Suppose you are woken up at night and asked about message brokers: What are they, what types are available and what's the difference? Or imagine you face this question at a job interview, or maybe you just want to show your colleagues that you are in the know. So then, buckle in, take a deep breath and rattle off the following.
What are the types of communication?
Let’s take a closer look at what types of communication there are. The most common one is dialogue. N talks to Y and sounds off on a subject, waiting for a response or feedback.
The illustration is phone conversations:

Another type is all of the above, except N conveys the message to Y and does not require a response. Yes, there are indeed people who are in the habit of voicing their opinions just for the sake of it. Email marketing or push notifications on your phone follow the same pattern too.
Public address systems:

There are also types of mediated communication. For example, N asks X to memorise the message and pass it on to their friends. The caveat is that N does not know who exactly X’s friends are. X passes the message on to all of their friends: C, D and E.
A good example of this is a messaging app. The sender posts messages to specific groups and users join such groups and read these messages.

In a similar scenario, N writes a message on a card and gives it to X. X puts the cards in a special box. Those with access peek into the box one at a time, taking one message each. One message, one recipient.

Information Exchange Patterns
In the computer world, most apps and services often do not work on their own, but interact, exchanging data with each other. Without communication, user tasks simply would not be performed.
There are different ways of exchanging information and their classification gives rise to patterns. Four basic patterns of communication in simple terms were listed above and the same patterns are inherent in programs:
Request-Response;
One-Way or Fire and Forget;
Publish-Subscribe, or Pub-Sub;
Point-to-Point.
On the internet, Request-Response is an HTTP operation: the client sends a request to the server, waits for and receives a response. One-Way is when an app sends a UDP (User Datagram Protocol) packet over the network to the server without waiting for a response. These two scenarios are related to message brokers, but for more details on them, read on.
Often, as part of their interaction, apps use the Request-Response pattern. Programs communicate with each other directly and in sync. Such interaction has the following features:
The sender needs to know the recipient’s address;
The recipient must be available at the time of the call;
The sender may wait for and never receive a response if some failure occurs;
The sender is blocked while waiting for a response.
With the development of technology, micro-service architecture, IoT and the overall increase in the number of programs, the synchronous approach to app communication no longer fits the bill. New solutions are required.
Pub-Sub and Point-to-Point patterns involve asynchronous communication that is brokered. When such patterns are implemented, the programs can:
Perform asynchronous data exchange (the sender is not blocked);
Separate the sender from the recipient (the sender knows nothing about the recipient);
Perform delayed message processing. The recipient does not need to be constantly active – messages can be read at a convenient time;
Delegate responsibility for routing and delivery of messages to a third party;
Integrate smoothly with systems using different platforms, languages and communication protocols.
Anyway, what do brokers stand for?
In the pictures above, the letter X means a message broker.

A message broker is a software system that either fully or partially implements Pub-Sub and Point-to-Point patterns. Interaction of programs through the broker simplifies the development process. There is no need to implement mechanisms of message delivery, routing and storage in each service – all of this is done by a 'broker'. 'Brokered' communication helps to order and lend clarity to data flows, thus simplifying development and reducing the likelihood of errors.

Using a broker is the go-to option if:
There are tasks that require plenty of time and resources;
There is no need for immediate results;
Performance of many services has to be coordinated (an event-based communication model);
It is necessary to boost the scalability and fault tolerance of the system.
Delivery Guarantee
A broker assumes the responsibility
for delivering messages to recipients. At the same time, there may be failures
in the data chain, resulting in a loss of data. Types of delivery guarantees
are defined based on the system behaviour when failures occur:
At most once
The easiest option is to send the Fire and Forget type of messages. Most messages are delivered to the recipient, but some are lost to failures.

At least once
For all the data to reach the destination, resending may be required. At least one attempt will be successful. In this case, the messages are not lost but may be duplicated.
This is typically implemented through the ACK (acknowledgement) mechanism. The message is resent if no delivery acknowledgement has been received. Duplicates are possible if the acknowledgement has been lost or not sent due to a failure.

Exactly once
The most challenging option in terms of feasibility is the maximum delivery guarantee. Messages are never lost or duplicated; each is delivered exactly once.

Queue and Topic
The broker that implements the Point-to-Point pattern is associated with a queue. The sender’s messages hit a queue and the recipient retrieves the messages from the queue. Upon retrieval, the message is no longer available to anyone. The data are stored in the queue until they are read or expire.
Pub-Sub is associated with a topic. Messages go to the topic. The system distributes each message among all the subscribers of the topic (broadcasting). Messages can be stored in the topic as long as it is necessary before the data will be distributed among all the subscribers.
A Diversity of Brokers in Nature
There are many software implementations of message brokers. The best known include:
Each of the implementations may have different features:
scalability, throughput;
fault tolerance, ability to recover data because of a failure;
clustering;
Pub-Sub and Point-to-Point model support;
message delivery guarantee;
streamlined message delivery;
access control;
openness of the code;
supported platforms.
For example, Innotech software solutions actively use Kafka and RabbitMQ message brokers, which have become a de-facto standard. These brokers have certain differences and features in the way they operate. Let's dig deeper to understand the specific operating principles.
'Smart Broker, Dumb Consumer'
RabbitMQ is a conventional open-source message broker that can work both autonomously and as part of a cluster. It supports both Pub-Sub and Point-to-Point models, AMQP, MQTT, STOMP and other protocols. At most once and At least once message delivery guarantees are implemented.
In the case of At most once, throughput is greater, as the data is processed in faster RAM. At least once is reliable when it comes to delivery, but less fast in terms of data transfer since it uses an acknowledgement mechanism and writing to disk.
To give you the basic idea, the RabbitMQ operating principles can be represented as follows: the sender app (publisher) publishes messages to the broker referring to its exchange internal entity. Depending on the type and settings, the exchange forwards messages to one or more queues associated with it. Consumer apps maintain constant TCP connection with RabbitMQ and wait for messages from the specified queue. The broker sends (pushes) and distributes messages among the consumers. If the queue has several consumers, messages are evenly distributed among them. If a message is successfully processed by a consumer, it is removed from the queue.
RabbitMQ can send acknowledgement to the sender after it has saved its message. Or wait for
acknowledgement from the recipient about successful processing of the message
retrieved from the queue.
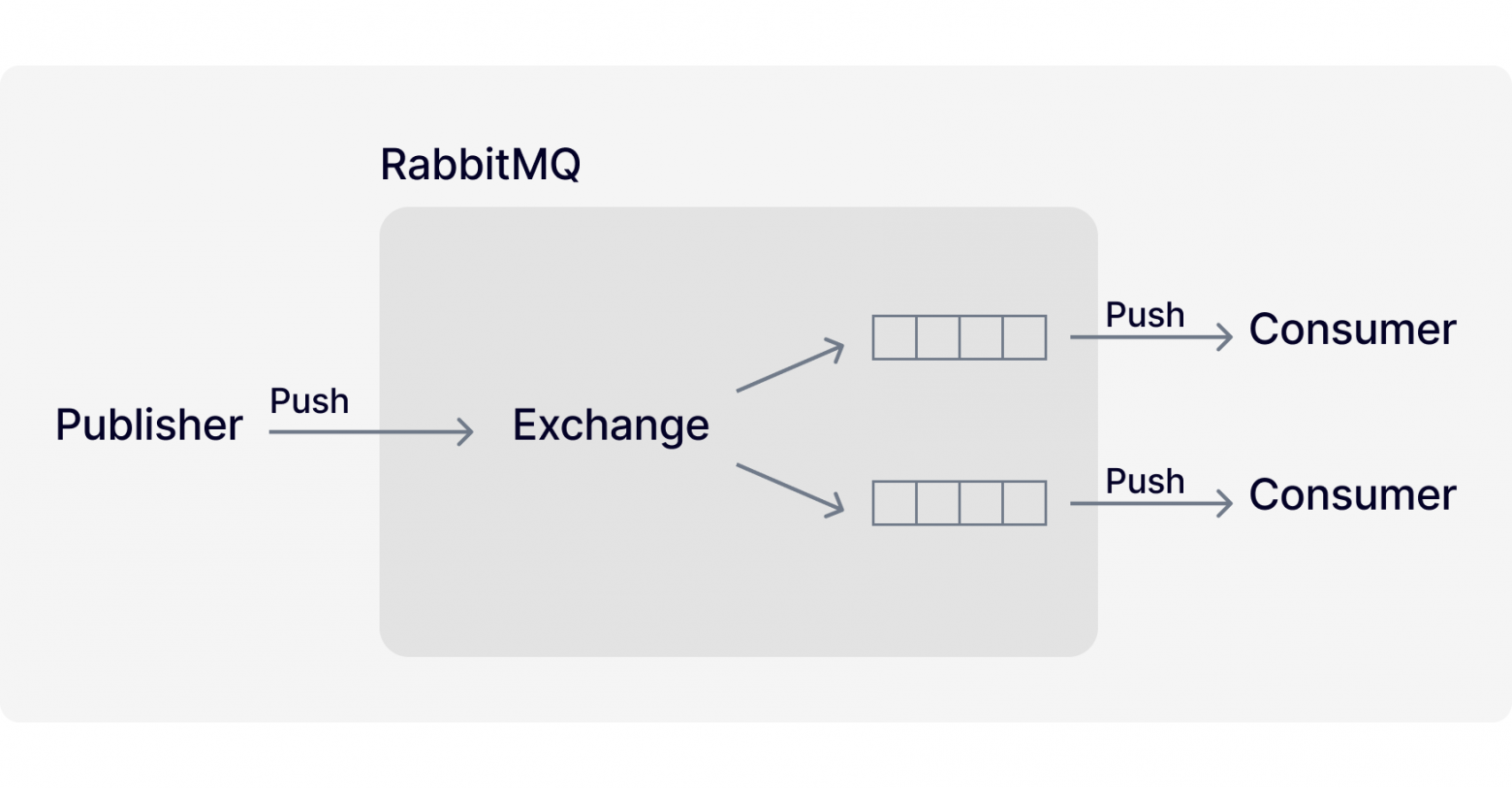
With respect to RabbitMQ, the 'Smart Broker, Dumb Consumer' principle means that the broker takes on a lot of additional actions. For example, it keeps track of read messages and removes them from the queue. Or organises the process of distributing messages among the consumers.
'Dumb Broker, Smart Consumer'
Apache Kafka is an open-source Pub-Sub software broker. On top of At most once and At least once delivery guarantees, it supports Exactly once. It is normally used in large projects thanks to its better throughput and fault tolerance, which make it superior to RabbitMQ and many other brokers. That being said, it has a high threshold of entry and is demanding on resources.
Kafka can be represented as a distributed and replicated commit log. It is distributed, as it is deployed as a cluster of nodes (managed by Apache Zookeeper). It is replicated, as all data are synced among the nodes. It is a log, as incoming messages are consistently added to the log, remain there unchanged and are not deleted once read, as is the case with RabbitMQ.
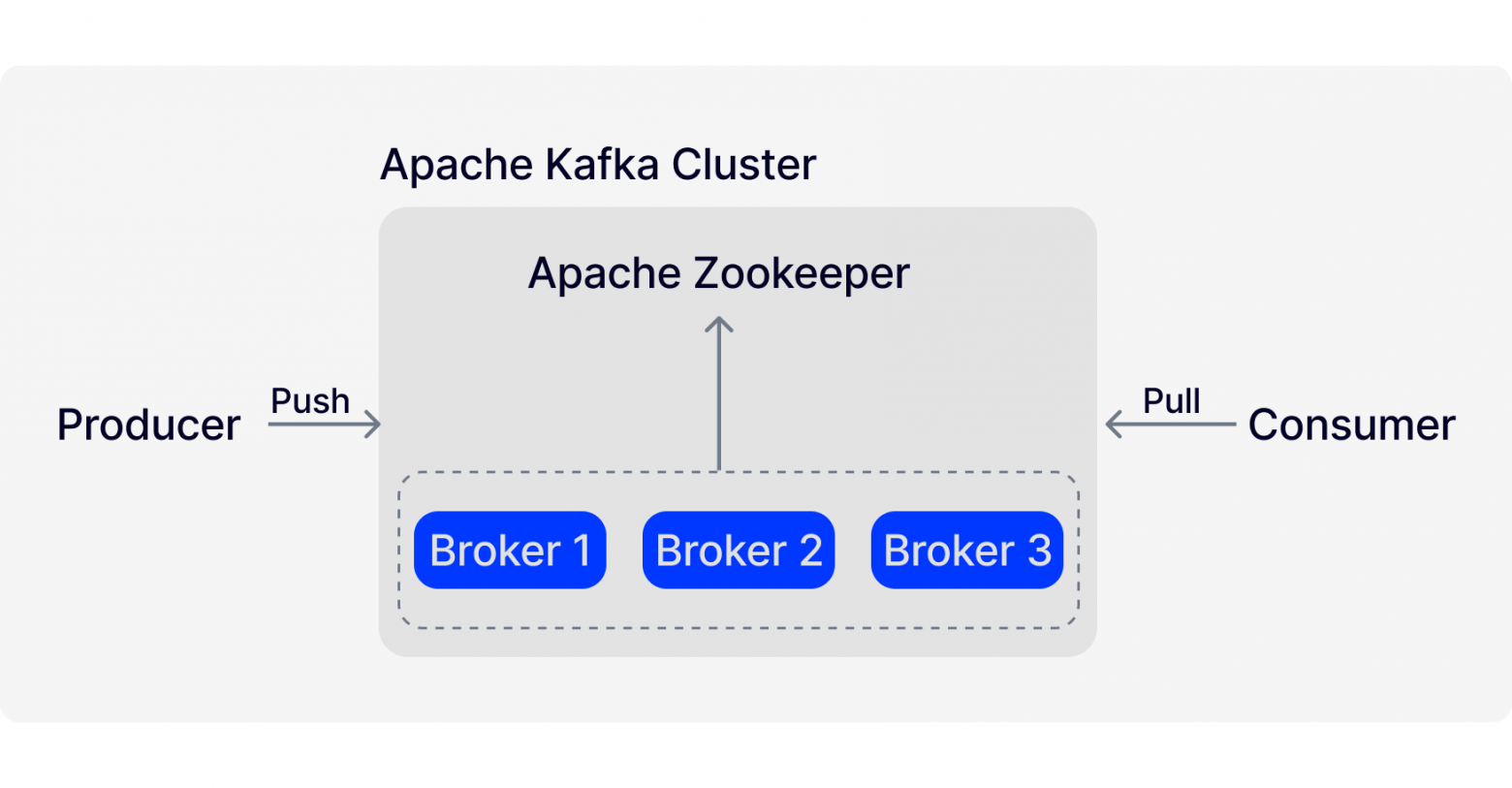
In Kafka, there is no concept of a queue – apps write or read messages from partitioned topics. Simply put, the principle is as follows: the producer app sends a message to the broker’s topic where it is written at the end of one of its partitions. By default, the Round-Robin algorithm is used to distribute messages among the partitions of the topic. The sender can influence the choice of a partition by sending a message key along with the message.
Consumer apps read and pull messages from the specified topic. For each consumer, Kafka remembers the last read offset. If the app fails and then recovers, it can resume reading from the previous location or rewind the offset to the past and read the data again.
For Kafka, the 'Dumb broker, smart consumer' principle means that it does not control or distribute messages, unlike RabbitMQ. Consumers request the broker themselves and decide which messages to read; the broker only stores the data.
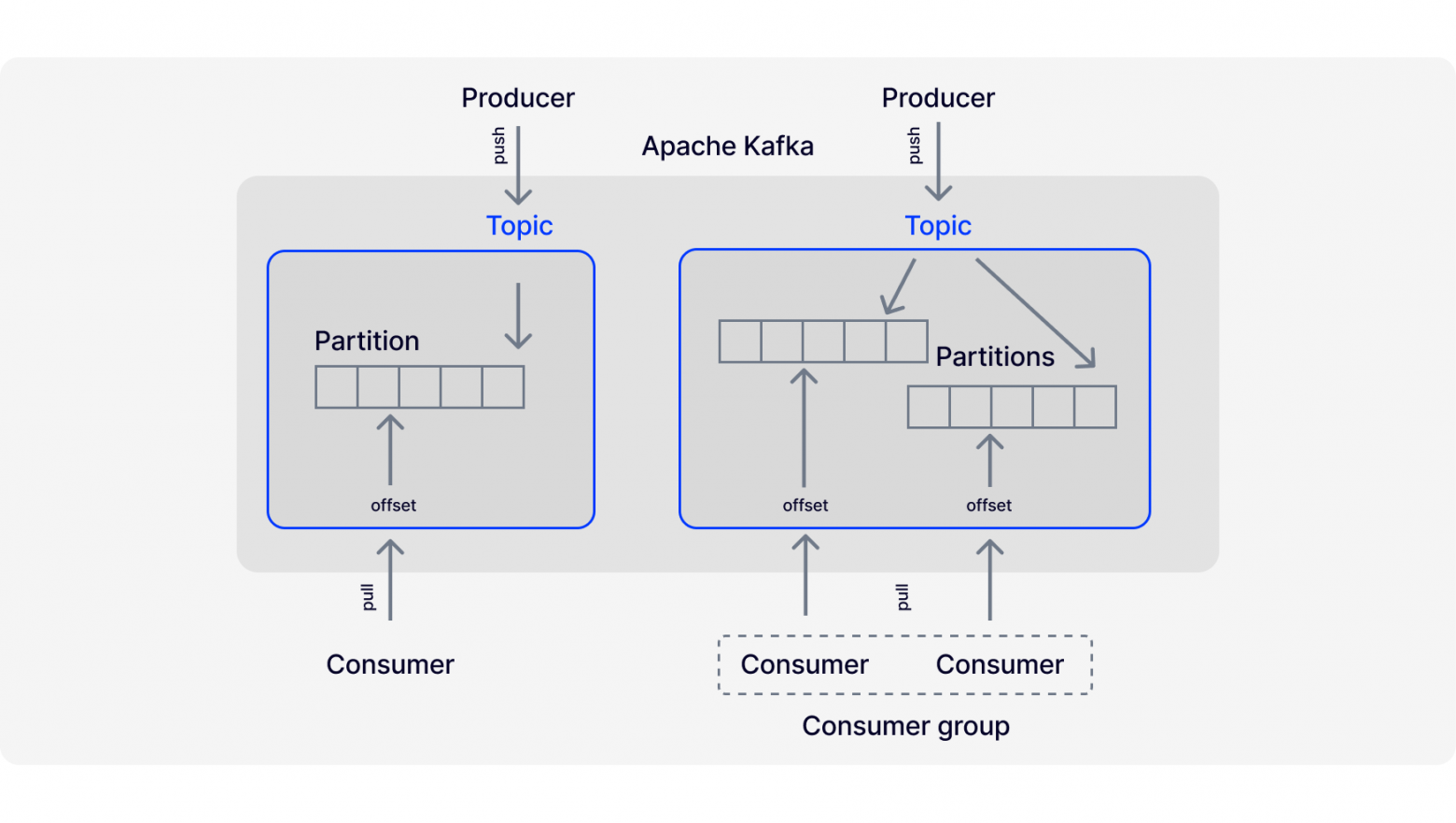
The number of partitions in a topic depends on the number of its competing consumers. One app cannot read data from a single partition in multiple threads. Parallelism is achieved by increasing the number of partitions. There is a single partition for each of the threads.
Such problem does not exist with RabbitMQ. A broker pushes messages to consumers and can therefore balance and distribute data among the consumers in the queue. On the other
hand, a push approach (one message at a time) is less productive compared to a
pull approach in Kafka.
Choosing Between Kafka and RabbitMQ
In fact, it is hard to compare message brokers in broad strokes. They all have their own tasks and areas of application. With Apache Kafka and RabbitMQ, it's a slightly different level where one is not better than the other.
Kafka is used to process large amounts of data, hundreds of thousands of messages per second, which are stored on disk and read many times by hundreds or even thousands of consumers. Kafka is an easily scalable system with higher fault tolerance, which is very important in large projects.
RabbitMQ is easier to install and configure. It successfully handles asynchronous data exchange in a microservice architecture. It does not require additional components and disk resources because all messages are removed from the queue once read. Compared to Kafka, it has more options to configure message exchange patterns. This is an excellent choice if you do not have rigorous fault tolerance and throughput requirements.
