Apache Hadoop — это набор утилит для построения суперкомпьютера, способного решать задачи, слишком большие для одного сервера. Множество серверов образуют Hadoop-кластер. Каждая машина в кластере носит название узла, или ноды. Если необходимо увеличить производительность системы, то в кластер просто добавляется больше серверов. Ethernet выполняет функции «системной шины» суперкомпьютера. В данной статье будут рассмотрены аспекты дизайна сетевой инфраструктуры, а также архитектура, которую Cisco предлагает использовать для таких систем.
Для понимания принципа работы Hadoop необходимо разобраться с функциями двух основных компонентов: HDFS (Hadoop File System) и MapReduce, которые будут рассмотрены в данной статье подробнее. Другие возможные составляющие системы показаны на Рисунке 1.

Рисунок 1. Экосистема Hadoop
HDFS — глобальная файловая система, распределенная через кластер, которая обеспечивает хранение данных. Файлы разбиваются на большие блоки, как правило, 64, 128 или 512 Мб, после чего они записываются на разные узлы кластера. Таким образом, на HDFS могут быть размещены файлы любого размера, даже превышающие объем хранилища одного сервера. Каждый записанный блок еще минимум дважды реплицируется на другие узлы. С одной стороны, репликация обеспечивает отказоустойчивость. С другой — возможность локальной обработки данных без нагрузки на сетевую инфраструктуру. Объем дискового пространства кластера при стандартном коэффициенте репликации должен быть в три раза больше, чем информация, которую требуется сохранить. Также необходимо иметь дополнительно 25–30% вне HDFS для хранения промежуточных данных, возникающих в процессе обработки. То есть на 1 Тб «полезной информации» нужно 4 Тб «сырого пространства».
MapReduce — система для распределения задачи обработки данных между узлами Hadoop-кластера. Этот процесс, как ни странно, состоит из двух стадий: Map и Reduce. Map запускается одновременно на многих узлах и выдает промежуточную информацию, обрабатываемую Reduce для предоставления конечного результата.
Приведу упрощенный пример, который поможет лучше понять происходящее. Представьте, что вам необходимо посчитать число повторений слов в газете. Вы будете записывать каждое слово и ставить галочку напротив, когда оно снова встретится в тексте. Этот процесс займет очень много времени, особенно если вы собьетесь и придется начинать все заново. Гораздо проще будет разделить газету на небольшие части и раздать их друзьям и знакомым с просьбой выполнить подсчет. Таким образом, задача будет распределена и каждый предоставит вам некоторый промежуточный результат. Поскольку данные уже прошли предварительную сортировку, то ваша задача будет очень простой — просуммировать полученную информацию. Выражаясь терминами Hadoop, ваши друзья выполнят стадию Map, а вы — Reduce. К слову, промежуточные данные носят название Shuffle, а кусочки газеты — Chunk.
Наилучшим считается вариант, когда процесс Мap работает с информацией на локальном диске. Если такой возможности нет по причине высокой утилизации узла, то задача будет передана другой ноде, которая предварительно скопирует данные, чем увеличит нагрузку на сеть. Если бы на HDFS хранилась только одна копия информации, то случаи удаленной обработки были бы частыми. По умолчанию HDFS создает три копии данных на разных узлах, и это хороший коэффициент для обеспечения отказоустойчивости и локальных вычислений.
Существует два типа узлов: SlaveNodes и MasterNodes. Узлы SlaveNode непосредственно записывают и обрабатывают информацию, запускают демоны DataNode и TaskTracker. MasterNodes выступают управляющими, они хранят метаданные файловой системы и обеспечивают распределение блоков на HDFS (NameNode), а также координируют MapReduce с помощью демона Job Tracker. Каждый демон запускается на своей собственной Java Virtual Machine (JVM).
Рассмотрим процесс записи на HDFS файла, разбитого на два блока (Рисунок 2). Клиент обращается к NameNode(NN) с запросом, на какие DataNode (DN) эти блоки должны быть помещены. NameNode дает инструкцию поместить Block1 на DN1. Кроме того, NameNode командует DN1 выполнить репликацию Block1 на DN2, а DN2 — на DN6. Аналогичным образом Block2 помещается на узлы DN2, DN5 и DN6. Каждый DN с периодичностью в несколько секунд отправляет NN отчет об имеющихся блоках. Если отчет не приходит, то DN считается потерянным, а это означает, что на одну реплику определенных блоков стало меньше. NN инициирует их восстановление на других DN. Если через некоторое время пропавший DN появится вновь, то NN выберет DN, с которых будут удалены лишние копии данных.
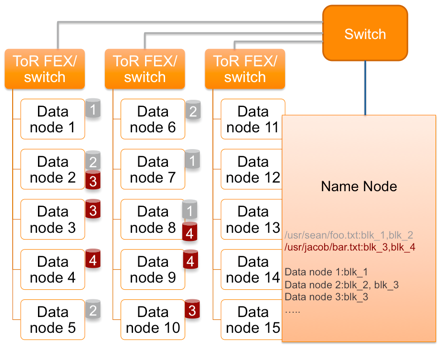
Рисунок 2. Процесс записи на HDFS
Эквивалентен NameNode по важности демон JobTracker, управляющий распределенной обработкой данных. Если вы хотите запустить программу на всем кластере, то она отправляется MasterNode с демоном JobTracker. JobTracker определяет, какие блоки данных нужны, и выбирает узлы, где стадия Мap может быть выполнена локально; кроме того, выбираются узлы для Reduce. Со стороны SlaveNode процесс взаимодействия с JobTracker выполняется демоном TaskTracker. Он сообщает JobTracker статус выполнения задачи. Если задача не осуществлена по причине ошибки или слишком длительного времени исполнения, то JobTracker передаст ее другому узлу. Частое невыполнение задачи узлом ведет к тому, что он будет помещен в черный список.

Рисунок 3. Процесс обработки данных MapReduce
Таким образом, для сетевой инфраструктуры Hadoop-кластер производит несколько типов трафика:
— Heartbeats — служебная информация между MasterNodes и SlaveNodes, с помощью которой определяются доступность узлов, статус исполнения задач, отправляются команды на репликацию или удаление блоков и т. д. Нагрузка Heartbeats на сеть минимальна, и эти пакеты не должны теряться, так как от них зависит стабильность работы кластера.
— Shuffle — данные, которые передаются после выполнения стадии Мар на Reduce. Природа трафика — от многих к одному, генерирует среднюю нагрузку на сеть.
— Запись на HDFS — запись и репликация больших объемов данных большими блоками. Высокая нагрузка на сеть.
Интересно наблюдать за тем, как эволюционируют вычислительные ресурсы, используемые под Hadoop. В 2009 году конфигурация типового узла, сбалансированного по ресурсам, представляла собой одноюнитовый двухсокетный сервер с четырьмя жесткими дисками, двухъядерными процессорами и 24 гигабайтами оперативной памяти, подключенный к гигабитной Ethernet-сети. Что изменилось за пять лет? Сменилось четыре поколения процессоров — они стали мощнее, поддерживают больше ядер и памяти, а 10-тигигабитная сеть широко используется в центрах обработки данных. И только жесткие диски не поменялись. Чтобы оптимально утилизировать доступные процессоры и память, современные кластеры строятся на базе двухъюнитовых серверов, куда можно поставить большое количество дисков. Число возможных операций с файловой подсистемой, в свою очередь, определяет потребности узлов в пропускной способности сети. На Рисунке 4 приведены данные для серверов различной конфигурации, откуда следует, что при построении системы лучше ориентироваться на скоростной 10GbE, так как узлы потенциально могут обрабатывать более 1 Гб/с.

Рисунок 4. Производительность подсистемы ввода/вывода в зависимости от количества жестких дисков
Требования к объему локальной системы хранения также определяют тот факт, что для Hadoop не используются серверы в блейдовом исполнении, где возможности по установке локальных дисков крайне ограничены. Также стоит отметить, что для SlaveNodes не используют виртуализацию и диски не собирают в RAID.
Компания Cisco имеет полный набор продуктов для построения аппаратной платформы под Hadoop. Это серверы, сетевые устройства, системы управления и автоматизации. На базе Cisco UCS и Nexus была создана и протестирована архитектура для работы с большими объемами данных, которая носит название CPA (Common Platform Architecture). В данном разделе статьи будут описаны особенности сетевого дизайна, используемого в решении.
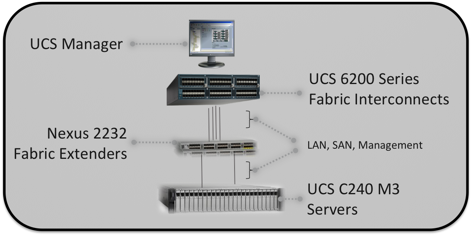
Рисунок 5. Компоненты Common Platform Architecture
Решение строится на следующем наборе оборудования:
— Fabric Interconnect 6200 (FI) — высокоскоростные неблокируемые универсальные коммутаторы со встроенной графической системой управления (UCSM) всеми компонентами подключаемой серверной инфраструктуры.
— Nexus 2232 Fabric Extender — линейные карты Fabric Interconnect в независимом исполнении. Позволяют использовать ToR-схему подключения серверов, сохраняя компактную кабельную инфраструктуру и не увеличивая количество точек управления. Обеспечивает 32 x 10GbE порта для подключения серверов и 8 x 10GbE портов для подключения к Fabric Interconnect.
— UCS C240 — двухъюнитовые серверы в стоечном исполнении
— Cisco VIC — сетевые адаптеры, обеспечивающие два порта 10GbE, поддерживающие аппаратную виртуализацию
Каждый сервер одновременно подключается к двум модулям Fabric Interconnect, как показано на Рисунке 6. Активным является только один путь, второй нужен для отказоустойчивости. В случае проблем произойдет автоматическое переключение на резервный путь, при этом mac-адрес сервера останется без изменений. Данная функция носит название Fabric Failover, является частью UCS и не требует каких-либо настроек со стороны операционной системы.
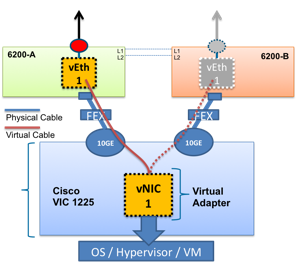
Рисунок 6. Схема подключения сетевого адаптера к Fabric Interconnect
UCS дает возможность гибко управлять распределением трафика между FI. В описываемой архитектуре на сетевом адаптере сервера создается три виртуальных интерфейса, каждый из которых помещается в отдельный VLAN: vNIC0 — для доступа системного администратора к узлу, vNIC1 — для информации, которой обмениваются узлы внутри кластера, vNIC2 — для остальных типов трафика. Для vNIC1 и vNIC2 включается поддержка фреймов большого размера. В штатном режиме каждый из интерфейсов использует тот FI, который был выбран основным при настройке сетевого адаптера. В данном примере весь трафик vNIC1 будет коммутироваться на FI-A, а трафик vNIC2 — на FI-B (Рисунок 7). В случае выхода из строя одного из FI, весь трафик автоматически переключится на второй.
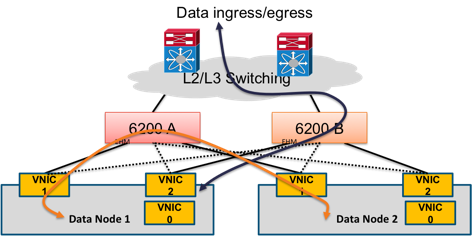
Рисунок 7. Распределение различных типов трафика в системе
В решении используется два модуля Fabric Interconnect для резервирования системы управления и коммутации. В каждый серверный шкаф рекомендуется ставить 16 серверов и 2 модуля Fabric Extender.

Рисунок 8. Масштабирование Hadoop-кластера на базе оборудования Cisco
Масштабирование Hadoop-кластера осуществляется путем добавления большего количества серверов и линейных карт Nexus 2232. Автоматическая инсталляция и настройка новых узлов может выполняться с помощью программного продукта Cisco UCS Director Express, но это уже совсем другая история.
Приобрести продукцию Cisco или узнать информацию о ценах можно у партнеров Cisco в Украине и в России.
Они помогут подобрать и реализовать лучшее решение для вашего бизнеса.
Основы Hadoop
Для понимания принципа работы Hadoop необходимо разобраться с функциями двух основных компонентов: HDFS (Hadoop File System) и MapReduce, которые будут рассмотрены в данной статье подробнее. Другие возможные составляющие системы показаны на Рисунке 1.
Рисунок 1. Экосистема Hadoop
HDFS — глобальная файловая система, распределенная через кластер, которая обеспечивает хранение данных. Файлы разбиваются на большие блоки, как правило, 64, 128 или 512 Мб, после чего они записываются на разные узлы кластера. Таким образом, на HDFS могут быть размещены файлы любого размера, даже превышающие объем хранилища одного сервера. Каждый записанный блок еще минимум дважды реплицируется на другие узлы. С одной стороны, репликация обеспечивает отказоустойчивость. С другой — возможность локальной обработки данных без нагрузки на сетевую инфраструктуру. Объем дискового пространства кластера при стандартном коэффициенте репликации должен быть в три раза больше, чем информация, которую требуется сохранить. Также необходимо иметь дополнительно 25–30% вне HDFS для хранения промежуточных данных, возникающих в процессе обработки. То есть на 1 Тб «полезной информации» нужно 4 Тб «сырого пространства».
MapReduce — система для распределения задачи обработки данных между узлами Hadoop-кластера. Этот процесс, как ни странно, состоит из двух стадий: Map и Reduce. Map запускается одновременно на многих узлах и выдает промежуточную информацию, обрабатываемую Reduce для предоставления конечного результата.
Приведу упрощенный пример, который поможет лучше понять происходящее. Представьте, что вам необходимо посчитать число повторений слов в газете. Вы будете записывать каждое слово и ставить галочку напротив, когда оно снова встретится в тексте. Этот процесс займет очень много времени, особенно если вы собьетесь и придется начинать все заново. Гораздо проще будет разделить газету на небольшие части и раздать их друзьям и знакомым с просьбой выполнить подсчет. Таким образом, задача будет распределена и каждый предоставит вам некоторый промежуточный результат. Поскольку данные уже прошли предварительную сортировку, то ваша задача будет очень простой — просуммировать полученную информацию. Выражаясь терминами Hadoop, ваши друзья выполнят стадию Map, а вы — Reduce. К слову, промежуточные данные носят название Shuffle, а кусочки газеты — Chunk.
Наилучшим считается вариант, когда процесс Мap работает с информацией на локальном диске. Если такой возможности нет по причине высокой утилизации узла, то задача будет передана другой ноде, которая предварительно скопирует данные, чем увеличит нагрузку на сеть. Если бы на HDFS хранилась только одна копия информации, то случаи удаленной обработки были бы частыми. По умолчанию HDFS создает три копии данных на разных узлах, и это хороший коэффициент для обеспечения отказоустойчивости и локальных вычислений.
Существует два типа узлов: SlaveNodes и MasterNodes. Узлы SlaveNode непосредственно записывают и обрабатывают информацию, запускают демоны DataNode и TaskTracker. MasterNodes выступают управляющими, они хранят метаданные файловой системы и обеспечивают распределение блоков на HDFS (NameNode), а также координируют MapReduce с помощью демона Job Tracker. Каждый демон запускается на своей собственной Java Virtual Machine (JVM).
Рассмотрим процесс записи на HDFS файла, разбитого на два блока (Рисунок 2). Клиент обращается к NameNode(NN) с запросом, на какие DataNode (DN) эти блоки должны быть помещены. NameNode дает инструкцию поместить Block1 на DN1. Кроме того, NameNode командует DN1 выполнить репликацию Block1 на DN2, а DN2 — на DN6. Аналогичным образом Block2 помещается на узлы DN2, DN5 и DN6. Каждый DN с периодичностью в несколько секунд отправляет NN отчет об имеющихся блоках. Если отчет не приходит, то DN считается потерянным, а это означает, что на одну реплику определенных блоков стало меньше. NN инициирует их восстановление на других DN. Если через некоторое время пропавший DN появится вновь, то NN выберет DN, с которых будут удалены лишние копии данных.
Рисунок 2. Процесс записи на HDFS
Эквивалентен NameNode по важности демон JobTracker, управляющий распределенной обработкой данных. Если вы хотите запустить программу на всем кластере, то она отправляется MasterNode с демоном JobTracker. JobTracker определяет, какие блоки данных нужны, и выбирает узлы, где стадия Мap может быть выполнена локально; кроме того, выбираются узлы для Reduce. Со стороны SlaveNode процесс взаимодействия с JobTracker выполняется демоном TaskTracker. Он сообщает JobTracker статус выполнения задачи. Если задача не осуществлена по причине ошибки или слишком длительного времени исполнения, то JobTracker передаст ее другому узлу. Частое невыполнение задачи узлом ведет к тому, что он будет помещен в черный список.
Рисунок 3. Процесс обработки данных MapReduce
Таким образом, для сетевой инфраструктуры Hadoop-кластер производит несколько типов трафика:
— Heartbeats — служебная информация между MasterNodes и SlaveNodes, с помощью которой определяются доступность узлов, статус исполнения задач, отправляются команды на репликацию или удаление блоков и т. д. Нагрузка Heartbeats на сеть минимальна, и эти пакеты не должны теряться, так как от них зависит стабильность работы кластера.
— Shuffle — данные, которые передаются после выполнения стадии Мар на Reduce. Природа трафика — от многих к одному, генерирует среднюю нагрузку на сеть.
— Запись на HDFS — запись и репликация больших объемов данных большими блоками. Высокая нагрузка на сеть.
Особенности построения инфраструктуры для Hadoop
Интересно наблюдать за тем, как эволюционируют вычислительные ресурсы, используемые под Hadoop. В 2009 году конфигурация типового узла, сбалансированного по ресурсам, представляла собой одноюнитовый двухсокетный сервер с четырьмя жесткими дисками, двухъядерными процессорами и 24 гигабайтами оперативной памяти, подключенный к гигабитной Ethernet-сети. Что изменилось за пять лет? Сменилось четыре поколения процессоров — они стали мощнее, поддерживают больше ядер и памяти, а 10-тигигабитная сеть широко используется в центрах обработки данных. И только жесткие диски не поменялись. Чтобы оптимально утилизировать доступные процессоры и память, современные кластеры строятся на базе двухъюнитовых серверов, куда можно поставить большое количество дисков. Число возможных операций с файловой подсистемой, в свою очередь, определяет потребности узлов в пропускной способности сети. На Рисунке 4 приведены данные для серверов различной конфигурации, откуда следует, что при построении системы лучше ориентироваться на скоростной 10GbE, так как узлы потенциально могут обрабатывать более 1 Гб/с.
Рисунок 4. Производительность подсистемы ввода/вывода в зависимости от количества жестких дисков
Требования к объему локальной системы хранения также определяют тот факт, что для Hadoop не используются серверы в блейдовом исполнении, где возможности по установке локальных дисков крайне ограничены. Также стоит отметить, что для SlaveNodes не используют виртуализацию и диски не собирают в RAID.
Cisco Common Platform Architecture
Компания Cisco имеет полный набор продуктов для построения аппаратной платформы под Hadoop. Это серверы, сетевые устройства, системы управления и автоматизации. На базе Cisco UCS и Nexus была создана и протестирована архитектура для работы с большими объемами данных, которая носит название CPA (Common Platform Architecture). В данном разделе статьи будут описаны особенности сетевого дизайна, используемого в решении.
Рисунок 5. Компоненты Common Platform Architecture
Решение строится на следующем наборе оборудования:
— Fabric Interconnect 6200 (FI) — высокоскоростные неблокируемые универсальные коммутаторы со встроенной графической системой управления (UCSM) всеми компонентами подключаемой серверной инфраструктуры.
— Nexus 2232 Fabric Extender — линейные карты Fabric Interconnect в независимом исполнении. Позволяют использовать ToR-схему подключения серверов, сохраняя компактную кабельную инфраструктуру и не увеличивая количество точек управления. Обеспечивает 32 x 10GbE порта для подключения серверов и 8 x 10GbE портов для подключения к Fabric Interconnect.
— UCS C240 — двухъюнитовые серверы в стоечном исполнении
— Cisco VIC — сетевые адаптеры, обеспечивающие два порта 10GbE, поддерживающие аппаратную виртуализацию
Каждый сервер одновременно подключается к двум модулям Fabric Interconnect, как показано на Рисунке 6. Активным является только один путь, второй нужен для отказоустойчивости. В случае проблем произойдет автоматическое переключение на резервный путь, при этом mac-адрес сервера останется без изменений. Данная функция носит название Fabric Failover, является частью UCS и не требует каких-либо настроек со стороны операционной системы.
Рисунок 6. Схема подключения сетевого адаптера к Fabric Interconnect
UCS дает возможность гибко управлять распределением трафика между FI. В описываемой архитектуре на сетевом адаптере сервера создается три виртуальных интерфейса, каждый из которых помещается в отдельный VLAN: vNIC0 — для доступа системного администратора к узлу, vNIC1 — для информации, которой обмениваются узлы внутри кластера, vNIC2 — для остальных типов трафика. Для vNIC1 и vNIC2 включается поддержка фреймов большого размера. В штатном режиме каждый из интерфейсов использует тот FI, который был выбран основным при настройке сетевого адаптера. В данном примере весь трафик vNIC1 будет коммутироваться на FI-A, а трафик vNIC2 — на FI-B (Рисунок 7). В случае выхода из строя одного из FI, весь трафик автоматически переключится на второй.
Рисунок 7. Распределение различных типов трафика в системе
В решении используется два модуля Fabric Interconnect для резервирования системы управления и коммутации. В каждый серверный шкаф рекомендуется ставить 16 серверов и 2 модуля Fabric Extender.
Рисунок 8. Масштабирование Hadoop-кластера на базе оборудования Cisco
Масштабирование Hadoop-кластера осуществляется путем добавления большего количества серверов и линейных карт Nexus 2232. Автоматическая инсталляция и настройка новых узлов может выполняться с помощью программного продукта Cisco UCS Director Express, но это уже совсем другая история.
Приобрести продукцию Cisco или узнать информацию о ценах можно у партнеров Cisco в Украине и в России.
Они помогут подобрать и реализовать лучшее решение для вашего бизнеса.
