
Вы когда-нибудь собирали театральные программки? Если да, то, наверное, в вашей коллекции их десятки, а может, наберется и сотня. А теперь представьте, что в вашем распоряжении 120 тысяч программок, 48 тысяч афиш и 100 тысяч исторических фотографий. Столько бумажных документов сохранил с середины XIX века Большой театр. Самые древние и ценные из них уже пожелтели и стали ветхими, а на поиск информации в театральном архиве уходили часы. Чтобы сохранить эти сокровища, сотрудники театрального музея начали вручную переводить документы в электронный вид, но оказалось, что на это могут уйти годы.
Поэтому в сентябре 2016 года вместе с Большим театром и при активной поддержке Феклы Толстой, праправнучки Льва Николаевича Толстого, мы запустили краудсорсинговый проект по оцифровке истории главного театра страны. В этом посте мы расскажем о подробностях первого этапа проекта и о его технических деталях: как мы оцифровывали уникальные документы с помощью ABBYY FineReader и как волонтеры помогали проверять результаты распознавания.
Немного истории
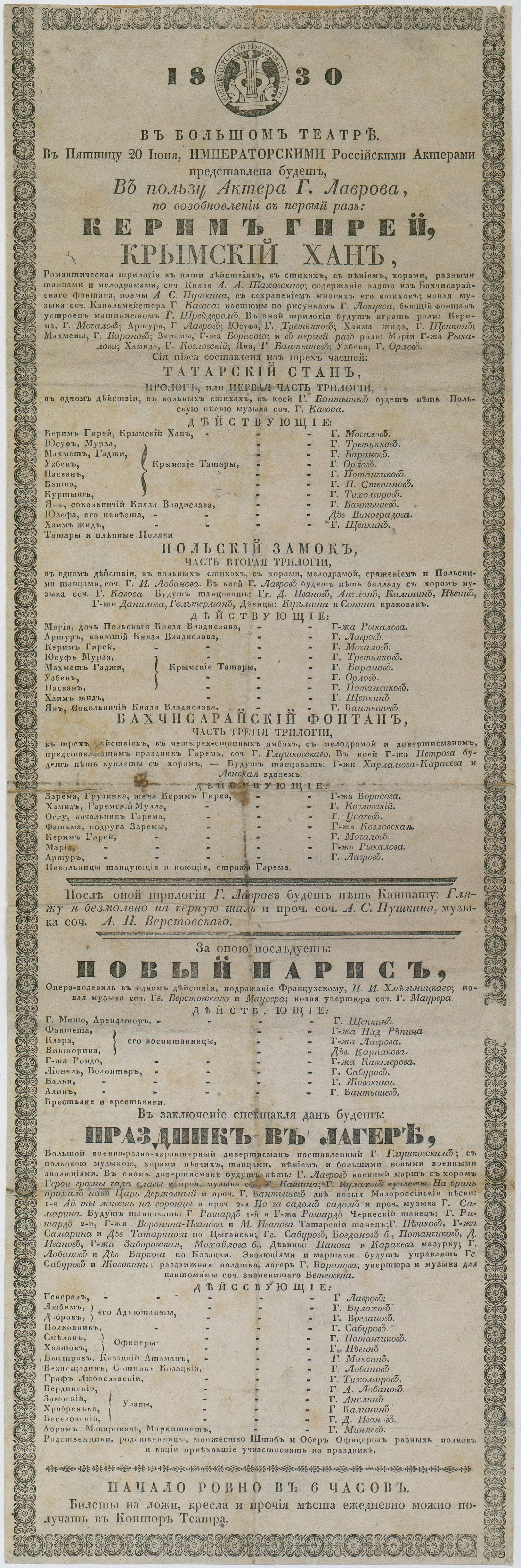
Большой театр основала императрица Екатерина II 28 марта 1776 года. В зданиях, где располагался театр, не раз происходили пожары, самый крупный – в 1853 году. Огонь полыхал три дня, и в нем сгорела значительная часть исторического наследия Большого. Самый старинный театральный документ, который уцелел с тех пор, – афиша 1830 года. Все остальные афиши и программки сохранились только с 1858 года.
Афиша Большого театра, 1830 год. Кликайте на картинку, чтобы рассмотреть подробнее
Музей Большого театра хотел не только сохранить ценнейший архив, оцифровав его, но и сделать информацию о постановках, действующих лицах, режиссерах, хореографах и многих других доступной каждому. Если бы сотрудники Большого театра вручную перепечатывали данные из программок и афиш, это заняло бы несколько десятков лет. Тогда театр решил призвать на помощь интеллектуальные технологии и волонтеров. Инициатором волонтерского проекта «Открой историю Большого» стала Фекла Толстая. С ней мы уже сотрудничали в проекте «Весь Толстой в один клик». Тогда, в 2014 году, с помощью ABBYY Recognition Server и ABBYY FineReader и при участии 3 тысяч волонтеров мы оцифровали 46 тысяч страниц 90-томного собрания сочинений Льва Николаевича Толстого. Теперь все книги в электронном виде доступны на официальном портале tolstoy.ru. Подробнее о самом проекте можно почитать здесь.
В проекте «Открой историю Большого» перед нами стоит задача не только оцифровать коллекцию документов, но и извлечь из них ценную информацию для создания электронного архива.
Поэтому проект делится на три этапа:

- Вначале мы сканировали документы и распознавали их программой ABBYY FineReader. Затем волонтеры помогали проверять результаты распознавания, чтобы исключить ошибки, возможные при оцифровке.
- Второй этап стартовал в июне 2017 года и еще продолжается. Его задача – извлечь и упорядочить данные из уже оцифрованной коллекции программок и афиш. Интеллектуальная технология понимания и анализа текстов на естественном языке ABBYY Compreno анализирует текст документов, а затем извлекает ценную информацию в поля базы данных, по которым данные в дальнейшем можно будет быстро найти в электронном архиве. Сейчас волонтеры проверяют итоги работы искусственного интеллекта. В результате информация будет загружена в музейную базу данных, разработанную компанией КАМИС, и наследие Большого театра станет доступно каждому.
- На третьем этапе проекта волонтеры займутся рубрикацией 100 тысяч исторических фотографий из архива музея Большого театра.
Официально проект был запущен в октябре 2016 года, когда волонтеры начали проверять оцифрованные тексты программ и афиш. Но подготовку к старту мы начали чуть раньше.
Жаркий август 2016
В августе 2016 команда сканировщиков приехала в Большой театр. Они 7 месяцев сканировали десятки тысяч программок и фотографий из фондов музея Большого театра. Афиши сканировать не пришлось, так как музей уже сделал это сам.
Дружная команда сканеровщиков. Слева направо: Николай Алтунин, Ирина Андрюхина, Дмитрий Нестеров.

Наш партнер, компания Fujitsu, предоставила для проекта два планшетных сканера Fujitsu fi-6770 и Fujitsu fi-6750S и два бесконтактных сканера Fujitsu ScanSnap SV600.
Планшетники помогли нам оцифровать программки, которые были собраны в подшивки и плотно сброшюрированы. На них мы также сканировали фотографии с двух сторон. На обороте снимков содержится ценная информация: название постановок, имена артистов и фотографов.

Бесконтактные ScanSnap SV600 помогли нам оцифровывать крупноформатные и ветхие программки. С ними нужно было обращаться очень бережно.

Подробнее посмотреть, как шел этап оцифровки, можно в галерее.
В результате сканирования мы получили файлы c фотографиями в формате TIFF с разрешением 600 dpi, а также программы в формате JPEG c разрешением 300 dpi.
Распознать и извлечь
Мы разделили все отсканированные документы на небольшие части – «пакеты», чтобы работа не была сложной для участников. Один пакет – это одна программка либо афиша. В программках бывает и по одному листу, и по 30, в среднем — по четыре листа. Пакеты мы разделили по годам и пронумеровали.
Затем нужно было распознать отсканированные документы и создать файлы PDF с текстовым слоем. Зачем нужен текстовый слой? Чтобы сотрудники музея могли не только просматривать оцифрованные афиши и программы, но и искать и копировать информацию. FineReader автоматически распознавал сканы и размечал на них области: текст выделял зеленым, изображения – красным, а таблицы – фиолетовым.

В табличном формате в афишах и программках представлены списки действующих лиц:

Каждый участник первого этапа проекта регистрировался на сайте openbolshoi.ru. Затем заходил в личный кабинет, читал подробную инструкцию, устанавливал бесплатную версию FineReader, скачивал пакет (документ FineReader, заархивированный в формате zip) и приступал к проверке. Волонтеры смотрели на правильность разметки областей, вычитывали текст и исправляли неточности распознавания, возможные при оцифровке.
Участников этого этапа мы назвали верификаторами. Они проверяли программки и афиши с октября 2016 по июнь 2017 года, начав с настоящего времени и постепенно продвигаясь к XIX веку.
Вкратце о том, как делали сайт проекта, можно прочитать под спойлером.
Краудсорсинговая платформа
Краудсорсинговая платформа
Сайт openbolshoi.ru – это платформа для совместной работы волонтеров. Она создана под управлением CMS «1C-Битрикс» в связке с СУБД – MySQL. Язык программирования – PHP. Для создания хранилища программок и афиш использовался Amazon S3, для версионного контроля – система GIT. После подготовки ТЗ проект был технически реализован всего за один месяц.
Составляющие платформы:
1. Публичная часть (доступна всем пользователям, содержит информацию о проекте).
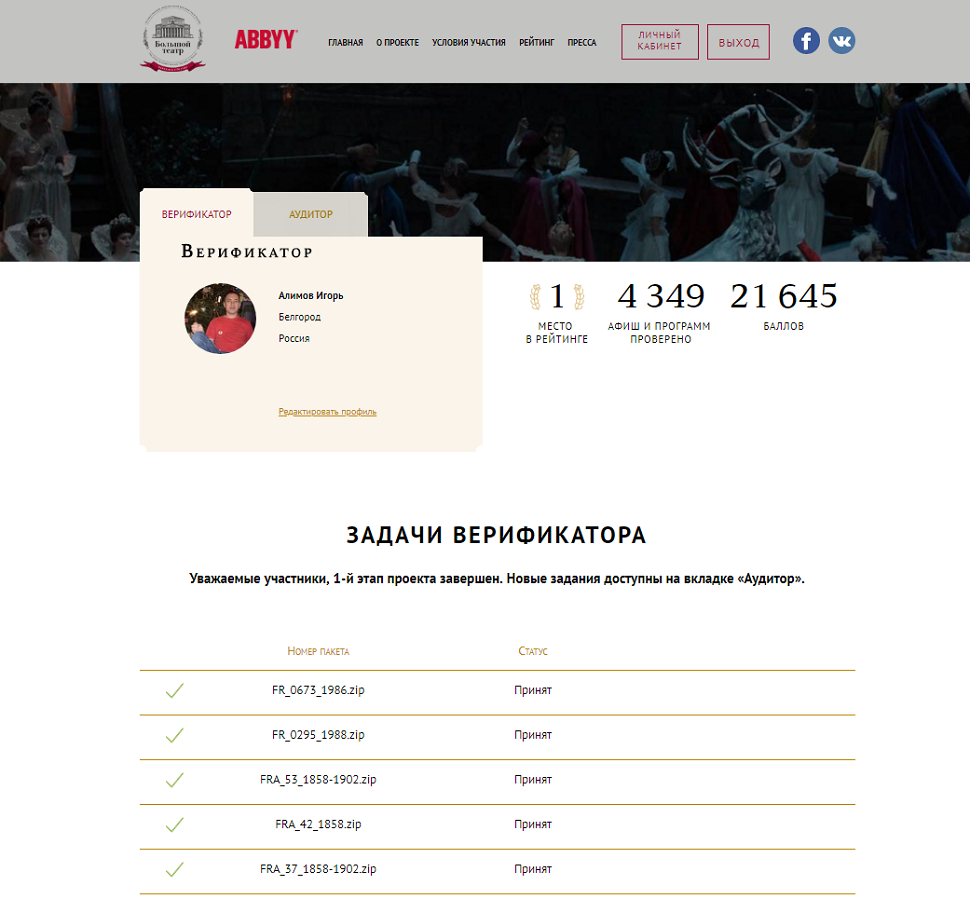
2. Личный кабинет участника (доступен зарегистрированным пользователям и предназначен для проверки пакетов и персональной информации). В личном кабинете волонтеры видели количество пакетов, которые были у них приняты, место в рейтинге и начисленные баллы.
3. Личный кабинет администратора (доступен только администраторам платформы, предназначен для проверки работы волонтеров).
4. Административная часть платформы (доступна только администраторам CMS и нужна для глобального управления платформой).
5. Файловое хранилище Amazon (предназначено для хранения пакетов).
Сайт openbolshoi.ru – это платформа для совместной работы волонтеров. Она создана под управлением CMS «1C-Битрикс» в связке с СУБД – MySQL. Язык программирования – PHP. Для создания хранилища программок и афиш использовался Amazon S3, для версионного контроля – система GIT. После подготовки ТЗ проект был технически реализован всего за один месяц.
Составляющие платформы:
1. Публичная часть (доступна всем пользователям, содержит информацию о проекте).
2. Личный кабинет участника (доступен зарегистрированным пользователям и предназначен для проверки пакетов и персональной информации). В личном кабинете волонтеры видели количество пакетов, которые были у них приняты, место в рейтинге и начисленные баллы.
3. Личный кабинет администратора (доступен только администраторам платформы, предназначен для проверки работы волонтеров).
4. Административная часть платформы (доступна только администраторам CMS и нужна для глобального управления платформой).
5. Файловое хранилище Amazon (предназначено для хранения пакетов).
Успеть за 48 часов
Каждому волонтеру давалось 48 часов на проверку одного пакета. Если за это время человек не успевал проверить документ, то файл снова попадал в общую выдачу. И уже другой волонтер мог взять его на проверку. Если участник проверял пакет внимательно и в срок, то пакет принимали и начисляли волонтеру 5 баллов. Если участник недобросовестно проверил документ, то такой пакет не принимался, а волонтер терял 10 баллов.
Трудности перевода
Проверка афиш оказалась сложнее вычитки программок. В старинных афишах и программах из-за мелкого и размытого текста, сложной верстки и качества печати символы не всегда правильно распознавались.
Например, на проверку этой большой, сложной афиши 1936 года с мелким шрифтом волонтер потратил целый день. Каждую третью фамилию приходилось искать в интернете:

А на этой афише плохо видна подпись снизу:

Часто волонтерам попадались старые, оборванные афиши, часть информации из которых приходилось вводить вручную. На этой афише 1883 года волонтер распознавал только заголовок и первые два столбца, потому что часть документа не сохранилась:

Хотя FineReader и знает старорусский язык, участникам было непривычно проверять дореволюционные афиши и программки с их нетипичным стилем изложения и давно забытыми буквами «i», «ѣ», «ѳ» и др. Тем не менее, волонтеры успешно справились с этой задачей и с юмором писали в комментариях: «После проверки афиш 18** годов руки так и тянутся вместо «действиях» писать «дѣйствiяхъ»...».
На фото – программа 1910 года:

Техподдержка на связи
Оргкомитет проекта круглосуточно отвечал на вопросы волонтеров по электронной почте, в соцсетях и по телефону. В группе «ВКонтакте» волонтеры задавали много вопросов и активно помогали другу другу. Выглядело это вот так:

Участники также делились интересными подробностями и необычными фактами, найденными в уникальных документах.

Под спойлером мы собрали другие находки волонтеров.
Самая маленькая афиша, забытые в театре вещи и 40 дам в костюмах дебардеров


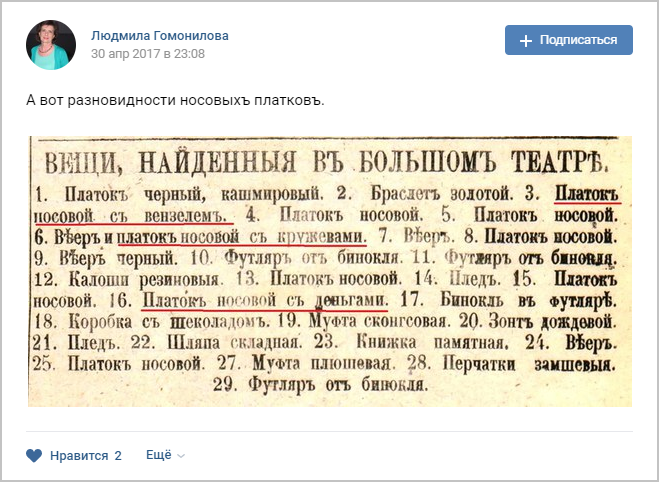

Выигрышный билет
Как Вы помните, за каждый проверенный пакет Оргкомитет начислял баллы. Так формировался рейтинг волонтеров. Пятерка самых активных участников получила призы — билеты в Большой театр. Первое место занял Игорь Алимов из Белгорода, он проверил 4 349 пакетов. В пятерку победителей также вошли Галина Зарина из Москвы, Александр Аксенов из Санкт-Петербурга, Наталья Клементьева из Москвы и Лариса Огородникова из Екатеринбурга. Они выбрали интересные им постановки и посетили спектакли «Дон Кихот», «Щелкунчик», «Снегурочка», «Иоланта» и премьеру балета «Ромео и Джульетта».

Отзывы других победителей первого этапа проекта можно прочитать тут и тут.
Кроме того, первая десятка активных волонтеров получила в подарок ABBYY FineReader. А участники, которые проверили хотя бы один пакет, получили специальные дипломы:

Немного статистики
В первом этапе проекта участвовали 4 тысячи волонтеров из 60 стран: США, Австралии, Бразилии, Индии, Китая, Казахстана, Монголии, многих стран Европы и, конечно же, России.

ТОП-10 городов, в которых живет большинство волонтеров:
- Москва,
- Санкт-Петербург,
- Калининград,
- Челябинск,
- Новосибирск,
- Екатеринбург,
- Пермь,
- Самара,
- Омск,
- Воронеж.
В проекте участвовали программисты, ИТ-специалисты, учителя, музыканты, фотографы, журналисты, руководители компаний, историки, пенсионеры, студенты, художники, домохозяйки, артисты и люди многих других профессий.

Благодаря волонтерам оцифровать и проверить все программы и афиши удалось всего за 9 месяцев. В Музей Большого театра уже переданы программки и афиши в форматах JPEG и PDF с текстовым слоем, а также фотографии в формате TIFF.

Сейчас продолжается второй этап проекта, в котором участвуют уже 6 450 волонтеров. Они помогают извлечь и упорядочить данные из оцифрованных документов. На этом этапе задействован целый комплекс технологий ABBYY – от ABBYY Compreno до ABBYY FlexiCapture, а волонтеры помогают проверить работу искусственного интеллекта. Подробнее о том, как это работает, мы рассказываем во второй части поста. А пока вы тоже можете стать участником волонтерского проекта «Открой историю Большого». Присоединяйтесь!
Елизавета Титаренко, редактор корпоративного блога ABBYY,
Марина Антропова, ведущий менеджер по специальным проектам ABBYY
