")
Обработка потоковых данных стала крайне важна в настоящее время. И на это есть веские причины, такие как:
Компании жаждут получать данный как можно быстрее, и переход на потоковую обработку будет хорошим способом уменьшить задержки.
Объемные неограниченные наборы данных, все чаще встречающиеся в современных бизнес процессах, могут быть легче обузданы применением систем, специально спроектированных для таких объемов информации
Обработка данных по мере их поступления распределяет нагрузку более равномерно по времени, приводя с стабильному и предсказуемому потреблению вычислительных ресурсов.
Несмотря на существенный интерес к потоковой обработке данных со стороны бизнеса, львиная доля таких систем оставалась относительно незрелой по сравнению с аналогичными системами, ориентированными на пакетную обработку данных, так что это привело к недавнему всплеску вдохновляющих разработок в этой сфере.
Как тот, кто работал над крупно‑масштабной системой потоковой обработки в Google на протяжении последний пяти с лишним лет (MillWheel, Cloud Dataflow), я, мягко говоря, в восторге от сложившихся тенденций. Я все также заинтересован в том, чтобы люди понимали, что именно системы потоковой обработки в состоянии выполнять, и как их использовать наилучшим образом, в частности, закрыв нехватку знаний, оставшуюся между существующими системами пакетной обработки и потоковыми. С этой целью замечательные ребята из O»Reilly пригласили меня предоставить письменную версию моего доклада «Say Goodbye to Batch»(прим. пер. Оригинальная ссылка не работает) с конференции Strata + Hadoop World London 2015.(прим. пер. Оригинальная ссылка не работает) Поскольку мне предстоит осветить довольно много вопросов, я разделю его на две отдельных публикации:
Основы потоковой обработки данных (ориг. Streaming 101): Первая часть рассмотрит основные понятия и прояснит используемые термины до погружения в детали такой штуки как использование времени, а так же выполнит обзор общих подходов к обработке данных, как пакетной, так и потоковой.
Модель течения данных (ориг. The Dataflow Model): Вторая публикация будет в основном состоять из быстрого обзора унифицированной модели пакетной + потоковой обработки, используемой Google Cloud Dataflow, с приведением конкретного примера, применяемого в разнообразных вариантах использования. После этого я завершу кратким смысловым сравнением существующих пакетных и потоковых систем.
Итак, долгое вступление наконец закончилось, время занудствовать.
Основы
Для начала, я поделюсь важной справочной информации, которая поможет сформулировать остальные темы для обсуждения. Мы сделаем это в трех конкретных разделах:
Терминология: чтобы точно говорить о сложных темах, требуются точные определения терминов. Для некоторых терминов, которые имеют разные толкования при современном использовании, я постараюсь точно определить, что я имею в виду, когда их использую.
Возможности: я отмечу недостатки потоковых систем. Я также предложу образ мышления, который, по моему мнению, должны принять разработчики систем обработки данных, чтобы удовлетворить потребности современных потребителей данных в будущем.
Временные домены: я представлю два основных способа использования времени, которые важны для обработки данных, покажу, как они соотносятся, и укажу на некоторые трудности, которые создают эти два домена.
Термины: Что такое потоковая обработка (Streaming)?
Прежде чем идти дальше, я хотел бы убрать с дороги одну вещь: что такое потоковая обработка(стриминг)? Термин «streaming» используется сегодня для обозначения множества различных вещей (и для простоты я использовал его несколько свободно до сих пор), что может привести к недопониманию того, что такое стриминг на самом деле, или на что на самом деле способны потоковые системы. Таким образом, я бы предпочел определить этот термин более точно.
Суть проблемы заключается в том, что многие вещи, которые должны быть описаны тем, чем они являются (например, неограниченная обработка данных, приблизительные результаты и т. д.), стали описываться в просторечии тем, как они исторически были выполнены (т. е. через потоковые исполнительные механизмы). Это отсутствие точности в терминологии затмевает то, что на самом деле означает потоковая передача. А в некоторых случаях, накладывает ограничения на сами потоковые системы, подразумевая, что их возможности ограничены характеристиками, часто описываемыми как «потоковая обработка», такими как приблизительные или спекулятивные результаты. Учитывая, что хорошо спроектированные системы потоковой передачи так же (в большей степени технически) способны давать правильные, последовательные, повторяемые результаты, как и любой существующий пакетный движок, я предпочитаю выделить термин «потоковая обработка» в очень конкретном значении: тип механизма обработки данных, который разработан с учетом бесконечных наборов данных. Больше ничего. (Для полноты картины, возможно, стоит отметить, что это определение включает в себя как настоящую потоковую, так и микропакетную реализацию.)
Что касается других распространенных применений «потоковой обработки», вот несколько, которые я слышу регулярно, каждый из которых представлен с более точными описательными терминами, которые я предлагаю нам как сообществу попытаться принять:
Неограниченные данные: тип постоянно растущего, по существу бесконечного набора данных. Их часто называют «потоковыми данными (streaming data).» Однако термины «поток» или «пакет» проблематичны при применении к наборам данных, поскольку, как отмечалось выше, они подразумевают использование определенного типа механизма выполнения для обработки этих наборов данных. Ключевое различие между двумя типами рассматриваемых наборов данных в действительности заключается в их конечности, и поэтому предпочтительнее охарактеризовать их терминами, отражающими это различие. Таким образом, я буду ссылаться на бесконечные «потоковые» данные как на неограниченные данные, а на конечные наборы «пакетных» данных как на ограниченные данные.
Неограниченная обработка данных: постоянный режим обработки данных, применяемый к вышеупомянутому типу неограниченных данных. Как бы мне лично ни нравилось использование термина «потоковая обработка» для описания этого типа обработки данных, его использование в этом контексте снова подразумевает использование механизма потокового выполнения, что в лучшем случае вводит в заблуждение; повторяющиеся запуски пакетных механизмов использовались для обработки неограниченных данных с момента первой разработки пакетных систем (и наоборот хорошо спроектированные системы потоковой передачи более чем способны обрабатывать «пакеты» рабочих нагрузок из ограниченным данным). Таким образом, для ясности я просто назову это неограниченной обработкой данных.
Результаты с малой задержкой, приблизительные и/или спекулятивные результаты: Эти типы результатов чаще всего связаны с потоковыми движками. Тот факт, что пакетные системы традиционно не проектировались с учетом низких задержек или спекулятивных результатов, является историческим артефактом, и не более того. И, конечно же, системы пакетной обработки вполне способны давать приблизительные результаты, если им это указано. Таким образом, как и в случае с приведенными выше терминами, гораздо лучше описывать эти результаты такими, какие они есть (с малой задержкой, приблизительными и/или спекулятивными), чем тем, как они исторически проявлялись (через потоковые движки).
С этого момента, каждый раз, когда я использую термин «потоковая обработка», вы можете смело предположить, что я имею в виду механизм выполнения, предназначенный для неограниченных наборов данных, и не более того. Когда я имею в виду любой из других приведенных выше терминов, я прямо скажу: неограниченные данные, неограниченная обработка данных или минимально‑задерживаемые/приблизительные/спекулятивные результаты. Вот такие термины мы приняли в рамках Cloud Dataflow, и я призываю других занять аналогичную позицию.
О сильно преувеличенных ограничениях потоков
Далее давайте немного поговорим о том, что потоковые системы могут и не могут делать, с акцентом на возможности; одна из самых важных вещей, которые я хочу донести в этих публикациях, — это то, насколько способной может быть хорошо продуманная потоковая система. Системы потоковой обработки уже давно отодвинуты на несколько нишевый рынок, обеспечивающий низкие задержки, приблизительные/спекулятивные результаты, часто в сочетании с более функциональной пакетной системой, обеспечивающей в конечном итоге правильные результаты, т. е. Лямбда‑архитектурой.
Для тех из вас, кто еще не знаком с лямбда‑архитектурой, основная идея заключается в том, что вы запускаете потоковую систему вместе с пакетной системой, выполняя по существу одни и те же вычисления. Система потоковой обработки дает вам неточные результаты с малой задержкой (либо из‑за использования алгоритма аппроксимации, либо потому, что сама система потоковой передачи не обеспечивает корректность), а некоторое время спустя пакетная система продвигается вперед и обеспечивает вам правильный вывод. Изначально предложенный Натаном Марцем в Twitter (создателем Storm), такой подход в итоге получился вполне удачным, потому что это была, по сути, фантастическая для того времени идея; потоковые движки немного подводят с корректностью результатов, а пакетные движки были по своей сути громоздкими, как и следовало ожидать, так что Lambda дала вам возможность получить свой пресловутый торт и съесть его. К сожалению, поддержание системы Lambda — это хлопоты: вам нужно построить, предоставить и поддерживать две независимые версии вашего конвейера, а затем также каким‑то образом объединить результаты двух конвейеров в конце.
Как человек, который много лет работал над строго согласующимся(ориг. strong‑consistent) потоковым движком, я также нашел весь принцип лямбда‑архитектуры немного неприятным. Неудивительно, что я был большим поклонником критической публикации(прим. пер. Оригинальная ссылка не работает) за авторством Джея Крепса о лямбда‑архитектуре, когда она вышла. Это было одно из первых весьма заметных заявлений против необходимости двухрежимного исполнения; восхитительно. Крепс обратился к вопросу повторяемости в контексте использования воспроизводимой системы, такой как Kafka, в качестве потокового соединения, и зашел так далеко, что предложил архитектуру Kappa, которая, по сути, означает запуск одного конвейера с использованием хорошо продуманной системы, созданной соответствующим образом для указанной работы. Я не думаю, что само понятие требует названия, но идею в принципе полностью поддерживаю.
Честно говоря, я бы пошел еще дальше. Я бы сказал, что хорошо продуманные потоковые системы на самом деле обеспечивают строгий набор пакетных функций. В сухом остатке оглядываясь на эффективность1, не должно быть необходимости в пакетных системах, как они существуют сегодня. И слава людям из Flink за то, что они приняли эту идею близко к сердцу и создали систему, которая внутри себя делает потоки из всего и для всего, даже в пакетном режиме; Мне это нравится.
Следствием всего этого является то, что устойчивое развитие потоковых систем в сочетании с надежными платформами для неограниченной обработки данных со временем позволит отодвинуть Лямбда‑архитектуру на задворки истории больших данных, к которой она принадлежит. Я считаю, что пришло время воплотить это в жизнь. Потому что для этого, т. е. чтобы обыграть партию в своей игре, вам действительно нужно только две вещи:
Корректность — Это обеспечит вам паритет с пакетной обработкой. По сути своей, корректность сводится к согласованному хранению. Потоковым системам нужен метод проверки хранимого состояния системы с течением времени (о чем Крепс говорил в своей публикации «Почему локальное состояние является фундаментальным примитивом потоковой обработки»(прим. пер. Оригинальная ссылка не работает)), и он должен быть достаточно хорошо спроектирован, чтобы оставаться согласованным при сбоях вычислительного узла. Когда несколько лет назад Spark Streaming впервые появилась на публичной сцене больших данных, это было путеводной звездой согласованности в мрачном мире потоковой обработки. К счастью, с тех пор ситуация несколько улучшилась, но примечательно, сколько потоковых систем все еще пытаются обойтись без сильной согласованности. Я серьезно не могу поверить, что обработка в режиме 'максимум однажды' все еще остается чем‑то особенным, но это так. Еще раз повторю, потому что этот момент важен: для обработки ровно один раз требуется сильная согласованность, которая необходима для корректности, что является требованием для любой системы, которая будет иметь шанс соответствовать или превосходить возможности пакетных систем. Если только вам по‑настоящему нет дела до ваших результатов, я умоляю вас избегать любой потоковой системы, которая не обеспечивает строго согласованного состояния. Пакетные системы не требуют раньше времени проверять, способны ли они давать правильные ответы, не тратьте время на потоковые системы, которые не могут соответствовать той же самой планке. Если вам интересно узнать больше о том, что нужно, чтобы получить сильную согласованность в потоковой системе, я рекомендую вам ознакомиться с работами MillWheel и Spark Streaming. Обе статьи тратят значительное количество времени на обсуждение согласованности. Учитывая количество качественной информации на эту тему в литературе и других местах, дальше в этих постах я ее освещать не буду.
Инструменты для работы со временем — Это выводит вас за рамки пакетной обработки. Хорошие инструменты для работы со временем необходимы для работы с неограниченными, неупорядоченными данными с различными смещениями по времени произошедшего события. Все большее число современных наборов данных демонстрируют эти характеристики, а существующие пакетные системы (а также большинство потоковых систем) не имеют необходимых инструментов, чтобы справиться с трудностями, которые они создают. Оставшуюся часть этого поста и большую часть следующего поста я потрачу на объяснение и сосредоточение внимания на этом вопросе. Для начала мы получим базовое понимание важного понятия временных областей, после чего глубже рассмотрим, что я подразумеваю под неограниченными, неупорядоченными данными с различными смещениями времени произошедшего события. Остаток этого поста мы потом потратим на то, чтобы посмотреть на общие подходы к ограниченной и неограниченной обработке данных, используя как пакетные, так и потоковые системы.
Время события или обработки (Event time vs Processing Time)
Чтобы убедительно говорить о неограниченной обработке данных, необходимо четкое понимание связанных с этим временных определений. В любой системе обработки данных обычно есть два типа времени, которые нас волнуют:
Время события, то есть время, в которое события действительно произошли.
Время обработки, то есть время, в которое события наблюдаются в системе.
Не все варианты использования заботятся о времени событий (а если в вашем случае нет, ура! — ваша жизнь проще), но многие делают это. Примеры включают характеристику поведения пользователей с течением времени, большинство приложений для выставления счетов и многие типы обнаружения аномалий, и это лишь некоторые из них.
В идеальном мире время событий и время обработки всегда будут равны, при этом события будут обрабатываться сразу по мере их возникновения. Однако реальность не так любезна, и перекос между временем события и временем обработки не только ненулевой, но и часто сильно изменчивый из‑за характеристик базовых источников ввода, механизма выполнения и аппаратного обеспечения. Вещи, которые могут повлиять на уровень перекоса, включают в себя:
Ограничения общих ресурсов, такие как перегрузка сети, сетевые границы или сегментирование или общий ЦП в невыделенной среде.
Программные причины, такие как логика распределенной системы, разногласия между компонентами и т. д.
Особенности самих данных, включая распределение ключей, дисперсию пропускной способности или дисперсию в беспорядке (например, самолет, полный людей, выводивших свои телефоны из авиарежима после того, как они использовали их в автономном режиме на протяжении всего полета).
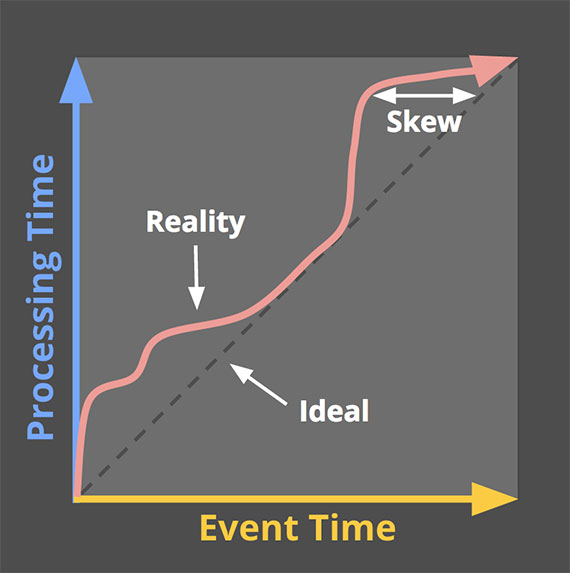
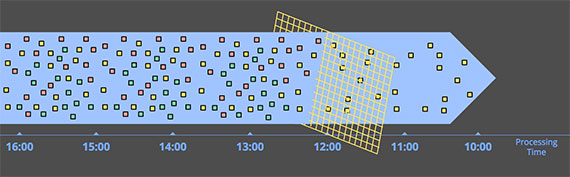
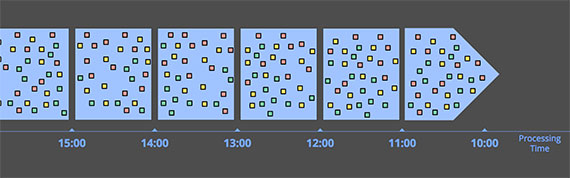
В результате, если вы отображаете ход времени события и времени обработки в любой реальной системе, вы обычно получаете что‑то, что немного похоже на красную линию на рисунке 1.
")
Черная пунктирная линия с наклоном в единицу представляет идеальное состояние, где время обработки и время события точно равны; красная линия представляет реальность. В этом примере система немного отстает в начале обработки, ближе поворачивается к идеалу посередине, а затем снова немного отстает к концу. Горизонтальное расстояние между идеалом и красной линией — это сдвиг между временем обработки и временем события. Этот перекос по сути представляет собой задержку, создаваемую конвейером обработки.
Поскольку сопоставление между временем события и временем обработки не является статическим, это означает, что вы не можете анализировать свои данные исключительно в контексте того, когда они наблюдаются в вашем конвейере, если вас волнует время событий (т. е. когда события действительно произошли). К сожалению, именно так работает большинство существующих систем, предназначенных для неограниченных данных. Чтобы справиться с бесконечной природой неограниченных наборов данных, эти системы обычно используют некоторое представление об окне входящих данных. Внизу мы обсудим оконную обработку очень глубоко, но это, по сути, означает рубку набора данных на конечные части по временным границам.
Если вы заботитесь о корректности и заинтересованы в анализе ваших данных в контексте времени их событий, вы не можете определить эти временные границы, используя время обработки (т. е. окно времени обработки), как это делает большинство существующих систем; без последовательной корреляции между временем обработки и временем события, некоторые из ваших данных о времени событий окажутся в неправильных временных окнах обработки (из‑за присущей распределенным системам задержки, онлайн/офлайн‑характера разных типов входных источников и т. д.), выбрасывая корректность в окно, как это было ранее. Более подробно рассмотрим эту проблему в ряде примеров ниже, а также в следующем посте.
К сожалению, картина не совсем радужная и при окнах по времени события. В контексте неограниченных данных беспорядок и меняющийся перекос вызывают проблему полноты временных окон событий: отсутствие предсказуемого отображения между временем обработки и временем события, как вы можете определить, когда вы наблюдали все данные за заданное время события X? Для многих реальных источников данных это просто невозможно. Подавляющее большинство систем обработки данных, используемых сегодня, полагаются на некоторое понятие полноты, что ставит их в крайне невыгодное положение применительно к неограниченным наборам данных.
Я утверждаю, что вместо того, чтобы пытаться объединить неограниченные данные в конечные пакеты информации, которые в конце концов станут полными, нам следует разработать инструменты, которые позволят нам жить в мире неопределенности, вызванной этими сложными наборами данных. Придут новые данные, старые данные могут быть отозваны или обновлены, и любая система, которую мы создаем, должна быть в состоянии справиться с этими фактами сама по себе, при этом понятия полноты являются удобной оптимизацией, а не семантической необходимостью.
Прежде чем погрузиться в то, как мы пытались построить такую систему с помощью модели текущих данных(ориг. Dataflow Model), используемой в Cloud Dataflow, давайте закончим еще одну полезную часть основ: общие шаблоны обработки данных.
Общие шаблоны обработки данных
На данный момент у нас достаточно информации, чтобы мы могли начать рассматривать основные типы шаблонов обработки, распространенные сегодня при ограниченной и неограниченной обработке данных. Мы рассмотрим оба типа обработки, и где это уместно, в контексте двух основных типов систем, которые нас волнуют (пакетный и потоковый, где в этом контексте я, по сути, смешиваю микропакетный режим с потоковым, поскольку различия между ними не очень важны на этом уровне).
Ограниченные данные (ориг. Bounded data)
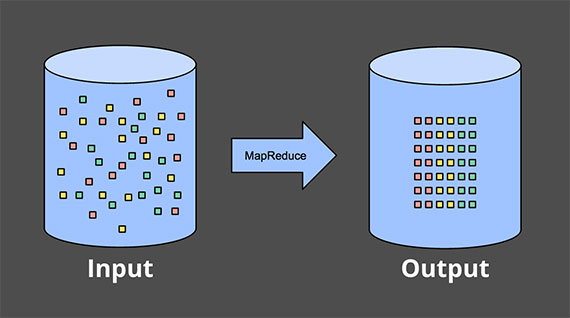
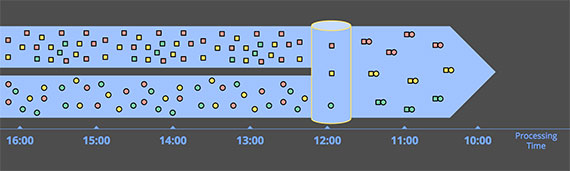
Обработка ограниченных данных довольно проста и, вероятно, знакома всем. На рисунке 2 мы начинаем слева с набора данных, полного энтропии. Мы запускаем его через какой‑то механизм обработки данных (обычно пакетный, хотя хорошо продуманный потоковый движок будет работать так же хорошо), такой как MapReduce, и справа получаем новый структурированный набор данных с большей внутренней ценностью:

Хотя, конечно, существуют бесконечные вариации того, что вы действительно можете вычислить по этой схеме, общая модель довольно проста. Гораздо интереснее задача обработки неограниченного набора данных. Давайте теперь рассмотрим различные способы обычной обработки неограниченных данных, начиная с подходов, используемых с традиционными пакетными движками, а затем заканчивая подходами, которые можно использовать с системой, предназначенной для неограниченных данных, например, с большинством потоковых или микропакетных движков.
Неограниченные данные в пакетной форме ( ориг. Unbounded data - batch)
Пакетные механизмы, хотя и не были явно разработаны с учетом неограниченных данных, использовались для обработки неограниченных наборов данных с момента первой разработки подобных систем. Как и следовало ожидать, такие подходы вращаются вокруг разделения неограниченных данных на набор ограниченных наборов данных, подходящих для пакетной обработки.
Постоянные интервалы времени (Fixed windows)
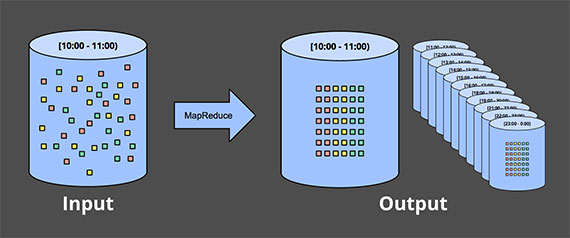
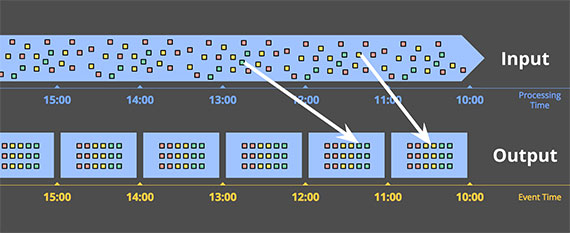
Наиболее распространенный способ обработки неограниченного набора данных с использованием повторяющихся запусков пакетного механизма — это деление таких данных на интервалы фиксированного размера, а затем обработка каждого из этих интервалов как отдельного ограниченного источника данных. В частности, для источников ввода, таких как журналы событий, где события могут быть записаны в иерархии каталогов и файлов, имена которых представляют отдельный промежуток времени, которому они соответствуют, подобные вещи на первый взгляд кажутся довольно простыми, поскольку вы, по сути, выполнили временную перетасовку, чтобы определить данные в соответствующие временные окна заранее.
В действительности, однако, у большинства систем все еще есть проблема полноты: что, если некоторые из ваших событий задерживаются по пути к журналам из‑за сегментации сети передачи? Что, если ваши события собираются по всему миру и должны быть перенесены в общее место перед обработкой? А если ваши события приходят с мобильных устройств? Это означает, что может потребоваться какое‑то смягчение (например, задержка обработки до тех пор, пока вы не будете уверены, что все события собраны, или повторная обработка всей партии для данного окна всякий раз, когда данные поступают с опозданием).

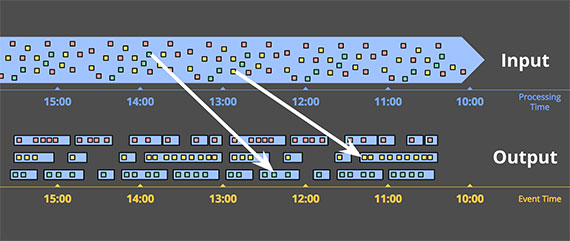
Сеансы
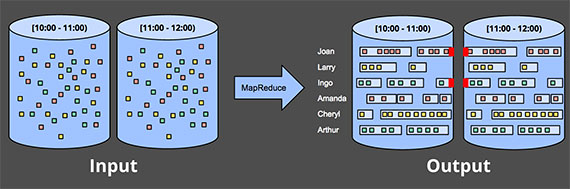
Подобный подход разваливается еще сильнее, когда вы пытаетесь использовать пакетный механизм для обработки неограниченных данных в более сложных оконных стратегиях, такие как сеансы (или сессии). Сеансы обычно определяются как периоды активности (например, для конкретного пользователя), завершающиеся периодом бездействия. При расчете сеансов с использованием типичного пакетного механизма вы часто получаете сеансы, разделенные на части, как указано красными метками на рисунке 3 ниже. Количество расщеплений можно уменьшить за счет увеличения размеров партий, но ценой увеличения задержки. Другой вариант — добавить дополнительную логику для сшивания сеансов из предыдущих запусков, что, однако, увеличивает сложность.

В любом случае, использование классического пакетного движка для расчета сеансов далеко не идеально. Более приятным способом было бы построение сеансов в потоковой манере, на что мы посмотрим позже.
Неограниченные данные - потоки (ориг. Unbounded data - streaming)
В отличие от сложившейся практики большинства подходов к пакетной неограниченной обработке данных, потоковые системы создаются специально для неограниченных данных. Как я отмечал ранее, для многих реальных распределенных источников ввода вы не только имеете дело с неограниченными данными, но и с данными, которые являются:
Крайне неупорядоченными по времени событий, а это означает, что вам нужна какая‑то временная перетасовка в вашем конвейере, если вы хотите проанализировать данные в контексте, в котором они произошли.
По разному смещены по времени события, то есть нельзя просто предположить, что вы всегда увидите большую часть данных для данного времени события X в пределах некоторого постоянного промежутка времени Y.
Существует несколько подходов, которые можно использовать при работе с данными, имеющими эти характеристики. Обычно я разделяю эти подходы на четыре группы:
Независимые от времени
Аппроксимация
Окно по времени обработки
Окно по времени мероприятия
Потратим сейчас немного времени на то, чтобы рассмотреть каждый из этих подходов.
Независимость от времени
Независимая от времени обработка используется в тех случаях, когда время по существу не имеет значения — т.е, вся соответствующая логика управляется собственно данными. Поскольку поведение системы в таких вариантах использования продиктовано появлением большего количества данных, потоковому движку действительно нечего поддерживать, кроме базовой доставки данных. В результате, по существу, все существующие потоковые системы поддерживают не зависящие от времени варианты использования «из коробки» (отклонения от системы к системе конечно неизбежны, для тех из вас, кто заботится о корректности). Пакетные системы также хорошо подходят для неограниченной по времени обработки неограниченных источников данных путем простого разделения неограниченного источника на произвольную последовательность ограниченных наборов данных и независимой обработки этих наборов данных. Рассмотрим в этом разделе пару конкретных примеров, но, учитывая очевидность использования не зависящей от времени обработки, не потратим на нее много времени.
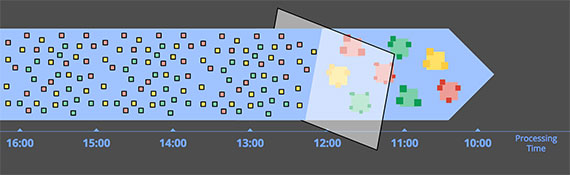
Фильтрация
Самая основная форма такой обработки — это фильтрация. Представьте, что вы обрабатываете журналы веб‑трафика и хотите отфильтровать весь трафик, исходящий не из определенного домена. Вы смотрели на каждую запись по мере ее поступления, проверяли, принадлежит ли она интересующему домену, и удаляли ее, если нет. Поскольку подобные вещи в любой момент времени зависят только от одного элемента, тот факт, что источник данных неограничен, неупорядочен и имеет различный временной сдвиг, не имеет значения.
 различных типов фильтруется в однородный сборник, содержащий один тип. Изображение: Тайлер Акидау.")
Внутренняя связь (Inner-joins)
Другим не зависящим от времени примером является внутреннее соединение (или хеш‑соединение). При объединении двух неограниченных источников данных, если вас волнуют результаты объединения только при поступлении элемента из обоих источников, в логике нет временной составляющей. Увидев значение из одного источника, вы можете просто буферизовать его в постоянном хранилище; вам нужно выпустить объединенную запись только после того, как придет второе значение из другого источника. (По правде говоря, вам, скорее всего, понадобится какая‑то политика сбора мусора для неиспользованных частичных соединений, которая, вероятно, будет зависеть от времени. Но для варианта использования с небольшим количеством незавершенных соединений или вообще без них это не является проблемой.)
 различных типов фильтруется в однородный сборник, содержащий один тип. Изображение: Тайлер Акидау.")
Переключение семантики на какое‑то внешнее соединение создает проблему полноты данных, о которой мы говорили: как только вы увидите одну сторону соединения, как вы узнаете, придет ли когда‑нибудь другая сторона или нет? По правде говоря, не узнаете, поэтому приходится вводить какое‑то понятие тайм‑аута, который вводит элемент времени. Этот элемент времени — по сути, форма оконной обработки, с которой мы более внимательно разберемся через минуту.
Приблизительные алгоритмы

Вторая основная категория подходов — это аппроксимационные алгоритмы, такие как приближенный Top‑N, потоковое K‑среднее и т. д. Они берут неограниченный источник входных данных и предоставляют выходные данные, которые, если вы присмотритесь на них, выглядят более или менее как то, что вы надеялись получить. Преимущество алгоритмов аппроксимации заключается в том, что по своей конструкции они имеют низкие накладные расходы и предназначены для неограниченных данных. Недостатками является то, что их число ограничено, сами алгоритмы часто сложны (что затрудняет создание новых), а их приблизительный характер ограничивает их полезность.
Стоит отметить: эти алгоритмы, как правило, действительно имеют какой‑то элемент времени в своей конструкции (например, какой‑то встроенный период распада). А поскольку они обрабатывают элементы по мере их поступления, этот элемент времени обычно основан на времени обработки. Это особенно важно для алгоритмов, которые предоставляют своего рода доказуемые пределы ошибок для своих приближений. Когда пределы ошибок основаны на данных, поступающих по порядку, они практически бессмысленны, когда вы передаете алгоритму неупорядоченные данные с различным перекосом во времени событий. Это то, что стоит просто иметь в виду.
Алгоритмы аппроксимации сами по себе увлекательная тема, но, поскольку они, по сути, являются еще одним примером нестационарной обработки (без учета временных особенностей самих алгоритмов), их довольно просто использовать, и поэтому они не заслуживают дальнейшего внимания с учетом нашей нынешней направленности.
Разбиение на интервалы (Windowing)
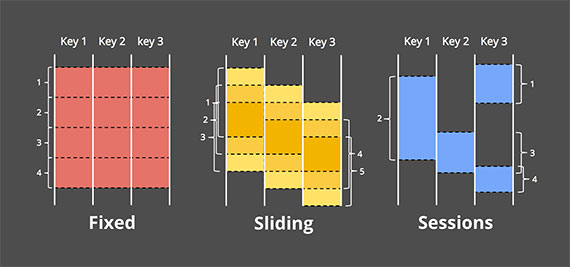
Остальные два подхода к неограниченной обработке данных представляют собой варианты оконной обработки. Прежде чем погрузиться в различия между ними, я должен прояснить, что именно я имею в виду под окнами, поскольку я коснулся этого лишь кратко. Окно — это просто идея взять источник данных (неограниченный или ограниченный) и разбить его по временным границам на конечные фрагменты для обработки. На рисунке 8 показаны три различных шаблона окон:
, подчеркивая разницу между выровненными окнами (которые применяются ко всем данным) и невыровненными окнами (которые применяются к подмножеству данных). Изображение: Тайлер Акидау. (Прим. пер. Fixed - фиксированные, Sliding - скользящие, Sessions - сеансы)")
Фиксированные окна: фиксированные окна делят время на сегменты фиксированной длины. Обычно (как на рисунке 8) сегменты фиксированных окон применяются равномерно по всему набору данных, что является примером выровненных окон. В некоторых случаях желательно сдвинуть окна по фазе для разных подмножеств данных (например, для каждого ключа), чтобы более равномерно распределить нагрузку завершения окна во времени, что вместо этого является примером невыровненных окон, поскольку они различаются по данным.
Скользящие окна: Обобщая фиксированные окна, скользящие окна определяются фиксированной длиной и фиксированным периодом. Если период меньше длины, то окна перекрываются. Если период равен длине, у вас есть фиксированные окна. А если период больше длины, у вас есть необычное окно выборки, которое рассматривает только подмножества данных с течением времени. Как и в случае с фиксированными окнами, скользящие окна обычно выравниваются, но в некоторых случаях могут быть не выровнены в целях оптимизации производительности. Обратите внимание, что скользящие окна на рисунке 8 нарисованы таким образом, чтобы создать ощущение скользящего движения; на самом деле все пять окон будут действовать по всему набору данных.
Сеансы: пример динамических окон, сеансы состоят из последовательностей событий, завершающихся периодом бездействия, превышающим некоторый тайм‑аут. Сеансы обычно используются для анализа поведения пользователей с течением времени путем группировки серии событий, связанных во времени (например, последовательности видеороликов, просматриваемых за один присест). Сессии интересны тем, что их продолжительность не может быть определена априори; они зависят от фактических данных. А еще они — канонический пример не выровненных окон, поскольку сеансы практически никогда не бывают одинаковыми для разных подмножеств данных (например, у разных пользователей).
Две типа времени — время обработки и время события — по сути, являются теми, которые нас волнуют2. Окно имеет смысл в обоих доменах, поэтому рассмотрим каждый подробно и посмотрим, чем они отличаются. Поскольку окна времени обработки гораздо чаще встречается в существующих системах, начну с этого.
Интервалы времени обработки

В интервалах времени обработки система, по сути, буферизует входящие данные в окна до тех пор, пока не пройдет некоторое время обработки. Например, в случае пятиминутных фиксированных окон система будет буферизовать данные в течение пяти минут времени обработки, после чего она будет обрабатывать все данные, которые она наблюдала за эти пять минут, как окно и отправлять их далее.
Есть несколько приятных свойств окна времени обработки:
Это просто. Реализация чрезвычайно проста, поскольку вы никогда не беспокоитесь о перетасовке данных во времени. Вы просто буферизуете данные по мере их поступления и отправляете их вниз по течению, когда окно закрывается.
Судить о полноте окна просто. Поскольку система прекрасно знает, были ли видны все входные данные для окна или нет, она может принимать идеальные решения о том, завершено ли данное окно или нет. Это означает, что нет необходимости иметь возможность каким‑либо образом обрабатывать запоздавшие данные при таком способе
Если вы хотите получить информацию об источнике в том виде, в каком она наблюдается, окно времени обработки — это именно то, чего вы хотите. Многие сценарии мониторинга попадают в эту категорию. Представьте себе, что вы отслеживаете количество запросов в секунду, отправленных в веб‑сервис глобального масштаба. Расчет частоты этих запросов с целью обнаружения сбоев является идеальным использованием этого подхода.
Помимо преимуществ, есть один очень большой недостаток окна времени обработки: если с рассматриваемыми данными связано время события, эти данные должны поступать в порядке времени события, чтобы окна времени обработки отражали факт того, когда эти события действительно произошли. К сожалению, упорядоченные данные по времени событий редко встречаются во многих реальных распределенных источниках ввода.
В качестве простого примера представьте себе любое мобильное приложение, которое собирает статистику использования для последующей обработки. В тех случаях, когда данное мобильное устройство отключается на какое‑либо время (краткая потеря связи, авиарежим во время полета по стране и т. д.), данные, записанные в этот период, не будут загружаться до тех пор, пока устройство не выйдет в онлайн снова. Это означает, что данные могут поступать со сдвигом времени события в минуты, часы, дни, недели или более. По сути, невозможно сделать какие‑либо полезные выводы из такого набора данных, когда он разделен на интервалы времени обработки.
В качестве другого примера можно показать, что многие распределенные источники ввода предоставляют упорядоченные (или почти так) данные о времени события, когда вся система в порядке. К сожалению, тот факт, что сдвиг времени событий невелик для источника входных данных, когда он здоров, не означает, что он всегда останется таким. Рассмотрим глобальный сервис, который обрабатывает данные, собранные на нескольких континентах. Если в сети возникают проблемы в трансконтинентальной линии с ограниченной полосой пропускания (которые, к сожалению, удивительно распространены), что еще больше уменьшает полосу пропускания и/или увеличивает задержку, внезапно часть ваших входных данных может начать поступать с гораздо большим сдвигом, чем раньше. Если вы просматриваете эти данные по времени обработки, ваши окна больше не являются репрезентативными для данных, которые фактически произошли внутри них; вместо этого они представляют окна времени, когда события прибыли в конвейер обработки, что представляет собой произвольное сочетание старых и текущих данных.
В обоих этих случаях мы действительно хотим отделять данные времени событий таким образом, чтобы они были устойчивы к порядку прибытия событий. Чего мы действительно хотим, так это окна времени события.
Интервалы времени события
Окно времени события — это то, что вы используете, когда вам нужно наблюдать источник данных в конечных фрагментах, которые отражают время, в которое эти события действительно произошли. Это золотой стандарт фрагментирования времени. К сожалению, большинство систем обработки данных, используемых сегодня, не имеют такой функции (хотя любая система с достойной моделью согласованности, такая как Hadoop или Spark Streaming, может выступать в качестве разумной основы для создания такой оконной системы). (прим. пер. что‑то могло измениться с момента выхода публикации в 2015 г.)
На рисунке 10 показан пример оконной обработки неограниченного источника в часовые фиксированные окна:

Сплошные белые линии на диаграмме выделяют два конкретных случая. Оба этих события поступили в окна времени обработки, которые не соответствовали окнам времени события, к которым они принадлежали. Таким образом, если бы эти данные были включены в окна обработки для тех вариантов использования, которым важно время событий, рассчитанные результаты были бы неверными. Как и следовало ожидать, правильность времени событий — это одна из хороших вещей в использовании окон времени событий.
Еще одна приятная вещь в окне времени событий в неограниченном источнике данных заключается в том, что вы можете создавать окна динамического размера, такие как сеансы, без произвольного разбиения, наблюдаемого при определении сеансов через фиксированные окна (как мы видели ранее на примере сеансов в разделе «Неограниченные данные — пакетная обработка»):

Конечно, мощная семантика редко бывает бесплатной, и окна времени события не являются исключением. Окна времени событий имеют два заметных недостатка из‑за того, что окна часто должны жить дольше (по времени обработки), чем фактическая длина самого окна:
Буферизация: из‑за увеличенного срока жизни окон требуется большая буферизация данных. К счастью, постоянное хранилище, как правило, является самым дешевым из типов ресурсов, от которых зависит большинство систем обработки данных (остальные — это в первую очередь процессорное время, пропускная способность сети и оперативная память). Таким образом, эта проблема обычно вызывает гораздо меньше беспокойства, чем можно было бы подумать, при использовании любой хорошо спроектированной системы обработки данных с четко согласованным постоянным состоянием и приличным уровнем кэширования в памяти. Кроме того, многие полезные функции агрегации не требуют буферизации всего входного набора (например, суммы или среднего), а вместо этого могут выполняться постепенно, с гораздо меньшим промежуточным значением, хранящимся в постоянной памяти.
Полнота: учитывая, что у нас часто нет хорошего способа узнать, когда мы увидели все данные для данного окна, как мы узнаем, когда результаты для окна готовы материализоваться? По правде говоря, мы не можем. Для многих типов входных данных система может дать достаточно точную эвристическую оценку оконного завершения по чему‑то вроде водяных знаков MillWheel (о чем я расскажу подробнее в части 2). Но в тех случаях, когда абсолютная правильность имеет первостепенное значение (опять же, подумайте о финансовых операциях и выставлении счетов), единственный реальный вариант — предоставить создателям конвейера обработки возможность выразить, когда они хотят, чтобы результаты для окон были материализованы, и как эти результаты следует уточнять с течением времени. Заниматься оконной полнотой (или ее отсутствием) — тема увлекательная, но, пожалуй, лучше всего исследовать её в контексте конкретных примеров, которые мы рассмотрим в следующий раз.
Заключение
Уф! Здесь было много информации. Тем из вас, кто зашел так далеко: вас следует похвалить! На данный момент мы находимся примерно на полпути к материалу, который я хочу охватить, поэтому, вероятно, разумно отступить, подвести итог тому, что я освещал до сих пор, и позволить всему немного усвоиться, прежде чем погрузиться во вторую часть. Преимуществом всего этого является то, что Часть 1 — скучный пост; Часть 2 — это то, с чего действительно начинается самое интересное.
Кратко
Подводя итог, в этом посте у меня есть:
Уточненная терминология, в частности сужение определения «потоковой обработки» для применения только к механизмам выполнения, при этом используются более описательные термины, такие как неограниченные данные и приблизительные/спекулятивные результаты для отдельных концепций, часто относимых к категории «потоковой обработки».
Оценил относительные возможности хорошо спроектированных систем пакетной обработки и потоковой обработки, заявив, что потоковая обработка на самом деле является строгим надмножеством пакетной и что такие понятия, как лямбда‑архитектура, которые основаны на том, что потоковая система уступает пакетной, предназначены для вывода из эксплуатации по мере развития потоковых систем.
Предложил две концепции, необходимые потоковым системам как для догоняющего, так и для того, чтобы в конечном итоге превзойти пакетные, а именно: правильность и инструменты для работы со временем соответственно.
Установлены важные различия между временем события и временем обработки, охарактеризованы трудности, которые эти различия создают при анализе данных в контексте того, когда они произошли, и предложен сдвиг в подходе от представлений о полноте к простой адаптации к изменениям данных с течением времени.
Рассмотрел основные подходы к обработке данных, широко используемые сегодня для ограниченных и неограниченных данных, как через пакетные, так и через потоковые механизмы, грубо разделив неограниченные подходы на: не зависящие от времени, аппроксимацию, оконную времени обработки и оконную времени событий.
В следующей части
В этой публикации приводится контекст, необходимый для конкретных примеров, которые я буду изучать во второй части, которая будет состоять примерно из следующего:
Концептуальный взгляд на то, как мы разбили понятие обработки данных в Dataflow Model по четырем связанным осям: что, где, когда и как.
Подробный взгляд на обработку простого и конкретного набора примерных данных в нескольких сценариях, подчеркивающий множество вариантов использования, разрешенных Dataflow Model, и конкретные задействованные API. Эти примеры помогут донести представления о времени события и времени обработки, представленные в этом посте, а также дополнительно изучить новые концепции, такие как водяные знаки(Watermarks).
Сравнение существующих систем обработки данных по важным характеристикам, описанным в обоих постах, чтобы лучше обеспечить обоснованный выбор между ними и стимулировать улучшение в недостающих областях, при этом моей конечной целью является улучшение систем обработки данных в целом и системы потоковой передачи, в частности, во всем сообществе больших данных.
Должно быть приятно. Увидимся позже!
Примечания
1 То, что я представляю, не неотъемлемое ограничение потоковых систем, а просто следствие выбора дизайна, сделанного до сих пор в большинстве потоковых систем. Разница эффективности между пакетной и потоковой обработкой во многом является результатом улучшенного пакетирования и более эффективного тасования данных, наблюдаемых в пакетных системах. Современные пакетные системы делают все возможное, чтобы реализовать сложную оптимизацию, которая обеспечивает замечательный уровень пропускной способности с использованием удивительно скромных вычислительных ресурсов. Нет причин, по которым умные идеи, которые делают пакетные системы лидерами эффективности, которыми они являются сегодня, не могли быть включены в систему, предназначенную для неограниченных данных, предоставляя пользователям гибкий выбор между тем, что мы обычно считаем системами с высокими задержками и более эффективной пакетной обработки или обработкой с низкой задержкой и более низкой эффективностью потоковой обработки. По сути, это то, что мы сделали с Cloud Dataflow, предоставив как пакетные, так и потоковые механизмы по одной и той же унифицированной модели. В нашем случае мы используем отдельные исполнители, потому что у нас есть две независимо разработанные системы, оптимизированные для их конкретных вариантов использования. В долгосрочной перспективе, с инженерной точки зрения, мне бы хотелось, чтобы мы объединили их в единую систему, которая включает в себя лучшие части обоих, сохраняя при этом гибкость выбора соответствующего уровня эффективности. Но это не то, что у нас есть в наличии на настоящий момент. И честно говоря, благодаря единой модели текущих данных это даже не является строго необходимым; так что этого вполне может никогда и не произойти. (Назад)
2 Если хорошо поискать в академической литературе или потоковых системах на базе SQL, то наткнетесь и на третью временную область окон: окна основе множеств (т. е. окна, размеры которых определяются количеством элементов). Однако оконная обработка на основе кортежей, по сути, является формой окна по времени обработки, при которой элементам назначаются монотонно увеличивающиеся временные метки по мере их поступления в систему. Как таковой, мы не будем здесь подробно обсуждать окна на основе кортежей (правда, пример ее мы увидим во второй части). (Назад)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}