в двоичном коде. Не могут предложить простого решения и разработчики стандарта. Хотя ломают над этим голову.
См., например, 1. Modern Computer Arithmetic Richard P. Brent and Paul Zimmermann 2. Correctly Rounded Floating-point Binary-to-Decimal and Decimal-to-Binary Conversion Routines in Standard ML
3. Hardest-to-Round Cases – Part 2 и другие. Все эти ребята входят в рабочую группу по ревизии стандарта IEEE754 и пока проблему не решили.
И потом, стандарт должен удовлетворять потребности всех пользователей решающих разнообразные задачи, а не только тех с которыми вы сталкиваетесь. Уж извините. Накипело. Поэтому, давайте по делу.
А каково назначение IEEE754
Вычисления, производимые над результатами измерений, разумеется.
сделать вычисления более точными
Вычисления не будут точнее, чем исходные данные. А в исходных данных у вас никогда не будет столько значимых цифр, сколько входит в мантиссу double.
И точность результата будет у вас уменьшаться при каждом вычислении, независимо от того, в каком формате вы храните данные.
Вы не предложили ни одной работающей программы, решающей проблему правильного округления десятичных чисел в двоичном коде.
Вы не объяснили, нахрена она нужна.
Рассмотрим разность двух десятичных чисел 9876543210988,06-9876543210988,04=0,02. В формате double эта разность будет 9.876543210988060546875E12-9.8765432109880390625E12=0.021484375
Ошибка вычисления в двоичном коде относительно точного значения будет |0.02-0.021484375|= 0.001484375. Если же округлить полученный результат до 2 знаков после запятой получим 0,02. Или в формате double 2.00000000000000004163336342344E-2. Ошибка после десятичного округления двоичного числа составляет |0.02-0.0200000000000000004163336342344|≈0,4*10^-17.
Попробуйте, в который раз предлагаю, сделать осмысленный эксперимент. Посчитать sin(pi) через ряд Тейлора по обычной методике и по вашей. Если по вашей методике ряд сойдется к нулю значительно быстрее — тогда ок, ее можно применять в прикладных расчетах.
двух десятичных чисел 9876543210988,06-9876543210988,04
Замечательно. С какой точностью они известны?
Приведите пример физической величины, которую можно измерить с подобной точностью.
Что касается порядка чисел, приведенных в примере, то я думаю где-нибудь в астрономии, космологии, или в микромире, вы вполне можете столкнуться с подобными величинами.
Если Вы лично работаете с абсолютно точными цифрами — вы не должны использовать тип с плавающей точкой, ни IEEE754, ни какой-то другой, какой вы выдумаете. Это как 2*2=4.
Вы попытались его использовать, ладно бы для работы, а для баловства, с вроде как точными значениями, и у вас «неожиданно» получилось плохо. Вы вместо того, чтобы взять более подходящий для ваших задач инструмент, развели бурную деятельность по обсиранию указанного инструмента.
Если же округлить полученный результат до 2 знаков после запятой получим 0,02
У вас было 2 числа, известных с точностью до 2 знаков после запятой, которые при вычитании должны давать 0.02 с точностью до 2 знаков после запятой. После вычитания получилось 0.02 с точностью до 2 знаков после запятой (0.021484375). В чем проблема-то?
0.00(9) + 0.00(9), то есть в сумме верным будет уже один знак после запятой.
Это как складывать в терминах «плюс-минус лапоть» — в одном слагаемом у нас плюс лапоть, в другом — минус лапоть, в сумме получаем, что грешим уже на два лаптя.
А, ну формально да, я скорее про ожидания автора говорил.
И мне захотелось узнать, чему равна разность этих чисел. Имею право? Имею. Ждать мне некогда, матлабы и прочие инструменты слишком долго считают. Решил посчитать в двоичной арифметике, используя Стандарт для чисел с плавающей точкой. Набираю на клаве свои абсолютно точные числа 9876543210988,06 и 9876543210988,04. Поскольку все 15 цифр в числах верные, то и результат хочу получить с такой же точностью, т.е. с точностью до 15 значащих цифр.
Напечатал я одни числа, а на вход моего двоичного калькулятора поступают другие числа 9.876543210988060546875E12 и 9.8765432109880390625E12. Смотрю на сколько они отличаются от моих точных. И вижу, что погрешность первого числа составила 0,000546875, а второго 0,0009375. Многовато конечно, ну да ладно. Назад пути нет, процесс необратимый.
Залил я свои числа в калькулятор и на выходе получил ответ: 0.021484375. Да, что-то не очень. Я калькулятору — Ты что ж, гад, мне выдал? А он мне — Ничего не знаю, что компилятор мне дал, то я и посчитал. Посчитал, кстати, точно. Т.к. 9.876543210988060546875E12-9.8765432109880390625E12=0.021484375. Как ни крути, результат точный. И погрешность, ну строго по теории образовалась: 0,000546875+0,0009375=0.000484375
Кто же, думаю, виноват? Компилятор свое дело сделал точно, но числа получились приблизительными. Калькулятор посчитал точно, но ответ еще больше далек от правды. Что же делать? Присмотрелся к ответу, а там две цифры верные. Эврика? Надо отсечь лишние. Как, да просто округлить надо! А как это сделать, это совсем другая история.
Мы имеем 2 числа. Они абсолютно точныеЧисло само по себе не может быть точным. Число 3.141592666 — точное или неточное?
Для калькулятора — это точное число
С чего Вы это взяли? Когда у нас есть число с плавающей точкой, логично считать, что его погрешность ±половина последнего известного разряда. Так во всех расчётах делают, почитайте хотя бы Брадиса.
максимально точно сделать вычисления, не внося в них, по возможности, больших искажений
Надо отсечь лишние. Как, да просто округлить надо!
Я вижу противоречие, или мне кажется? ;)
Отсекая лишние цифры («мусор») точность повышается.
Неплохо так ;) Двоемыслие айтишника?
— Нутром чую, Петька, будет 1 литр, до доказать не могу
Вы так и не привели пример задачи, которая плохо, неточно решается со стандартным округлением и хорошо, точно — с нестандартным.
Как, да просто округлить надо!
Так чем вас стандартное округление-то не устраивает?
1. Предложен альтернативный известному алгоритм округления десятичных чисел в двоичном коде. Он работает.
Возражений не?
2. Десятичное округление десятичных чисел в двоичном коде может повысить точность вычислений. Приведен конкретный пример.
Обоснованных аргументов против этого факта пока высказано не было.
3. Вопрос -А на «хрена» это нужно?
См. п.2.
4. Чем меня не устраивает стандартная функция округления?
Если она вас устраивает, значит вы не сталкивались с задачами, где она облегчает жизнь. Пользуйтесь стандартной. Но реализовать стандартную функцию в железе затратно.
Он не альтернативный. Математически он тот же самый. Именно поэтому и вопрос — почему вы говорите, что стандартное округление как-то неправильно работает.
Это не доказано, пример не приведен. Я у вас его несколько раз уже просил, вы уходите от ответа. В примере выше вы пишете, что ответ должен быть 0.02, но он и так 0.02.
См. п.2.
Так я об этом и спрашиваю. И другие вас тоже об этом спрашивают. В каких конкретно задачах ваше округление "облегчает жизнь", а стандартное "не облегчает"?
Но реализовать стандартную функцию в железе затратно.
Почему "умножение + сложение + деление" вдруг стало затратнее "возведение в степень + умножение + условие + умножение + условие + деление + сложение + умножение"? Вычисление числа разрядов и возведение 10 в эту степень я, так и быть, не учитывал.
Согласно Стандарту обмен операндами в компьютере производится через внутренний формат обмена в 32- разрядном слове. Чтобы сохранить промежуточный результат в массиве, надо число double преобразовать в float.
Пусть у нас есть число в double:
1.11001101001010110010100 10111110110001000100110110001*2^40 и нам надо его запомнить с минимальной погрешностью.
Если округлить это число до 24 значащих двоичных цифр с погрешностью <0.5ulp, мы получим число 1.11001101001010110010101 *2^40
Десятичный эквивалент этого числа, который будет записан в формат обмена, будет:
11100110100101011001010100000000000000000.000=1980704096256.
Для лучшего восприятия я числа представляю в произвольном масштабе. При желании их можно нормализовать.
Нас интересует точность представления, равная 7 десятичным цифрам. Т.е., мы хотели бы, чтобы в памяти хранилось число 1980704000000. Тогда погрешность десятичного округления была бы <=0.5ulp, но уже десятичного ulp. Двоичный эквивалент числа 1980704000000 в формате double равен 111001101001010110010100 01000100000000000. Или округленное до 24 значащих цифр это число будет равно 111001101001010110010100*2^17. Это число ближайшее к правильно округленному числу 1980704000000 и как мы видим оно отлично от правильно округленного в двоичной арифметике первичного двоичного числа.
Таким образом, чтобы минимизировать потери, перед записью в формат обмена, двоичное число double должно быть правильно преобразовано к двоичному числу, которое должно являться представимым числом, ближайшим к правильно округленному десятичному числу.
При большом массиве обрабатываемых чисел использовать для округления функцию atof очень затратно. Конечно, лучше всего разделить число 1980704096256, в нашем случае на 10^6, округлить, а затем снова преобразовать во float для записи в память. Но как догадаться, что нужно разделить именно на 6? В моем алгоритме эта задача решена.
Вопрос не в 64 или 32 словах обмена.
Процессор, как правило, вычисляет в расширенном формате, а затем пакует в более компактный. Для 64-х разрядных, это 80- битные и даже 128-битные операционные регистры. Но потом все равно приходится паковать. А именно здесь собака и порылась. Я тут выше уже давал ссылки на последние работы по этой проблеме. Пока то, что предлагается, ну крайне громоздко.
Согласно Стандарту обмен операндами в компьютере производится через внутренний формат обмена в 32- разрядном слове.
Что за стандарт? Как он применяется на 64-битной архитектуре? Про 16-битную и 8-битную (микроконтроллеры, ага) даже боюсь заикаться.
Чтобы сохранить промежуточный результат в массиве, надо число double преобразовать в float.
Не надо так делать.
Согласно Стандарту обмен операндами в компьютере производится через внутренний формат обмена в 32- разрядном слове. Чтобы сохранить промежуточный результат в массиве, надо число double преобразовать в float.
В таких утверждениях надо приводить ссылки на тот стандарт, который вы имеете в виду, желательно с указанием цитаты.
Я в этом сомневаюсь. Если бы это было так, тип double был бы бесполезен. Представьте, что они бы в integer преобразовывались посередине вычислений.
Поэтому дальнейшие ваши рассуждения ложны, к происходящему в программе они не имеют никакого отношения.
Если вы будете вручную конвертирвать из double во float и обратно с превышением разрядной сетки float, значит у вас плохо написанная программа, а плавающая точка тут ни при чем.
Т.е., мы хотели бы, чтобы в памяти хранилось число 1980704000000.
Значит вы неправильно выбрали инструмент, потому что там 30 значащих цифр, а во float влазит 24. А в double это значение нормально влазит. Значит при использовании double оно округлится так, как нужно.
При большом массиве обрабатываемых чисел использовать для округления функцию atof очень затратно.
Так и не надо ее использовать для округления, она в моих примерах используется для ввода данных. Округление это floor(a * multiplier + 0.499...) / multplier (константа зависит от используемого типа float или double).
Конечно, лучше всего разделить число 1980704096256, в нашем случае на 10^6, округлить, а затем снова преобразовать во float для записи в память. Но как догадаться, что нужно разделить именно на 6? В моем алгоритме эта задача решена.
Посчитать значащие цифры и отнять сколько надо. Алгоритм округления и алгоритм подсчета значащих цифр это разные алгоритмы. Ваше достижение в том, что вы собрали 2 алгоритма вместе? Ну поздравляю, другие программисты тоже так умеют.
В таких утверждениях надо приводить ссылки на тот стандарт, который вы имеете в виду, желательно с указанием цитаты.
IEEE Standard for Floating-Point Arithmetic (IEEE 754). Разделы: «Extended and extendable precision formats» и «Interchange formats».
Значит вы неправильно выбрали инструмент, потому что там 30 значащих цифр, а во float влазит 24. А в double это значение нормально влазит. Значит при использовании double оно округлится так, как нужно.
Ну, во-первых, в числе 1980704000000= 1.980704*10^13 всего 7 значащих десятичных цифр, которые гарантированно могут быть представлены в 24 разрядной мантиссе float с точностью <=0.5ulp (десятичной). А во-вторых, формат doable гарантированно может представить 15 десятичных цифр (где-то, кажется вы сами об этом упоминали). Так что число 1.980704*10^13 гарантированно «влазит» в float с указанной погрешностью и точно, как бы это вас ни коробило, в формат doable. Но если взять числа с большей экспонентой, например число 1*10^30, то оно уже и в doable не вместится.
Посчитать значащие цифры и отнять сколько надо.
У вас в формате double записано число 1.0110101111001100010000100100111111101011011110010111*2^140. Посчитайте сколько значащих десятичных цифр в этом числе и округлите до 3 значащих цифр. На основании того, что вы свои расчеты выполняете с точностью до 3 значащих цифр, а остальные для вас являются ложными, согласно теории приближенных вычислений.
Ваше достижение в том, что вы собрали 2 алгоритма вместе?
Что вы имеете ввиду? Какие 2 алгоритма я собрал вместе? Подскажите. Честное слово, я не нарочно:).
Согласно Стандарту обмен операндами в компьютере производится через внутренний формат обмена в 32- разрядном слове.
Там нет такого утверждения.
For the exchange of binary floating-point numbers, interchange formats of length 16 bits, 32 bits, 64 bits, and any multiple of 32 bits ≥128 are defined
For the exchange of decimal floating-point numbers, interchange formats of any multiple of 32 bits are defined.
— эти фразы переводится иначе.
Разделы: «Extended and extendable precision formats» и «Interchange formats»
Там нигде не написано, что 64-битный double преобразуется в 32-битный float.
Ну, во-первых, в числе 1980704000000= 1.980704*10^13 всего 7 значащих десятичных цифр, которые гарантированно могут быть представлены в 24 разрядной мантиссе float
Не могут.
1 9 17 25 30 33 41
11100110 10010101 10010100 01000100 00000000 0
^Там умножается на степень двойки, а не десятки, поэтому число ненулевых десятичных цифр нерелевантно.
А во-вторых, формат double гарантированно может представить 15 десятичных цифр (где-то, кажется вы сами об этом упоминали).
Ну я так и сказал — в double оно нормально влазит. Но никакого "гарантированно «влазит» в float" там нет (см. предыдущий пункт).
Посчитайте сколько значащих десятичных цифр в этом числе
Как вам уже сказали, число значащих цифр, которым можно доверять, определяется методикой измерений и передается вместе с данными. В одном случае в этом значении может быть погрешность в единицы, в другом в тысячные доли. Число значащих цифр результата, до которых имеет смысл округлять, вычисляется по этой дополнительной информации. У вас оно вообще вводится пользователем.
Я там немного неправильно написал, да. Просто "отнять сколько надо" вряд ли получится.
Что вы имеете ввиду? Какие 2 алгоритма я собрал вместе?
Вы выдаете определение числа значащих цифр за преимущество своего алгоритма. Но это другой алгоритм, с алгоритмом округления он никак не связан. Кстати, тут вообще не очень понятно, что вы называете "задача решена". То, что число значащих цифр задается пользователем?
Там нигде не написано, что 64-битный double преобразуется в 32-битный float.
Я не могу здесь пересказывать вам стандарт IEEE754. Я дал ссылку на Wiki… Там можно найти нужную литературу.
Не могут.
Могут. Десятичное 1.980704*10^13 преобразуется в
1.980703965184E12, в котором первые 7 цифр с погрешностью <=0.5ulp дают число 1.980704.
У вас оно вообще вводится пользователем.
Естественно, кто кроме пользователя владеет этой информацией. Откуда машине знать до какого количества десятичных цифр надо округлять.
Вы выдаете определение числа значащих цифр за преимущество своего алгоритма.
Да, по другому эта задача не решается так просто.
Кстати, тут вообще не очень понятно, что вы называете «задача решена»
Решена, поскольку очень просто округляет любое десятичное число в двоичном коде до нужного пользователю количества десятичных цифр.
Я не могу здесь пересказывать вам стандарт IEEE754. Я дал ссылку на Wiki… Там можно найти нужную литературу.
Его не надо пересказывать. Надо привести одну цитату, подтверждающую ваши слова. Судя по тому, что вы уходите от ответа, вы сами ее найти не можете. В стандарте нет такого утверждения, потому что иначе вычисления в double не работали бы.
Посылать туда не знаю куда это неуважение к собеседнику.
Десятичное 1.980704*10^13 преобразуется в 1.980703965184E12
Вы писали "мы хотели бы, чтобы в памяти хранилось число 1980704000000". Если нас устраивает отклонение в некоторых пределах, то надо так и писать, но в этом случае подходят оба варианта.
Решена, поскольку очень просто округляет любое десятичное число в двоичном коде до нужного пользователю количества десятичных цифр.
Но это задача и в моем примере решена. Пользователь введет число, программа вычислит степень 10 от этого числа. А после нормализации числа количество значащих цифр и цифр после запятой вообще отличается ровно на единицу. А раз printf умеет ее делать, значит и в своем коде можно сделать так же.
Еще раз. Вы утверждали "Десятичное округление десятичных чисел в двоичном коде может повысить точность вычислений". Я попросил у вас пример.
Изначальное число у нас было 1980704062856.605712890625.
Вы его округлили до 1980704000000, тем самым внесли отклонение на 62856.
Далее вы предлагаете внести отклонение еще на 34816 (1980704000000-1980703965184).
Каким образом это увеличивает точность?
Если мы хотим увеличить точность, надо брать ближайшее к исходному числу. Во float это 1980704096256 (ошибка 33400).
Именно поэтому оно и "отлично от правильно округленного в двоичной арифметике первичного двоичного числа". Потому что первичное двоичное число было совсем не 1980704000000.
А вот если первичное число взять 1980704000000, то оно работает именно так, как вы и ожидаете.
float a = atof("1980704000000");
printf("%.6f\n", a);
// 1980703965184.000000Надо привести одну цитату, подтверждающую ваши слова.
Я не могу привести одну цитату. Принцип двоичных вычислений представляет собой взаимосвязанный комплекс аппаратных и программных средств. Который базируется на принципах закрепленных в стандарте.
Стандарт определяет основные форматы ( 3.1.1 Formats ) представления двоичных и десятичных чисел. Сюда входит формат хранения и обмена данными (3.6 Interchange format parameters), который определяет разрядность компьютера. Для двоичных чисел приняты 3 основных формата 32, 64 и 128 разрядов. В этих словах могут храниться как целые числа, так и упакованные числа с плавающей точкой. Как двоичные так и десятичные. Определен также арифметический формат (arithmetic formats), который может как совпадать с базовыми форматами, так и иметь расширенный ( extended precision format) или расширяемый формат (extendable precision format). Последние форматы используются в арифметических вычислениях для повышения точности. Но после всех вычислений они снова упаковываются в формат обмена. Операционные регистры АЛУ всегда имеют бОльшую разрядность чем ячейки памяти, т.к. после распаковки восстанавливается виртуальная единица в нормализованном числе и добавляются сторожевые биты для повышения точности вычислений. Ну, действительно, развивать эту тему дальше, это еще одна статья в коментах.
Вы писали «мы хотели бы, чтобы в памяти хранилось число 1980704000000». Если нас устраивает отклонение в некоторых пределах, то надо так и писать, но в этом случае подходят оба варианта.
Как раз нас устроило бы если бы в память можно было записать точное значение 1.980704*10^13. Но, поскольку это число непредставимо в float, в результате мы получаем 1.980703965184E12.
А раз printf умеет ее делать, значит и в своем коде можно сделать так же.
А как работает printf вас устраивает? Тогда можно.
Изначальное число у нас было 1980704062856.605712890625.
Вы его округлили до 1980704000000, тем самым внесли отклонение на 62856.
Далее вы предлагаете внести отклонение еще на 34816 (1980704000000-1980703965184).
Каким образом это увеличивает точность?
Если при измерении вы получили результат 12.12345, а класс точности прибора 0.01, что нужно сделать с лишними цифрами? Округлить. В результате мы получаем более точное измерение или нет?
Также и в нашем случае, если мы хотим получить точность вычислений до 7 значащих цифр мы свое число должны округлить до 7 значащих цифр. Но, поскольку число не представимо в flooat, мы получаем ближайшее к точно округленному числу представимое число.
Если мы хотим увеличить точность, надо брать ближайшее к исходному числу. Во float это 1980704096256 (ошибка 33400).
Совершенно верно. Но в double хранится двоичное число с какой-то экспонентой и без преобразования в десятичное представление вы не можете точно сказать на что надо умножить и разделить это двоичное число. А моя программа может.
Операционные регистры АЛУ всегда имеют большую разрядность чем ячейки памяти
Эта фраза означает, что если есть 64-битная ячейка памяти типа double, то промежуточные вычисления будут в формате 128 бит. При чем тут 32 бита, которые имеют меньшую разрядность?
А как работает printf вас устраивает?
Прочитайте еще раз то, что я написал. И предыдущие сообщения этой части. Я писал про подсчет значащих цифр. После нормализации он отличается от числа после запятой на единицу. То есть если мы хотим округлить до 3 значащих цифр, это означает 2 цифры после запятой в нормализованном формате.
В результате мы получаем более точное измерение или нет?
Так это не точность вычислений, а точность измерений.
Я не уверен, что в метрологии это считается "более точным" значением, но теперь по крайней мере понятно, что вы имели в виду.
Также и в нашем случае, если мы хотим получить точность вычислений до 7 значащих цифр мы свое число должны округлить до 7 значащих цифр.
Вот исходное число 1980704062856 и было округлено до 7 значащих цифр. Никакой ошибки округлений здесь нет. Вы в одном случае приводите к float одно число, в другом другое, потому и результаты различаются.
Но в double хранится двоичное число с какой-то экспонентой и без преобразования в десятичное представление вы не можете точно сказать на что надо умножить и разделить это двоичное число. А моя программа может.
Ваша программа не может, она запрашивает эту информацию у пользователя.
Эта фраза означает, что если есть 64-битная ячейка памяти типа double, то промежуточные вычисления будут в формате 128 бит. При чем тут 32 бита, которые имеют меньшую разрядность?
Все промежуточные вычисления выполняются в более широком формате, а хранятся в памяти в базовом формате обмена. В 32-х разрядных машинах базовым является 32-х разрядное слово.
Прочитайте еще раз то, что я написал. И предыдущие сообщения этой части. Я писал про подсчет значащих цифр. После нормализации он отличается от числа после запятой на единицу. То есть если мы хотим округлить до 3 значащих цифр, это означает 2 цифры после запятой в нормализованном формате
О каком представлении числа вы говорите? О двоичном или десятеричном? Поскольку внутреннее представление это нормализованное двоичное, то посчитать цифры в нем, нет проблем. Но вам надо определить множитель для десятичного представления. Следовательно без printf вам не обойтись.
Вот исходное число 1980704062856 и было округлено до 7 значащих цифр. Никакой ошибки округлений здесь нет. Вы в одном случае приводите к float одно число, в другом другое, потому и результаты различаются.
Повторюсь еще раз. Число 1980704062856 является представимым в double числом. Представимым, значит точно представлено в выбранном формате. Но оно не представимо в формате float. В результате округления числа double до float мы получаем правильное округление двоичного числа, в соответствии с выбранным сценарием, прописанным в Стандарте. Мы получаем другое представимое число. И оно, не смотря на то, что двоичное округление было верным может не являться ближайшим.
Вот исходное число 1980704062856 и было округлено до 7 значащих цифр.
Вернемся к истокам. В результате неких вычислений вы получили число double:1.1100110100101011001010010111110110001000100110110001*2^40. Для нас это первичное число. Никакой информации кроме двоичной мантиссы и экспоненты мы не имеем. Чтобы посмотреть, что это в десятичном виде мы применяем printf. И видим 1980704062856.605712890625. Это первичное десятичное представимое число.
Но нас для расчетов вполне устраивает точность N=7 (или любая другая). Для этого первичное число надо округлить до 7 значащих цифр. В десятичной арифметике мы бы получили 1980704000000. Но оно непредставимо в float. Поэтому, максимум на что мы можем рассчитывать это на ближайшее к этому представимое число, которое можно сохранить в fljat.
А это 1.980703965184E12. В котором 7 первых цифр совпадают с погрешностью <=ulp с идеально округленным числом 1980704000000.
Ваша программа не может, она запрашивает эту информацию у пользователя
Еще раз повторюсь. Программа не знает с какой точностью вас интересуют вычисления. Эту точность надо задать.
а хранятся в памяти в базовом формате обмена
Вот есть 64-битный формат double, в нем значения в памяти и хранятся. Типы для этого и придумывают.
В 32-х разрядных машинах базовым является 32-х разрядное слово.
Из того, что 32-х разрядное слово базовое, никак не следует, что не-базовое 64-х разрядное использовать нельзя.
64-разрядные integer нормально считаются на 32-разрядной машине. А 32-разрядные прекрасно считались во времена 16-разрядного DOS. И 64-битные double тоже прекрасно считаются на 32-разрядной машине, с двойной точностью, без округления во float.
Вы возможно с компьютерной графикой путаете, там действительно оптимизировано для float. Даже если в коде будут double, матрицы графических преобразований все равно будут во float.
"Direct3D 10 supports several different floating-point representations. All floating-point computations operate under a defined subset of the IEEE 754 32-bit single precision floating-point behavior."
И оно, не смотря на то, что двоичное округление было верным может не являться ближайшим.
Не может. Исходное число 1980704062856, число 1980704096256 является ближайшим к нему (ошибка 33400).
Ваш вариант 1980703965184, у него отклонение от исходного 97672.
Следовательно без printf вам не обойтись.
printf работает не на магии, а по вполне конкретным алгоритмам. Эти же алгоритмы можно реализовать в своем коде без вызова printf.
А это 1.980703965184E12. В котором 7 первых цифр совпадают с погрешностью <=ulp с идеально округленным числом 1980704000000
Ну так стандартные средства так и округляют, там нет "отличного от правильно округленного в двоичной арифметике", как вы утверждаете.
Вот, берите, пользуйтесь.
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
double roundToSignificantDigits(double value, int nSignificantDigits)
{
int normalizationDegree = (int)floor(log10(fabs(value))); // or frexp * log2
int nDigitsAfterDotNormalized = nSignificantDigits - 1;
int nDigitsAfterDot = nDigitsAfterDotNormalized - normalizationDegree;
double multiplier = pow(10, nDigitsAfterDot);
value = floor(value * multiplier + 0.49999999999999994) / multiplier;
return value;
}
int main()
{
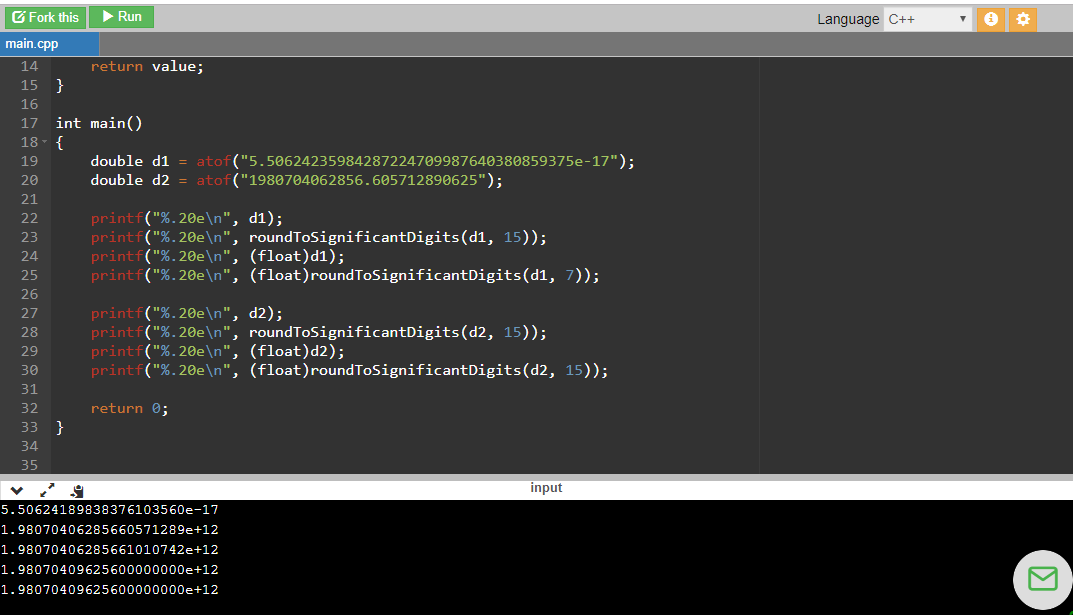
double d1 = atof("5.50624235984287224709987640380859375e-7");
double d2 = atof("1980704062856.605712890625");
printf("%.20f\n", d1);
printf("%.20f\n", roundToSignificantDigits(d1, 7));
printf("%.20f\n", (float)d1);
printf("%.20f\n", (float)roundToSignificantDigits(d1, 7));
printf("%.20f\n", d2);
printf("%.20f\n", roundToSignificantDigits(d2, 7));
printf("%.20f\n", (float)d2);
printf("%.20f\n", (float)roundToSignificantDigits(d2, 7));
// 0.00000055062423598429
// 0.00000055062420000000
// 0.00000055062423598429
// 0.00000055062417914087
// 1980704062856.60571289062500000000
// 1980704000000.00000000000000000000
// 1980704096256.00000000000000000000
// 1980703965184.00000000000000000000
return 0;
}log10 возвращает степень десятки, что эквивалентно степени 10 для нормализации (и числу десятичных знаков в числе для значений больше 1). Вы это вычисляете через e*0.301. Округляем всегда в меньшую сторону, то есть отрицательные значения округляются в минус бесконечность (0.99 должно стать 9.9, то есть степень -1).
Нормализованное число имеет дробную часть от 1 до 10, значит до запятой всегда одна цифра, значит число знаков после запятой на 1 меньше.
Вычитаем и получаем необходимое число знаков после запятой в исходном ненормализованном числе.
Округляем до него — умножить на соответствующую степень, округлить до целых, поделить обратно.
К float всегда приводим в конце вычислений. Если везде заменить double на float, то результаты другие, но и ваша программа выдает такие же.
Округление десятичного числа с плавающей запятой — тривиальная задача, если известна его экспонента и что число — нормализованное. Проблема заключается в нахождении значения десятичной экспоненты. Функция frexp в моем алгоритме просто считывает значение двоичной экспоненты e в числе double. Не знаю, насколько это легко выполнить программно, но аппаратно это осуществляется за 1 такт. Для определения десятичной экспоненты осталось вычислить floor(e*double(value*0.301)). Думаю, это реализовать проще, чем вычислить log 10(value). А что вы думаете?
Так вот, проблема в том, что до одного и того же числа можно округлить разные числа. Например, два double — числа 5.50624245984287807511338305951E-17и 5.50624155984287824709987743381E-17, округленные до 14 и менее значащих цифр будут иметь одно и то же значение. (Я специально увеличил |значение| экспоненты). Так, округленное до 7 значащих цифр наше число, это 5.506242. Опять же, в десятичной арифметике, ни каких проблем здесь не возникает. Берем и округляем, если вычислили десятичную экспоненту. Но в двоичном представлении все гораздо сложнее.
Возьмем число 5.50624245984287807511338305951E-17. Его двоичное представление будет таким 1.1111101111011100011110010110010011010000110111101111*2^-55.
Мы знаем, что в мантиссу float можно записать 24 бита. Округляем наше double-число до 24 значащих цифр с погрешностью <=0.5ulp. Получим 1.11111011110111000111101*2^-55= 5,5062425601282510780228041102902e-17≈5,506243. В результате правильного округления двоичного числа double с погрешностью <0.5 ulp мы получили округление его десятичного эквивалента c погрешностью>1ulp. Ближайшим же к правильно округленному десятичному числу будет float-число 5.50624189838376103560066421316E-17.
Думаю, это реализовать проще, чем вычислить log 10(value). А что вы думаете?
Это проще, но я там и написал, что можно и так считать. Дело же в остальном алгоритме.
Ближайшим же к правильно округленному десятичному числу будет float-число 5.50624189838376103560066421316E-17
Смотрите, если вы в вашей программе будете использовать float, то она тоже округлит неправильно, будет 5.5062428910004961e-17.
Если же использовать double и округлять его до разрядности float, меняя тип на float после вычислений, то стандартные средства и так округляют правильно.
double v = atof("5.50624245984287807511338305951E-17");
printf("%.29e\n", (float)roundToSignificantDigits(v, 7));
// 5.50624189838376103560066421316e-17Дело же в остальном алгоритме.
Да нет, квинтэссенция моего алгоритма именно в том и состоит, что по двоичному doable определяется десятичное значение экспоненты. Когда это значение определено, дальше преобразования идут по стандартному алгоритму десятичной арифметики. Когда вы применяете функцию atof, вы в ней задаете десятичное значение экспоненты, вводя ее при печатании вручную. Но в doable может храниться произвольная двоичная экспонента для двоичного числа, десятичное значение которого вам не известно…
Когда вы применяете функцию atof
atof это аналог вашего cin>>x. Она используется только для ввода данных, к округлению она отношения не имеет.
Еще раз повторю. В моей программе можно убрать atof и использовать вместо него cin>>v, а вместо printf использовать cout<<v. Функция округления roundToSignificantDigits() принимает и возвращает тип double.
#include <iostream>
#include <iomanip>
#include <math.h>
using namespace std;
double roundToSignificantDigits(double value, int nSignificantDigits)
{
int e;
frexp(value, &e);
int normalizationDegree = (int)floor(e * 0.301);
int nDigitsAfterDotNormalized = nSignificantDigits - 1;
int nDigitsAfterDot = nDigitsAfterDotNormalized - normalizationDegree;
double multiplier = pow(10, nDigitsAfterDot);
value = floor(value * multiplier + 0.49999999999999994) / multiplier;
return value;
}
int main()
{
double v;
cout << "Input value: ";
cin >> v;
cout << setprecision(30);
cout << v << "\n";
cout << roundToSignificantDigits(v, 7) << "\n";
cout << (float)v << "\n";
cout << (float)roundToSignificantDigits(v, 7) << "\n";
// 5.50624245984287807511338305951e-17
// 5.50624200000000031759065934773e-17
// 5.50624256012825107802280411029e-17
// 5.50624189838376103560066421316e-17
return 0;
}Все, больше вам ничего не известно. Как это сделать без конвертации этого числа в десятичный код стандартной программой округления?
Умножение на степень десятки, округление до целого, деление обратно.
Я же привел программу без atof, она работает, действия для вычисления степени там написаны, назначение переменных отражено в их названии.
Умножаем степень двойки на коэффициент 0.301..., получаем степень десятки самого числа. Отнимаем число значащих цифр минус 1, получаем на какую степень десятки надо разделить, чтобы использовать округление до целых. Если поменять слагаемые местами, получим, на какую степень десятки надо умножить.
Вы взяли мой алгоритм, один к одному его переписали и выдали его за свой.
Я написал алгоритм, который описан в этом комментарии ("умножение числа и последующее после округления деление") и встречается много где в интернете (1, 2, 3, 4).
Если это то же самое, что написали вы, тогда непонятно, почему вы говорите, что что-то где-то неправильно округляется. То есть мы возвращаемся к изначальному вопросу, который вам и задавали — что вас не устраивает в существующих средствах?
Может быть вы мне тогда объясните, зачем вы применили эту функцию -(int)floor(e * 0.301)?
Я же написал — "получаем степень десятки самого числа". Можно через десятичный логарифм, можно через двоичный, умноженный на коэффициент. Математически они эквивалентны. Через десятичный логарифм в интернете встречается чаще, так как в других языках низкоуровневых функций типа frexp может не быть.
И дадите ссылочку на стандартный алгоритм, где она используется.
Я написал алгоритм, который описан в этом комментарии
В этом коментарии нет алгоритма округления десятичного числа представленного двоичным кодом.
(«умножение числа и последующее после округления деление») и встречается много где в интернете (1, 2, 3, 4).
Вы правы, алгоритм «умножение числа и последующее после округления деление» много раз встречается в интернете. Только в ваших ссылках я насчитал более 20 алгоритмов округления. Но, «стандартного» не обнаружил.
что вас не устраивает в существующих средствах?
Под средствами вы понимаете множество существующих алгоритмов или набор стандартных функций?
Можно через десятичный логарифм, можно через двоичный, умноженный на коэффициент. Математически они эквивалентны. Через десятичный логарифм в интернете встречается чаще,
Вы мне дали ссылку на поисковую страничку google и предлагаете просмотреть все ссылки, чтобы убедиться, что «Через десятичный логарифм в интернете встречается чаще». Но почему-то на страницах, которые вы указали в предыдущих 3-х ссылках я не встретил ни одного алгоритма использующего этот способ.
Что касается «можно через двоичный, умноженный на коэффициент.» Но, что-то я тоже не нашел ни одного алгоритма, кроме моего и чудесным образом «вашего», где бы использовался такой способ определения коэффициента.
Я написал алгоритм… Если это то же самое, что написали вы, тогда непонятно, почему вы говорите, что что-то где-то неправильно округляется.
Вы написали программу по моему алгоритму. Но дьявол кроется в деталях.
Вы эту фразу имеете ввиду?
Это высказывание моего оппонента. Здесь имелось ввиду, наверное, десятичный логарифм двойки. По крайней мере, именно в этом смысле я воспринял его вольное высказывание. Что же касается равенства lbX=logX, то однозначно это неверно.
В этом коментарии нет алгоритма округления десятичного числа представленного двоичным кодом.
Нет такого термина "десятичное число, представленное двоичным кодом". Есть просто число, которое может быть представлено в десятичной, двоичной, римской, или еще какой-то системе счисления. В формате double используется двоичная система счисления, никакой десятичной там нет, поэтому и "округлять десятичное число" нельзя. Десятичная запись в приведенных в этом обсуждении программах присутствует только в строках, при вводе и выводе, в виде ASCII-символов, где цифра 1 представлена кодом 0x31.
Только в ваших ссылках я насчитал более 20 алгоритмов округления. Но, «стандартного» не обнаружил.
Нет там разных алгоритмов. Все реализации описываются выражением "умножить, округлить до целого, поделить". Потому он и стандартный.
Под средствами вы понимаете множество существующих алгоритмов или набор стандартных функций?
Я подразумеваю те алгоритмы и их реализации, которые решают задачу округления числа с плавающей запятой до N десятичных знаков после запятой либо значащих.
Вы мне дали ссылку на поисковую страничку google и предлагаете просмотреть все ссылки
Я дал ссылку на результаты со stackoverflow.com, чтобы показать, что задача округления встречается в разных языках, и не во всех из них есть функция frexp.
Но почему-то на страницах, которые вы указали в предыдущих 3-х ссылках я не встретил ни одного алгоритма использующего этот способ.
Потому что вычисление степени десятки и округление это разные алгоритмы. О чем я вам уже говорил. Можно вычислять степень десятки не для округления, или делать округление по степени десятки просто введенной пользователем.
1,2 и 4 ссылки относятся к округлению до целого, в 3 степень десятки задается константой в коде примеров.
А ссылка на страничку google относится именно к теме данной статьи — округление до N значащих цифр. И если у вас появилась такая задача, вам надо было сначала поискать информацию, проверить существующие способы, и только если они вас чем-то не устраивают, написать свой, и указать в статье, чем именно не устраивают.
Но, что-то я тоже не нашел ни одного алгоритма, кроме моего и чудесным образом «вашего», где бы использовался такой способ определения коэффициента.
Потому что в большинстве случаев используется десятичный логарифм, потому что не во всех языках есть функция frexp. Что тут непонятного? На той страничке google десятичный логарифм используется почти в каждой ссылке.
Их не надо искать, я в комментарии специально дал еще 2 ссылки, в них используется константа 0.301.
Вы написали программу по моему алгоритму.
Нет, я написал программу, округляющую число до N значащих десятичных знаков. В качестве примеров я использовал информацию из интернета, а не из вашей статьи, и эта информация появилась там гораздо раньше, чем ваша статья. При этом результаты она дает такие же, как и ваша программа. Не приписывайте себе изобретение алгоритма округления.
Нет такого термина «десятичное число, представленное двоичным кодом». Есть просто число, которое может быть представлено… двоичной или еще какой-то системе счисления.Вы не находите, что «нет» и «есть» здесь взаимоисключающие утверждения?
Нет там разных алгоритмов. Все реализации описываются выражением «умножить, округлить до целого, поделить». Потому он и стандартный
Ни одна из этих операций (умножить, округлить...) не является стандартной. Каждая может быть реализована множеством способов (алгоритмами). Все зависит от процессора. Также и реализация «умножить, округлить до целого, поделить» имеет множество вариантов даже в рамках одного языка. А раз так, у каждого есть свои достоинства и недостатки. Стандартной реализации нет.
Я подразумеваю те алгоритмы и их реализации, которые решают задачу округления числа с плавающей запятой до N десятичных знаков после запятой либо значащих.
Как же так, если
В формате double используется двоичная система счисления, никакой десятичной там нет,
Потому что вычисление степени десятки и округление это разные алгоритмы.
Впрочем, как умножение, возведение в степень и проч. Собранные вместе определенным образом эти алгоритмы образуют алгоритм округления десятичного числа, представленного в двоичной системе.
На той страничке google десятичный логарифм используется почти в каждой ссылке.
Приведу вам ваши же слова:
Надо привести одну цитату, подтверждающую ваши слова. Судя по тому, что вы уходите от ответа, вы сами ее найти не можете.
Что является аргументом этих десятичных алгоритмов? И откуда он берется?
Нет, я написал программу, округляющую число до N значащих десятичных знаков. В качестве примеров я использовал информацию из интернета, а не из вашей статьи, и эта информация появилась там гораздо раньше, чем ваша статья. При этом результаты она дает такие же, как и ваша программа.
Вся информация для любого алгоритма естественно имеется, в том числе и в интернете. Вопрос, как распорядиться этой информацией. Вы, почему-то, для доказательства стандартности алгоритма округления, привели свою программу, в которой использовали frexp из моей программы, а не десятичный логарифм, который выполняет ту же задачу в широко известных стандартных алгоритмах округления. Хотелось бы увидеть хоть одну программу округления, где бы использовалась функция frexp.
Вы не находите, что «нет» и «есть» здесь взаимоисключающие утверждения?
Не нахожу, иначе бы не писал такое утверждение. Сформулируйте противоречие словами, пожалуйста.
Ни одна из этих операций (умножить, округлить...) не является стандартной.
При чем тут отдельные операции? Я говорю про их совокупность, выполнение в определенном порядке с определенными параметрами.
Каждая может быть реализована множеством способов (алгоритмами)
Стандартной реализации нет.
Вы путаете алгоритм и его реализацию. Под словом "алгоритм" обычно подразумевается абстрактное описание действий без деталей реализации.
Я не говорил именно про стандартную реализацию, я говорил про стандартные средства. Перестаньте играть словами, пожалуйста.
Как же так, если
Сформулируйте противоречие словами, пожалуйста.
В формате double никакие десятичные знаки не используются, там только двоичные биты.
Собранные вместе определенным образом эти алгоритмы образуют алгоритм округления десятичного числа, представленного в двоичной системе.
Вы сказали, что в предыдущих ссылках не встретили десятичного логарифма. Я объяснил почему — потому что собрал свою программу из отдельных независимых частей. Какое отношение к этим фактам имеет информация о том, что образуют эти алгоритмы вместе? Ну допустим образуют, в чем возражение-то?
Те, о которых идет речь в данном обсуждении, образуют "алгоритм округления числа до N значащих цифр при представлении этого числа в десятичной системе счисления". И этот алгоритм присутствует в разных реализациях на разных языках по той ссылке, которую вы назвали "страничка google". Также я указал ссылки, из которых взял отдельные части — округление до целого и округление до N десятичных знаков после запятой. Следовательно, ваше утверждение "вы переписали мой алгоритм" неверно. Я переписал то, что уже есть в интернете.
Надо привести одну цитату, подтверждающую ваши слова
Вы сказали "я не нашел ни одного алгоритма, где бы использовался такой способ определения коэффициента".
Я дал вам ссылку, где десятичный логарифм присутствует практически в каждом результате поиска.
Какую еще цитату вам надо? Что должно быть в этой цитате помимо того, что выдает Google?
Что является аргументом этих десятичных алгоритмов? И откуда он берется?
Извините, я не понял этот вопрос. Берется из ответов, потому что авторы ответов на stackoverflow его написали в своем коде. Что туда передается, можно посмотреть в этом же коде. А именно — абсолютное значение числа, которое надо округлить.
Вы, почему-то, для доказательства стандартности алгоритма округления, привели свою программу, в которой использовали frexp из моей программы, а не десятичный логарифм
Ну здрасьте-приехали. Вот в этом комментарии я написал код с десятичным логарифмом. Вот здесь вы заметили, что наверно лучше использовать frexp, и далее сделали несколько утверждений, показывающих, что вы не до конца понимаете работу моей программы (например, про роль atof), поэтому я заменил на frexp, чтобы вам было понятнее.
А вот здесь вам указывают на то, что это математически эквивалентные вычисления (переход к новому основанию). Еще раз, log10(x) и frexp(x, &e); e * log10(2); вычисляют одно и то же, поэтому никаких вычислений, свойственных только вашей программе, тут нет.
Хотелось бы увидеть хоть одну программу округления, где бы использовалась функция frexp.
А на тех языках, где ее нет, вы предлагаете вообще не округлять? Еще раз, она слишком низкоуровневая и аппаратно-зависимая, поэтому вместо нее используют десятичный логарифм числа.
старичок. — Точный электронно-механический прибор для отвечания на любые
вопросы, а именно — на научные и хозяйственные.
Изобретатель наворотил кучу наукообразного текста (даже сайт есть), цитирует не по делу сам себя и непонятные источники, и одновременно
путается в школьной математике и отказывается привести доказательства применимости изобретения в народном хозяйстве.
Предлагаю дуэль.Сражаться будем не языком, а цифрами. Согласны?
Если да — вот мои условия.
Вы выбираете одну, самую стандартную программу из тех, что вы здесь предлагали или из тех, что найдете в интернете. Но одну, и самую стандартную:)!
И мы будем (стреляться) округлять те числа, которые предложим друг-другу. Каждому дается три выстрела. Оружие в процессе дуэли не менять. Согласны?
Или и дальше будем соревноваться в словесной изящности?
Задача должна быть, во первых, осмысленной. Само по себе округление бессмыссленно, но, вы утверждаете, что правильное (tm) округление повышает точность расчетов. Поэтому расчетов должно быть много, и результат должен быть верифицируемый. Ряд Тейлора не особо показателен, он слишком быстро сходится. Предлагаю двойное обращение матрицы, повторенное раз 1000 (чтобы погрешности расчетов накапливались) ;).
Берем стандартную картинку 512*512, конвертим в grayscale, заполняем матрицу. Прогоняем 1000 раундов обращения, считаем попиксельно среднеквадратическое отклонение от оригинальной матрицы.
Или балабол ;)
ЗЫ: Преобразование Фурье тоже должно подойти.
ЗЗЫ: А батл по спортивному округлению пусть проводится в более подходящем месте (4 класс средней школы) :D
Вы выбираете одну, самую стандартную программу из тех, что вы здесь предлагали
И мы будем (стреляться) округлять те числа, которые предложим друг-другу.
Так мы же уже это сделали. Я же округлил своей программой все числа, которые вы давали, она дает те же результаты, что и ваша программа. Программа и 2 числа в этом комментарии, еще 1 в этом. Также вы можете ее запустить сами и ввести туда любые числа. Так что я согласен и уже выиграл)
Впрочем, можем еще одно число рассмотреть, если вы настаиваете, уже четвертое.
Ну одно да потому… Математически это одно и то же. Как выражения "2+2" и "4". Или "x2" и "x6/x4". Даже если у меня в программе где-то ошибка в вычислениях, и результаты различаются, это именно ошибка, а не намеренно написанный алгоритм.
Проверяйте ту, которая через log.
Даже если у меня в программе где-то ошибка в вычислениях, и результаты различаются, это именно ошибка, а не намеренно написанный алгоритм.Мы еще не начали, а вы уже оправдываетесь. Выберите ту стандартную программу, которая широко используется в интернете и которая 100% решает задачу десятичного округления двоичных чисел. Вы же мне столько ссылок давали.
Выберите ту стандартную программу, которая широко используется
printf ;)
Округление обычно используют при выводе, чтобы не захламлять бумагу/дисплей незначащими символами. И printf с этим справляется ;)
Мы еще не начали, а вы уже оправдываетесь
Как это не начали? Зачем же вы тогда все это спрашиваете?
Я сообщил вам это заранее, на случай если вы найдете какое-то отклонение, так как вы, судя по всему, не разбираетесь ни в программировании, ни в математике, и не сможете правильно оценить сами, является ли это неправильной работой алгоритма округления или случайной ошибкой в программе, которую я набросал за несколько минут, не рассчитывая ни на какие соревнования, и потому досконально ее не проверял. Математическое равенство указанных выражений от этого не меняется.
Выберите ту стандартную программу, которая широко используется в интернете
"Программа и 2 числа в этом комментарии"
"Проверяйте ту, которая через log"
вы, судя по всему, не разбираетесь ни в программировании, ни в математике, и не сможете правильно оценить сами,
Ну, что же вы меня все время роняете? С вашей помощью, думаю, разберемся.
Округляет ваша программа правильно, но только до 14 значащих цифр. А моя до 15 и в разы быстрее. Она рассчитана на железо.
Вы правильно сделали, что выбрали вариант с логарифмом, он все же проверен многократно. А моя программа, в вашем исполнении, страдает изъянами. Уж, извините.
Нет уж, вы говорите, что что-то не так, вот и показывайте, как вы запускали, что вводили, какие результаты получили, и какие они должны быть. Раз еще и про производительность начали говорить, то показывайте как замеряли производительность. А то я так тоже могу: ваша программа округляет до 13 цифр, и в 10 раз медленнее.
Никто вас не роняет, вы сами высказываете утверждения, не имеющие технического смысла или не соответствующие действительности. Я пропускал это или объяснял, в чем вы не правы, пока вы не начали меня поддевать.
Раз еще и про производительность начали говорить, то показывайте как замеряли производительность.Я уже ранее говорил и вы, вроде, не возражали, что считать в регистр двоичную экспоненту, которая хранится в готовом виде в коде числа double, а затем умножить ее на коэффициент, значительно проще, чем выполнить итеративный алгоритм вычисления логарифма. Мне кажется это очевидно.
Почему не в double? Как, по-вашему, должно выглядеть "выводить результат в double"?
В вашей программе я ввел nSignificantDigits=15, но получил округление только до 14 цифр.
Еще раз говорю, так проверки не делаются. Вы сами предложили проверять конкретно, вот и проверяйте конкретно — показывайте, какое конкретно число вводили, что конкретно получили, и что конкретно должно быть. Я не умею читать мысли.
Почему не в double? Как, по-вашему, должно выглядеть «выводить результат в double»Формат double, это формат двоичного числа с плавающей точкой. У него есть мантисса и экспонента. Так что это число должно выводиться — мантисса+экспонента, только в десятичном эквиваленте. А то, для экспоненты, скажем =1020, замучаешься искать значащие цифры на консоле. Или я не прав?
Я в вашей программе ничего не менял, кроме коэффициента nSignificantDigits=15, задающего точность. Поэтому ваше число double d1 = atof(«5.50624235984287224709987640380859375e-17»); если его округлить до 15 значащих цифр должно иметь 15 значащих цифр и должно быть равно 5.50624235984287. Но программа округляет его до 14 цифр и дает результат 5.5062423598429. Не спорю, правильный.
Так что это число должно выводиться
Подождите. Вы сказали "почему ваша программа выводит результат не в double, а в строку? Это что же, потом ее опять надо конвертировать в double?". Ваша программа тоже выводит результат в строку. cout<<xr преобразует число double в строку ASCII символов, потому что экран может выводить только строковые символы. cout<<setprecision(18)<<xr это аналог printf('%.17f', xr), о чем я уже говорил. Почему вашей программе можно выводить в строку, а моей нельзя?
Функция roundToSignificantDigits() принимает double и возвращает double. Результат типа double можно использовать потом в других вычислениях, или выводить на экран через printf или cout, или делать с ним что-то еще. Ни с какими строками она не работает, поэтому и конвертировать обратно в double ее результат не надо.
Но программа округляет его до 14 цифр и дает результат 5.5062423598429.
В моей программе, на которую я приводил ссылку, стоит вызов printf("%.20f\n", d1), поэтому выводить 13 знаков после запятой она ну никак не может.
Для вывода строки в виде "мантисса+экспонента", как вы хотите, там должно быть printf("%.20e\n", d1). На функцию округления числа это никак не влияет.
а затем умножить ее на коэффициент, значительно проще, чем выполнить итеративный алгоритм вычисления логарифма. Мне кажется это очевидно.
Вы дали конкретную оценку "в разы". Это не очевидно. В процессорах есть инструкции для вычисления логарифмов.
Итак, вскрытие показало следующее.
Для округления было взято число d1=5.50624235984287224709987640380859375e-17. Которое на консоль было выведено как 5.5062423598428724e-17.
Округленное до 15 значащих цифр это число должно быть равно 5.50624235984287e-17. Ближайшее к нему представимое число-double равно 5.5062423598428699579894231941E-17.
(Использовался калькулятор) На консоль выведено число 5.50624235984287E-17. Неправильно.
Число-double d1 преобразованное к float равно 5.50624222925600605681173416173E-17(См. на калькуляторе). На консоль выведено число 5.5062422292560061E-17. Правильно.
Округленное до 7 значащих цифр это число должно быть равно 5.062422E-17. Ближайшее к нему представимое число должно быть равно 5.06242211118537429118124926219E-17. На консоль выведено число 5.06241898383761E-17. Неправильно.
Вы решили в троллинг скатиться? Что вам непонятно во фразе "показывайте, как вы запускали"? Или во фразе "выводить 13 знаков после запятой моя программа не может"? Покажите конкретный код, который вы запускали. Полностью, который можно скомпилировать. Так же, как это делаю я. Потому что код это формальное доказательство.
Я не знаю, что за код вы взяли, и что там поменяли. Я вам говорил про код в этом комментарии. Он выводит с точностью до 20 знаков после запятой, причем в стандартной записи, а не в экспоненциальной, поэтому выводить то, что вы написали, он не может. Следовательно, вы проверяли какой-то свой код, и его результаты к моей программе не имеют никакого отношения.
Я внес изменения только те, что вы мне рекомендовали.
include <stdlib.h>
include <math.h>
double roundToSignificantDigits(double value, int nSignificantDigits)
{
int normalizationDegree = (int)floor(log10(fabs(value))); // or frexp * log2
int nDigitsAfterDotNormalized = nSignificantDigits — 1;
int nDigitsAfterDot = nDigitsAfterDotNormalized — normalizationDegree;
double multiplier = pow(10, nDigitsAfterDot);
value = floor(value * multiplier + 0.49999999999999994) / multiplier;
return value;}
int main()
{
double d1 = atof("5.50624235984287224709987640380859375e-17");
double d2 = atof("1980704062856.605712890625");
printf("%.20e\n", d1);
printf("%.20e\n", roundToSignificantDigits(d1, 15));
printf("%.20e\n", (float)d1);
printf("%.20e\n", (float)roundToSignificantDigits(d1, 7));
printf("%.20e\n", d2);
printf("%.20e\n", roundToSignificantDigits(d2, 15));
printf("%.20e\n", (float)d2);
printf("%.20e\n", (float)roundToSignificantDigits(d2, 15));
return 0;}
Тут проверял
#include <stdio.h>
int main(void) {
double d1 = atof("5.50624235984287224709987640380859375e-17");
double d2 = 5.50624235984287224709987640380859375e-17;
double d3 = 5.50624235984287224709987640380899999e-17;
printf("%.30e\n", d1);
printf("%.30e\n", d2);
printf("%.30e\n", d3);
if(d2 == d3) printf("Its a same!\n");
return 0;
}
0.000000000000000000000000000000e+00
5.506242359842872423179752009763e-17
5.506242359842872423179752009763e-17
Its a same!
Согласен, в ВАШЕЙ программе atof используется неправомерно. Строку мы вводим не с консоли, а задаем прямо в теле программы константой. Зададим наше число правильно.
include <stdlib.h>
include <math.h>
double roundToSignificantDigits(double value, int nSignificantDigits)
{
int normalizationDegree = (int)floor(log10(fabs(value))); // or frexp * log2
int nDigitsAfterDotNormalized = nSignificantDigits — 1;
int nDigitsAfterDot = nDigitsAfterDotNormalized — normalizationDegree;
double multiplier = pow(10, nDigitsAfterDot);
value = floor(value * multiplier + 0.49999999999999994) / multiplier;
return value;}
int main()
{
double d1 = 5.50624235984287224709987640380859375e-17;
double d2 = atof("1980704062856.605712890625");
printf("%.20e\n", d1);
printf("%.20e\n", roundToSignificantDigits(d1, 15));
printf("%.20e\n", (float)d1);
printf("%.20e\n", (float)roundToSignificantDigits(d1, 7));
printf("%.20e\n", d2);
printf("%.20e\n", roundToSignificantDigits(d2, 15));
printf("%.20e\n", (float)d2);
printf("%.20e\n", (float)roundToSignificantDigits(d2, 15));
return 0;}
Но результат тот же. И виновата в этом не ваша программа, а двоичная арифметика.
А вывод программы где, который у вас получился после ее запуска? Слушайте, слово "конкретно" означает именно "конкретно". То есть полностью. От начала до конца. Без недоговорок, без додумываний, без описания измненений на словах. Полностью воспроизводимый пример, доказывающий ваши слова. Программный код, ввод и вывод.
Вы утверждали "На консоль выведено число 5.50624235984287E-17".
Указанная вами программа выводит на консоль такие строки:
5.50624235984287242318e-17
5.50624235984286995799e-17
5.50624222925600605681e-17
5.50624189838376103560e-17
1.98070406285660571289e+12
1.98070406285661010742e+12
1.98070409625600000000e+12
1.98070409625600000000e+12Где среди них указанное вами число? Его там нет. Следовательно, вы врете. Или по ошибке запускали какой-то другой код. В любом случае, к программе, о которой я говорил, эти результаты отношения не имеют.
UPD: Код онлайн
Да не нервничайте вы так. И перестаньте бросаться словами — "вы врете". Мы просто разговариваем пока на разных языках. Я пытаюсь понять ваш язык. Попробуйте и вы понять о чем я говорю. Вы классный программист. Но речь идет о математике. Я запустил вашу программу, текст которой я вам привел выше. Могу повторить.
include <stdlib.h>
include <math.h>
double roundToSignificantDigits(double value, int nSignificantDigits)
{
int normalizationDegree = (int)floor(log10(fabs(value))); // or frexp * log2
int nDigitsAfterDotNormalized = nSignificantDigits — 1;
int nDigitsAfterDot = nDigitsAfterDotNormalized — normalizationDegree;
double multiplier = pow(10, nDigitsAfterDot);
value = floor(value * multiplier + 0.49999999999999994) / multiplier;
return value;}
int main()
{
double d1 = 5.50624235984287224709987640380859375e-17;
double d2 = atof("1980704062856.605712890625");
printf("%.20e\n", d1);
printf("%.20e\n", roundToSignificantDigits(d1, 15));
printf("%.20e\n", (float)d1);
printf("%.20e\n", (float)roundToSignificantDigits(d1, 7));
printf("%.20e\n", d2);
printf("%.20e\n", roundToSignificantDigits(d2, 15));
printf("%.20e\n", (float)d2);
printf("%.20e\n", (float)roundToSignificantDigits(d2, 15));
return 0;}
Запустив программу, я на консоле получил те числа, которые и привел выше. Где я вас в чем обманул? Вывести их другим способом я не умею. Скриншот прикрепить тоже. Я выписал их с консоли.
Еще раз говорю, проблема не в программе, а в двоичных числах, которые используются как эквивалент десятичных. Если в программе я допустил ошибку, исправьте. Если вы готовы, мы можем обсудить те числа, которые вы привели в этом коменте.
Округленные числа, приведенные вами выше: 5.50624235984287242318e-17
5.50624235984286995799e-17
Правильные. Есть числа, которые неправильно округляются и вашей программой и моей. Мы обсуждали это ранее.
Рассмотрим вторую группу чисел.
Округленное до 7 значащих цифр число 1980704062856.605712890625= 1.98070406285660571289e+12 равно 1.980704e+12. Запишите это число в doable и получите то же число 1.980704e+12. Т.е. это представимое число. В вашей программе оно округлено до 1.98070406285661010742e+12. Это правильно?
И перестаньте бросаться словами — "вы врете".
Это было намеренно. Чтобы показать один из вариантов, какие мысли вызывают ваши утверждения без доказательств.
Могу повторить.
Для оформления кода на C++ используются три обратные кавычки ```cpp если галочка Markdown установлена, и тег <source lang="cpp"> если нет. Закрываются они соответственно ``` и </source>.
Я не просил вас повторить текст программы. Я просил привести программу и ее вывод вместе в одном сообщении. Чтобы не выискивать по разным сообщениям, не уточнять и не додумывать, что вы хотели сказать.
Это на будущее. Для данного случая это уже не требуется, так как все равно уже понадобилось несколько сообщений для уточнения.
Запустив программу, я на консоле получил те числа, которые и привел выше. Где я вас в чем обманул?
Я это уже 2 раза повторил. В строке "5.50624235984287E-17" 14 знаков после запятой. В программе, которую вы привели, стоит printf("%.20e\n", d1) — вывод 20 знаков после запятой. Поэтому выводить 14 знаков этот код никак не может. Значит вы запускали какую-то другую программу.
Вывести их другим способом я не умею. Скриншот прикрепить тоже.
Я вам специально дал ссылку на онлайн редактор. Там именно тот код, который вы показываете. Нажмите там кнопку "Run". При запуске он выводит на консоль то, что говорю я. Раз вы не можете разобраться, что вы запускаете на своем компьютере, пишите пожалуйста код там, запускайте, проверяйте, и приводите ссылку здесь. Для получения ссылки там есть кнопка "Share".
Раз вы не можете разобраться, что вы запускаете на своем компьютере, пишите пожалуйста код там, запускайте, проверяйтеЯ не подвергаю сомнению работу вашей программы. Я верю числам, которые ваша программа выдает. Я говорю, что эти числа иногда имеют погрешность больше, чем можно получить, если использовать мой алгоритм. Доказательства я привел выше.
Я говорю, что эти числа иногда имеют погрешность больше, чем можно получить, если использовать мой алгоритм. Доказательства я привел выше.
Ну одно да потому. Вы не привели доказательства. В этих ваших якобы доказательствах вы утверждаете, что моя программа выводит некие числа с 14 знаками после запятой. Но моя программа не может их выводить, в ней задан вывод до 20 знаков. Значит вы запускали не мою программу, а какую-то другую. Возможно вы сделали это по ошибке, я не знаю, но факт в том, что 14 знаков после запятой она не выводит. А значит любые ваши доказательства касательно ее работы, где фигурируют числа с 14 знаками после запятой, неверны. Неверны, значит не относятся к ней, к ее работе, и ничего касательно нее не доказывают. Что вам здесь непонятно? Напишите, я еще подробнее объясню.
Я говорю, что эти числа иногда имеют погрешность больше, чем можно получить, если использовать мой алгоритм.
Я вам дал ссылку на онлайн редактор. Напишите пожалуйста там код, который подтверждает ваши слова. Чтобы я мог его запустить, и чтобы он выводил те результаты, о которых говорите вы.
Я вам дал ссылку на онлайн редактор. Напишите пожалуйста там код, который подтверждает ваши слова.Я ничего не менял в вашей программе. Как она вами была туда помещена, так я ее и запустил. На выходе программы получились те числа, которые вы привели в тексте вашего комента выше. Они полностью совпадают с теми, что получены в результате работы вашей программы. См. Скриншот
{kind=link}
Именно эти числа я и приводил в качестве доказательства своей правоты. Что я сделал не так?
Именно эти числа я и приводил в качестве доказательства своей правоты. Что я сделал не так?
Вот в этом комментарии вы писали "На консоль выведено число 5.50624235984287E-17. Неправильно." Но на консоль не выводится такое число, и ваш скриншот это подтверждает. Почему вы утверждали, что оно выводится, если оно не выводится?
Не уходите от ответа. Моя программа правильно выводит или нет?
Я вам уже сказал причину, почему вы их не нашли — frexp есть не во всех языках. И другую причину вам тоже сказали — округление до десятичных знаков в середине вычислений обычно не требуется, это потеря точности, округляют при выводе. Единственное отличие вашего алгоритма от тех, которые есть в интернете — вы вычисляете десятичный логарифм через двоичный. Я верю, что вы его разработали самостоятельно, но ничего нового в нем нет.
Поэтому, прежде чем конвертировать из double (или другого более широкого формата) в float оно должно быть сначала правильно округлено.
По поводу этого. При округлении double во float округление до десятичных знаков не нужно. Максимально близкий результат дает двоичное округление до 23 знаков мантиссы, для этого достаточно проверить 24-й бит. Пример я уже приводил — там где ошибка 33400.
Вы куда-то не туда переобуваетесь ;)
Начали с округления double, теперь решаете проблему потери точности преобразования double to float. Точность float как раз в районе 7 значащих цифр; чем поможет предварительное округление?
Желательно увидеть это в виде программы в онлайн дебаггере.
В результате некоторых вычислений вы получили какое-то double-число: 1.0011… 00011*2^123 (любое). Вам из него надо получить двоичное число, равное ближайшему к правильно округленному до 7 десятичных знаков десятичному числу.
Округление double (~15 значащих десятичных знаков) до 7 знаков вносит некую погрешность (7 знаков, грубо говоря). Разница между правильным и обычным округлением значительно (на несколько десятичных порядков) меньше этой погрешности. Не могу представить задачу, где допустимо внесение погрешности размером в 7 младших десятичных разрядов, и одновременно недопустима погрешность в 1 младший разряд.
"Если при измерении вы получили результат 12.12345, а класс точности прибора 0.01, что нужно сделать с лишними цифрами? Округлить. В результате мы получаем более точное измерение или нет?"
Результатом измерения этим прибором может оказаться любое значение из диапазона 12.0… 12.2 (если грубо). 12.12345 ничем не лучше 12.1. Отбрасывание "лишних" цифр повлияет на скорость обработки данных? На объем занимаемой памяти? Каким образом?
Отбрасывание «лишних» цифр повлияет на скорость обработки данных? На объем занимаемой памяти? Каким образом?
На точность. См. Действия над приближенными числами
А отбрасывание цыфр повышает или понижает точность? Или под термином "точность" подразумевается что-то другое? ;)
Отбрасывание цыфр повышает точность расчетов? (Да, Нет, Другой ответ)
Для десятичных чисел в двоичном коде другая ситуация. Изменение длинны двоичной мантиссы может приводить к потере точности десятичного числа, может повышать точность, а может и не менять ее. Повышение точности в смысле accuracy, т.е. близости к теоретическому результату мы и обсуждали в комментах выше.
Ну и пример того, когда десятичная точность не меняется при сокращении длинны мантиссы. Если число точное (exact) и представимо в мантиссе с p разрядами, то оно представимо и точно (exact) в мантиссе с p+n разрядами. Отсюда, усечение n разрядов двоичной мантиссы приводит к уменьшению precision, но exact и accuracy не меняются. Так, число 0.125 можно представлять 64-мя,24-мя или 3-мя значащими цифрами, его значение не изменится.
Если длинна мантиссы двоичного нормализованного числа не меняется, то любые арифметические преобразования не приводят к изменению точности p
sizeof(double) == sizeof(double), следовательно, не меняет.
Изменение длинны двоичной мантиссы может приводить к потере точности десятичного числа, может повышать точность, а может и не менять ее
При операциях с плавающей запятой sizeof(double) == sizeof(double), следовательно, длина двоичной мантиссы не меняется.
… Так, число 0.125 можно представлять 64-мя,24-мя или 3-мя значащими цифрами, его значение не изменится.
Встретить подобное число при расчётах с floating point — великая удача. Но формату float (double, long double) все равно, сколько внутри двоичных нулей (хоть и все) — от этого он не становится ни меньше, ни быстрее. А выполните деление точного 0.125 на точное 3, то, что получилось, умножьте на точное 3 — и результат уже неточный, так что сильно озабочиваться в двоичное округление нет никакого смысла. Точности в вычислениях это не добавит.
Проверить это утверждение очень легко. Сосчитайте с использованием округления то, что легко проверяется аналитически (sin(pi) через ряд), или сравнением (дважды обращенная матрица равна сама себе).
Проверить это утверждение очень легко. Сосчитайте с использованием округления то, что легко проверяется аналитически (sin(pi) через ряд), или сравнением (дважды обращенная матрица равна сама себе).
Вы жаждете, чтобы я сам себя «зарезал», а вы постояли в сторонке, а потом сказали — Ну, вот, что я говорил. Нет, батенька, потрудитесь сами. Получите результаты, правильно их интерпретируйте, а затем мы с вами их обсудим. ОК?
На обычном C это выглядит приблизительно так:
#include <stdio.h>
#include <math.h>
int main(void) {
double x=M_PI;
printf("calc sin(%.15e)\n",x);
double s = x;
int sign = 1;
int power = 1;
double c = x;
double f = 1;
for (power =3; power< 100; power = power +2)
{
sign = -sign;
c = c*x*x;
f = f*(power-1)*power;
s = s + sign*(c/f);
printf("%d; %.15e\n",power, s);
}
return 0;
}
Запустил на repl.it/languages/c
clang version 7.0.0-3~ubuntu0.18.04.1 (tags/RELEASE_700/final)
clang-7 -pthread -lm -o main main.c
./main
calc sin(3.141592653589793e+00)
3; -2.026120126460176e+00
5; 5.240439134171684e-01
7; -7.522061590362350e-02
9; 6.925270707504691e-03
11; -4.451602382096569e-04
13; 2.114256755795548e-05
15; -7.727858898747279e-07
17; 2.241951027282289e-08
19; -5.289187244469688e-10
21; 1.034774181384365e-11
23; -1.707299030884088e-13
25; 2.292021495202086e-15
27; -1.405396847913007e-16
29; -1.109726693627516e-16
31; -1.112864486590965e-16
33; -1.112835160099258e-16
35; -1.112835403326881e-16
37; -1.112835401524659e-16
39; -1.112835401536661e-16
41; -1.112835401536589e-16
43; -1.112835401536589e-16
45; -1.112835401536589e-16
47; -1.112835401536589e-16
49; -1.112835401536589e-16
Видно, что начиная с 41 степени ряда он сходится к -1.112835401536589e-16 (ожидалось 0, но погрешности округления мешают).
Ваш ход? Вставляйте округление в место, где посчитаете нужным, продемонстрируйте результат.
Или балабол ;)
Вставляйте округление в место, где посчитаете нужным, продемонстрируйте результат.
Своими ручками пожалуйста. Вставьте где нужно мое округление и покажите, что оно не работает. Вся информация для этого в статье и в коментах. Если будут вопросы, обращайтесь.
Ну да… :)
Про Рассела и его чайник слышали? Кто алгоритм придумал, тот и доказывает его работоспособность. Функции magick_round() в вашей программе я не вижу.
А Брадиса Вы читали?
У.Кэхэна читал, Д.Голдберга читал, Харрисона читал, Циммермана читал. Брадиса? Кажется в школе проходили. А в чем дело?
Кажется в школе проходили.
Не таблицы, а учебник.
Дело в том, что вопросы точности были разобраны лет за семьдесят до рождения хренов с горы, на которых Вы ссылаетесь.
На том простом основании, что все компьютеры работают по теории, изложенной в этом учебнике, а не в учебнике Брадиса. Поэтому мы с вами на разных языках разговариваем.
И он, что характерно, с этим справляется.
Да вот, оказывается, не очень. Зачем-то заменили 32-разрядные компьютеры на 64-разрядные, а теперь и на 128. А еще работают над 256 разрядными? Вам ни кажется это странным? Вы представляете себе это десятичное число с плавающей запятой? А все ради нее, ради точности стараются.
Зачем-то заменили 32-разрядные компьютеры на 64-разрядные, а теперь и на 128.
Ради производительности, разумеется. В предел скорости упёрлись, а расти дальше как-то надо.
Вы представляете себе это десятичное число с плавающей запятой
Нет, не представляю.
А все ради нее, ради точности стараются.
Чем докажете?
Они абсолютно точные
А если оно точное, то даже записанное в форме с плавающей точкой, оно остается быть точным
А, так вы не в курсе.
Это они в десятичной системе абсолютно точные. А в двоичной системе это периодическая дробь. Потому что в двоичной системе любые дроби периодические, кроме тех, у которых знаменатель степень двойки. И в десятичной любые дроби периодические, кроме тех, у которых знаменатель кратен только 2 или 5, то есть приводится к степени десятки умножением на соответствующий коэффициент.
Если вы возьмете дробь 1/3 и запишете ее в десятичной системе с точностью 53 знака после запятой, она округлится до 0.3333...333. И точно так же дробь 987654321098806/100 в двоичной системе с точностью 53 знака округляется до ближайшего числа. Округленные данные присутствуют изначально, это математическое ограничение, его нельзя обойти, потому что нельзя записать бесконечно много знаков в фиксированной разрядной сетке.
Для случая, когда надо округлить число до определенного знака, в библиотеке <math.h> отдельной функции нет
Потому и нет, что нет удовлетворительных алгоритмов.
потому обычно используют умножение числа и последующее после округления деление,
Это работает для случая нулевой экспоненты (без сдвига). Если экспонента двоичного числа существенно превышает количество разрядов двоичной мантиссы, или она отрицательная, определить значение коэффициента 10^E, на который надо разделить число, а потом его умножить, сложная задача. См. 1,2,3.
Сейчас же мне приходится парсить наукообразный поток сознания, чтобы выяснить, что же автору так не понравилось в штатной округлялке. Ну и чтобы выяснить, не NIH ли это синдром.
МаркЁром странности также является то, что автор предлагает Один Единственно Верный Способ округления, хотя даже Википедия знает больше, как то «к ближайшему числу», «банковское», «округление вверх», «округление вниз», и так далее.
Код читать также невозможно. Вот эта карамба из однобуквенных переменных без комментариев, константности и инициализации радостно встречает нас в начале программы:
double q,x,xr,X;
unsigned long long int Xr;
int N,p,E,e,k;Что тут, куда тут — читатель умный, разберется.
А еще, мне понравилось вот это
X=x*pow(10,k);Input a binary precision p=111111
Input a decimal precision N=2
Input a number and press ENTER:
x= 0.011
X= 0.0109999999999999994
Xr= 11e-3
xr=0.0109999999999999994
sh: 1: pause: not found
Расскажите, пожалуйста, что означает сие? Зачем вы спрашиваете какую-нибудь двоичную точность, если далее в коде она нигде не используется? Что за Xr, xr, где собственнно округление?
X= 0.0109999999999999994 — это десятичное представление двоичного числа, которое получилось после конвертации десятичного x в формат double.
Xr= 11e-3=0.011 — число, полученное округлением до N=2 числа x с целочисленной десятичной мантиссой.
xr=0.0109999999999999994 — двоичное представление числа Xr в формате double
Да, и еще. Округление ведется не до N знаков после точки/запятой, а до N значащих десятичных цифр.
Точность p, это десятичное число p<=53.
А почему не >=1000?
В коде вашего «алгоритма» это десятичное число все равно не используется.
Программа написана для проверки работы алгоритма с переменными типа double. Для этого формата p=53, так что неявно это число присутствует.
Т.е. он не нужен.
А зачем тогда запрашивать его у пользователя?
Но, насколько я знаю, операционных регистров с количеством разрядов p близким к 1000 пока не существует.
Библиотеки дл работы с числами любой длины существуют уже много-много лет. Навскидку — GMP, ttmath, MPFR — последняя вообще позиционируется как «библиотека для больших чисел с плавающей точкой и с правильным округлением».
Т.е. он не нужен.
А зачем тогда запрашивать его у пользователя?
Программа тестовая. Она тестирует округление для любого формата в котором p<=53. Вы можете задать p=24 для формата single, или любое другое значение p.
Библиотеки дл работы с числами любой длины существуют уже много-много лет.
Эти программы и библиотеки существуют, но они очень тяжелые и потому используются в крайних случаях. Зачем покупать дорогой автомобиль, если до места — рукой подать?
Программа тестовая. Она тестирует округление для любого формата в котором p<=53. Вы можете задать p=24 для формата single, или любое другое значение p.
Правда, это ничего не изменит, потому что р в программе не используется.
Эти программы и библиотеки существуют, но они очень тяжелые и потому используются в крайних случаях. Зачем покупать дорогой автомобиль, если до места — рукой подать?
Ну так это же не я сетовал на то, что в бинарном представлении как-то маловато разрядов. Это были вы.
Про тяжелость вы сами придумали или есть какие-то данные с полей? Вы вот в своем коде, на минуточку, вызваете библиотечные функции pow и frexp, которые не факт что легенькие.
Правда, это ничего не изменит, потому что р в программе не используется.
Согласен, что касается p, вы правы.
Ну так это же не я сетовал на то, что в бинарном представлении как-то маловато разрядов. Это были вы.
В каком месте нашего диалога я жаловался на малость разрядов в бинарном представлении?
Про тяжелость вы сами придумали или есть какие-то данные с полей?
Может я ошибаюсь, но длинная арифметика, в том числе для чисел с плавающей точкой реализована в десятичном формате с использованием BCD. А этот формат требует существенных программно-аппаратных затрат. Именно поэтому в железе он до сих пор мало где реализован.
pow и frexp, которые не факт что легенькие.
Если отвлечься от программной реализации этих функций, а посмотреть чисто на алгоритм, то frexp легко реализуется аппаратно, т.к. надо просто считать поле двоичной экспоненты, а pow легко реализуется в табличном виде.
длинная арифметика, в том числе для чисел с плавающей точкой реализована в десятичном формате с использованием BCD. А этот формат требует существенных программно-аппаратных затрат. Именно поэтому в железе он до сих пор мало где реализован.
Если некий софтовый функционал до сих пор не реализован в железе, с вероятностью в 146% можно предположить, что он в железе никому не нужен.
Потому что в BCD что-то хранить и обрабатывать расточительно.
x=7.123456789098765321 e-89 — десятичное число, которое мы хотели бы округлить до 15 значащих цифр.
А чем вас округление при выводе-то не устраивает?
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int main()
{
double a = atof("7.123456789098765321e-89");
printf("%.18e\n", a);
printf("%.14e\n", a);
return 0;
}
// gcc 1.c -lm -o 1.bin && ./1.bin
// 7.123456789098765586e-89
// 7.12345678909877e-89А чем вас округление при выводе-то не устраивает?
Потому, что округлять часто надо в процессе вычислений, которые выполняются над двоичными числами. Иначе десятичные ошибки могут быстро накапливаться.
Зачем?
Почему они не будут накапливаться с округлением, если округление по определению отбрасывает часть разрядов, а значит увеличивает ошибку?
Иначе десятичные ошибки могут быстро накапливаться.
Ошибки вычислений не зависят от формата представления числа. Любое округление по определению не устраняет ошибки а наоборот, вносит их. Таким образом, ваш «правильный» алгоритм округления лишь вносит дополнительные ошибки. Вы можете убедиться в этом самостоятельно, промоделировав вычисления с накоплением ошибок и сравнив результаты.
В институте нам показывали замечательный пример. Численно решить систему из 2 линейных уравнений, используя какой то итерационный метод, и использовать только 3 значащих цифры после запятой. Так вот, решение отличалось от школьного варианта на единицы, то есть ошибка превысила погрешность расчета на 3 порядка.
Секрет был в том, что прямые пересекались под очень острым углом.
Проверьте, делов то. Посчитайте sin(1) через ряд, или число pi. Элементы ряда сгрузите в массив, массив посортируйте рандомно (чтобы погрешности округления себя показали). 10000 элементов, думаю, хватит. Контрольный расчет повторите с обычными float. И точность, и быстродействие легко проверяется.
Но, когда мы десятичную арифметику реализуем в двоичных кодах, все становится не так очевидно.
Покажите пример пожалуйста. Те, что вы приводили в статье и в комментариях, нормально считаются и округляются стандартными средствами.
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int main()
{
double a = atof(«1.506242359842875009e-27»);
printf("%.18e\n", a);
printf("%.14e\n", a);
return 0;
}
Мне Code::Bloks выдал: 1.50624235984287e-27
Так у double точность примерно 15 десятичных знаков после запятой, почему вы ждете, что он будет 18 знаков на входе правильно обрабатывать?
Ближайшее число стандартными средствами округляется правильно.
double a = atof("1.506242359842875009e-27");
double multiplier = pow(10, 27 + 14);
double rounded = floor(a * multiplier + 0.49999999999999994) / multiplier;
printf("%.18e\n", a);
printf("%.18e\n", rounded);
printf("%.14e\n", rounded);
// 1.506242359842874922e-27
// 1.506242359842879944e-27
// 1.50624235984288e-27Так у double точность примерно 15 десятичных знаков после запятой, почему вы ждете, что он будет 18 знаков на входе правильно обрабатывать?
Поэтому и ожидаешь, что все 15 цифр обещают быть верными.
К сожалению, если округлять число 1.506242359842874900e-27 вашей программой, то мы получим ошибку в другую сторону. Округление даст 1.50624235984288e-27
К сожалению, если округлять число 1.506242359842874900e-27 вашей программой, то мы получим ошибку в другую сторону. Округление даст 1.50624235984288e-27
Ну так и ваша даст:
Input a binary precision p=53
Input a decimal precision N=15
Input a number and press ENTER:
x= 1.506242359842874900e-27
X= 1.50624235984287492e-27
Xr= 150624235984288e-41
xr=1.50624235984287994e-27Я думаю, это проблема округления 53-й значащей цифры
Дак это так и есть, и это именно то, что вам и пытаются тут объяснить. Вы делаете вычисления на границе точности, то есть используете инструменты не по назначению, и удивляетесь результатам. Если нужны вычисления с такой точностью, надо использовать соответствующие библиотеки.
double a = atof(«1.50624235984287501e-17»);
У меня Code::Bloks выдал: 1.50624235984287e-17
Моя тестовая программа выдает 1.50624235984288e-17
Где правда?
Правильное округление десятичных чисел в двоичном коде