Когда-то мне довелось делать программу для управления процессом измерения в мониторе артериального давления (АД). Хочу на этом примере разобрать и продемонстрировать что нужно для решения задач реального времени. Наверно на этом примере можно понять, в том числе, когда нужно использовать RTOS.
Я постараюсь, конечно, рассмотреть эту задачу как гипотетическую, с минимальным погружением в детали того откуда берутся те или иные требования, но очень многое завязано именно на эти детали.
Постановка задачи
Итак, у нас есть процессор, который управляет некоторой измерительной системой чтобы провести корректные измерения некоторых параметров наблюдаемой системы.
Измерительная система состоит из датчика, подключенного через АЦП к процессору и энергонезависимой (флэш) памяти для сохранения-регистрации первичных данных с датчика. Собственно суть задачи и основная проблема, которую нужно решить это то, что и АЦП и флэш память общаются с процессором по одной последовательной шине (SPI шине). Назначение устройства мониторинг артериального давления (АД), это медицинское устройство, которое, понятно, делается по медицинским стандартам на такого типа оборудование.
Когда я приступил к анализу того, как была построена работа монитора АД, мне досталось работающее устройство для анализа, у которого наблюдалась проблема со стабильностью работы. То есть в большинстве случаев устройство стабильно работало и выдавало ожидаемый результат, но был некоторый маленький процент зарегистрированных операций, при которых зарегистрированные данные показывали сбой нормального функционирования устройства. Для медицинского устройства наличие даже такого маленького процента некорректно выполненных операций ставило под сомнение будущее этого устройства. Проблема была в том что сбой корректно не регистрировался, в случае сбоя данные были просто не адекватные, то есть показывали то чего не может быть, и по ним ничего нельзя было понять.
В принципе проблема, которая приводила к сбоям, была в общем известна, это нарушение периода измерений – считывания значений с датчика, дело в том, что на основе этих значений строился некоторый алгоритм расчета АД, который понятным образом не работал, когда нарушался период поступления отсчетов с датчика давления.
Соответственно задача минимум была подтвердить предположение на основе объективных данных, то есть каким-то образом научить систему корректно регистрировать сбои, задача максимум совершенно исключить возможность сбоев, сделать встроенное ПО абсолютно надежным.
Аппаратные ограничения или когда начинаются поиски RTOS
Наверно не нужно объяснять, что любая система, которая занимается анализом сигналов (в данном случае сигналов с датчика давления, там анализируются импульсы давления крови) критична к периоду поступления отсчетов сигнала ��ля анализа, не существует математики, которая работала бы при не стабильном периоде измерений («не стабильный» здесь будет эквивалентом «не известный»).
Рассмотрим структурную схему, по которой построена аппаратная система (та ее часть, которая нас интересует):
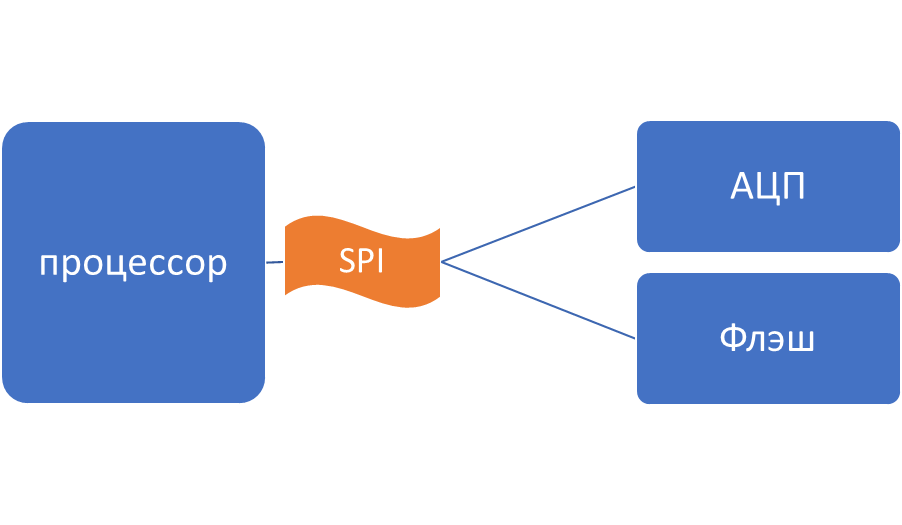
Все очень просто, надо с заданной частотой считывать данные с АЦП, проводить текущие вычисления по полученным с АЦП отсчетам (сэмплам) и каким-то образом в промежутках успевать записывать данные во Флэш по той же SPI шине, на которой висит АЦП!
Сохранение первичных данных, по которым вычисляются медицинские показатели пациента это не прихоть разработчика, это требование медицинского стандарта, которому должно соответствовать устройство.
На словах все понятно, но нужно сформулировать задачу математически точно, и это очень часто является непреодолимой проблемой. Собственно, на этом этапе обычно и начинаются поиски RTOS (Операционной Системы Реального Времени), которая волшебным образом должна решить задачу распределения операций во времени, задачу, которую никто даже не сформулировал!
Временные диаграммы, задача планировщика операций
Так вот чтобы сформулировать задачу математически точно, надо рассмотреть время выполнения каждой операции и расположить эти времена на оси времени так чтобы они не пересекались-не накладывались, исключение таких накладок как раз и сделает нашу систему абсолютно предсказуемой – надежной!
Вот такая картинка у меня сформировалась в ��олове.

Это тоже схема – схема или диаграмма событий-операций во времени, это решение задачи планировщика для этой конкретной предметной области. В принципе и наверно, ее можно обобщить на любую задачу, связанную с обработкой сигналов.
Тут надо пояснить как определяются времена операций, итак:
Тацп – это время чтобы выполнить АЦП и получить результат, это две операции на SPI шине: послать команду на запуск и потом послать команду на чтение, которая и является операцией чтения. Я уже не помню деталей реализации, но для нашего анализа нам достаточно знать, что эта активность занимает достаточно мало времени от периода обращений к АЦП (насколько я помню там было что-то меньше даже 10% от периода), а САМОЕ ГЛАВНОЕ, это время практически не изменяется, то есть Тацп это константа.
ВАЖНО обратить внимание все времена мы должны соотносить со временем периода АЦП! Так как период АЦП должен выдерживаться с максимально возможной точностью, которая обеспечивается тактовой частотой процессора, потому что алгоритмы анализа (обработки) сигнала очень чувствительны к погрешности установки этого периода.
Таким образом мы определяем:
«Период от одного АЦП до другого» (до следующего преобразования, далее Тсистемы или Tsyst) как константу, которая определяется в теории обработки сигналов (здесь такая чтобы «увидеть» биение сердца на графике давления. Это что-то в районе 100 Герц- 10 миллисекунд период).
Далее следует:
Т вычислений – это время, которое процессор тратит на обработку сигнала. Когда накачивается манжета для измерения давления, процессор должен рассчитать оценочное значение давления, при котором надо перейти в режим стравливания и более точного измерения давления. Тут можно заметить, что задачи обработки сигналов достаточно ресурсоемки, а в моем случае этот алгоритм рассматривался как черный ящик с неизвестным временем выполнения. Собственно, именно эта неопределенность времени:
Неопределенность Т вычислений и составляла основную проблему, которую как минимум нужно надежно детектировать, чтобы иметь возможность предъявить претензии разработчикам алгоритма обработки сигналов, в который я не имел права вмешиваться.

На этом рисунке показано как выглядит проблема на временной диаграмме, но сначала я поясню про:
«Т на сохранение» - это время которое необходимо на сохранение отсчетов АЦП во флэш на SPI шине, тоже абсолютно детерминированное, обозначим как Tsave, для дальнейшего использования. Отсчеты сохраняются блоками, скажем 128 отсчетов за одну операцию -транзакцию записи во флэш. Это значит, что сохранение происходит один раз на 128 АЦП преобразований, то есть на диаграмме приведен период с максимальным количеством операций за период. Другим последствием этого факта является то, что сохранение можно отложить. Например у нас накопилось 128 отсчетов и мы готовы произвести транзакцию сохранения во флэш, но выясняется что на данный период случилась особенно длительная операция вычисления-обработка сигнала (очередного отсчета), и так как данные все равно пишутся во второй 128-байтный буфер (простейшая двойная буферизация была реализована), мы можем подождать до 128 периодов когда обработка сигнала окажется достаточно короткой чтобы успеть провести и закончить транзакцию записи во флэш до того как придет время в очередной раз запустить АЦП.
Оказывается, проблема заключается в том, что в исходной прошивке процессора не контролировалось время обращений к разным устройствам на SPI шине! Соответственно иногда происходила ситуация, изображенная на второй диаграмме, задержка операции вычисления приводила к тому, что транзакция сохранения во флэш перекрывает момент запуска АЦП. Что происходит в этом случае в программе нет смысла анализировать, это в любом случае не чего хорошего не дает, стратегия должна быть в том, чтобы не допустить такой ситуации, в крайнем случае аварийным прекращением измерения. Но на самом деле описанное мной отложенное выполнение транзакции совершенно решает эту проблему (в той железке, на которой мне пришлось работать), и сохранение во флэш всегда начинается так чтобы успеть закончить его до момента запуска очередного АЦП.
Техника измерения времени, которое остается до момента запуска очередного АЦП после завершения вычислений мне, кажется совершенно очевидной.
Решение одной из проблем наложения операций во времени
Любой процессор аппаратно поддерживает функцию для получения текущего значения своих тиков. Не бывает процессоров без встроенного счетчика с возможностью счета с точностью до разрешения тактовой частоты процессора (даже 20 лет назад тактовые частоты начинались от мегагерц). Период Тсистемы (Tsyst период между двумя последовательными АЦП) конечно будет известен в единицах тиков процессора мы сами его определяем. Тогда, если мы каждый запуск АЦП предваряем чтением текущего значения тиков процессора (обозначим Tstart) то, если мы прочитаем текущее значения тиков процессора сразу после окончания вычислений по обработке сигнала, обозначим этот момент окончания как Tend, то посчитав:
Tsyst – (Tend – Tstart) = T-до-конца-системного-периода, то есть до момента запуска очередного АЦП, обозначим как Т остатка периода после вычислений = Тост.
Тогда, чтобы решить можно ли запускать транзакцию записи во флэш нам надо просто проверить условие:
unsigned int Tend = getTicks();
unsigned int Tcalc = Tend - Tstart;
if (Tsyst - Tcalc > Tsave)
{//
if (BufferReadyFlag)
{
BufferReadyFlag = false;
ЗапуститьТранзакциюСохраненияВоФлеш();
}
}
else
{
if (BufferReadyFlag)
{
//здесь логика ожидания отложенной записи
//и генерация ошибки в случае недопустимого поведения
}
}Тут надо обратить внимание на булеву переменную BufferReadyFlag, она нужна чтобы запомнить, что буфер готов и начать проверять возможность его сохранения, в течение последующих 128 системных периодов. Соответственно, там должна быть логика, которая анализирует количество попыток запустить сохранение, и если за (128-1) период не удастся произвести сохранение это будет означать что вычисления длятся неадекватно долго в течении системного периода и в течении недопустимого количества периодов. И тут ничего не остается как прекращать измерение, сдувать манжету, регистрировать и индицировать сбой – ошибку недопустимой длительности вычислений недопустимое количество раз. Самое интересное что эта ошибка не должна никогда произойти, при условии, что алгоритм вычисления написан адекватно и не затягивается не оправданно долго, но ошибки никогда нельзя исключать и любая система, особенно система, работающая в реальном времени должна как минимум быть способна к самодиагностике, она должна как минимум сообщить о нештатной работе (неадекватных результатах работы) своих внутренних алгоритмов, когда такое случается! В том моем случае у меня был дополнительный стимул реализовать самодиагностику так как алгоритм вычислений я не контролировал, поэтому если моя программа не говорила бы что стало причиной сбоя, причиной сбоя всегда бы признавалась моя часть программы, и я соответственно всегда был бы виноват.
Таким образом мы видим, что в данном случае описанная здесь логика контроля времени выполнения (я думаю, что как минимум большинство согласится что речь идет именно о реальном времени в этом случае) не только позволяет избежать непредсказуемого и поэтому недопустимого поведения алгоритма управления, но также обеспечивает функции самодиагностики в системе!
Мы рассмотрели то, каким образом разместить операцию сохранения данных во флэш в пределах системного периода, чтобы не поломать этот самый системный период.
Вторая проблема наложения операций во времени
Есть еще одна проблема, связанная с непредсказуемостью времени вычислений, это время может оказаться достаточно большим чтобы перекрыть момент запуска очередного АЦП, причем это вполне может быть случаем штатной работы.
Тут наверно нужно пояснить что требуемая концепция встроенного ПО как я ее тогда реализовал, предполагала что сторонний код алгоритма обработки сигнала может быть разного происхождения и от разных авторов, и окружение этого произвольного алгоритма должно обеспечивать управление измерительной системой и снабжение данными этого произвольного алгоритма независимо от характеристик производительности этого алгоритма, но конечно в некоторых разумных пределах. Собственно то, что я излагаю в большой степени и является описанием метода-методов определения этих разумных пределов в виде математических критериев, на базе анализа временных диаграмм по определенным в системе операциям управления-контроля измерительной системы.
Итак, вот диаграмма, на которой вопросом отмечен участок с недопустимым наложением операций.

И давайте сразу приведем диаграмму с решением.

Решением является разделение операций на те которые выполняются в прерываниях и те, которые выполняются в фоновой программе. Из приведенной диаграммы мы видим, что операция выполнения АЦП должна прерывать операцию вычисления (обработки очередного отсчета с АЦП)! Я не помню подробностей реализации на той конкретной аппаратной системе, но вполне очевидно, что мы можем разместить операцию выполнения АЦП в таймерном прерывании и назначить этому прерыванию (таймеру) период размером Тсист.
Соответственно операция вычислений должна выполняться в фоновой программе, в основном цикле. Далее следует псевдокод (С-подобный), в котором приведена логика, которую надо реализовать в фоновой программе чтобы решить указанную проблему.
Тут есть не точность в имени переменной которая может ввести в заблуждение: Tcalc это относительное время окончания измерения (это Тацп+Т измерения), а не время только измерения. Константы взяты с потолка, но в правильном соотношении что Tsyst больше чем Tsave.
volatile bool BufferReadyFlag;
volatile unsigned int Tstart;
const unsigned int Tsyst = 0x777;//ticks in Tsyst period
const unsigned int Tsave = 0x333;//ticks in Tsave period
void mainLoop()
{
...
while (1)
{
//это аналог семафора в какой нибудь Опер.Системе который здесь
//открывается из прерывания Таймера после
//получения результата АЦП!
WaitNextAdcResult();
//выполнить Операцию Вычисления и произвести необходимые Манипуляции
// По Управлению измерительной Системой();
ExecuteCalculations();
unsigned int Tend = getTicks();
unsigned int Tcalc = Tend - Tstart;
if (Tsyst - Tcalc > Tsave)
{//
if (BufferReadyFlag)
{
BufferReadyFlag = false;
ЗапуститьТранзакциюСохраненияВоФлеш();
}
}
else if (Tcalc > (Tsyst + Tsyst / 2))
{// Если Tcalc > (1.5*Nsyst)
Error("недопустимо большое время обработки отсчета АЦП!");
MesureEnd();
}
else
{//ничего не надо делать, мы по циклу вернемся на выполнение операции вычисления
// любом случае! Если Tcalc < Nsyst будем ждать в WaitNextAdcResult()
//следующего АЦП, Если (1.5*Nsyst) > Tcalc >= Nsyst WaitNextAdcResult() должна
//будет нас сразу пропустить к обработке результата АЦП
}
if (BufferReadyFlag)
{
//здесь логика ожидания отложенной записи
//и генерация ошибки в случае недопустимого поведения
}
...
}
Техника использования знаковых-беззнаковых целочисленных переменных здесь не совсем корректна, но я не буду ее разъяснять. Те, кто занимаются задачами реального времени, должны ее хорошо знать, то есть у них не должно быть проблем с переводом этого псевдокода в нормальный работающий код.
Чтобы описать как все эти частные наблюдения, идеи объединяются в законченную полноценную программу пришлось бы написать книгу, а не статью. И конечно неплохо бы иметь эту самую программу, а лучше не одну в виде работающего кода на работающем железе. Проблема в том, что эта программа и аппаратное решение были созданы более 15 лет назад. Поэтому я постарался изложить то, что осталось в моей голове от того решения, и то, что как мне кажется, не потеряет актуальности пока существуют процессоры с таймерами-счетчиками, и с прерываниями.
Заключение
По поводу вопроса, который подразумевается в заголовке “а нужна ли RTOS для решения такого типа задач?” я думаю так:
Решение задачи реального времени всегда требует полного анализа аппаратной системы, на которой эта задача решается, она требует явного планирования разработчиком последовательности операций, которую он должен реализовать или хочет реализовать если у него есть выбор между разными возможными последовательностями. Но тогда задача еще сложнее, вообще говоря, так как надо идентифицировать не одну, а набор этих разных последовательностей операций.
Потом RTOS реализуются на системах на которых есть избыток ресурсов, на той аппаратной платформе на которой я решал изложенную задачу, был скорее недостаток ресурсов и не было особо места для размещения какой бы то ни было ОС. Ну и самый главный аргумент, любая ОС добавляет вам уровень операций-уровень софта, который надо отдельно изучать и проверять на этом конкретном железе, а мы выяснили что нам в любом случае надо провести полный анализ аппаратной системы, и аппаратная система для задач реального времени обычно получается не стандартная, поэтому нам придется еще и разбираться с особенностями функционирования какой бы то ни было ОС на этой не стандартной аппаратной платформе.
В общем при решении той конкретной задачи мне было гораздо проще обойтись без какой бы то ни было RTOS, хотя предложения воткнуть туда такой промежуточный слой софта были в наличии.

