Comments 170
Для организаций с большим количеством данных, можно сделать централизированное хранилище доступное по сети с большим набором готовых блоков данных, которые можно использовать в «архивации».
Так сказать внешний большой словарь готовых блоков.
Также автоматически вычисляются блоки, которые могут быть переиспользованы достаточно раз, чтобы для них выделить место и наоборот — если блок используется мало, оригинальный файл перепаковывается, чтобы не использовать хранилище.
Я читал что такая схема где-то используется на практике, но это очень нишевое решение, которое не подойдет для публичного использования.
Большой словарь готовых блоков — это хорошо, но его где-то тоже надо хранить. Да, можно хранить его где-то далеко, а локально сохранять только известные хеши — тогда сжатие будет очень быстрым, но для распаковки придется запрашивать по сети сами блоки. В сценарии, когда часто идет архивация шаблонных данных, а разархивирование происходит крайне редко, это еще может быть оправдано.
Если же разархивировать приходится часто, либо шаблонности в данных маловато — увы, заранее сгенерированная таблица известных блоков превращается скорее в обузу. Проще строить ее на ходу, чем, собственно, все и занимаются.
Как минимум по умолчанию.
AFAIK, гит использует дельту именно что "под капотом" в качестве метода сжатия. А семантически, да, хранит все версии.
2. Используется дедупликация — в каждом коммите просто список хешей. То есть если сжать какой-то одинаковый файл два раза — гит получит тот же самый хеш для этого блоба, и не будет хранить этот блоб дважды.
Периодически он перепаковывает одиночные файлы недавних коммитов в более крупные наборы файлов более старых коммитов, но внутри каждый файл хранится отдельным объектом-блобом.
2. коммиты, которые не принадлежат бренчам (удалил фича бренч) удаляются целиком, что еще раз говорит о том, что это несложная операция. GC по дефолту вроде удаляет это примерно через 3 недели неиспользования какого-либо коммита.
3. git как раз умышленно отказался от модели CVS — хранить диффы, чтобы было удобно делать различные штуки типа cherry pick, удалять старые ненужные коммиты и так далее. Он каждый файл хранит целиком. Просто пакует их.
Черт побери, ребята, это же написано в документации к гиту, о чем спор??
git-scm.com/book/en/v2/Git-Internals-Git-Objects#_tree_objects
nfarina.com/post/9868516270/git-is-simpler
В гите есть даже отдельные команды, чтобы распаковать отдельно взятый блоб в файл.
Да это и не спор — так, поболтать. Был не прав в формулировках, признаю. Впрочем, плохо понятно, как (3) помогает черри пику а не наоборот мешает.
Нигде не хранится дельта файла.
И даже не хранятся дельты коммитов.
Каждый коммит — список определенных файлов в него входящих
Именно поэтому бренчи и коммиты в гите настолько легковесны — у них нет никаких зависимостей, которые нужно вычислять и хранить.
Но таки поясните по пункту 3. А то я то ли тплю, то ли что-то еще упускаю.
Причем в ветке A уже куча комитов (десятки или сотни), но например их там 20.
Предположим что вносим изменения в коммит #10 ветки А
Затем в #11 коммит ветки А и так до 20-го.
В случае GIT — делается дифф между нужным и предыдущим коммитом ветки B, получаем собственно сами изменения.
В случае с CVS, для начала, насколько я помню, там в принципе нет штатной команды для такого. Нужно откатиться на 10-й коммит ветки B, и последовательно (скорее всего руками), вытащить все изменения между коммитами.
Затем опять откатиться на 10й, применить изменения из ветки Б, и последовательно накатывать сохраненные изменения.
Я уже не помню можно ли в CVS переименовывать ветки, но возможно у вас с тех пор будет существовать две ветки — старая и новая.
В случае git — получили изменения из ветки B, штатной командой применяется черри пик. Внутри он просто идет по всем коммитам начиная с 10-го и применяет к каждому из них изменения из ветки B. Независимо, как к индивидуальным коммитам. Не нужно ничего вычислять, только как изменения ветки B применить к конкретному состоянию.
Старые коммиты при этом оказываются выкинуты из ветки, и со временем их объекты удалит мусоросборщик, у вас будет ветка, в которой словно бы всегда были эти изменения.
Кроме того, что это делается штатной командой, сами вычисления внутри довольно просты и интуитивны. И несмотря на то, что черри пик в принципе не самый популярный git flow, он вполне себе может иметь место в некоторых проектах на постоянной основе.
В случае GIT — делается дифф между нужным и предыдущим коммитом ветки B, получаем собственно сами изменения.Но это же и есть дельта файла. Как хранение сразу дельты нам помешает? При чем, если бы мы хранили изменения а не состояния, то было бы достаточно прямого копирования коммита в середину цепочки без обработки последующих.
Или я не прав?
C CVS я вообще не работал, если честно.
Ветка1
КоммитА1, коммитА2, коммитА3,… КоммитА99
Ветка 2
КоммитБ-1, КоммитБ-2
Сравнили КоммитБ1 и КоммитБ2, нашли собственно изменения.
Их нужно применить ко ВСЕЙ ветке 1, начиная с коммитА40 и до коммитА99.
А у вас там хранятся только дельты от КоммитА1.
Куча перебора, куча проверок на конфликты, пересчеты.
Да просто нет такого функционала.
Ветки в CVS тяжелые. Каждая ветка — это куча информации. 100-200 веток это уже вопрос. 500-1000 веток в CVS — это просто ужас.
В гите это вообще не проблема и практически ноль нагрузки на CPU, вдобавок минимум нагрузки на диск.
Куча перебора, куча проверок на конфликты, пересчеты.Они разве бывают при черри пике?
Их нужно применить ко ВСЕЙ ветке 1, начиная с коммитА40 и до коммитА99.
Это уже не cherry-pick, это rebase.
Куча перебора, куча проверок на конфликты, пересчеты.
Ровно как и в Git: при ребейзе каждого коммита проверяются конфликты, которые могли возникнуть в т.ч. в результате ребейза предыдущих коммитов.
Ровно как и в Git: при ребейзе каждого коммита проверяются конфликты, которые могли возникнуть в т.ч. в результате ребейза предыдущих коммитов.
Не нужно для каждого коммита восстанавливать историю ветки. У тебя всегда есть готовый файл, к которому нужно применить мерж. В этом и смысл «дешевых веток» — вычислить конкретный коммит на любой ветке, неважно как давно он был и сколько коммитов в этой ветке — для git это всегда одна операция.
Не нужно для каждого коммита восстанавливать историю ветки. У тебя всегда есть готовый файл, к которому нужно применить мерж.
Может и не нужно, но фактически Git делает именно это: превращает всю переписываемую историю ветки в набор патч-файлов, и накатывает их по одному.
github.com/git/git/blob/master/builtin/rebase.c#L811
И в 2 словах: почему сжатие через поиск последовательности в числе Pi гиблая идея? :)
А какой алгоритм сжатия покажет наибольшую эффективность, если в наличии много ресурсов и времени, а сжатие нужно произвести только 1 раз, например сжимаем видео 16K HDR 3D?Тут нельзя говорить «например», поскольку для видео — свои алгоритмы, более того — для 3D видео свои))). Для 2D видео рекомендую следить за нашими отчетами по 4K (релиз этого года скоро будет), а сильные универсальные алгоритмы через месяц можно будет посмотреть в Global Competition Leaderboards (сейчас многие сильные алгоритмы авторы не заливают).
И в 2 словах: почему сжатие через поиск последовательности в числе Pi гиблая идея? :)Потому, что фон Нейман таки в чем-то прав)))
Есть ли какая-то утилита которая бы определяла наиболее оптимальный алгоритм сжатия?
По поводу неоптимальности — тут смотря какие параметры оптимизировать. Если сжимать универсальные файла по 5 ГБ, то нейросеть для оценки таких файлов почти наверняка не уместится в оперативке, т.е. запустить её в работу будет нелегко. А доказать, что она всегда выдаёт качественный результат (а в промышленных решениях без аудита никуда) ещё тяжелее…
По моему, овчинка выделки не стоит. Сначала надо нейросеть обучить на основе огромного объёма данных для сжатия, потом проанализировать наши данные, а потом уже сжать "условно оптимальным алгоритмом". Времени/электричества на первые два шага-то не жалко? ;)
Я не профи ни в нейросетях, ни в сжатии видео, но мне кажется, единственное реальное применение нейросети в сжатии — это анализ небольшой совокупности кадров на предмет "а чем именно лучше сжать именно вот эту последовательность?".
Ну и обучать, кмк, проще и дешевле.
Берем разные последовательности между I-кадрами, кормим нейросети, потом сжимаем разными способами и сообщаем обучалке, какой в данном случае алгоритм был лучше всех. Ну, там много нюансов, много направлений для оптимизации, но — судя по тому, что я слышал об этом деле — это наиболее вероятное применение.
При этом сегодня нейросети массово уходят внутрь кодеков. В новом AV1, например, который молитвами Google уже в каждом новом смартфоне под Android, внутри десятки небольших сеток на 5-7 слоев, заменивших методы принятия решений предыдущих поколений. Наш аспирант в этот проект код контрибьютил, в итоге сейчас работает в офисе Google в Лондоне.
КМК ничего странного. Кодеки десятилетиями целенаправленно проектировались на потерю незначительных для человеческого восприятия деталей, нейросети пока под это не обучаются массово, по крайней мере судя по образчикам их творчества.
И в 2 словах: почему сжатие через поиск последовательности в числе Pi гиблая идея? :)Одни данные (сжимаемого файла) другими данными (смещением найденной последовательности) заменяем. Притом скорее всего «найдётся» настолько далеко, что размер файла только вырастет.
Насколько я знаю, это распространенное заблуждение — нормальность числа пи является открытой проблемой.
Избыточное, но существование любой последовательности доказать ещё сложнее (нормальность упрощённо говоря означает "все последовательности примерно равноправны, так что алгоритм построения числа не делает какие-то из них менее вероятными"), и для пи подобного доказательства нет.
Рациональными числами искать не столь интересно — обычно в виде шутки (а иногда и всерьез) предлагают искать именно в пи.
Пример: Имеем число М=705128205
Представим его как смешанную периодическую дробь, отступив 3 знака: 0,705(128205)
Преобразуем в обыкновенную: 55/78
Было 9 разрядов. Стало (55,78,3) 5 разрядов. Явно стало короче, но для этого нам пришлось подобрать место расположения скобки.
И в 2 словах: почему сжатие через поиск последовательности в числе Pi гиблая идея? :)Потому что фактически мы заменяем одну последовательность другой через биекцию и надеемся, что новая будет короче. А это 50 на 50. Может и не повезти.
Пример попроще: из числа Pi генерируем таблицу перестановок byte -> byte (т.е. таблицу битовых последовательностей длины 8). И выходим на рынок с супер-идеей: наша таблица перестановок настолько супер-крута, что любые файлы после замены всех байт по ней начинают сжиматься гораздо лучше!
А поскольку данные — это хранение информации и передача, то если хотя бы на единицы процентов результат улучшить — это миллиарды долларов (смотрим экономию всех провайдеров на передаче и хранении, всех дата-центров компаний, всех домашних пользователей, перемножаем… аж дух захватывает)!
А сайты всё пухнут и жиреют.
Четыре года назад мне хватало гигабайта с небольшим трафика в месяц, чтобы скоротать время в пути на работу. Сейчас не хватает пяти. И непохоже, что кого-то интересуют «единицы процентов». Хотя что, например, сделаешь с фейсбуком или вконтактиком? Толстеют и будут толстеть.
Четыре года назад мне хватало гигабайта с небольшим трафика в месяц, чтобы скоротать время в пути на работу. Сейчас не хватает пяти.Это всегда будет. Иногда смотришь как векторные картинки сжимают в JPEG вместо PNG — плакать хочется.
Но и оптимизировать будут. Недавно разговаривал с коллегами, которые грамотно пережимают тысячи картинок вконтакта в JPEG2000. Там хороший гейн был получен. И нетривиальная работа по оптимизации реализации JPEG2000 на GPU проведена.
В остальном -каша. Пол текста об алгоритмах без потерь, потом резко вдруг об мр3, который ну никак к ним не относится со своей психо-аккустической моделью сжатия с потерями. Так же как и сжатие видео. А именно эти компрессии и представляют сегодня коммерческий интерес, а остальные -только научный. Немного сумбурно, но надеюсь, что автор меня понял
1. Речь шла про сжатие mp3 БЕЗ ПОТЕРЬ, психо-аккустика при этом не применяется, только энтропийный движок.
2. Сжатие видео — отдельная интересная тема, которой автор много и плотно занимается и о которой писал на хабр, ссылка на статью в конце для тех кому интересно приведена.
3. В тексте несколько раз даны примеры именно коммерческой эффективности алгоритмов сжатия без потерь. И ровно по этой причине компании объявляют конкурсы на десятки тысяч долларов (2 примера дано, в последнем конкурсе 12 номинаций).
И да -десятки тысяч долларов — это просто ни о чем. Это зарплата за пару месяцев. А приличные алгоритмы сжатия аудио видео сегодня — это пару лет работы. И не одного человека, а нескольких.
А приличные алгоритмы сжатия аудио видео сегодня — это пару лет работы. И не одного человека, а нескольких.В примере, который я привел над коммерческой реализацией технологии сжатия без потерь работало 6 человек и там было порядка 20-25 человеколет суммарно. Там нормальная сложность (особенно когда делается поддержка битых данных, работы в стримминге и т.д.). Не стоит ее сложность недооценивать. И я тоже давно в индустрии видеокодеков, у вас очень скромная на мой вкус оценка сложности «приличного алгоритма сжатия видео»)
Про конкурсы — на десятки тысяч долларов логика в статье совершенно конкретная: множество людей по непонятной причине полагает, что они изобретут классный алгоритм, дорого продадут его и будут богаты. Реальные же примеры — скорее ближе к ML/DL пути, т.е. победы на конкурсах и далее работа в компаниях. Т.е. заработок будет на зарплате, а не на патентах/продаже технологии. В чем однобокость? )
Сложности именно в сжатии аудио -видео с потерями в котором даже верификация вызывает нетривиальные проблемы. В смысле что я согласен с комментарием:
habr.com/ru/post/525664/#comment_22244112
Про «отсутствие принципиально более эффективных алгоритмов» — рекомендую глянуть как прямо сейчас захватывает рынок Brotli ( github.com/google/brotli ) в силу его принципиального (порядка 20% для отдельных кейсов) преимущества перед Deflate. Также интересно, что как раз сейчас появился реальный шанс на появление нового заметного прорыва благодаря DL. Тут надо будет через пару лет смотреть.
И да, в Хайфе Интел более отзывчивый
Объёма накопителя для сырых данных хватает на несколько дней и они могут тереться по мере получения новых.
Что-то мне подсказывает, что для объёмных данных можно достичь гораздо более высоких коэффициентов сжатия, чем для послойных, сжатых скажем JPEG2000.
1 реконструкция выполняется на более дорогом оборудовании чем, то на котором доктор смотрит картинки иногда на пару порядков, в случае итеративного реконсруирования
2 вместе с сырыми данными нужно поставлять и программу реконструирования, а она не всегда влезет на компьютер доктора, и результат ещё надо верифицировать для разных архитектур.
3.число степеней свободы (значимый объем данных) у исходных данных и реконструированных примерно одинаково. Собственно это одно из требований FDA(реконструкция без потери значимой информации). Так что компрессироваться они будут абсолютно одинаково.
4 серия DICOM картинок отлично жмётся именно благодаря некоторой избыточности. Картинки сильно зависят друг от друга по оси Z. И этим пользуются при хранении.
2 аналогично, встречал ПО для реконструкции свёрткой, занимающее что-то около 20 МБ.
3 о таких требованиях не знал, спасибо. Информативность сырых данных всё же выше к оси вращения и ниже по краям, на плоских реконструкциях она равномерна. Т.е. если реконструкции делать с максимальным разрешением, как в центре они будут избыточно большими, если взять среднее разрешение неизбежно какая-то часть существенных данных пропадёт.
4 тут как раз в тему статьи.
Печально всё же, что несмотря на бурно развивающееся в последние годы ПО для обработки DICOM изображений всё ещё не налажена обработка чужих сырых данных. То есть понятно, что есть ограничения на ПО в связи с его применением в диагностических целях, ответственность и всё такое. Но жаль.
Compression.ru как давно это было.
С универсальными архиваторами таки да особо текущую ситуацию не улучшить. А вот со специализированными поле деятельности весьма широкое. Скажем сжимать мультипликацию в целом и аниме в частности явно можно лучше чем стандартными видеокодеками просто в силу методов создания мультипликации.
Для текста тоже можно вынести изрядную часть избыточности в специализированный архиватор. Не факт что это будет давать преимущество в размере архива но может дать его в скорости распаковки.
Скажем сжимать мультипликацию в целом и аниме в частности явно можно лучше чем стандартными видеокодеками просто в силу методов создания мультипликации.Там скоро с переводом в векторный формат может быть недетский рывок.
Для текста тоже можно вынести изрядную часть избыточности в специализированный архиватор.На Hutter Prize ровно об этом речь. И там сейчас минимальный приз 5000 EUR (они подняли).
Так что сжимать сжатое можно! За это даже платят. Лично проверял!
Тоже сделал свой архиватор для скриншотов через рекомпрессию — сэкономил достаточно много места.
А не знаете ли вы какие-нибудь профессиональные программы для этой цели?
p.s.
3Dvideo, спасибо.
Книга «Методы сжатия данных» очень хорошая была, по крайней мере в плане алгоритмов сжатия данных и текста. Зачитал до дыр, большое спасибо!
Смысл конкурса в том, что была взята хорошо подготовленная последовательность случайных чисел (большой файл):
Задача была создать архиватор для этого файла, который вместе с архивом был бы меньше по размеру, чем сжимаемый файл
)))))) Видать человеку тоже надоело дурацкие письма читать, вот он и решил всех граждан с нестандартным мышлением собрать на одном большом корабле.
quixdb.github.io/squash-benchmark
В интернете есть ещё несколько подобных мест, куда можно посылать любителей покомпрессировать.
успешных кейсов, чтобы человек подал патент на алгоритм сжатия и разбогател, я не встречал
Первое, что приходит в голову — это LZW в GIF: вроде бы за него Unisys успешно сдирали деньги.
LZW в GIF: вроде бы за него Unisys успешно сдирали деньги.Патент подан Sperry Corporation, а не человеком (жизненный цикл патента примерно 25K USD — это без судов), но даже в случае их активных вложений в суды Unisys обогатиться (к счастью))) не удалось…
Идея: допиливаем сеть, хорошо транскрибирующую видео и сжимаем результат алгоритмом Фабриса Беллара. Другая сеть по разжатой транскрипции восстанавливает Нео, взмывающего со взволнованного асфальта ввысь и Тринити в обтягивающем мотокостюме, обрушиваюшуюся с небес на головы незадачливых охранников.
Результат сжатия печатаем на (одной) перфокарте для потомков.
Спасибо за содержательную статью, в особенности за напоминание кто есть ху в мире сжатия.
Есть HA Archiver Plugin для Total Commander: http://wcx.sourceforge.net/
И да, тексты он жмет (или жал) заметно лучше всех, но раза в 3-4 медленнее чем другие архиваторы.
Кажется, у WinAce была неплохая версия под DOS.
Опасаться подобных программ не стоит — можно скачать с какого-нить сайта любителей раритетов, прогнать через любой онлайн антивирус и в досбокс.
Разумеется. Просто в свое время HA жал тексты заметно лучше, чем ARJ, ZIP или какой-нибудь, прости Тьюринг, AIN.
P.S. Учитывая, что AIN еще любил запарывать архивы на ровном месте, RAR был как манна небесная.
Во-вторых я почти уверен, что вы сравниваете rar c использованием solid archive.
А если взять рар во времена DOS (дай бог памяти, какой-нить 2.55 версии), то ha однозначно был лучше.
ha0999.exe
winrar 5.20 (оба метода — в rar и rar5)
Везде максимальная степень сжатия, максимально большой словарь, солид архив.
Результаты:
hotstart.txt, обычный текст в winn1251, размер 656850
250448 hotstart.rar
250843 hotstart_rar5.rar
223972 hotstart.ha
tzan.htm тоже текст, но в UTF-8, размер 1148861
263504 tzan1.rar
263769 tzan1_rar5.rar
249144 TZAN1.HA
hpmor.ru.fb2 UTF-8, есть парочка jpegs in base64, размер 6819245
1334614 hpmor_ru.rar
1334009 hpmor_ru_rar5.rar
1376798 HPMOR2.HA
edem.fb2 UTF-8, только текст без аттачей, размер 821121
193101 edem.rar
193280 edem_rar5.rar
173413 EDEM.HA
Итого, ha уверенно лидирует, показывая результат на 5-10% лучше. Но только если файл — чистый текст
Современные архиваторы, которые в солид, могут использовать гигабайты оперативки для создания словаря, следовательно на большом количестве файлов однозначно будет выигрыш
А ха — ну что-то улучшится, но я сомневаюсь что будет какой-либо прирост после 1-2 мегабайта, ибо в 95 году 4 мб оперативки была редкость.
Итого, ha уверенно лидирует, показывая результат на 5-10% лучше. Но только если файл — чистый текстЕсли уж нестандартный формат гоняете, попробуйте интереса ради новые LSTM-based кодировщики текста. Там преимущество перед старыми алгоритмами как раз на текстах в 2.2-2.7 раза (вот nncp, например, по сравнению с обычным gzip):
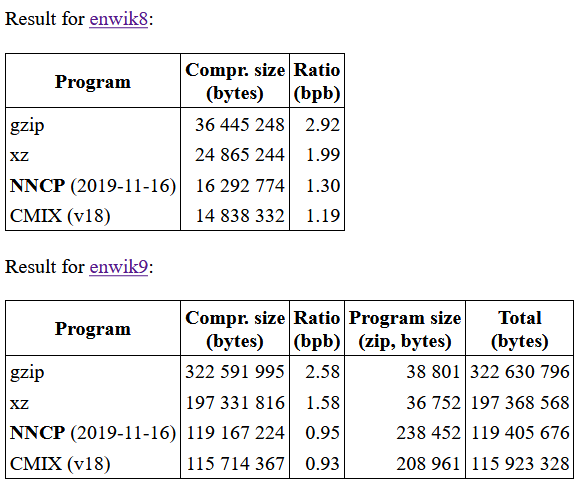
Интересно CMIX посмотреть, например).
Вообще на Large Text Compression Benchmark у Мэтта Махоней топ-10 (из примерно 200 архиваторов текстов) выглядит так:
Compression Compressed size
Program Options enwik8 enwik9
------- ------- ---------- -----------
cmix v18 14,838,332 115,714,367
phda9 1.8 15,010,414 116,544,849
nncp 2019-11-16 16,292,774 119,167,224
paq8pxd_v48_bwt1 -s14 16,004,759 126,183,029
tensorflow-compress v2 16,828,585 127,146,379
durilca'kingsize -m13000 -o40 -t2 16,209,167 127,377,411
cmve 0.2.0 -m2,3,0x7fed7dfd 16,424,248 129,876,858
paq8hp12any -8 16,230,028 132,045,026
drt|emma 1.23 16,523,517 134,164,521
zpaq 6.42 -m s10.0.5fmax6 17,855,729 142,252,605
phda9 (2 место), кстати — это Саша Ратушняк, durilca'kingsize (6 место) — это Дмитрий Шкарин, и к paq8* (4 и 7) Саша Ратушняк руку также прикладывал)
Ну а gzip вообще не имеет смысл сравнивать. Его плюс точно не в силе сжатия =)
Или вы про досовские версии?
по сравнению с обычным gzip):
Мне кстати интересно.
Почему сравнение идет именно с gzip, а не хотя бы zip?
Ведь gzip это вообще потоковый архиватор, с которым прямо нет смысла соревноваться тем, кто может прочитать и проанализировать файл целиком перед сжатием?
А с zip человек сравнивается (пусть и с ключем максимальной степени сжатия), поскольку он сжимает хуже, конечно).
Для сравнения: у 7zip 44 место в рейтинге, у WinRAR — 71 место, у bzip2 (крайне популярен под Linux) — 116, а у gzip — 146 место (из 199))). При том, что все архиваторы внесены с наилучшими опциями (сжатие может сильно отличаться в зависимости от опций).
gzip это только deflate, причем gzip заточен под работу не с файлами а с потоками, и обрабатывает (сжимает данные) поблочно, а не по файлово. У меня даже есть подозрение, что он разрабатывался именно для такого использования. Поэтому лучшие опции для gzip — это zip ;)
А вот сам zip может использовать несколько методов, выбирая удобный под конкретный файл. Обычно это deflate, но он может также и в deflate64, implode и даже bzip2, но используя zip наверное следует указывать какой конкретно метод был выбран.
1 — The file is Shrunk
2 — The file is Reduced with compression factor 1
3 — The file is Reduced with compression factor 2
4 — The file is Reduced with compression factor 3
5 — The file is Reduced with compression factor 4
6 — The file is Imploded
7 — Reserved for Tokenizing compression algorithm
8 — The file is Deflated
9 — Enhanced Deflating using Deflate64(TM)
10 — PKWARE Data Compression Library Imploding (old IBM TERSE)
11 — Reserved by PKWARE
12 — File is compressed using BZIP2 algorithm
13 — Reserved by PKWARE
14 — LZMA (EFS)
15 — Reserved by PKWARE
16 — Reserved by PKWARE
17 — Reserved by PKWARE
18 — File is compressed using IBM TERSE (new)
19 — IBM LZ77 z Architecture (PFS)
97 — WavPack compressed data
98 — PPMd version I, Rev 1
Под ключами я имею ввиду -1, -9 которые позволяют сжимать сильнее или слабее без потерь, но тратя на это существенно разное время.
https://yadi.sk/d/y01KMiG7KQ282Q (взято откуда-то из сети)
Развлекайтесь (на генте собралось без проблем, с парой варнингов)
Ещё есть зеркало на gitlab'е.
А вот был такой формат архивов как HA. И им любили сжимать книги… утверждали, что текст он лучше всех жмёт…Потому что других доступных реализаций ppm order-4 не было. А теперь у вас есть более мощный PPMd в составе, как минимум, 7z. При том, что PPMd — по нынешним временам уже легендарный старичок.
Интересно следить за новыми экспериментами, например, NNCP: Lossless Data Compression with Neural Networks. Не рекордный, но на enwik9 сжимает тексты В 2.7 РАЗА(!) сильнее gzip!
А за ними еще есть tensorflow-compress (последнее обновление которого на гитхабе 2 дня назад(!!!)), или DeepZip: Lossless Data Compression using Recurrent Neural Networks, CMIX с нейросетевой LSTM и т.д.
Это крайне интересные ростки завтрашнего дня! Надеюсь, руки дойдут и про это нейросетевое безобразие напишу. )
Самое лучшее сжатие без потерь обеспечивает magnet ссылка.
Самый короткий анекдот: pkunzip.zip
КМК искать нужно либо у коллег по цеху, либо у радиоастрономов — им приходится десятилетиями хранить огромные массивы необработанных данных, не теряя пока не найденных артефактов.
Возможно, выходом было бы хранение несжатых данных на винчестерах ноутбучного формфактора — они массово доступны на вторичном рынке за гроши. Весьма удобно использовать, не теряя в скорости, через USB3 переходник. Либо подключать наживую к материнской плате с шестью sata портами, периодически подставляя пустые.
Другой вопрос, что радиосигнал содержит случайные шумы, и может он вообще не пожмется без потерь, но тут хз, я не теоретик :)
WAV файл с радиозаписью размером 986 Мб сжался zip до 906 Мб и 7z ultra до 712 Мбайт. Наверно оно того не стоит, кардинального прироста нет, а сложность записи и обработки таких файлов вырастает.
но какой архиватор посоветуете для Mac OS?
Пользуюсь либо встроенным (жмёт в zip), либо Archiver, либо Keka, но может есть вариант(ы) получше?
Весело бывает с тем же Маком, когда кто-то присылает архив в RAR (и зачем? 10 Кб сэкономить?) и начинаются поиски распаковщика в App Store :)
зачем? 10 Кб сэкономить?Странный вопрос. Вы что, думаете отправитель сжал несколькими разными архиваторами и послал вам тот, у которого размер меньше получился? Нет, он и не вдавался в такие подробности. Просто всегда пользуется RAR-ом
и начинаются поиски распаковщика в App Store :)А вы что — распаковали и удалили его? И название не помните и никаких следов в истории загрузок там не остаётся?
Тут Far manager под Macos запилили, он 7z умеет, как и Keka впрочем. Зато можно в теме запросить новую функциональность.
Если натравить на результирующий файл стандартный архиватор, то он сожмёт ещё вдвое.
Если же сохранять массивы не поразрядно, то стандартный архиватор, всё равно сжимает только в два раза.
старшие разряды у полей — в большинстве случаев либо 0 либо FF
В этом случае отлично помогают en.wikipedia.org/wiki/Variable-length_quantity
Существует какое-то объяснение этого явления?
Вот и уменьшили количество нулей в текстовом файле на 10 восмиричных процентов
Вы же сами привели Джима Коунси, директора подразделения Autodesk Developers Network и вспомнили про блог Dances with Elephants: How small companies can partner with large companies to accelerate their business growth.
Т.е. некая компания, хочет получить что-то дорогое, всего за $100 или даже за $10000.
Что такое $10т. в современном мире? Это месяц-два работы!
Получается, что человек/компания потратившая много-много своего личного времени (за $0 в час) на разработку какого-то уникального алгоритма, должна отдать его за эту смешную подачку?!
Вы можете ещё возразить, а как же «слава»?
Ну, так вам Коунси и объясняет — вас раздавят и не заметят! Другими словами, просто отберут алгоритм и скажут: вы — никто, а мы — всё! (История имеет МНОГО примеров) Даже просто по тому, что у них медиа и финансовый ресурс — ОГРОМЕН! И вы не сможете с ними бороться за «славу».
Я, как и вы, когда-то занимался разработкой сжатия данных. Я, как и вы, получил замечательные результаты, но был один минус — не всегда удавалось сжать данные и иногда сжимаемые данные, на выходе, были больше чем оригинал (это нормально, такое есть и у RAR и Zip). Необходимо было дополнительно исследовать и разрабатывать, НО хотелось кушать!
Вообщем, моя мораль: я, лучше разработаю это, как говорят писатели, в стол до лучших времён, ну а если не получится то на предсмертном одре — расскажу, как…
Поэтому, стоит задуматься, если у вас действительно есть что-то гениальное, как это гениальное сохранить. Я — не Перельман, я — хочу кушать, ездить на новых машинах, ходить в удобной хорошей одежде, обеспечивать семью и родителей.
А, слава?! Нафиг нужно!
Сто раз подумайте, какую вы имеете цель и для чего вы это всё делаете.
Миром правят — прагматики! Но с другой стороны, без лоха и жизнь плоха )))))
Аплодирую стоя.
Также интересно, что если бы можно было зафиксировать распакованный файл (условно WAV), а не MP3, то для того же распакованного файла (бит в бит в WAV) можно было бы еще чуть увеличить сжатие.
В каком смысле зафиксировать?
Если я правильно понял, имеется в виду следующее. Изначально имелся файл MP3, который можно "распаковать" в некий эквивалентный ему WAV. От авторов требовалось реализовать дополнительное сжатие, которое позволит при распаковке получить байт-в-байт тот же MP3. Они могли бы сжать лучше, если бы имели право получить другой MP3, которому соответствует байт-в-байт такой же WAV.
Совершенно так, спасибо!
Берется какой-то декодер, как референсный (а разные декодеры дают несколько разные выходные стримы в основном из-за оптимизаций) и можно еще наиграть степень сжатия, если обеспечивать выходной файл бит в бит по декодированному стриму (WAV), а не по MP3.
Так если MP3 на порядок меньше WAV (почти как хэш-сумма), тогда, наверное, одному MP3 может соответствовать несколько WAV, из каждого из которых получится тот самый MP3. И тогда, чтобы стремиться к соответствию бит в бит WAV, нужно договориться об алгоритме декодирования.
Это как раз и есть "берётся референсный декодер", по идее. Другой вопрос, что не каждому WAV соответствует какой-то MP3 (на то оно и сжатие с потерями), так что аналогия с хэш-суммой не совсем верна.
не каждому WAV соответствует какой-то MP3
Кодировщик выдаст "деление на ноль" на некоторых WAV?
Или имеется ввиду, что фиксируется не исходный WAV, а после преобразования WAV->MP3->WAV в референсном декодере?
Это как раз и есть "берётся референсный декодер", по идее.
ровно так)
Другой вопрос, что не каждому WAV соответствует какой-то MP3 (на то оно и сжатие с потерями), так что аналогия с хэш-суммой не совсем верна.
Все так) На практике некоторое множество WAV при сжатии дает один MP3.
Спасибо за ответы)
О талантах, деньгах и алгоритмах сжатия данных