
В конце июня коллектив из Carnegie Mellon University показал нам XLNet, сразу выложив публикацию, код и готовую модель (XLNet-Large, Cased: 24-layer, 1024-hidden, 16-heads). Это предобученная модель для решения разных задач обработки естественного языка.
В публикации они сразу же обозначили сравнение своей модели с гугловым BERT-ом. Они пишут, что XLNet превосходит BERT в большом количестве задач. И показывает в 18 задачах state-of-the-art результаты.
BERT, XLNet и трансформеры
Один из трендов последнего времени в глубоком обучении — это Transfer Learning. Мы обучаем модели решать несложные задачи на огромном объеме данных, а затем используем эти предобученные модели, но уже для решения других, более специфических задач. BERT и XLNet — это как раз такие предобученные сети, которые можно использовать для решения задач обработки естественного языка.
Эти модели развивают идею трансформеров — доминирующего на данный момент подхода к построению моделей для работы с последовательностями. Очень подробно и с примерами кода о трансформерах и механизме внимания (Attention mechanism) написано в статье The Annotated Transformer.
Если взглянуть на General Language Understanding Evaluation (GLUE) benchmark Leaderboard, то сверху можно увидеть много моделей, основанных на трансформерах. Включая обе модели, которые показывают результат лучше человека. Можно сказать, что с транформерами мы наблюдаем мини-революцию в обработке естественного языка.
Недостатки BERT
BERT является автокодировщиком (autoencoder, AE). Он скрывает и портит некоторые слова в последовательности и пытается восстановить изначальную последовательность слов из контекста.
Это приводит к недостаткам работы модели:
- Каждое скрытое слово предсказывается в отдельности. Мы теряем информацию о возможных связях между маскированными словами. В статье приводится пример с названием «New York». Если мы попытаемся независимо предсказывать эти слова по контексту, мы не будем учитывать связь между ними.
- Несоответствие между фазами тренировки модели BERT и использования предобученной модели BERT. Когда мы тренируем модель — у нас есть скрытые слова ([MASK] токены), когда мы используем предобученную модель, мы на вход ей уже такие токены не подаем.
И все же, несмотря на эти проблемы, BERT показывал state-of-the-art результаты на многих задачах обработки естественного языка.
Особенности XLNet
XLNet — это авторегрессионная модель (autoregressive language modeling, AR LM). Она пытается предсказать следующий токен по последовательности предыдущих. В классических авторегрессионных моделях эта контекстная последовательность берется независимо из двух направлений исходной строки.
XLNet обобщает этот метод и формирует контекст из разных мест исходной последовательности. Как он это делает. Он берет все (в теории) возможные перестановки исходной последовательности и предсказывает каждый токен в последовательности по предыдущим.
Вот пример из статьи, как предсказывается токен x3 из различных перестановок исходной последовательности.

При этом контекст — это не мешок слов. Информация об изначальном порядке токенов также подается в модель.
Если проводить аналогии с BERT-ом, то получается, мы не маскируем токены заранее, а как бы используем разные наборы скрытых токенов при разных перестановках. При этом исчезает и вторая проблема BERT-а — отсутствие скрытых токенов при использовании предобученной модели. В случае XLNet на вход поступает уже вся последовательность, без масок.
Откуда XL в названии. XL — потому что XLNet использует Attention-механизм и идеи из модели Transformer-XL. Хотя злые языки утверждают, что XL намекает на количество ресурсов, необходимых для обучения сети.

И про ресурсы. В твиттере выложили расчет, во что обойдется обучение сети с параметрами из статьи. Получилось 245000 долларов. Правда потом пришел инженер из Гугла и поправил, что в статье упоминаются 512 чипов TPU, которых по четыре на устройстве. То есть стоимость уже 62440 долларов, или даже 32720 долларов, если учитывать 512 ядер, которые тоже упоминаются в статье.
XLNet против BERT
К статье выложили пока только одну предобученную модель для английского языка (XLNet-Large, Cased). Но в статье упоминаются эксперименты и с меньшими по размеру моделями. И во многих задачах модели XLNet показывают лучшие результаты по сравнению с аналогичными моделями BERT.
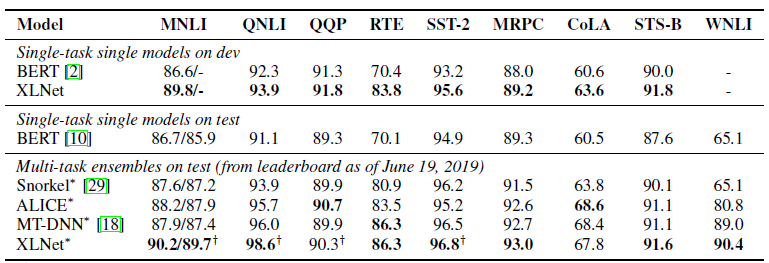
Появление BERT и особенно предобученных моделей привлекло большое внимание исследователей и привело к огромному числу связанных с ним работ. Теперь вот XLNet. Интересно посмотреть, станет ли он на какое-то время стандартом де-факто в NLP, или наоборот подстегнет исследователей в поиске новых архитектур и подходов для обработки естественного языка.
