В предыдущей части статьи мы разбирались, как обеспечить поисковым роботам доступ к HTML-коду страницы. С вами снова Александр Усков, я ведущий разработчик more.tv, и в этом посте мы поговорим о том, что именно представляет из себя этот код и что можно сделать, чтобы сделать его максимально «понятным» и содержательным и для поисковых систем, и для браузеров.
Семантика HTML
HTML — язык разметки, который используется для передачи содержимого страниц в Сети и представляет собой определенным образом структурированный текст, состоящий из тегов. Довольно распространенная ошибка новичков в сфере информационных технологий — называть HTML языком программирования, однако язык программирования предполагает наличие некоторой динамичной среды времени выполнения, в которой хранится изменяющееся во времени состояние программы. HTML же статичен, и это и есть состояние, в то время как программой является браузер, который превращает этот код в видимую для нас интерактивную веб-страницу.
Исторически HTML развивался вокруг визуальной составляющей страницы, и значительная часть его спецификации посвящена именно внешнему образу элементов страницы. Однако с распространением и развитием специального языка разметки стилей CSS значимость выбора конкретных тегов существенно снизилась: при помощи стилей и программирования на Javascript можно практически любой элемент заставить выглядеть и вести себя как любой другой элемент. Одновременно с этим выросла потребность в автоматическом анализе (парсинге) веб-страниц, включая и задачи индексации контента в поисковых системах.
В связи с этим было введено понятие «семантичности» используемой разметки, то есть. соответствия используемых HTML-тегов той функции, которую они осуществляют на странице. Например, элемент, который является ссылкой, должен быть задан соответствующим тегом <a>, а изображения, которые должны быть доступны автоматизированным средствам парсинга, желательно вставлять через специализированный тег <img>. При этом теги могут дополнительно иметь обязательные к указанию атрибуты, которые определяют их поведение или эквивалентное содержание, — разработчики стандартов подумали и о людях с ограниченными возможностями, и существует большое количество специальной разметки, например, для автоматических “читалок” страниц или для нетрадиционных средств ввода, таких как голосовое управление или экранная клавиатура. А в последнюю, пятую, (актуальную на текущий момент) версию спецификации HTML были добавлены специальные теги для разметки разных смысловых элементов, которые до той поры каждый реализовал как мог, например, меню навигации или футер (закрепленный в конце каждой страницы сквозной элемент), которые не имеют уникальных свойств отображения, но имеют именно что особое назначение, понятное парсерам. При этом, как минимум в силу обратной совместимости стандартов, абсолютно любую страницу можно реализовать и без оных, определенным образом используя базовые элементы, которые не имеют особой семантики, например, самый часто используемый тег в разметке практически любой страницы, — <div>
Поисковые системы высоко ценят разметку с высоким уровнем семантичности, ведь это позволяет им более точно определить содержимое страницы и, следовательно, включить ее в выдачу по наиболее релевантным запросам, что, как было показано в первой части статьи, является главным приоритетом для ПС. В то время как человекоподобные пользователи браузеров видят конечный результат отображения страницы глазами, и могут из опыта относительно быстро оценить, что является ссылкой, что - текстом, что - картинкой, и какое содержимое те передают, поисковые системы, в основном, полагаются исключительно на разметку и полностью зависят в своем “восприятии” от нее. В последние годы состоялось беспрецедентное развитие систем компьютерного зрения и машинного обучения, но до сих пор нет убедительных данных о том, насколько успешно ПС внедрили их в свои индексирующие системы, и какие факторы являются значимыми для этого средства анализа страниц. Можно надеяться, что в ближайшее время ПС будут еще лучше, чем раньше, выявлять контент и структуру страниц практически любых сайтов, но пока что мы вынуждены, как и 15 лет назад, уделять максимальное внимание именно HTML-коду страниц, которые мы хотим продвинуть в поиске.
Наиболее значимые элементы разметки для SEO — это <h1>, <title> и <meta name=”description>, как минимум потому, что их содержимое попадает в поисковый сниппет в выдаче или при шаринге в соцсетях (если не используется более специфичная разметка, об этом ниже).

Кроме того, исторически считается, что именно в этих элементах ключевые слова, по которым производится оптимизация страницы, имеют наибольший вес для ПС.
Непосредственно на more.tv мы используем не так уж много прочих элементов семантической разметки из стандарта HTML по разным причинам. Главная из них в том, что стандарт преимущественно заточен на текстовый и графический контент, а поддержка стримингового видео, из которого, в основном, и состоит more.tv, появилась в браузерах относительно недавно, по меркам времени жизни стандартов, — хороших средств семантически описать атрибуты видеоконтента в HTML просто нет. Однако, как и всегда в IT-индустрии, там где не хватает одного стандарта, появляются энтузиасты и придумывают новые. Так случилось и в этот раз.
Микроразметка
Поскольку HTML сам по себе является подмножеством XML и (по крайней мере на бумаге) допускает произвольное расширение своей семантики в рамках того же синтаксиса, есть возможность создать определенные комбинации стандартных тегов и атрибутов для семантического описания более сложных сущностей, чем текст или картинка, и, описать такие сущности как «эпизод сериала» или «режиссер фильма». Одна из популярных в интернете инициатив создания такой универсальной разметки — проект Schema.org. В целом это попытка создать спецификацию для структурированного описания вообще всего, что есть во вселенной: верхний объект иерархии в данной схеме так и называется: Thing. При этом все элементы этой разметки невидимы и не влияют непосредственно на отображение.
Нас интересуют более релевантные нашему контенту сущности, такие как персона или фильм. Они позволяют сообщить парсерам структурную информацию о контенте, например, длительность трека или количество сезонов в сериале, что позволяет, в частности, видеоматериалам сайта лучше ранжироваться в специальных видах поиска, например, по видео или по тегам.

В то время как специфические сущности, как правило, описывают всю страницу целиком (одна страница представляет собой что-то одно — один видеотрек, один сезон, один проект и прочее), Schema.org предоставляет эквиваленты разметки для переиспользуемых объектов, включая как стандартные элементы HTML (текст, ссылки, изображения) так и нестандартизованные но широкоиспользуемые компоненты, например, «хлебные крошки». Эту дополнительную разметку можно использовать везде, где это уместно, для повышения доступности контента роботам. Например, это позволяет нивелировать отсутствие тегов <img>, и, в то же время, позволяет сообщить парсеру больше нюансов в правилах отображения картинки, нежели позволяет сам HTML

Разметка этих типов данных поддерживается Google и частично поддерживается Yandex, и, судя по всему, такая нормализация данных внутри самих страниц позволяет продвинутым системам поиска построить семантический граф всего сайта, получив ценную информацию не только о содержимом самих страниц, но и о связях между ними и с другими ресурсами Сети. Вообще, до того, как термин Web3 захватили евангелисты криптовалют, отдельные представители консорциума выдвигали предположение, что следующий скачкообразный этап развития интернета (по сравнению с Web 2.0) сделает его именно «семантической сетью», в которой связь между ресурсами определяется не гиперссылками и пользовательскими тегами, а непосредственно физическим смыслом этих ресурсов.
Иначе говоря, условное «Белое солнце пустыни», где бы в Сети не находилась информация об этом фильме, либо сам фильм, — это все еще одна и та же сущность, и интернет будущего, в теории, должен автоматически связывать все копии, упоминания и иные частичные отсылки к нему, независимо от того, поставил ли автор контента соответствующую гиперссылку или нет (что, кстати, делает поисковые системы бессмысленными). Это, само собой, потребует какой-то стандартизации предметной области, и использование подобной специальной микроразметки — один из значительных шагов в данном направлении.
Например, у Google есть своя база фильмов и актеров, и вы можете увидеть в результатах поиска те самые семантические ссылки, которые имеют очень высокую кликабельность. Поэтому, кроме задачи быть в выдаче по данным запросам как можно выше, разметка видеоконтента на more.tv также позволяет Google в принципе получить информацию о тех или иных тайтлах и персонах, и добавить их в свою базу. Это, в свою очередь, создает минорный, но постоянный низкочастотный трафик на эксклюзивный и архивный контент на сервисе.
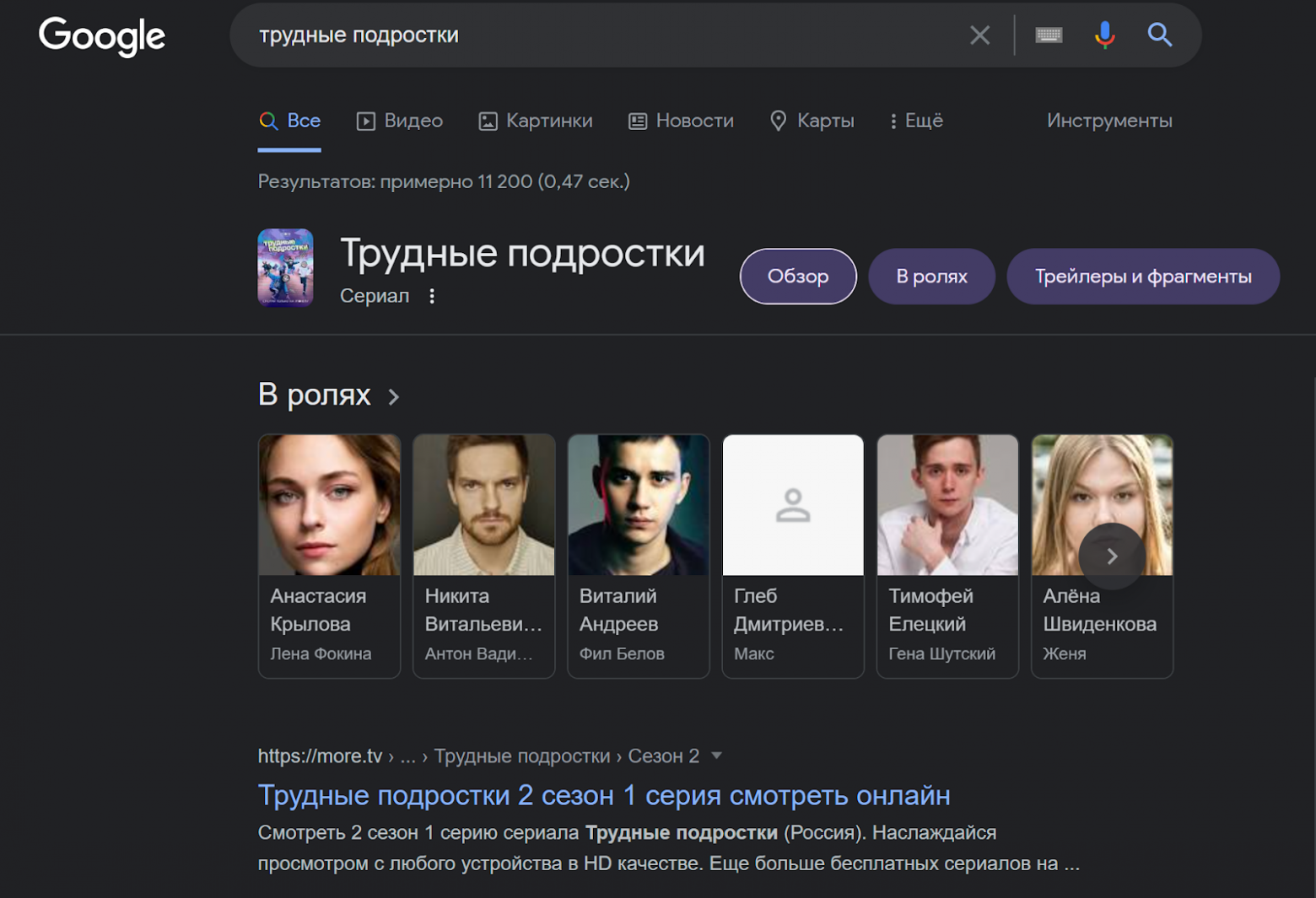
Кроме schema.org существует еще один популярный стандарт семантической разметки — OpenGraph. Эта спецификация предполагает чуть менее детализированный подход, предоставляя только разметку уровня страницы, но не отдельных элементов. При этом сам синтаксис OpenGraph позволяет описать более одной сущности в рамках одной страницы, например, перечислить краткий состав съемочной группы сериала на странице самого сериала. Примечательно, что эта информация отражена и в основной, «видимой» разметке страницы в виде соответствующего виджета, но вероятность того, что парсер ПС из этой разметки «поймет», что связь между страницей и виджетом соответствует отношению «сериал» - «съемочная группа», как показывают наши эксперименты, крайне мал, в то время как соответствующая микроразметка существует именно и только для этого.
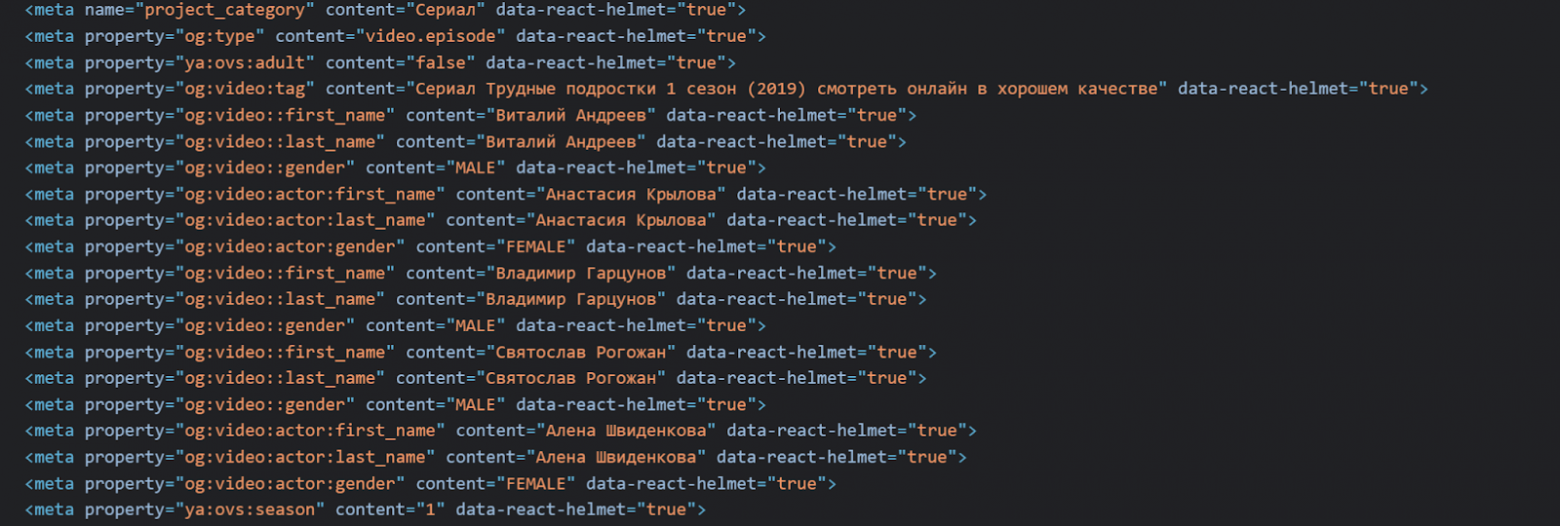
Поскольку микроразметка имеет максимально четкую семантику, есть все основания предполагать, что ПС имеет более высокий рейтинг «доверия”» к этой информации, и ключевые слова, размещенные в этих тегах, также имеют чуть больший вес, чем оные в стандартных тегах. Кроме того, og-разметка поддерживается большинством соцсетей и мессенджеров, и, в случае наличия, имеет более высокий приоритет перед <title> и <meta name=”description”> в формировании сниппетов при шаринге ссылок, что позволяет гибко управлять видом виджетов и максимально эффективно использовать их, в том числе, в маркетинговых целях.
Пара слов о производительности
Со времен широко известного в узких кругах исследования 2008 года и по сей день остается неизменным тот факт, что количество тегов на странице напрямую и существенно влияет на её производительность в браузере. Если для страницы в 100-200 тегов пара лишних <div>ов погоды не делает, то при 5 000+ тегах проблемы начинаются уже не только в рейтинге Lighthouse, но и у вполне реальных пользователей. Современный дизайн требует порой весьма замысловатых приемов верстки и избыточного количества тегов, а часто повторяющиеся на странице элементы (например, подборки фильмов или списки серий), кратно их умножая, могут вызвать очень ощутимый дискомфорт на мобильных устройствах и иных относительно слабых девайсах, например, телевизорах.
О том, как мы сражаемся за производительность страниц в целом, мы поговорим в третьей части статьи, здесь же стоит отметить тот момент, что подавляющее большинство элементов микроразметки нужно только автоматизированным парсерам сайтов, включая ПС. Пользователям же она практически ничего не дает и может лишь ухудшить их пользовательский опыт, так как количество порождаемых ей тегов обычно очень велико: например, главная страница more.tv вместе со всей микроразметкой может легко включать больше 20 000 тегов. Поэтому, используя технологию гибридного рендеринга, описанную в первой части статьи, more.tv умеет отдавать микроразметку только поисковым системам, в то время как живые пользователи загружают исключительно минимальный необходимый html без лишней семантики. В конце концов, лучший валидатор — это браузер, а время загрузки страницы от подобной манипуляции только уменьшается.
Формально это может выглядеть как клоакинг, то есть манипуляция поисковой системой при помощи предоставления различного контента ей и пользователям. Однако, если вдуматься, то манипуляции тут никакой нет: сайт всегда отдает один и тот же контент, только в разном формате, с разной степенью детализации, так сказать. И, судя по текущим результатам, это действительно работает, и проблем с баном страниц в индексе у more.tv до сей поры не было.

