Вступление
В этой статье я бы хотел поделиться способом написания асинхронных микросервисов на Python, общающихся друг с другом через Kafka. В основе этих микросервисов лежит библиотека потоковой обработки Faust. Но Faust - это не только работа с Kafka, он также содержит HTTP-сервер и планировщик для выполнения задач с определенным интервалом или по расписанию.
Несмотря на то, что в тестовом проекте используются такие инструменты и библиотеки, как FastAPI, Grafana, Prometheus, основная речь пойдет о Faust.
Faust
Это реализация Kafka Streams, но на Python. Ее разработали и активно используют в Robinhood для написания высокопроизводительных систем.
Библиотека работает с Python 3.6+, Kafka 0.10.1+ и поддерживает модули для хранения данных, сбора статистик и ускорения. С Faust можно использовать все привычные библиотеки Python: NumPy, SciPy, TensorFlow, SQLAlchemy и другие.
Архитектура проекта
Чтобы понять, как работать с чем-то, надо с этим поработать. Поэтому давайте реализуем простенький тестовый проект. Архитектура проекта изображена на диаграмме ниже.
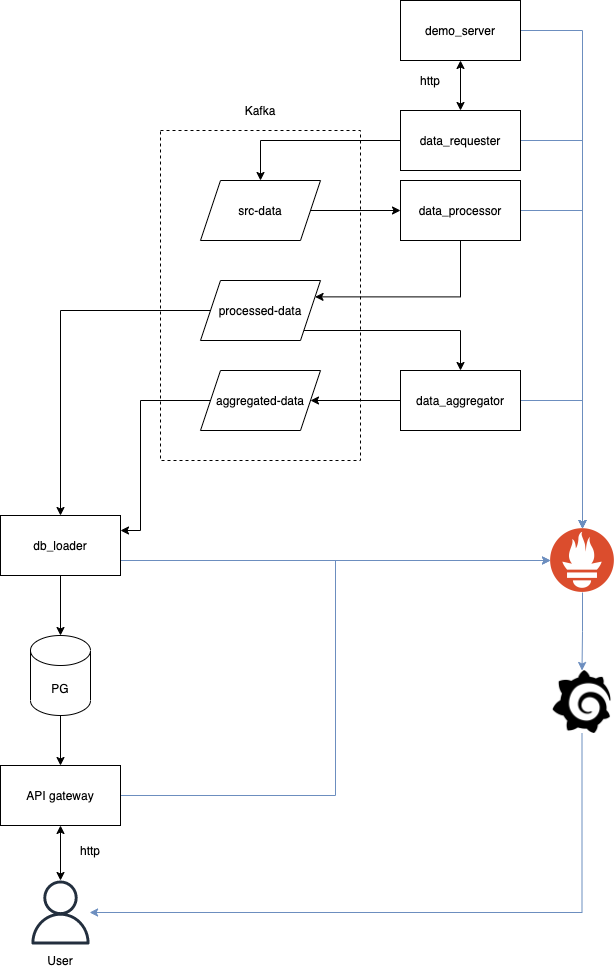
Тестовые данные будут формироваться в микросервисе под названием demo_server. Из него раз в секунду данные будут запрашиваться микросервисом data_requester. Data_requester - первый микросервис в нашей системе с Faust. После запроса data_requester кладет ответ в Kafka. Далее это сообщение вычитывает data_processor, обрабатывает его и кладет обратно в Kafka. Затем его вычитывает data_aggregator и db_loader. Первый сервис высчитывает средние значения, второй складывает все в базу. Также db_loader складывает в базу все сообщения, сгенерированные data_aggregator. Ну а из базы данные забирает api_gateway по запросу пользователя. Все это мониторится с помощью Prometheus и отображается на графиках в Grafana. Весь проект и все дополнительные сервисы запускаются в docker-compose.
Шаг 1. Инфраструктура
Как уже говорилось, мы будем запускать все в docker-compose, поэтому первым делом опишем все сторонние сервисы. Нам нужна Kafka, база, админка для базы, мониторинг сервисов - prometheus и grafana. В качестве базы возьмем Postgres, для удобства ее администрирования и мониторинга поставим PgAdmin. На данный момент наш docker-compose.yml будет выглядеть так:
version: '3' services: kafka: image: confluentinc/cp-kafka:${CONFLUENT_VERSION} depends_on: - zookeeper ports: - ${KAFKA_PORT}:9092 - ${KAFKA_LOCALHOST_PORT}:9093 environment: KAFKA_BROKER_ID: 1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_LISTENERS: INTERNAL://0.0.0.0:9092,PLAINTEXT://0.0.0.0:9093 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka:9092,PLAINTEXT://localhost:9093 KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 KAFKA_AUTO_CREATE_TOPICS_ENABLE: "false" KAFKA_LOG4J_ROOT_LOGLEVEL: INFO KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0 KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1 KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1 KAFKA_MESSAGE_MAX_BYTES: 10485760 KAFKA_SOCKET_REQUEST_MAX_BYTES: 100001200 restart: always volumes: - ./kafka-data:/var/lib/kafka/data zookeeper: image: zookeeper:${ZK_VERSION} ports: - ${ZK_PORT}:2181 restart: always volumes: - ./zk-data:/var/lib/zookeeper/data \ - ./zk-txn-logs:/var/lib/zookeeper/log \ kafka-actualizer: image: confluentinc/cp-kafka:${CONFLUENT_VERSION} depends_on: - kafka volumes: - ./docker/wait-for-it.sh:/wait-for-it.sh command: | bash -c '/wait-for-it.sh --timeout=0 -s kafka:9092 && \ kafka-topics --create --if-not-exists --topic src-data --partitions 8 --replication-factor 1 --zookeeper zookeeper:2181 && \ kafka-topics --create --if-not-exists --topic processed-data --partitions 8 --replication-factor 1 --zookeeper zookeeper:2181 && \ kafka-topics --create --if-not-exists --topic aggregated-data --partitions 8 --replication-factor 1 --zookeeper zookeeper:2181 && \ exit 0' environment: KAFKA_BROKER_ID: ignored KAFKA_ZOOKEEPER_CONNECT: ignored db: image: postgres:${PG_VERSION} restart: always environment: POSTGRES_DB: currencies POSTGRES_USER: postgres POSTGRES_PASSWORD: postgres volumes: - ./postgres-data:/var/lib/postgresql ports: - ${PG_PORT}:5432 pgadmin: image: chorss/docker-pgadmin4 restart: always volumes: - ./pgadmin:/data ports: - ${PG_ADMIN_PORT}:5050 depends_on: - db prometheus: image: quay.io/prometheus/prometheus:${PROMETHEUS_VERSION} ports: - ${PROMETHEUS_PORT}:9090 volumes: - ./prometheusconfig/prometheus.yml:/etc/prometheus/prometheus.yml grafana: image: grafana/grafana:${GRAFANA_VERSION} user: root restart: unless-stopped container_name: grafana ports: - ${GRAFANA_PORT}:3000 volumes: - ./grafana-data/data:/var/lib/grafana - ./grafana-data/certs:/certs - ./grafana/provisioning:/etc/grafana/provisioning - ./grafana/dashboards:/var/lib/grafana/dashboards environment: - GF_SECURITY_ADMIN_PASSWORD=admin
Docker-compose с инфраструктурой, всеми конфигами и вспомогательными скриптами лежит в отдельной папке репозитория.
Общие компоненты микросервисов
Несмотря на то, что каждый сервис выполняет свою определенную задачу и написан с использованием двух разных библиотек - FasAPI и Faust - у них есть общие компоненты.
Первый - загрузчик конфигов, основанный на библиотеке configloader. Он позволяет загружать конфиги из yaml-файлов и переопределять их значения через переменные окружения. Это очень полезно в случае, когда надо переопределить значение в docker-контейнере.
Второй - prometheus exporter. Его очень удобно использовать для экспорта метрик и отображения их в Grafana. Здесь реализация в FastAPI и Faust немного отличается, что мы и увидим дальше.
Шаг 2. Эмулятор данных
Для теста и демонстрации работы всей системы будет использоваться простенький сервис, который отдает значение валютных пар в JSON-формате. Для этого воспользуемся библиотекой FastAPI. Он такой же простой в использование, как и Flask, но асинхронный и с документацией swagger UI из коробки. Доступна по ссылке: http://127.0.0.1:8002/docs
У сервиса опишем всего один запрос:
@router.get("/pairs", tags=["pairs"]) async def get_pairs() -> Dict: metrics.GET_PAIRS_COUNT.inc() return { "USDRUB": round(random.random() * 100, 2), "EURRUB": round(random.random() * 100, 2) }
Как видно в примере кода, при каждом запросе в��звращается JSON с двумя парами, значения которых генерируются случайно. Пример ответа:
{ "USDRUB": 85.33, "EURRUB": 65.03 }
Для мониторинга подключаем Prometheus. Тут он подключается как middleware, а также для него определяется отдельный путь.
app = FastAPI(title="Metrics Collector") app.include_router(routes.router) app.add_middleware(PrometheusMiddleware) app.add_route("/metrics", handle_metrics)
Все метрики можно посмотреть и через браузер: http://127.0.0.1:8002/metrics
Шаг 3. Микросервис запроса данных
Данные с демосервера запрашивает микросервис api_requester. Вот здесь уже используем библиотеку Faust. Так как Faust - асинхронный, то и для запросов тестовых данных будем использовать клиент aiohttp.
Первым делом создаем приложение Faust:
app = faust.App(SERVICE_NAME, broker=config.get(config_loader.KAFKA_BROKER), value_serializer='raw', web_host=config.get(config_loader.WEB_HOST), web_port=config.get(config_loader.WEB_PORT))
При создании определяем имя приложения - обязательный аргумент. Если мы запустим несколько экземпляров сервиса с одинаковым именем, Kafka распределит партиции между ними, что позволит масштабировать нашу систему горизонтально. Также задаем тип сериализации сообщений в параметре value_serializer. В данном примере raw читаем, как есть и сами сериализуем полученные сообщения. Также мы задаем адрес и порт, на котором будет доступен HTTP-сервер, предоставляемый Faust.
Далее описываем топик, в который будем отправлять полученные от demo_server ответы.
src_data_topic = app.topic(config.get(config_loader.SRC_DATA_TOPIC), partitions=8)
Первый аргумент и он же обязательный - имя топика. Далее идет опциональный - число партиций. Оно должно быть равно числу партиций топику в Kafka, которое было указано при создании.
Cервис data_requester не читает сообщений из топиков, но каждую секунду отправляет запрос в эмулятор данных и обрабатывает ответ. Для этого надо описать функцию, вызываемую по таймеру с заданным интервалом.
@app.timer(interval=1.0) async def request_data() -> None: provider = data_provider.DataProvider(base_url=config.get(config_loader.BASE_URL)) pairs = await provider.get_pairs() metrics.REQUEST_CNT.inc() logger.info(f"Received new pairs: {pairs}") if pairs: await src_data_topic.send(key=uuid.uuid1().bytes, value=json.dumps(pairs).encode())
О том, что функция выполняется переодически, говорит декоратор @app.timer. В качестве аргумента он принимает интервал в секундах. Функция создает экземпляр класса DataProvider, который отвечает за запрос данных. После каждого запроса увеличиваем счетчик в Prometheus. И если данные в запросе пришли, то отправляем их в топик. Так как Kafka работает с ключом и сообщениями в байтах, то нам надо сериализовать наши данные перед отправкой.
Также нам надо проинициировать Prometheus при старте приложения. Для этого удобно использовать функцию, вызываемую во время запуска приложения:
@app.task async def on_started() -> None: logger.info('Starting prometheus server') start_http_server(port=config.get(config_loader.PROMETHEUS_PORT))
Опять-таки, назначение функции определяется декоратором @app.task. Сам Prometheus запускается как отдельный сервер на своем порту, работающий параллельно с HTTP-сервером, запущенный Faust.
Вот и все! Легко и просто описали запрос и отправку данных в Kafka каждую секунду. Да еще и мониторинг прикрутили.
Шаг 4. Микросервис обработки данных
Следующий микросервис - data_processor - занимается обработкой пар, полученных от микросервиса api_requester. Код инициализации приложения и мониторинга идентичен коду предыдущего сервиса. Но этот сервис получает сообщения из топика и обрабатывает их. Для этого надо описать функцию:
@app.agent(src_data_topic) async def on_event(stream) -> None: async for msg_key, msg_value in stream.items(): metrics.SRC_DATA_RECEIVED_CNT.inc() logger.info(f'Received new pair message {msg_value}') serialized_message = json.loads(msg_value) for pair_name, pair_value in serialized_message.items(): logger.info(f"Extracted pair: {pair_name}: {pair_value}") metrics.PROCESSED_PAIRS_CNT.inc() await processed_data_topic.send(key=msg_key, value=json.dumps({pair_name: pair_value}).encode()) metrics.PROCESSED_DATA_SENT_CNT.inc()
Для этой функции использовали декоратор @app.agent(src_data_topic), говорящий о том, что функция будет отрабатывать на сообщения в топике src_data_topic. Сообщения мы вычитываем в цикле async for msg_key, msg_value in stream.items()
Далее сериализуем полученное сообщение и извлекаем валютные пары и их значения. Каждую пару мы записываем в следующий топик по отдельности.
Шаг 5. Микросервис агрегации данных
Два предыдущих сервисса читали и писали данные в Kafka потоком. Каждое новое сообщение они обрабатывали независимо от предыдущих. Но переодически возникает необходимость обработать сообщения совместно с предыдущими. В нашем случае хотелось бы посчитать среднее для последних 10 значений пар. А это значит, что нам надо где-то хранить эти последние 10 значений. Локально не получится. Если мы запустим несколько экземляров сервиса агрегаций, то каждый будет хранить локально только свои значения, а это, в свою очередь, приведет к некорректным средним значениям. Тут на выручку придут таблицы Faust.
average_table = app.Table('average', default=dict)
Таблицы хранят значения в changelog-топике, а также локально в rocksdb. Это позволяет всем экземплярам сервиса работать синхронно, а при перезапуске быстро восстанавливать состояние из локальной базы и, вычитав доступный changelog, продолжить работу. Имя топика для таблицы формируется следующим методом: <service-name>-<table-name>-changelog. В нашем случае имя топика будет следующим: data-aggregator-average-changelog.
С обработкой новых сообщений и хранением их в таблице опять-таки ничего сложного:
@app.agent(processed_data_topic) async def on_event(stream) -> None: async for msg_key, msg_value in stream.items(): metrics.PROCESSED_DATA_RECEIVED_CNT.inc() logger.info(f'Received new processed data message {msg_value}') serialized_message = json.loads(msg_value) for pair_name, pair_value in serialized_message.items(): average_value = average_table.get(pair_name, {}) if average_value: average_value['history'].append(pair_value) average_value['history'] = average_value['history'][-10:] average_value['average'] = round(sum(average_value['history']) / len(average_value['history']), 2) else: average_value['history'] = [pair_value] average_value['average'] = pair_value logger.info(f"Aggregated value: {average_value}") average_table[pair_name] = average_value metrics.PAIRS_AVERAGE_AGGREGATED_CNT.inc()
Как видно, мы также описываем функцию - обработку сообщения в топике. И каждое новое значение сохраняем в нашу таблицу и считаем среднее. С таблицей же работаем, как и с обычным словарем в Python.
Шаг 6. Микросервис загрузки в базу
Микросервис db_loader у нас вычитывает сразу два топика - processed_data и data-aggregator-average-changelog. В первый топик пишет сообщения data_processor, во второй - data_aggregator. Поэтому нам надо описать две функции обработки сообщений.
@app.agent(average_changelog_topic) async def on_average_event(stream) -> None: async for msg_key, msg_value in stream.items(): metrics.AVERAGE_TOPIC_RECEIVED_CNT.inc() logger.info(f'Received new average message {msg_key}, {msg_value}') serialized_message = json.loads(msg_value) await db.save_average(pair_name=msg_key.decode(), value=serialized_message['average']) metrics.AVERAGE_TOPIC_SAVED_CNT.inc() @app.agent(processed_data_topic) async def on_processed_data_event(stream) -> None: async for msg_key, msg_value in stream.items(): metrics.PROCESSED_DATA_RECEIVED_CNT.inc() logger.info(f'Received new pair message {msg_key}, {msg_value}') serialized_message = json.loads(msg_value) for pair_name, pair_value in serialized_message.items(): await db.save_currency(pair_name=pair_name, value=pair_value) metrics.PROCESSED_DATA_SAVED_CNT.inc()
Как и в остальных сервисах, тут ничего сложного: читаем сообщение, кладем его в базу, обновляем метрики. Для работы с базой воспользуемся ORM SQLAlchemy. Многие с ней сталкивались и не раз, единственный важный момент в нашем случае - она должна работать асинхронно. Для этого мы устанавливаем нужные зависимости.
asyncpg==0.23.0 SQLAlchemy==1.4.0
В конфиге указываем DB URI:
DB_URI: "postgresql+asyncpg://postgres:postgres@127.0.0.1:5432/currencies"
А в коде для работы с базой используем асинхронные сессии.
from sqlalchemy.ext.asyncio import AsyncSession ... async def save_currency(self, pair_name: str, value: float) -> None: async with AsyncSession(self.db_engine) as session: async with session.begin(): logger.info(f"Save currency {pair_name}: {value}") currency = Currencies(pair_name=pair_name, value=value) session.add(currency) async def save_average(self, pair_name: str, value: float) -> None: async with AsyncSession(self.db_engine) as session: async with session.begin(): selected_average_execution = await session.execute( select(Average).filter(Average.pair_name == pair_name)) selected_average = selected_average_execution.scalars().first() if selected_average: logger.info(f"Update existing average {pair_name}: {value}") selected_average.value = value else: logger.info(f"Save average {pair_name}: {value}") currency = Average(pair_name=pair_name, value=value) session.add(currency)
Шаг 7. Сервис запроса результатов
Для запроса результатов из базы напишем простенький сервис на FastAPI, который будет вычитывать данные из базы и отдавать их в JSON. Для работы с базой возьмем ту же ORM, как и в предыдущем шаге. Ну а касательно FastAPI, справедливо все сказанное в шаге 2 “Эмуляция данных”.
Итог
Как видно, писать микросервисы для работы с Kafka на Python не так уж и сложно. Всю работу по взаимодействию с Kafka берет на себя бибоиотека Faust. Нам же надо просто описать функции обработки новых сообщений.
