
Итак, существует большое количество платных сервисов, например vuldb.com или vulners.com, которые предоставляют информацию об уязвимостях по подписке. В этой статье я приведу бесплатные источники, с которыми за полгода мы собрали информацию об 3153 уязвимости, для их дальнейшего ресерча.
Если вы открыли эту статью, то я надеюсь что знакомы с такими понятиями как cve, cvss, cpe, но, на всякий случай сделал сущности кликабельными, чтобы Вы могли освежить память.
Далее в статье будет питоновский код, и там где будет слишком много строк, для Вашего удобства я буду прятать его в спойлеры
Теперь, когда Вы освежили знания, определимся со следующими вопросами:
Откуда собирать информацию об уязвимостях?
Какую именно информацию собирать об уязвимостях?
Где и как это всё хранить?
По ходу статью я отвечу на все вопросы. Ну что ж, приступим.
Информацию о новых уязвимостях мы собираем со следующих источников:
Сайт opencve.io
Сайт cvetrends.com
С вышеперечисленных сайтов собираются только идентификаторы уязвимостей (например CVE-2021-40444), после чего по каждому идентификатору делается запрос на сайт nvd.nist.gov (через питоновскую библиотеку) и уже оттуда мы парсим всю необходимую нам информацию.
Теперь подробнее о реализации скрапинга идентификаторо�� уязвимостей с агрегаторов информации:
Бюллетени НКЦКИ
Ну тут всё понятно - рекомендации по устранению уязвимостей от Национального координационного центра по компьютерным инцидентам.
Сами бюллетени выпускаются в формате pdf, поэтому функции для парсинга будут выглядеть так:
Пример кода для скрапинга
# parse bulletine NKCKI------------------------------------------------------------------------------------------------ def get_cve_list(name_list): cve_list = [] cve_list_repeat = [] for name in name_list: pdf_file = open(f'{PATH}/{name}', 'rb') read_pdf = PyPDF2.PdfFileReader(pdf_file) number_of_pages = read_pdf.getNumPages() data = '' for i in range(number_of_pages): page = read_pdf.getPage(i) page_content = page.extractText() data1 = json.dumps(page_content) data += data1 rez = '' for n, item in enumerate(data, start=0): if item != '\\': rez += data[n] result = '' for n, item in enumerate(rez, start=0): if item != 'n': result += rez[n] rez1 = result.replace(" ", "") regex = re.findall(r'CVE-\d{4}-\d{4,8}', rez1) for cve in regex: cve_list_repeat.append(cve) for item in cve_list_repeat: if item not in cve_list: cve_list.append(item) return cve_list def get_links_for_bulletine(): links = [] for page in range(3): r = requests.get("https://safe-surf.ru/specialists/bulletins-nkcki/?PAGEN_1={}".format(page)) soup = BeautifulSoup(r.text, "html.parser") for vuln in soup.find_all("div", "blockBase blockBulletine"): bulletin_pdf_url = "https://safe-surf.ru{}".format(vuln.find('h4').find('a')['href']) links.append(bulletin_pdf_url) return links def create_pdf_file(links): for str in links: get = requests.get(str) name = str.replace("https://safe-surf.ru/upload/VULN/", "") check_file = os.path.exists(f'{PATH}/{name}') if check_file == 0: with open(f'{PATH}/{name}', 'wb') as f: f.write(get.content) else: print(f'file {name} already exists') def get_name_list(path): name_list = os.listdir(path) return name_list def remove_pdf_file(path): for item in path: os.remove(item) links = get_links_for_bulletine() create_pdf_file(links) name_list = get_name_list(PATH) # Получение имен скаченных файлов для парсинга cve_line = get_cve_list(name_list) # Получение списка cve из биллютеня НКЦКИ print(cve_line) # remove pdf buffer--------------------------------------------------------------------------------------------------- time.sleep(1) path_to_remove_pdf = [] for item in name_list: path_to_remove_pdf.append(f'{PATH}/{item}') remove_pdf_file(path_to_remove_pdf)
На вход скрипт принимает путь до папки, в которую он будет скачивать (и потом удалять) сами бюллетени, для того, чтобы вытянуть из них нужную информацию.
На выходе получается следующее:
['CVE-2022-30472', 'CVE-2022-30473', 'CVE-2022-30475', 'CVE-2022-30476', 'CVE-2022-30477', 'CVE-2022-30474', 'CVE-2022-30190', 'CVE-2022-1888', 'CVE-2022-1934', 'CVE-2022-26700', 'CVE-2022-26716', 'CVE-2022-26719', 'CVE-2022-26709', 'CVE-2022-30294', 'CVE-2022-26717', 'CVE-2022-30293', 'CVE-2022-26945', 'CVE-2022-27184', 'CVE-2022-28690', 'CVE-2022-30540', 'CVE-2022-29078', 'CVE-2021-23820', 'CVE-2022-22963', 'CVE-2022-22965', 'CVE-2021-3634', 'CVE-2022-1154', 'CVE-2022-1271', 'CVE-2022-23772', 'CVE-2022-25235', 'CVE-2022-25313', 'CVE-2022-25314', 'CVE-2022-25315', 'CVE-2022-27871', 'CVE-2022-28463', 'CVE-2021-3254', 'CVE-2022-1517', 'CVE-2022-1518', 'CVE-2022-1519', 'CVE-2022-1521', 'CVE-2022-29897', 'CVE-2022-29898', 'CVE-2022-31479', 'CVE-2022-31480', 'CVE-2022-31481', 'CVE-2022-26134']
Сайт opencve.io
Особенность данного сайта в том, что он предоставляет информацию только по тем продуктам и вендорам (тут пожалуй следует упомянуть про инвентаризацию ваших активов), которые вы выберете в своем профиле (да, нужна регистрация, но не нужно никакой платной подписки). Сам сайт также парсит nvd.nist.gov и либо заводит информацию о новой уязвимости (is a new CVE), либо обновляет информацию об уже заведенной (has changed):

Мы решили собирать информацию только о новых уязвимостях (is a new CVE), потому что обновляем информацию об уже заведенных сами:
Пример кода для скрапинга
# parse opencve.io---------------------------------------------------------------------------------------------------- def parsing_opencve(): url1 = 'https://www.opencve.io/login/' url2 = 'https://www.opencve.io/login' csrf_token = '' s = requests.Session() response = s.get(url1) soup = BeautifulSoup(response.text, 'lxml') # Get CSRF for a in soup.find_all('meta'): if 'name' in a.attrs: if a.attrs['name'] == 'csrf-token': csrf_token = a.attrs['content'] # Authentication s.post( url2, data={ 'username': USERNAME, 'password': PASSWORD, 'csrf_token': csrf_token, }, headers={'referer': 'https://www.opencve.io/login'}, verify=False ) # Get new CVE cve_line = [] for page_num in range(1, 20): pagination = f'https://www.opencve.io/?page={page_num}' resp = s.get(pagination) parse = BeautifulSoup(resp.text, 'lxml') for cve in parse.find_all('h3', class_='timeline-header'): index = cve.text.find('has changed') if index == -1: cve_line.append(cve.text.replace(' is a new CVE', '')) cve_line_no_replic = [] for item in cve_line: if item not in cve_line_no_replic: cve_line_no_replic.append(item[:-1]) return cve_line_no_replic cve_line = parsing_opencve() # Получение списка новых cve с сайта opencve.io print(cve_line)
На вход скрипт принимает только креды (логин и пароль) от вашей учетной записи на opencve.io.
На выходе также, список идентификаторов уязвимостей:
['CVE-2022-29170', 'CVE-2022-28660', 'CVE-2022-20795', 'CVE-2022-22191', 'CVE-2022-22193', 'CVE-2022-22197', 'CVE-2022-22196', 'CVE-2022-22185', 'CVE-2022-22186', 'CVE-2022-22182', 'CVE-2022-22188', 'CVE-2022-22181', 'CVE-2022-22198', 'CVE-2022-24828', 'CVE-2022-24812', 'CVE-2022-26148', 'CVE-2022-22943', 'CVE-2022-0711', 'CVE-2022-24329', 'CVE-2021-29220', 'CVE-2022-21824', 'CVE-2021-44531', 'CVE-2021-44532', 'CVE-2021-44533', 'CVE-2021-22041', 'CVE-2021-22040', 'CVE-2022-21703', 'CVE-2022-21713', 'CVE-2022-21702', 'CVE-2022-23601', 'CVE-2022-22938', 'CVE-2021-46088', 'CVE-2022-22176', 'CVE-2022-22156', 'CVE-2022-22153', 'CVE-2022-22154', 'CVE-2022-22177', 'CVE-2022-22172', 'CVE-2022-22167', 'CVE-2022-22170', 'CVE-2022-22166', 'CVE-2022-22163', 'CVE-2022-22176', 'CVE-2022-22160', 'CVE-2022-22170', 'CVE-2022-22180', 'CVE-2022-22167', 'CVE-2022-22172', 'CVE-2022-22161', 'CVE-2022-22171', 'CVE-2022-22154', 'CVE-2022-22173', 'CVE-2022-22169', 'CVE-2022-22177', 'CVE-2022-22178', 'CVE-2022-22156', 'CVE-2022-22168', 'CVE-2022-21673', 'CVE-2022-23134', 'CVE-2022-23133', 'CVE-2022-23132', 'CVE-2022-23131', 'CVE-2021-22045', 'CVE-2020-19316', 'CVE-2021-43815', 'CVE-2021-43813', 'CVE-2021-43803', 'CVE-2021-43808', 'CVE-2021-43798', 'CVE-2021-41270', 'CVE-2021-41267', 'CVE-2021-41268', 'CVE-2021-3935']
Сайт cvetrends.com:
На данном сайте отображаются топ-10 уязвимостей на данный момент.
С него также "дергаем" идентификаторы уязвимостей:
Пример кода для скрапинга
# parse cvetrends.com-------------------------------------------------------------------------------------------------- def get_top_cve_list(): link = 'https://cvetrends.com/api/cves/24hrs' r = requests.get(link) soup = BeautifulSoup(r.text, "lxml") regex = re.findall(r'"cve": "CVE-\d{4}-\d{4,8}"', soup.get_text()) top_cve_list = [] for item in regex: top_cve_list.append(re.search(r'CVE-\d{4}-\d{4,8}', item).group()) return top_cve_list top_cve_list = get_top_cve_list() # Получение топа cve с cvetrends.com print(top_cve_list)
На вход данный скрипт ничего не принимает, на выходе список идентификаторов:
['CVE-2022-30190', 'CVE-2022-26134', 'CVE-2022-32275', 'CVE-2022-32250', 'CVE-2022-30075', 'CVE-2022-32276', 'CVE-2202-26134', 'CVE-2022-29464', 'CVE-2020-3452', 'CVE-2021-40444']
Теперь по каждой уязвимости необходимо собрать нужную нам информацию:
Название уязвимости
Описание уязвимости
Дата публикации уязвимости
Дата выявления уязвимости
CPE для данной уязвимости
CVSSv3 Score
CVSSv3 Vector
Продукты и версии пакетов для которых актуальна уязвимость
Необходимые ссылки (далее в статье будет пояснение)
Наличие эксплоитов в открытых источниках
Наличие смягчающих мер (далее в статье также будет пояснение)
Иные нужные сущности
Теперь обо всём по порядку.
Название уязвимости
Ну тут всё очевидно. Название уязвимости это и есть идентификатор уязвимости, однако мы пошли чуть дальше и добавили несколько паттернов, чтобы даже по названию можно было сразу классифицировать уязвимость:
pattern = ['Stack-based buffer overflow', 'Arbitrary command execution', 'Obtain sensitive information', 'Local privilege escalation', 'Security Feature Bypass', 'Out-of-bounds read', 'Out of bounds read', 'Denial of service', 'Denial-of-service', 'Execute arbitrary code', 'Expose the credentials', 'Cross-site scripting (XSS)', 'Privilege escalation', 'Reflective XSS Vulnerability', 'Execution of arbitrary programs', 'Server-side request forgery (SSRF)', 'Stack overflow', 'Execute arbitrary commands', 'Obtain highly sensitive information', 'Bypass security', 'Remote Code Execution', 'Memory Corruption', 'Arbitrary code execution', 'CSV Injection', 'Heap corruption', 'Out of bounds memory access', 'Sandbox escape', 'NULL pointer dereference', 'Remote Code Execution', 'RCE', 'Authentication Error', 'Use-After-Free', 'Use After Free', 'Corrupt Memory', 'Execute Untrusted Code', 'Run Arbitrary Code', 'heap out-of-bounds write', 'OS Command injection', 'Elevation of Privilege', 'Race condition', 'Access violation', 'Infinite loop']
Например, на входе имеем CVE-2021-40444, на выходе получаем:
CVE-2021-40444 - Remote Code Execution
Описание уязвимости
Тут уже мы воспользуемся волшебной библиотекой cpe для питона:
def get_cve_data(cve): r = nvdlib.getCVE(cve, cpe_dict=False) cve_name = '' cve_info = r.cve.description.description_data[0].value for item in pattern: if item.upper() in cve_info.upper(): cve_name = cve + " - " + item break else: cve_name = cve
В переменную cve_info как раз записывается описание уязвимости. А вот цикл for item in pattern: тут нужен для того, чтобы добавить паттерн к названию уязвимости из примера выше.
Дата публикации и дата выявления уязвимости
В данном случае получаем переменные также с помощью библиотеки cpe в теле функции get_cve_data :
publishedDate = r.publishedDate[:-7] lastModifiedDate = r.lastModifiedDate[:-7]
CPE
Код в теле функции get_cve_data:
cve_cpe_nodes = r.configurations.nodes cpe_nodes = ast.literal_eval(str(r.configurations))
CVSSv3 Score и CVSSv3 Vector
Код в теле функции get_cve_data:
score = r.v3score vector = r.v3vector
Продукты и версии пакетов для которых актуальна уязвимость
Код в теле функции get_cve_data :
product_vendor_list = [] product_image_list = [] version_list = [] for cpe in cpe_for_product_vendors: cpe_parsed = CPE(cpe) product = cpe_parsed.get_product() vendor = cpe_parsed.get_vendor() product_vendor = vendor[0] + " " + product[0] if product != vendor else product[0] product_vendor_list.append(product_vendor) product_image_list.append(product[0]) version = cpe_parsed.get_version() if version[0] != '-' and version[0] != '*': version_list.append(f'{product[0]} - {version[0]}')
Необходимые ссылки
Тут под необходимыми ссылками понимаются следующие - ссылка на производителя, ссылка на решение, ссылка на эксплоит, ссылка на ресерч разбор уязвимости. На nvd.nist.gov это выглядит так:

У нас в коде это реализовано так:
links.append(r.url)
Наличие эксплоитов в открытых источниках
Для того, чтобы найти эксплоит или PoC (proof-of-concept) мы парсим теги на сайте nvd.nist.gov и пока два репозитория на гитхабе:

Пример кода для парсинга
# check https://github.com/nu11secur1ty/ ----------------------------------------------------------------------------- def get_exploit_info(cve): link = 'https://github.com/nu11secur1ty/CVE-mitre' link_2 = 'https://github.com/nu11secur1ty/CVE-mitre/tree/main/2022' default_link = '' poc_cve_list = [] r = requests.get(link) soup = BeautifulSoup(r.text, "html.parser") for cve_id in soup.find_all("span", class_="css-truncate css-truncate-target d-block width-fit"): regex = re.findall(r'CVE-\d{4}-\d{4,8}', cve_id.text) if regex: poc_cve_list.append(str(regex[0])) r = requests.get(link_2) soup = BeautifulSoup(r.text, "html.parser") for cve_id in soup.find_all("span", class_="css-truncate css-truncate-target d-block width-fit"): regex = re.findall(r'CVE-\d{4}-\d{4,8}', cve_id.text) if regex: poc_cve_list.append(str(regex[0])) for item in poc_cve_list: if cve == item: default_link = f'https://github.com/nu11secur1ty/CVE-mitre/tree/main/{cve}' return default_link # check https://github.com/trickest/cve/ ----------------------------------------------------------------------------- def get_exploit_info_2(cve): # print('get_exploit_info_2') # DEBUG year = cve.split('-')[1] link = f'https://github.com/trickest/cve/tree/main/{year}' r = requests.get(link) soup = BeautifulSoup(r.text, "html.parser") default_link = '' for cve_id in soup.find_all("span", class_="css-truncate css-truncate-target d-block width-fit"): if f'{cve}.md' == cve_id.text: default_link = f'**trickest/cve** - https://github.com/trickest/cve/tree/main/{year}/{cve}.md' break return default_link exploit_links = [] for t in r.cve.references.reference_data: links.append(t.url) if 'Exploit' in t.tags: exploit_links.append(t.url) if get_exploit_info(cve): # check https://github.com/nu11secur1ty/ exploit_links.append(get_exploit_info(cve)) if get_exploit_info_2(cve): # check https://github.com/trickest/cve/ exploit_links.append(get_exploit_info_2(cve))
Наличие смягчающих мер

Mitigations (меры по смягчению последствий) - это типовые наборы правил, позволяющих снизить риски от эксплуатации уязвимости. В данной ситуации мы парсим пульсы на сайте otx.alienvault.com. Пульсы - это ресерчи пользователей, в которых они описывают конкретные тактики и техники для эксплуатации уязвимости, а также IoC-ки, но это уже совсем другая история. Стоит заметить что данный способ парсинга не совсем точный, но если вы хотя бы немного ориентируетесь в матрице Mitre Att&ck, то эта информация будет для вас полезна.
Итак, скрипт:
Пример кода для скрапинга
# parse mitre.org----------------------------------------------------------------------------------------------------- def get_mitigations(tactic_id): # print("get_mitigations") # DEBUG tactic_url = f'https://attack.mitre.org/techniques/{tactic_id}' r_get_tactic_info = requests.get(tactic_url) s_get_tactic_info = BeautifulSoup(r_get_tactic_info.text, 'html.parser') # 0 - Procedure Examples # 1 - Mitigations # 2 - Detection try: mitigations = s_get_tactic_info.find_all("table", class_="table table-bordered table-alternate mt-2")[1].text buff_string_1 = str(mitigations).replace("ID", "").replace("Mitigation", "").replace("Description", "").replace( "\n\n", "") buff_list = buff_string_1.split('\n') buff_list.pop(0) # Remove empty element, index - 0 return_list = [] for count in range(int(len(buff_list) / 3)): id_mit = buff_list[count * 3].rstrip().lstrip() name_mit = buff_list[count * 3 + 1].rstrip().lstrip() desc_mit = buff_list[count * 3 + 2].rstrip().lstrip() return_list.append(f'[{id_mit} - {name_mit}](https://attack.mitre.org/mitigations/{id_mit}) - {desc_mit}') return return_list except: pass # parse alienvault.com------------------------------------------------------------------------------------------------ def get_ttp(cve): # print('get_ttp') # DEBUG headers_alienvault = {'X-OTX-API-KEY': API_KEY_ALIENVAULT} url = f'https://otx.alienvault.com/api/v1/indicators/cve/{cve}' pattern_default_answer = '{"detail": "endpoint not found"}' r_get_cve_info = requests.get(url, headers=headers_alienvault) s_get_cve_info = BeautifulSoup(r_get_cve_info.text, 'lxml') tactic_list = [] if str(s_get_cve_info.p.contents).replace("['", "").replace("']", "") == pattern_default_answer: print(f'no information for {cve}') # DEBUG else: content = json.loads(str(s_get_cve_info.p).replace("<p>", "").replace("</p>", "")) count = int(content['pulse_info']['count']) subs_list = [] for i in range(count): subs_list.append(content['pulse_info']['pulses'][i]['subscriber_count']) tactic_list = [] for i, item in enumerate(subs_list): max_test = max(subs_list) if content['pulse_info']['pulses'][i]['attack_ids']: for j in range(len(content['pulse_info']['pulses'][i]['attack_ids'])): tactic_list.append(content['pulse_info']['pulses'][i]['attack_ids'][j]['id']) break else: subs_list.remove(max_test) else: return f'NO TTP' tactic_list = list(set(tactic_list)) # replace replications technique_list = [] for i, item in enumerate(tactic_list): if len(str(item)) > 6: technique_list.append(str(item).replace(".", "/")) result_list = [] if technique_list: for tactic_id in technique_list: if get_mitigations(tactic_id): for item in get_mitigations(tactic_id): result_list.append(item) return list(set(result_list)) else: for tactic_id in tactic_list: if get_mitigations(tactic_id): for item in get_mitigations(tactic_id): result_list.append(item) return list(set(result_list))
На вход он принимает API-KEY от вашей учетной записи на сайте (да да, опять регистрация, но никакой платной подписки) и идентификатор уязвимости.
На выходе получаем список митигейшенов для конкретной уязвимости (в разметке markdown):
['[M1047 - Audit ](https://attack.mitre.org/mitigations/M1047)', '[M1017 - User Training ](https://attack.mitre.org/mitigations/M1017)', '[M1028 - Operating System Configuration ](https://attack.mitre.org/mitigations/M1028)', '[M1038 - Execution Prevention ](https://attack.mitre.org/mitigations/M1038)', '[M1040 - Behavior Prevention on Endpoint ](https://attack.mitre.org/mitigations/M1040)', '[M1018 - User Account Management ](https://attack.mitre.org/mitigations/M1018)', '[M1026 - Privileged Account Management ](https://attack.mitre.org/mitigations/M1026)', '[M1042 - Disable or Remove Feature or Program ](https://attack.mitre.org/mitigations/M1042)']
Иные нужные сущности
EPSS scoring (оценка вероятности использования уязвимости в реальных компьютерных атаках) очень полезная и интересная штука, советую почитать на досуге.
Код
def get_data_file(): data_link = "https://epss.cyentia.com/epss_scores-current.csv.gz" response = requests.get(data_link) with open(buffer, 'wb') as f: f.write(response.content) with gzip.open(buffer, 'rb') as f_in: with open(filename, 'wb') as f_out: shutil.copyfileobj(f_in, f_out) def info_data(filename): with open(filename) as csv_file: csv_reader = csv.reader(csv_file, delimiter=',') my_file = open(fileout, "w") for row in csv_reader: try: epss = str(round(float(str(100 / (1 / float(row[1])))[0:5]), 2)) data = str(row[0] + ',' + epss + '\n') my_file.write(data) except: pass my_file.close() filename = f'{PATH}/DATA.csv' fileout = f'{PATH}/DATA1.csv' buffer = f'{PATH}/tar.csv.gz' get_data_file() info_data(filename) cve_line = [] procent_line = [] with open(fileout) as csv_file: csv_reader = csv.reader(csv_file, delimiter=',') for row in csv_reader: cve_line.append(row[0]) procent_line.append(row[1])
На вход скрипт принимает путь до директории, в которую он будет скачивать (и потом удалять) csv файл со значениями, для того, чтобы вытянуть из них нужную информацию.
На выходе получается два массива, с идентификаторами и значениями epss.
Также мы парсим несколько сайтов майкрософт для того чтобы связывать уязвимости друг с другом и (или) получать список обновлений безопасности (KB).

Код
def get_kb(cve): msrc_url = f"https://api.msrc.microsoft.com/cvrf/v2.0/Updates('{cve}')" get_cvrf_link = requests.get(msrc_url, verify=False) id_for_cvrf = re.search(r'\d{4}-\w{3}', get_cvrf_link.text) cvrf_url = f'https://api.msrc.microsoft.com/cvrf/v2.0/document/{id_for_cvrf[0]}' get_info = requests.get(cvrf_url, verify=False) soup = BeautifulSoup(get_info.text, "lxml") parse_list = [] buff = '' for item in soup.text: if item == '\n': parse_list.append(buff) buff = '' else: buff += item parse_string = '' for j, item in enumerate(parse_list): regex = re.findall(cve, parse_list[j]) if regex: parse_string = parse_list[j] kb_list = re.findall(r'KB\d{7}', parse_string) not_remove_list_of_kb = [] for kb in kb_list: if kb not in not_remove_list_of_kb: not_remove_list_of_kb.append(kb) link_list = [] for kb in not_remove_list_of_kb: kb_url = f'https://catalog.update.microsoft.com/v7/site/Search.aspx?q={kb}' test = requests.get(kb_url, verify=False) if test.status_code == 200: url_get_product = f'https://www.catalog.update.microsoft.com/Search.aspx?q={kb}' get_product = requests.get(url_get_product, verify=False) soup_get_product = BeautifulSoup(get_product.text, "lxml") product_buff = '' for item in soup_get_product.find_all('a', class_='contentTextItemSpacerNoBreakLink'): product_buff = item.text product = product_buff.strip() # Output: Windows 10 Version 1809 for x86-based Systems #link_list.append(f'[{kb}]({kb_url}) - {(product.partition("for")[2])[:-12]}') if product: # Output: 2022-01 Cumulative Update for Windows 10 Version 1809 for x86-based Systems (KB5009557) link_list.append(f'[{kb}]({kb_url}) - {product[:-12]}') return link_list
На вход скрипт получается идентификатор уязвимости, на выходе список обновлений безопасности:
2022-04 Cumulative Update for Windows Server 2019 for x64-based Systems - https://catalog.update.microsoft.com/v7/site/Search.aspx?q=KB5012647 2022-04 Cumulative Update for Windows 10 Version 1909 for x64-based Systems - https://catalog.update.microsoft.com/v7/site/Search.aspx?q=KB5012591 2022-04 Dynamic Cumulative Update for Windows 10 Version 21H2 for x86-based Systems - https://catalog.update.microsoft.com/v7/site/Search.aspx?q=KB5012599 ...
Теперь ответим на вопрос, где всё это хранить
Тут решений конечно же очень много от банальных csv файлов для каждой уязвимости, до высокоуровневых СУБД.

Мы же решили заводить каждую уязвимость в трекер задач YouTrack отдельной задачей (за тавтологию извиняюсь).
Пример:
Скрин
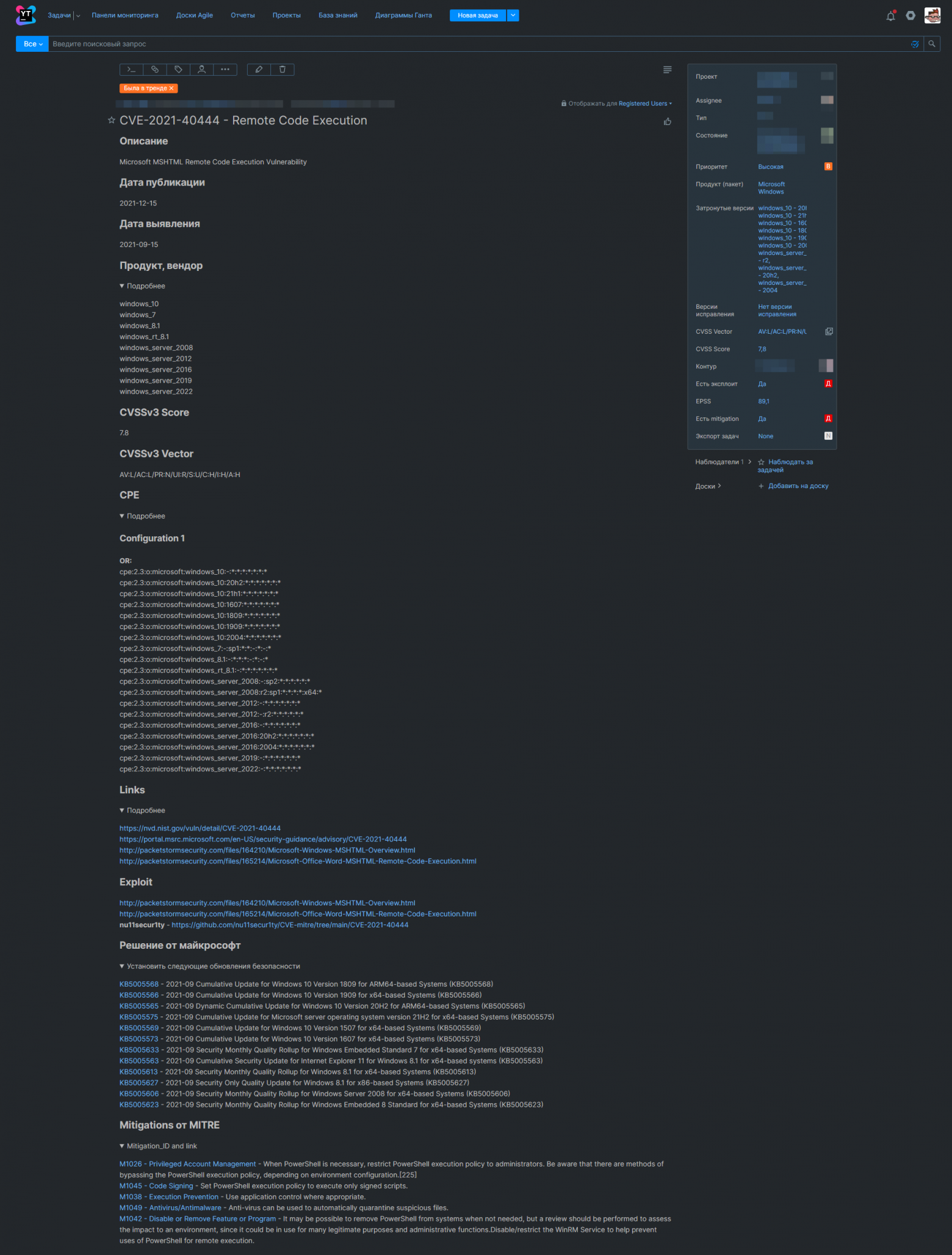
Ну вот примерно так, мы выстроили процесс vulnerability managment`a управления уязвимостями.
P.S. Автор не претендует на звание мастера программиста, а просто делится полезной информацией, которая в RU сегменте интернета слабо описана.
