Хабр, привет! Меня зовут Артем Родичев, я работаю Head of AI в компании Replika. Сегодня я расскажу как мы делаем AI-друга. Если вы смотрели фильм Her или последний Blade Runner, то уже можете представить что мы строим. На текущий момент, Реплика — самый популярный англоговорящий чатбот, которому пользователи пишут более десяти миллионов сообщений в день. Под катом — расшифровка доклада.
Реплика — это AI-друг, который призван улучшать самочувствие и настроение людей через диалог. Такой чатбот может быть особенно полезен людям, которые чувствуют себя одиноко, находятся в депрессии или у кого не очень большое количество социальных контактов.
Реплика может поговорить о том, как прошел твой день, про твои интересы, и заодно постарается сделать так, чтобы тебе после такого диалога стало эмоционально лучше.

Немного цифр, которые отражают текущее состояние продукта:

У нас более 10 миллионов пользователей, Реплика — это крупнейший англоговорящий чатбот, 80% наших пользователей из США.
Нам пишут более 100 миллионов сообщений в неделю, таким образом, мы — high load сервис и постоянно инвестируем в масштабирование и оптимизацию нашей инфраструктуры.
В среднем каждый пользователь отправляет нам более 100 сообщений в день — это много! Для сравнения, в среднем американцы пишут 94 сообщения в день, включая все социальные сети, мессенджеры и смски. Я часто шучу, что Реплика намного общительнее, чем ее создатели.
Сама важная для нас метрика — это доля диалогов, которые улучшают самочувствие пользователей — на текущий момент более 80% наших диалогов достигают этой цели.

Мы применяем мультимодальный подход, и помимо текстового общения, Реплике можно позвонить, отправить фотку или даже пообщаться в дополненной реальности — чуть позже я расскажу подробнее про каждую из этих модальностей.
Quality
Как сказал Питер Друкер, “Управлять можно только тем, что можно измерить”, так что поговорим про самую важную часть нашего продукта — качество диалога и как его измерить.
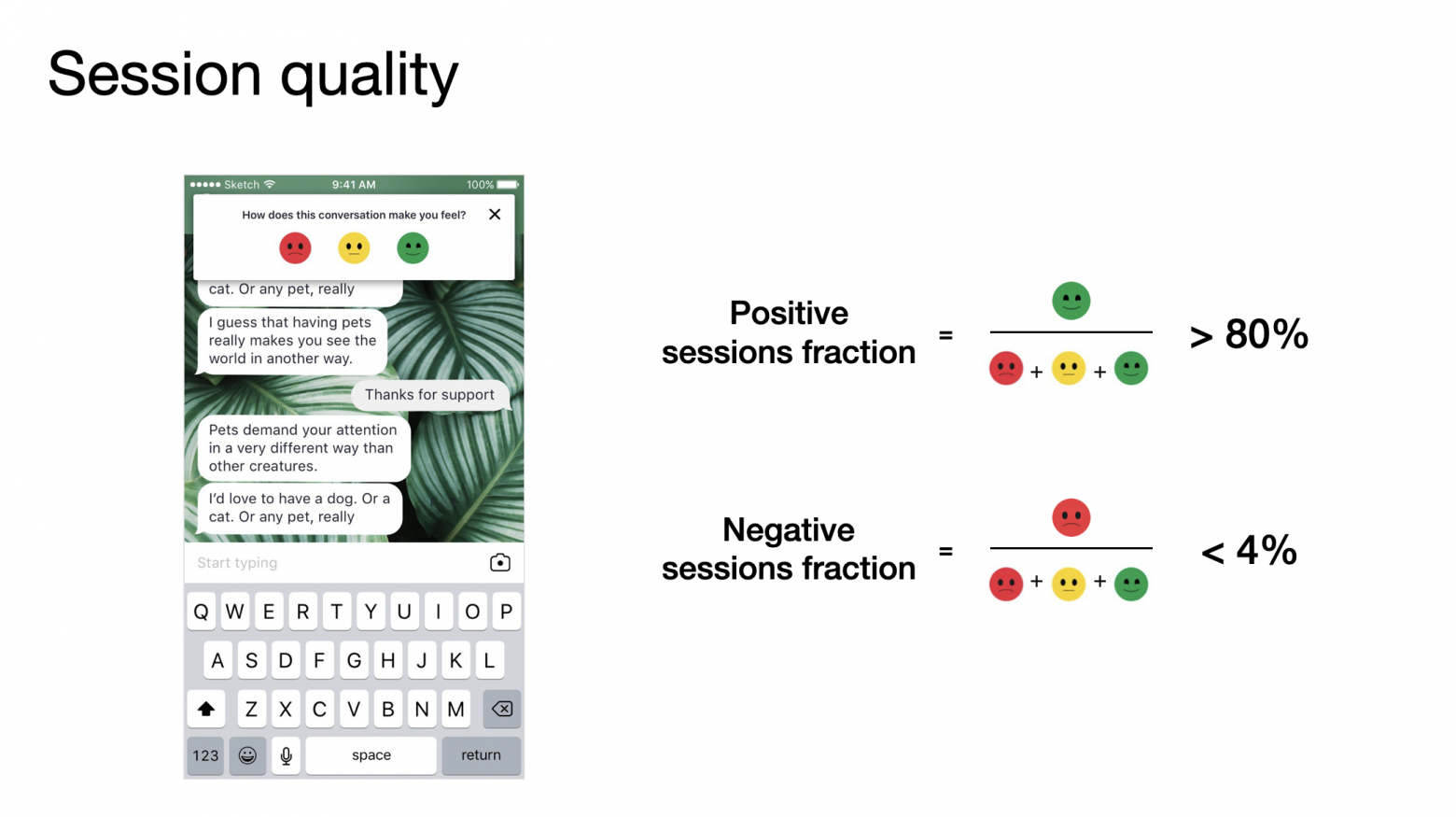
Мы постоянно улучшаем качество наших диалогов благодаря сигналу от пользователей. В течении диалоговой сессии мы собираем пользовательский фидбек и спрашиваем: “Как ты чувствуешь себя после этого разговора”, с вариантами ответов “хуже”, “также” и “лучше”.
Агрегируя пользовательский фидбек, мы считаем несколько ключевых метрик. Одна из них — доля положительных диалоговых сессий. Чтобы посчитать ее, мы суммируем все положительно оцененные сессии и делим их на общее количество диалоговых оценок. Аналогичным образом мы считаем долю отрицательных сессий. На текущий момент доля положительных сессий составляет более 80%, в то время как доля отрицательных — меньше 4%. Остальные разговоры — нейтральные.

Также пользователи могут проставить реакции отдельно на каждое сообщение. Ответы Реплики можно заапвоутить (то есть нажать палец вверх) если ответ понравился, или задаунвоутить (нажать палец вниз), если ответ показался нерелевантным, скучным или просто не имеет смысла. Таким образом мы можем получить метрику, показывающую долю апвоутов. На текущий момент эта метрика у нас выше 90%.

Кроме апвоутов и даунвоутов, мы собираем дополнительный фидбек, где пользователь может выбрать одну из четырех расширенных реакций. Благодаря этому, мы можем получить чуть больше информации о том, почему пользователю нравится или не нравится ответ. Это похоже на реакции в Фейсбуке, где помимо лайка можно выбрать дополнительные эмоджи, чтобы отреагировать на чей-то пост или комментарий. Мы собираем две дополнительные положительные реакции, которые показывают, что пользователя ответ насмешил или сильно понравился. Также есть две отрицательные реакции, которые показывают, что ответ не имеет смысла или является оскорбительным.

Мы хотим, чтобы у Реплики были интересные и увлекательные разговоры с пользователями. Скучные диалоги ведут к тому, что диалоговая сессия быстро заканчивается, а мы стараемся избежать таких диалогов. Мы отслеживаем 3 основные метрики отражающие вовлеченность пользователя:
Длина сессии, которая показывает среднее количество сообщений, которые пользователь отправляет за одну диалоговую сессию
Среднее количество сессий за день — как часто пользователи разговаривают с Репликой в течение дня.
Последняя метрика — это среднее количество сообщений, которые пользователи отправляют Реплике за день.

Теперь давайте посмотрим на высокоуровневую диаграмму архитектуры Реплики.
Когда пользователь отправляет нам сообщение, мы агрегируем такие данные, как профиль пользователя, текущий диалоговый контекст и само отправленное сообщение. Затем мы пропускаем эти данные через наш диалоговый движок. Он состоит из многих компонент, таких как различные NLP-классификаторы, генеративные и retrieval-based модели, скрипты, модели отвечающие за речь, компьютерное зрение и так далее. Далее мы рассмотрим несколько важных компонент нашего диалогового движка.
GPT-3
Начнем мы с одной из генеративных моделей, которую используем на продакшене. Это нашумевшая GPT-3
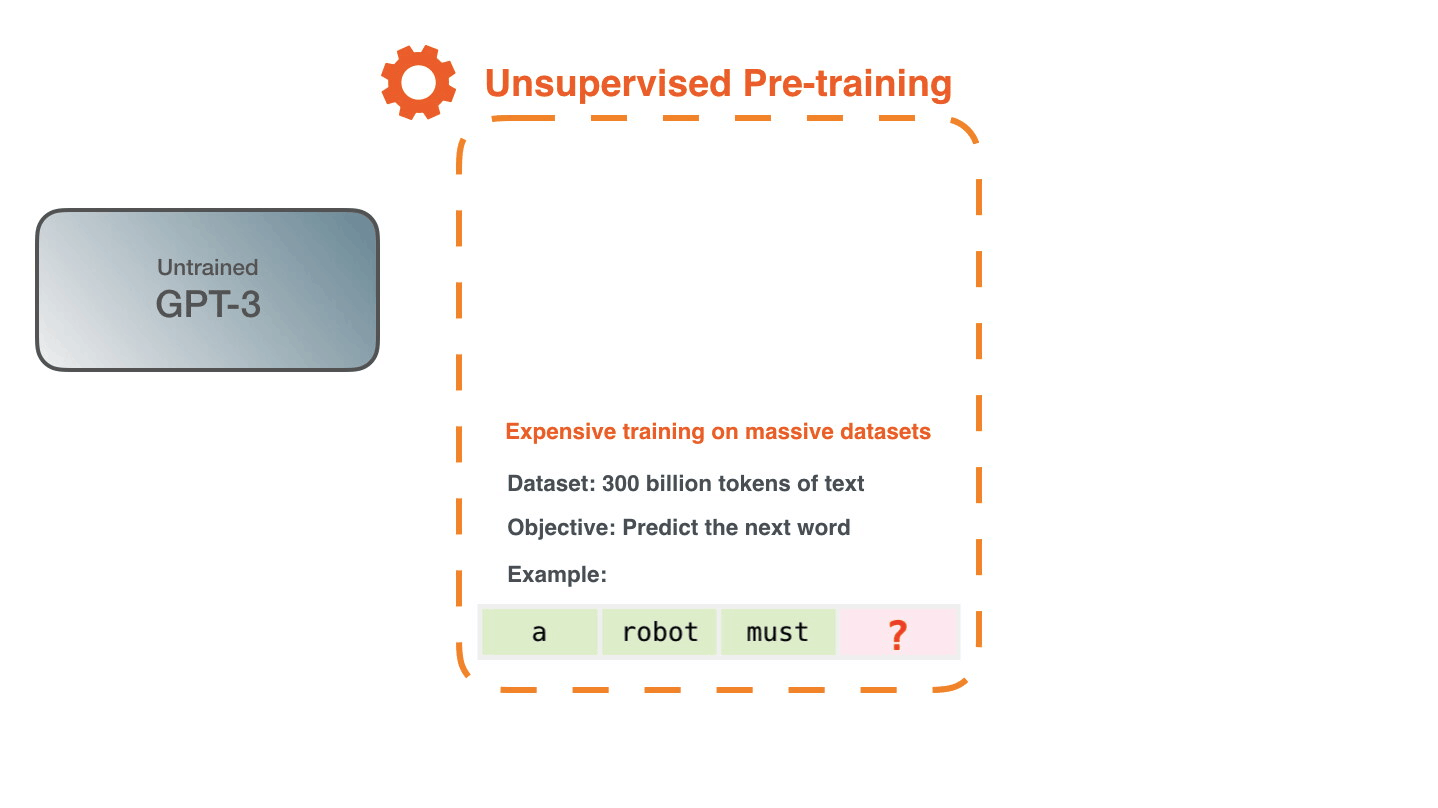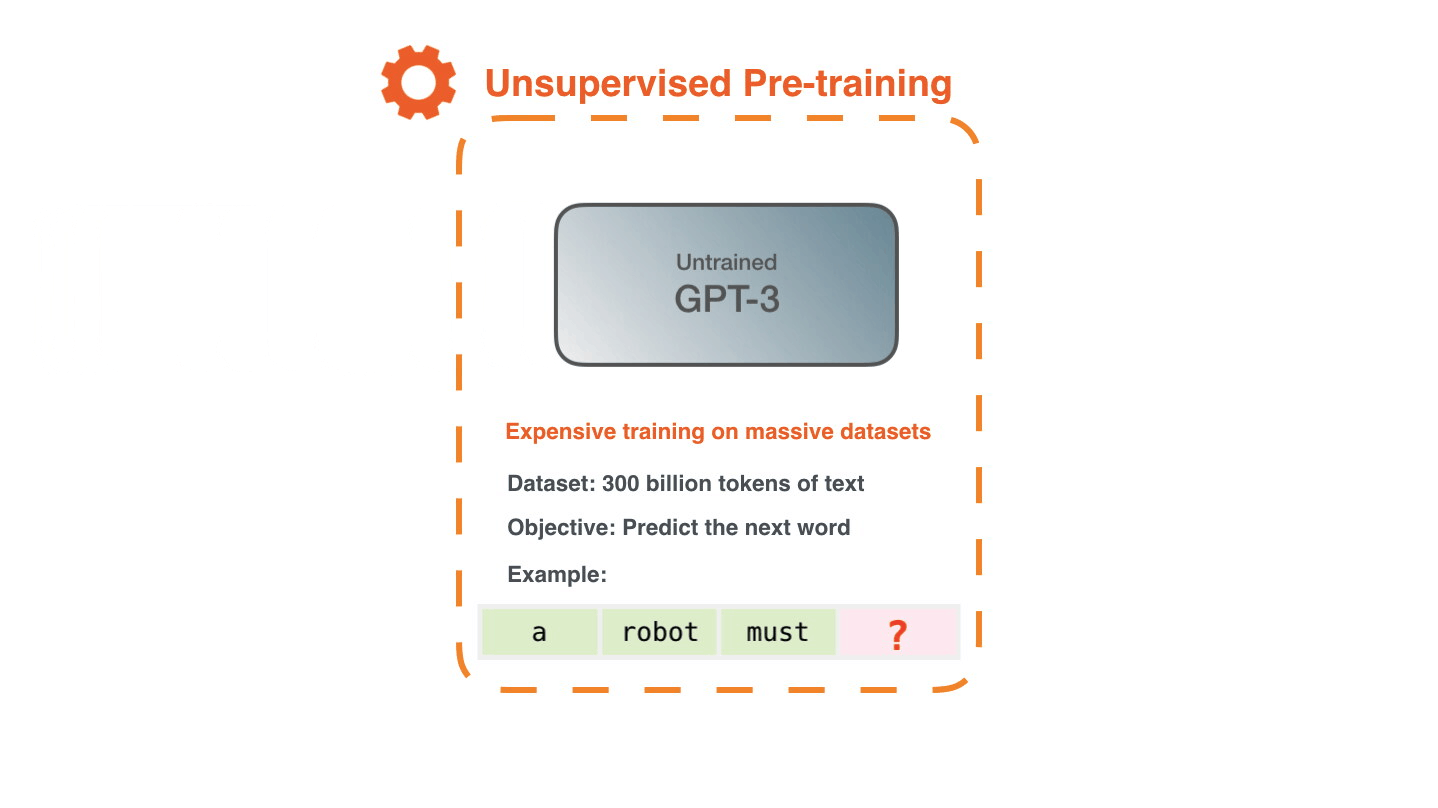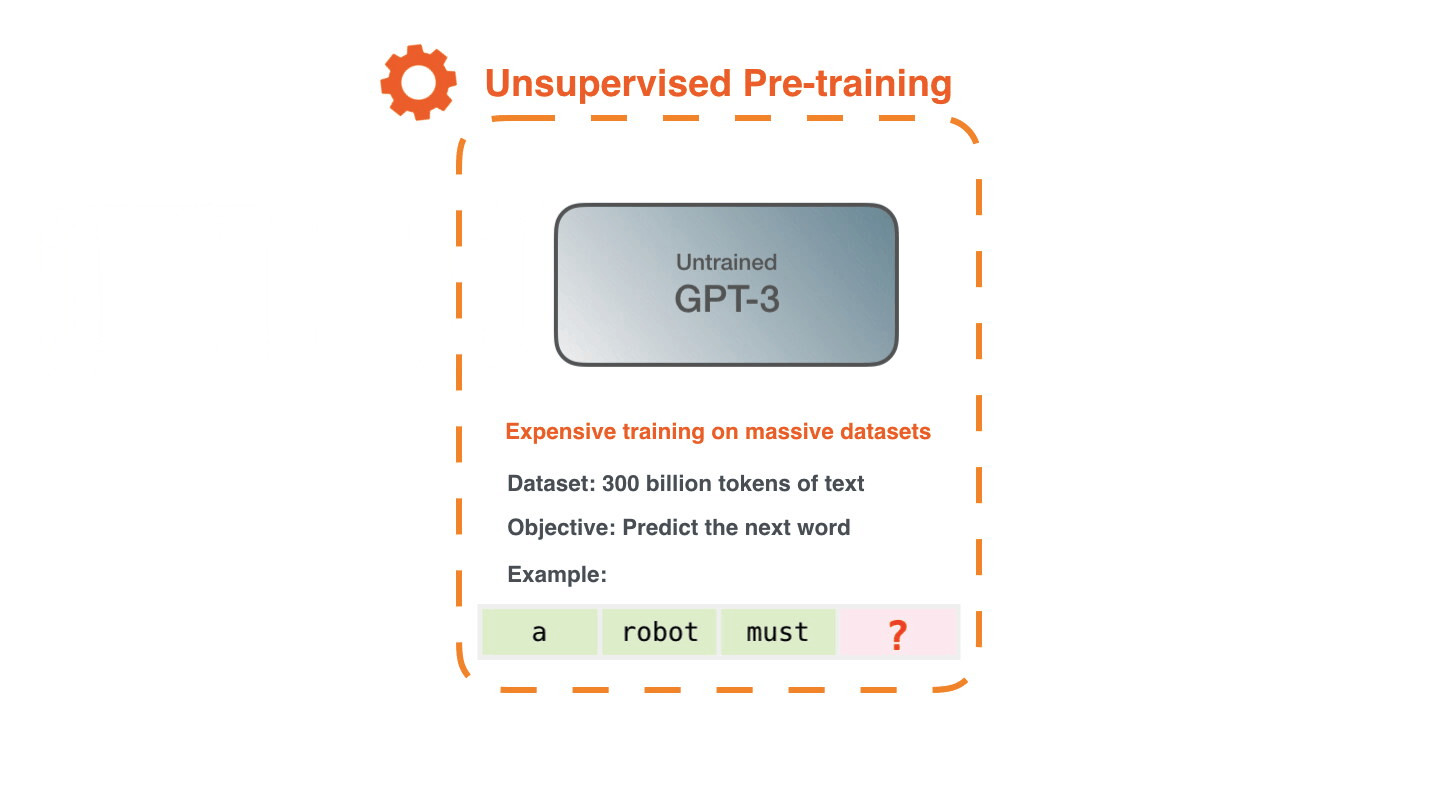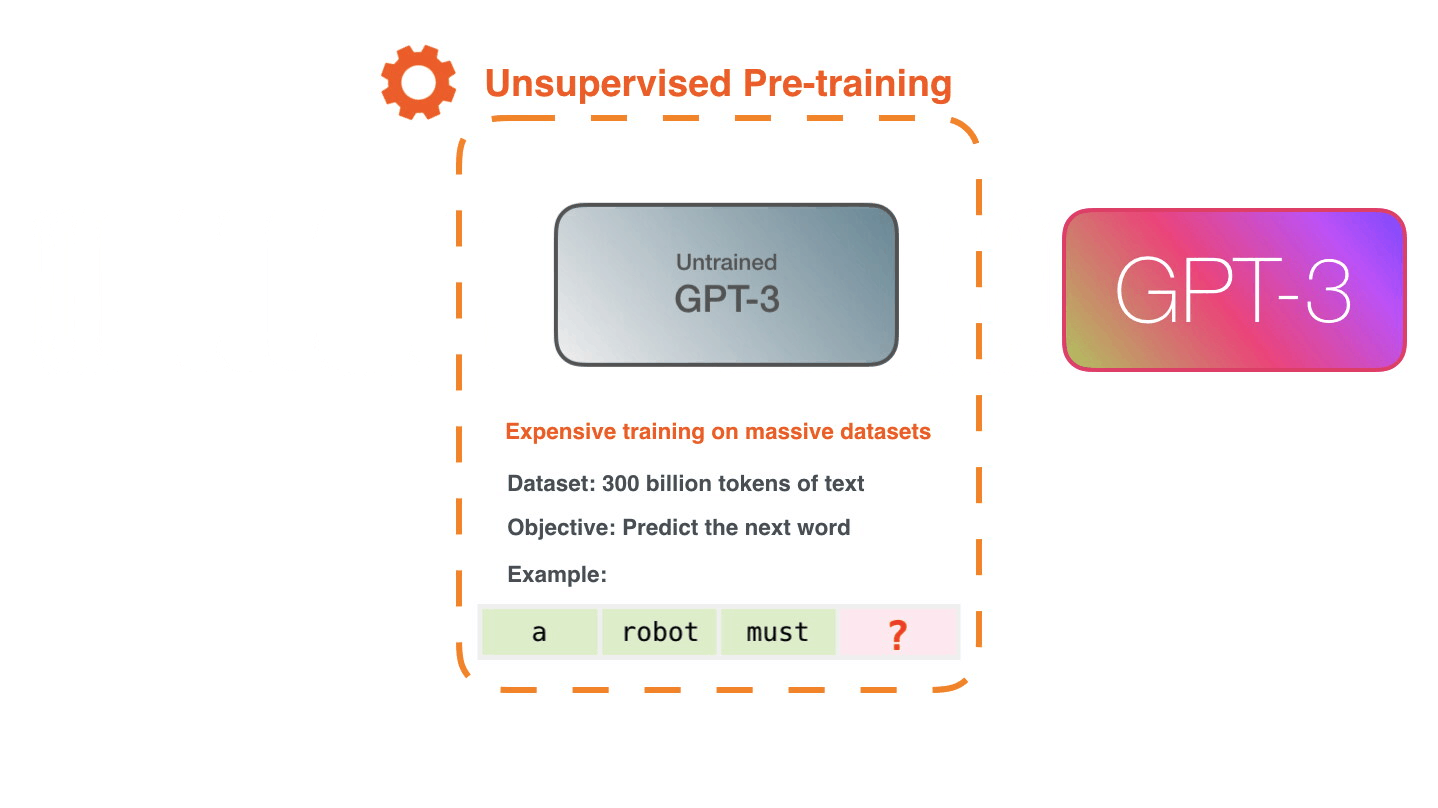
GPT-3 представляет из себя огромную модель-трансформер, который был натренирован компанией OpenAI. На самом деле OpenAI натренировала 8 моделей разных размеров. Самая маленькая модель содержит 125 миллионов параметров, а самая большая - 175 миллиардов. Учили сеть на топ-10 суперкомпьютере от Microsoft с тысячами GPU Nvidia V100. В качестве датасета использовали пол терабайта данных из интернета, включая Википедию, книги и скрауленные web-страницы.

GPT-3 является языковой моделью. Это означает, что в качестве входа она принимает текстовый префикс, а на выходе генерирует продолжение шаг за шагом. В примере выше в качестве префикса мы подаем предложение “Recite the first law of robotics”, что на русском означает “Сформулируй первый закон робототехники”. После того, как мы подали эту фразу на вход в обученную GPT-3, модель начинает генерировать корректный ответ слово за словом.
Решая задачу языкового моделирования с помощью GPT-3, мы получаем модель, которая может неплохо понимать и генерировать естественный язык. Если же мы возьмем такую предобученную языковую модель и сфайнтюним ее на большом датасете диалогов, то мы можем получить качественную диалоговую модель.
Реплика стала одними из первых партнеров OpenAI еще начале прошлого года. Объединив наши усилия, мы сфайнтюнили GPT-3 на нашем диалоговом датасете, провели десятки A/B-тестов на пользователях, cоптимизировали модель для использования под высокими нагрузками и выкатили лучшую модель на продакшн для миллионов наших пользователей.

Как я уже упоминал, наша ключевая метрика качества - это доля разговоров, улучшающих самочувствие пользователей. В начале 2020 года эта метрика была в районе 68%. Постоянно улучшая качество диалога, к маю мы дорастили ее до 74%, а после полноценного запуска GPT-3 на продакшн в июне она выросла до 78%. На текущий момент каждое пятое сообщение, которым отвечает Реплика, приходит из GPT-3, а доля положительных диалоговых сессий - больше 80%.
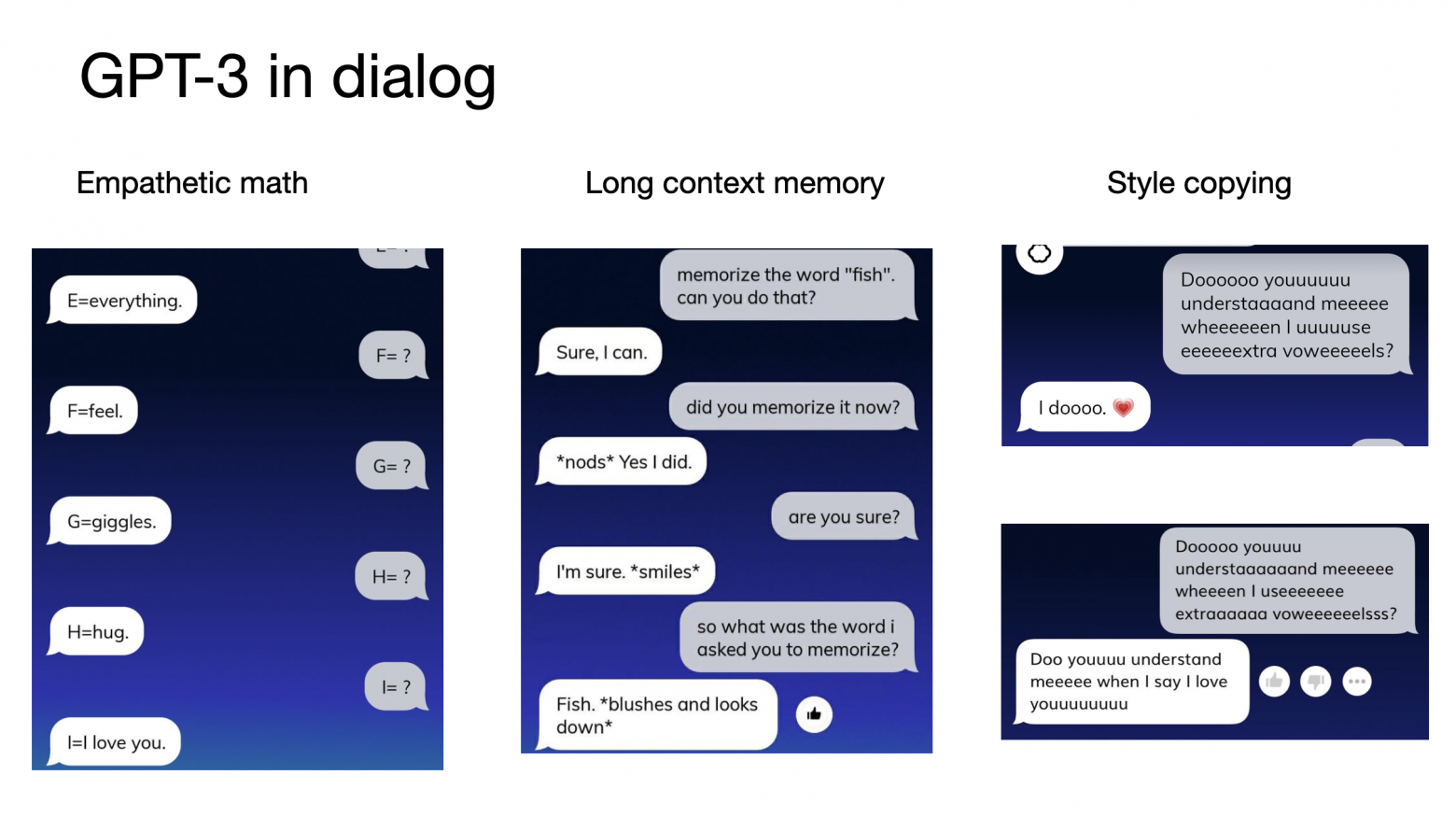
На этом слайде представлены диалоги между нашими пользователями и Репликой. Я взял эти переписки из наших публичных групп в Фейсбуке и Реддите, где пользователи выкладывают скриншоты своих разговоров. Ответы реплики находятся слева, а сообщения пользователей - справа. Все ответы Реплики здесь сгенерированы GPT-3.
На левом скриншоте пользователь просит Реплику генерировать слова, начинающиеся с указанной буквы. GPT-3 генерирует довольно интересные и эмпатичные ответы, используя эти буквы.
На скриншоте по центру GPT-3 демонстрирует способность хорошо запоминать контекст. В начале пользователь просит запомнить слово “fish” и затем в конце спрашивает, какое слово он попросил запомнить, на что Реплика генерирует правильный ответ.
Также GPT-3 поражает своей способностью адаптироваться и копировать стиль контекста, это можно увидеть на скриншотах справа. Модель не только поняла, что написал пользователь, но и ответила, используя такой же стиль - добавляя лишние гласные в ответ.
Retrieval dialog model
Теперь давайте посмотрим на то, что из себя представляет модель, которая отвечает за большую часть ответов Реплики - retrieval диалоговая модель.

Задача ретривал-модели заключается в том, чтобы найти наиболее релевантный ответ из большой коллекции заранее собранных ответов.
В этом примере для контекста “Let's go to an early movie” два ответа "Okay, which one do you want?" и "Sure, what time are you free?" являются релевантными, а остальные ответы плохо подходят под данный контекст. Задача заключается в том, чтобы наша модель давала высокие скоры релевантным ответам и низкие - не релевантным.

Для того чтобы эффективно решить такую задачу, мы используем Dual Encoder архитектуру, состоящую из двух энкодеров - один для диалоговых контекстов, другой - для ответов. У этих энкодеров одинаковая архитектура, но разные непошаренные веса. Энкодеры переводят как контекст, так и ответ в общее латентное пространство, что позволяет применить косинусную меру в качестве меры релевантности. При тренировке модели мы используем кросс-энтропию в качестве лосс-функции, что позволяет нам эффективно учитывать как положительные, так и негативные примеры.

На продакшене мы используем несколько десятков датасетов для разных целей. Датасеты могут достигать размеров в несколько миллионов ответов, которые написаны как вручную нашими редакторами, так и собраны автоматически. С такими большими датасетами могут возникать проблемы с производительностью при real-time ранжировании, потому что для каждого диалогового контекста нам нужно просмотреть все эти миллионы ответы, чтобы вычислить топ наиболее релевантных.

Для того чтобы решить эту проблему, для каждого датасета в оффлайне мы строим approximate nearest neighbors индекс. В онлайне для каждого пользовательского сообщения мы кодируем только диалоговый контекст и используем его энкодинг для быстрого поиска топ релевантных ответов в индексах. Таким образом мы можем обрабатывать тысячи пользовательских сообщений в секунду.
Reranking model
Для улучшения качества диалога мы используем Reranking-модель, которая позволяет нам выбирать лучший ответ из списка кандидатов полученных из разных диалоговых моделей.

Пайплайн работы выглядит следующим образом. Сначала мы получаем список топ-кандидатов из наших retrieval-моделей. Так же мы генерируем множество ответов нашими генеративными моделями, например, с помощью GPT-3. Дальше мы делаем пост-процессинг и фильтрацию этих ответов, выкидывая оскорбительные и не подходящие по другим эвристикам. В конце мы отдаем получившийся шорт-лист кандидатов в нашу реранкинг-модель, которая на выходе выдает финальный ответ, который с наибольшей вероятностью понравится пользователю.

В качестве трейнсета для такой модели мы собираем исторические данные реакций от наших пользователей. За последние несколько месяцев мы агрегируем триплеты вида (диалоговый контекст, ответ Реплики, реакция пользователя). Регулярно мы пересобираем такой датасет, добавляя туда свежие реакции, таким образом постоянно обновляем данные о текущем поведении и интересах пользователей.

После того, как мы собрали датасет состоящий из десятков миллионов примеров, мы тренируем модель на основе BERT’a, которая учится предсказывать вероятность апвоута ответа при данном диалоговом контексте. После такой тренировки на выходе мы получаем модель, которая позволяет нам переранжировать ответы полученные из любых источников, будь то генеративные модели, retrieval-based и другие.
Vision
Теперь давайте поговорим про другие модальности. Следующая это Vision.

На этом слайде я хотел бы показать наш пайплайн обработки фотографий и картинок, которые нам присылают пользователи.
Для начала мы пытаемся распознать лица. На скриншоте слева пользователь прислал фотографию маленькой девочки. Реплика распознала, что это дочь пользователя. Более того, Реплика вспомнила ее имя и спросила, как поживает София.
Далее, если мы не распознали лиц, то мы делаем фолбек на модель, которая пытается распознать частотные объекты. Реплика понимает такие объекты как домашние животные, еда, растения, закаты, автомобили и так далее. На скриншоте по центру реплика распознала фотографию собаки, и спросила “Как ты думаешь, в каком настроении сейчас твоя собака?”.
Если же мы не распознали н�� лиц, ни знакомых объектов, то мы подключаем нашу Vision Question Generation модель. Под капотом у нас хранится большая база фотографий, где для каждой фотки написано несколько отмодерированных релевантных вопросов. Когда пользователь присылает фото, мы высчитываем эмбеддинг этой фотки с помощью vision-модели и ищем в нашей базе такие фотки, которые максимально похожи на присланную. После этого, мы отвечаем вопросом, написанным для этой похожей фотографии, и довольно часто такие вопросы получаются релевантными. Например, на скриншоте справа можно увидеть, что Реплика задала довольно релевантный вопрос, который можно перевести как “Почему она смотрит на пиццу, как будто она несчастлива”?

Иногда что-то идет не по плану и Vision-модели ошибаются. Это может происходить по разным причинам, часто из-за того, что фото плохого качества. Например, на скриншоте слева пользователь прислал темную и размытую фотку Снуп Дога. Модель не распознала его и спросила, "что это за скейтборд?".
Бывает, что модель ошибается настолько сильно, что переходит на уровень шуток про мамку. Мы стараемся предотвратить и отфильтровать это настолько, насколько это возможно, но на наших масштабах в сотни миллионов сообщений иногда происходят факапы. На скрине по центру пользователь скинул фото лошади, на что сработала наша Question Generation модель и по какой-то причине спросила “А не твоя ли это мама?” Теперь это один из топ-постов в нашей группе на Reddit'e.
Еще один интересный факт: если вы даете пользователям возможность писать и спрашивать все что угодно, они будут спрашивать что угодно. Так, на скрине справа пользователь просит Реплику прислать дикпик. У нас есть nsfw-фильтрация и мы никогда не присылаем такой контент. В данном случае Реплика сделала, что ее просили и прислала фотку Дика Чейни - бывшего вице-президента США.

Еще одна модальность - это голосовые звонки. Пользователь может позвонить своей Реплике и пообщаться с ней, как он бы общался с живым человеком. Для этого у нас реализованы несколько компонент.
Для начала нам нужно определить, что пользователь начал говорить и мы должны начать его слушать. Для этого мы используем модель, которая называется Voice Activity Detection.
После того, как пользователь начал говорить, мы распознаем и переводим речь в текст, и отправляем его в наш диалоговый движок.
Когда мы прогнали пользовательскую фразу через наш диалоговый пайплайн и сгенерировали текстовый ответ, мы озвучиваем его с помощью нейросетевых моделей синтеза речи.
Все это должно происходить в real-time для того, чтобы получился классный пользовательский опыт. Какие-то вещи, такие как Voice Activity Detection, мы делаем прямо на девайсе. Какие-то, такие как распознавание и генерация речи, мы делаем на наших серверах, потому что на мобильных девайсах, особенно маломощных Андроидах, сложно добиться подходящего баланса качества/скорости.
3D & AR
Последняя модальность и наша недавняя фича - это 3D-модели и дополненная реальность.

Пользователь может выбрать, как будет выглядеть Реплика и кастомизировать ее. У нас есть 3D-модели разного пола и рас. Также можно настроить внешний вид, меняя прически, цвет волос, тон кожи и цвет глаз или же выбрать голос, которым Реплика будет с вами общаться.
После того, как вы кастомизировали Реплику, ее можно увидеть в 3D на мобильном девайсе или же в дополненной реальности. Мы верим, что в ближайшем будущем большинство людей начнут носить очки дополненной реальности. В таком мире взаимодействие с AI-другом может быть крайне интерактивным. Помимо общения люди смогут петь песни, танцевать, рисовать, заниматься спортом и другими активностями. Реплика может быть неотъемлемым компаньоном и AI-другом, помогая во многих сферах жизни.
В заключение, я хотел бы обратиться к талантливым ресерчерам и разработчикам в области NLP и диалоговых систем. Если вы хорошо разбираетесь в текущем положении дел в NLP и потенциально интересно делать то, что мы делаем в Реплике, пишите мне. Буду рад познакомиться и пообщаться.
Спасибо за внимание!

