Привет! Меня зовут Андрей Чучалов, я работаю в билайне, и в этом посте я расскажу про оптимизацию параметров запуска приложений в Spark, поиск проблем и повышение производительности. Разберем запуск приложений Spark в базовой и расширенной версиях, покажу методы расчёта основных параметров работы приложения для производительности и эффективности использования доступных ресурсов кластера. Бонусом — о том, как всё это привязано к деньгам, и где сэкономить можно, а где — не стоит.
Для чего это вообще нужно
Спараметризировать приложение — это не такая уж грандиозная задача, а вот попытаться понять взаимосвязь эффективности работы приложения со стоимостными параметрами такой работы — это уже сложнее. Тут вам пригодится своеобразное «боковое зрение».
В рассказе и на примерах я буду исходить из того, что у нас по умолчанию процесс ETL-обработки данных правильно, с самой программой всё ОК и она корректно спроектирована. И оборудование в составе кластера тоже рабочее и достаточное для запуска приложения. Это позволит говорить именно о влиянии параметров на эффективность.
Как у нас всё работает
Есть приложение и кластер. Мы получаем контекст, а через него— доступ к тем ресурсам, которые осуществляют непосредственный расчёт.
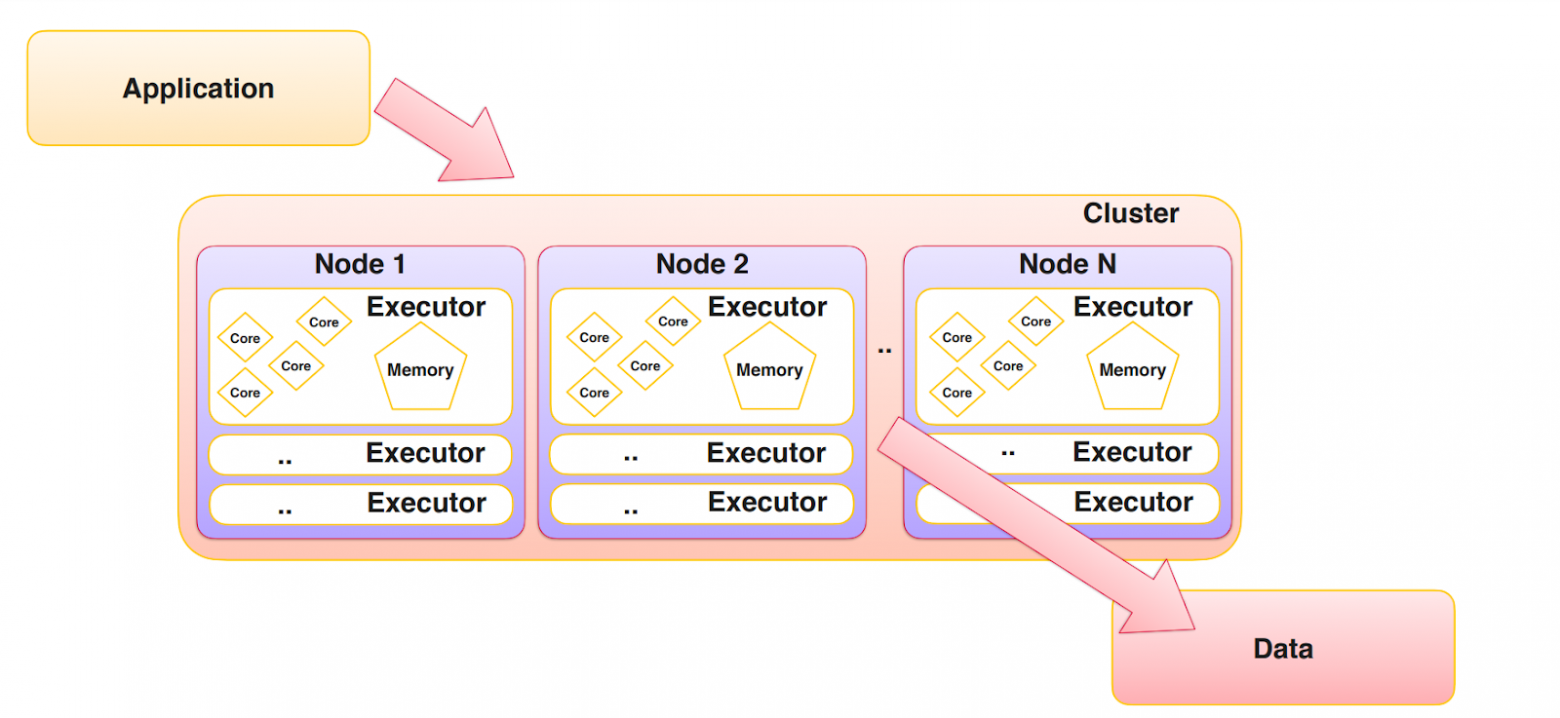
Кластер — это совокупность виртуальных серверов, зачастую без привязки к физической технике. Нод, которые являются воркерами, может быть несколько — одна, две, N, в зависимости от объёма используемого физического кластера. Внутри нод есть экзекьюторы, которые обладают свойствами, такими как количество ядер и объем памяти. Этот кластер пытается загрузить определенные данные, которые лежат в определённом месте (хранилище объектов, HDFS-хранилище, в общем, где вам привычнее). И после этого возвращает нам результат.
В нашем случае объектами параметризации будут процессор, память и параллелизм, который принимает во всём этом непосредственное участие.
Вот пример конфигурации.
--driver-cores 5
--executor-cores 5
--driver-memory 12G
--executor-memory 12G
--num-executors 150
--conf spark.driver.maxResultSize=7G
--conf spark.sql.shuffle.partitions=8000
--conf spark.default.parallelism=1500
--conf spark.dynamicAllocation.enabled=falseА теперь давайте немного на живом коде, у меня есть пример на Яндекс Облаке.
Входим в spark shell. Сделаем приложение, которое будет работать из коробки. Здесь у нас spark сконфигурирован в процессе создания кластера, так что никаких особых параметров использования ресурсов мы ему не задаем.
У нас включена динамическая аллокация ресурсов — spark сам для себя решит, какое количество ресурсов он использует для проведения наших расчётов. В моём примере были общедоступные данные по ковидной статистике, загруженные в HDFS, один CSV-файл занимает 12 гигабайт. Это нужно, чтобы за адекватное время проверить, сколько будет идти расчёт. Подгрузить данные очень просто — мы определяем наш датасет в виде некоторых комментариев, связанных с тематикой ковида.
Запустим простую операцию, которая подсчитает количество данных в датасете. На кластере параллельно работает 10 тасок: у нас параллельно используются 10 ядер для расчета вычисления количества данных внутри нашего датасета. Каждый мой кластер состоит из одного мастера и трёх воркеров. На каждый воркер приходится 4 ядра и 8 гигабайт памяти. Грубо говоря, на вычислительный расчет у меня получается 12 ядер.
За 25 секунд с использованием 10 ядер мы получили количество данных — порядка 17 миллионов. Всё это spark посчитал за 25 секунд именно с учётом динамического распределения ресурсов.
Тут сразу возникает главный вопрос — почему spark не дал нам для работы все 12 ядер, а использовал лишь 10? Мы же, вообще-то, оплачиваем мощности из разряда 12 ядер, куда ещё 2 делись? Выходит, что мы теряем какие-то средства, платя за мощности, которые не используем.
Понятно, что spark оставил тут себе точку входа для второй задачи. На случай, если кто-то еще придёт на этот кластер с желанием что-то запустить, тогда новый расчёт сразу же запустится, просто с меньшим количеством ресурсов. Но он не будет дожидаться окончания моих вычислений, которые уже выполняются. Звучит здорово, но для меня это невыгодно — раз я запустил кластер для одного приложения, то я хочу использовать все доступные мне и оплаченные ресурсы.
Значит, spark надо настроить.
Настраиваем spark
Сделать это можно через передачу определенных параметров, где я укажу количество экзекьюторов.
Первое, с чего начинаем, это драйвер, так как у нас драйвер — машинка послабее, там всего два ядра, Собственно говоря, так мы их и указываем — driver cores 2 executor cores 4.
Самих экзекьюторов у нас три. Плюс для каждого экзекьютора я определяю объем памяти и, соответственно, могу передать некоторые параметры — партишены в нашем случае. Если бы мы запускали join, это было бы полезно. Но так, как мы рассчитываем просто count, то здесь они никакой роли не играют. Главное, что я хочу сделать — выключить динамическую аллокацию ресурсов на spark как раз для того, чтобы вот эти передаваемые параметры работали, и spark их не переписывал собственными значениями.
Проверим, сработают эти настройки или нет.
Чтобы все эти настройки вступили в силу, все должно быть хорошо на самом кластере. Итак, у меня здесь executor-cores 4, а самих экзекьюторов — 3. Значит, spark должен использовать по-максимуму все 12 ядер. Проведу ту же самую операцию — определю датасет.
При таких настройках у нас заработают все 12 ядер одновременно вместо 10, которые были в прошлый раз. Это же будет работать, если кластер будет побольше, например, 24 ядра, 48 или вообще до 750 — в свое время была такая практика на очень достаточно тяжелых задачах. Вместо 25 секунд в первый раз сейчас это заняло 21 секунду,
А теперь сделаем всё немного интереснее
Положим всё это на вот такой график.
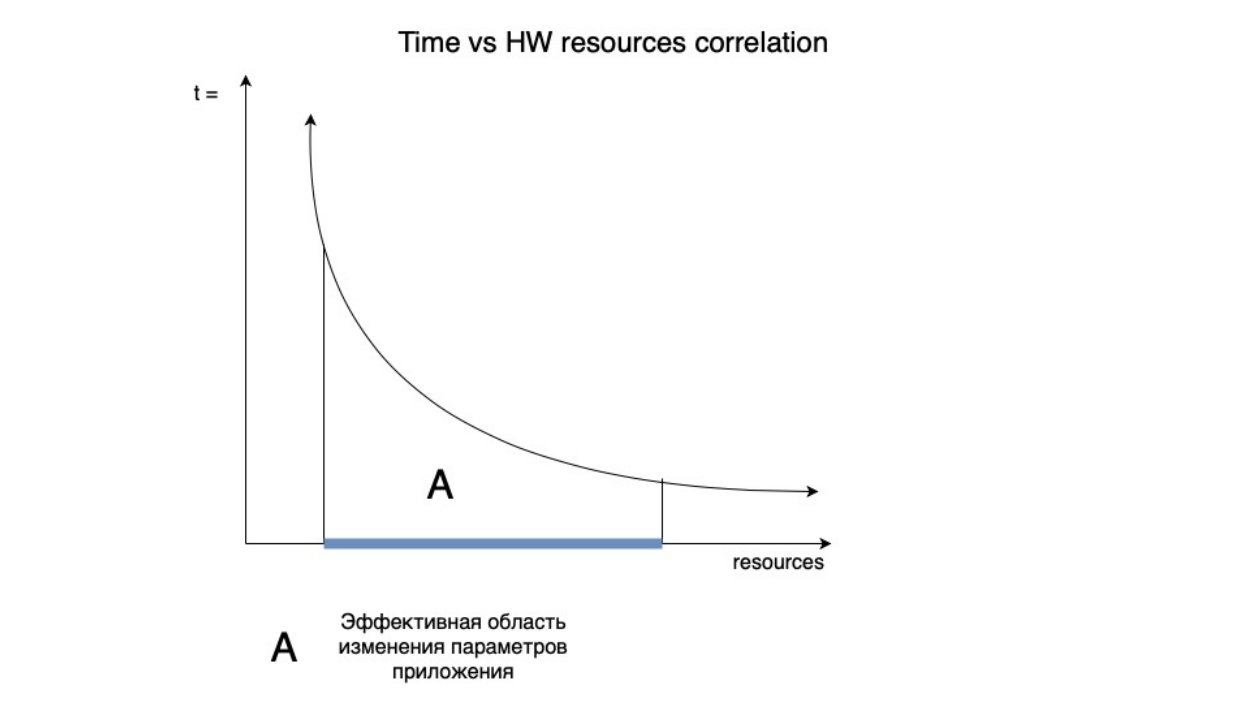
У нас есть зависимость количества времени работы нашего приложения от количества ресурсов, которые мы используем. И, соответственно, чем больше ресурсов мы используем, тем меньше времени тратится на выполнение нашей программы. Поэтому график времени здесь именно падающий, в зависимости от количества ресурсов, которые мы используем.
Всем известно, что мы не можем бесконечно ресурсы увеличивать и так же не можем их бесконечно уменьшать. Просто потому, что у нас найдётся такой этап времени, когда увеличение количества ресурсов станет бесконечным — оно не приведет к обозримому уменьшению времени, за которое наша программа будет рассчитывать результат.
Ровным счетом правдива и обратная ситуация. Например, если мы посмотрим слева от области А, то мы в принципе не можем не использовать ресурсы для вычисления. Поэтому существует и ситуация, когда уменьшение ресурсов даже в небольшом количестве будет существенно увеличивать время работы нашего приложения. Так что обозначим ту область, где мы можем эффективно менять параметры для нашего приложения, как область А.
Для чего всё это
Перемещаться по этому графику можно с помощью параметров. Spark воспринимает переданное нам количество параметров для экзекьюторов, количество памяти и количество ядер. То же самое для драйвера и плюс дополнительные какие-то параметры. С количеством ядер для экзекьюторов всё понятно — в каждом экзекьюторе мы должны использовать определённое количество ядер.
Само собой, чисто физически мы можем быть ограничены тем сервером, который используем. На своем сервере для примера я мог бы сделать и больше ядер, на то он и кластер. На самом деле, могло бы быть и два экзекьютора по шесть ядер. Но, скажем так, у нас есть определенная зависимость — чем больше данный параметр, тем меньше количество экзекьюторов. То есть на шесть ядер было бы уже два экзекьютора. Все, что кратно 12, мы можем все эти пары получить.

Соответственно, при уменьшении экзекьюторов у нас падает параллелизм, но малое количество ядер увеличивает объем операций ввода вывода. Практическим путём мы для себя этот параметр стали устанавливать равным пяти, реже четырём, еще реже — шести. В общем, 5 — это такой де-факто получившийся стандарт. Но он не так сильно влияет на производительность.
А вот что влияет — так это память. О ней (и о параллелизме) и будет вторая часть.
