В сегодняшней статье мы начнем знакомиться с универсальной и высокопроизводительной кластерной вычислительной платформой Apache Spark, научимся разворачивать данное решение и выполнять простейшие программы. При обработке больших объемов данных скорость играет важную роль, так как именно скорость позволяет работать в интерактивном режиме, не тратя минуты или часы на ожидание. Spark в этом плане имеет серьезное преимущество, обеспечивая высокую скорость, благодаря способности выполнять вычисления в памяти.
Основной целью создания этого фреймворка был охватит как можно более широкого диапазона рабочих нагрузок, которые ранее требовали создания отдельных распределенных систем. Например, такие системы требовали использования приложений пакетной обработки, циклических алгоритмов для работы с данными, интерактивных запросов и потоковой обработки.
Spark изначально поддерживает все эти виды задач с помощью единого механизма, тем самым упрощая и удешевляя объединение разных видов обработки, которые часто необходимо выполнять в едином конвейере обработки данных.
Фреймворк Spark предлагает простой API на языках Python,Java, Scala и SQL и богатую коллекцию встроенных библиотек. Он также легко объединяется с другими инструментами обработки больших данных.
Архитектура Spark
Фреймворк Spark состоит из нескольких компонентов, тесно взаимодействующих между собой. Основным компонентом, отвечающим за выполнение всех вычислительных задач является ядро (Core).
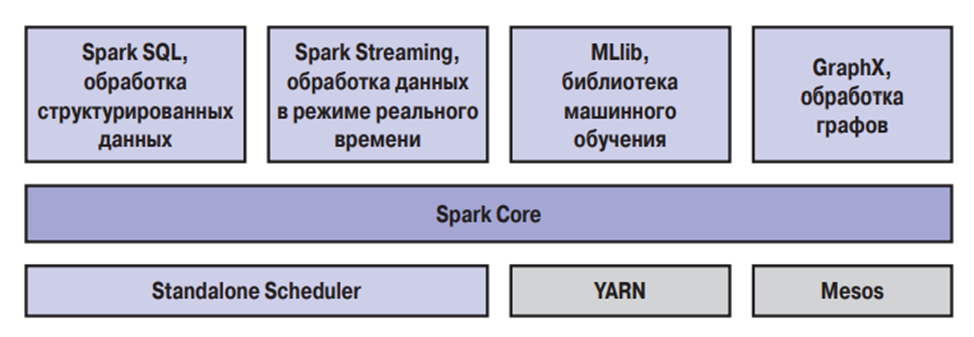
Ядро отвечает за планирование, распределение и мониторинг приложений, выполняющих множество различных задач на вычислительном кластере. Примерами таких задач является выполнение SQL запросов или машинное обучение.
Spark SQL
Компонент Spark SQL предназначен для работы со структурированными данными. Этот компонент работает с данными, используя диалект SQL Hive Query Language (HQL). При этом, Spark SQL умеет работать с множеством различных источников данных, таких как таблицы Hive, Parquet и JSON. Также Spark SQL позволяет смешивать в одном приложении запросы SQL с программными конструкциями на Python, Java и Scala, поддерживаемыми абстракцией RDD, и таким способом комбинировать SQL со сложной аналитикой.
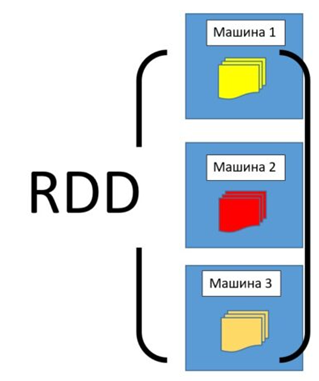
Об упомянутой абстракции RDD стоит сказать особо. RDD (Resilient Distributed Dataset) — это простая, неизменяемая, распределенная коллекция объектов во фреймворке Apache Spark. RDD представляет собой распределенный набор данных, который делится на множество частей, обрабатывающихся различными узлами в кластере.
Spark Streaming
Компонент для обработки потоковых данных в Spark называется Streaming. Spark Streaming имеет API для управления потоками данных, соответствующий модели RDD, поддерживаемой компонентом Spark Core, что облегчает изучение самого проекта и разных приложений обработки данных, хранящихся в памяти, на диске или поступающих в режиме реального времени. Примерами источников таких данных могут служить файлы журналов, заполняемые действующими веб-серверами, или очереди сообщений, посылаемых пользователями веб-служб.
Компонент MLlib
Направление машинного обучения в настоящее время очень популярно. Разработчики Spark не обошли стороной эту тему, добавив в состав Spark библиотеку MLlib, реализующую механизм машинного обучения (Machine Learning, ML). Данная библиотека поддерживает множество алгоритмов машинного обучения, включая такие важные алгоритмы, как алгоритмы классификации, регрессии, кластеризации и совместной фильтрации, а также функции тестирования моделей и импортирования данных. Все эти методы способны работать в масштабе кластера.
Компонент GraphX
Обработка графов является еще одной важной задачей, используемой при анализе данных. В Apache Spark для решения этих задач используется библиотека GraphX. Подобно компонентам Spark Streaming и Spark SQL, GraphX дополняет Spark RDD API возможностью создания ориентированных графов с произвольными свойствами, присваиваемыми каждой вершине или ребру. Также GraphX поддерживает разнообразные операции управления графами (такие как subgraph и rnapVertices) и библиотеку обобщенных алгоритмов работы с графами.
Например, анализ чего-то подобного:
Диспетчеры кластеров
Мы рассмотрели основные компоненты Apache Spark, однако помимо них важную роль играют диспетчеры – средства для обеспечения эффективного масштабирования от одного до многих тысяч вычислительных узлов. Примерами таких диспетчеров являются Hadoop YARN, Apache Mesos, а также простой диспетчер кластера, входящий в состав Spark, который называется Standalone Scheduler. При установке Spark на чистое множество машин на начальном этапе с успехом можно использовать Standalone Scheduler. При установке Spark на уже имеющийся кластер Hadoop YARN или Mesos можно пользоваться встроенными диспетчерами этих кластеров.
После рассмотрения архитектуры Apache Spark перейдем к практике, а именно посмотрим как развернуть Spark и выполнить простейшие операции.
Приступим к установке
Для того, чтобы загрузить Apache Spark необходимо перейти на страницу https://spark.apache.org/downloads.html и выбрать нужный вариант.
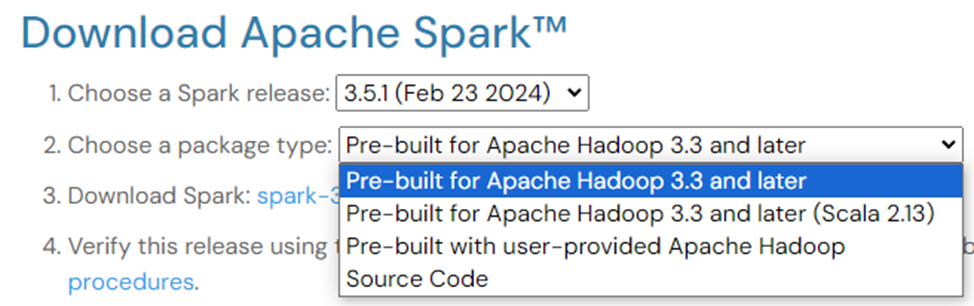
Упоминание Hadoop не должно смущать. Для установки Spark необязательно иметь Hadoop, но если у вас уже имеется настроенный кластер Hadoop или установлена поддержка HDFS, выбирайте для загрузки соответствующую версию.
Также установить Spark можно с помощью Pip, выполнив команду
pip install pyspark
А для тех, кому лень возиться с установкой есть готовый контейнер:
docker pull apache/spark-py:latest
Загрузив файл архива с фреймворком Spark, давайте распакуем его и посмотрим, что входит в состав дистрибутива по умолчанию. Для этого откройте окно терминала, перейдите в каталог, куда была выполнена загрузка Spark, и распакуйте файл. В результате будет создан новый каталог с тем же именем, но без расширения .tgz. Перейдите в этот каталог и посмотрите, что в нем содержится
cd - tar -xf spark-3.5.1-bin-hadoop3.3.tgz cd spark-3.5.1-bin-hadoop3.3 ls
Рассмотрим назначение некоторых наиболее важных файлов и каталогов:
README.md - содержит краткие инструкции по настройке Spark;
bin - содержит выполняемые файлы, которые можно использовать для взаимодействий с фреймворком Spark, например, командная оболочка Spark;
core, streaming, python, ... - содержат исходный код основных компонентов проекта Spark;
examples - содержит примеры реализации некоторых распространенных задач, которые можно опробовать и использовать для изучения Spark API.
Далее запускаем командную оболочку с помощью команды /bin/pyspark.
Примеры работы
Основной абстракцией Spark является распределенная коллекция элементов, называемая набором данных. Наборы данных могут быть созданы из входных форматов Hadoop (таких как файлы HDFS) или путем преобразования других наборов данных. Из-за динамической природы Python нам не нужно, чтобы набор данных был строго типизирован на Python. В качестве примера давайте создадим новый фрейм данных из текста файла README в исходном каталоге Spark:
>>> lines = sc.read.text("README.md")
После создания RDD появляется возможность выполнять два вида операций: преобразования и действия. Преобразования создают новые наборы RDD на основе существующих.
Примером типичного преобразования может служить фильтрация данных по заданному условию. Продолжая пример с текстовым файлом, можно создать новый набор RDD, хранящий только строки со словом Python.
pythonLines = lines.filter (lambda line: "Python" in line)
А вот действия, напротив, вычисляют результат, но при этом не создают новых наборов RDD, и возвращают его программе-драйверу или сохраняют во внешнем хранилище. Примером действия, которое мы уже выполняли выше, может служить вызов метода first(), который возвращает первый элемент RDD.
pythonLines.first()
Преобразования и действия отличаются способом обработки наборов RDD. Даже при том, что новый набор RDD можно создать в любой момент, Spark откладывает фактическое его создание до момента первого обращения к нему. На первый взгляд, такое решение может показаться необычным, но при работе с большими данными оно выглядит более чем разумно.
В завершении посмотрим пример различных действий на Python и Spark. Так, следующий код вернет нам количество записей в файле /etc/passwd и укажет первую запись:
>>> lines = sc.read.text("/etc/passwd") >>> lines.count() >>> lines.first()

Заключение
На этом ознакомление с основами Apache Spark можно завершить. Данный фреймворк является достаточно мощным инструментом разработки, обладающим различным полезным функционалом для распределенных вычислений.
Напоследок напомню про открытый урок в OTUS, посвященный мониторингу и управлению производительностью — на нем участники разберут стратегии и инструменты для эффективного наблюдения за приложениями Spark. Записывайтесь по ссылке, если тема для вас актуальна.
