

Александр Крижановский ( krizhanovsky )
По материалам доклада "Linux Kernel Extension for Databases" на HighLoad++ 2016.
Сегодня буду рассказывать про внутренности базы данных, про внутренности ОС и о том, что происходит на стыке. Когда я говорю про базу данных, я имею в виду в основном ввод/вывод, управление памятью и обработку транзакций. Это совершенно не про SQL, не про индексы, не про блокировки и т.д. Только ввод/вывод, управление памятью и транзакции.
Добрый вечер! Меня зовут Александр Крижановский, я работаю в 2-х местах. В одном мы занимаемся разработкой высокопроизводительных приложений на заказ, консалтингом, в основном, это система обработки сетевого трафика и базы данных. В другом проекте – в Tempesta Technologies (это филиал NatSys Lab) – мы занимаемся разработкой open source application delivery controller. Это гибриды из средств безопасности, веб-акселераторов и т.д., которые помогают вам доставлять контент быстро и надежно.

Сегодня я хочу рассказать про часть этого проекта. При том, что это в основном акселератор веб-контента, у него достаточно много общего с базами данных. Но про него в конце, а начну презентацию с моего очень давнего неудачного опыта построения собственной легкой базы данных.

Тогда, это много лет назад, у меня стояла задача построить очень быстрый сторедж для истории Instant messenger’а. Сторедж этот должен был держать сообщения пользователей по ключу из 3-х компонентов: отправитель, получатель и временами метка сообщения. Требовалась большая производительность. Начинали с того, что нам вообще консистентность не важна, мы хотели это все делать на файловом сторедже, а потом пришли к тому, что как-то нехорошо терять сообщения пользователей, и мы захотели какую-то consistency. И поскольку мы начинали с файлового стореджа, подумали, что 2-3 месяца достаточно, чтобы что-то такое сделать на файлах. Заложили срока очень мало, и в результате надо было это все быстро делать.
Сегодня буду рассказывать про внутренности базы данных, про внутренности ОС и о том, что происходит на стыке. Когда я говорю про базу данных, я имею в виду в основном ввод/вывод, управление памятью и обработку транзакций. Это совершенно не про SQL, не про индексы, не про блокировки и т.д. Только ввод/вывод, управление памятью и транзакции.
В тех местах, когда я буду упоминать про базы данных, я буду ссылаться на InnoDB, которая мне наиболее знакома.
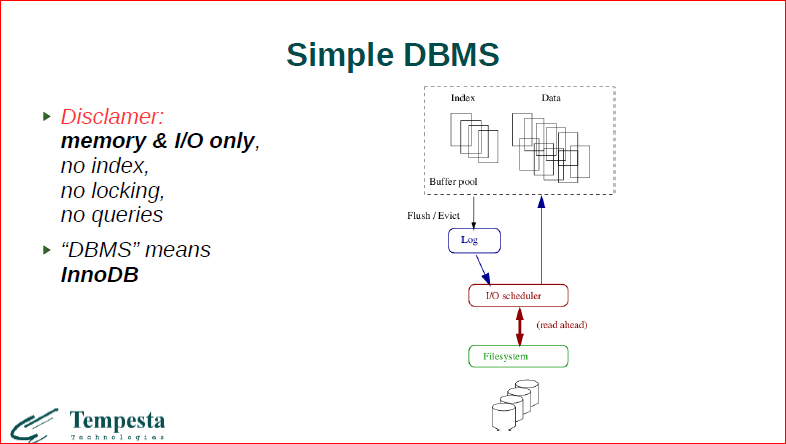
Если мы посмотрим на движок транзакционной базы, мы увидим примерно такую же картинку. У нас есть буфер pool, в нем живут странички индекса, странички данных. Все эти странички выводятся через транзакционный лог, когда они изменились, проходит это все через планировщик ввода/вывода и в ту, и в другую сторону. Планировщик ввода/вывода, когда он считывает что-то с диска, он делает read ahead. Все это проходит через файловую систему, но это дальше, на диске.
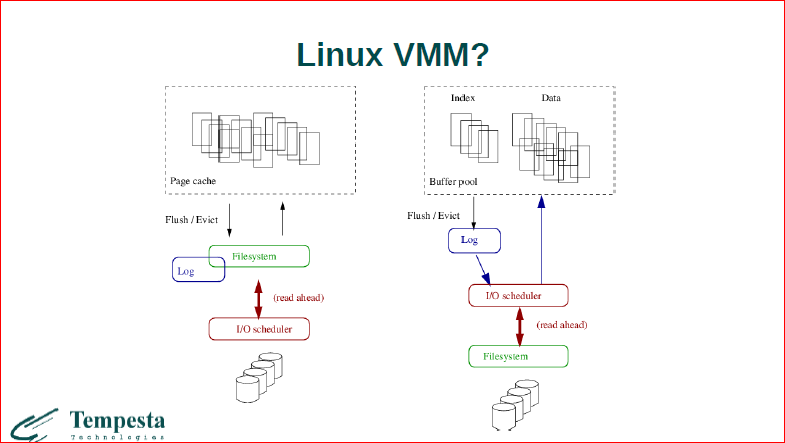
Теперь давайте посмотрим на то, как устроена подсистема ввода/вывода и виртуальной памяти в Linux. Вот, слева. И в принципе, в ОС. И мы видим очень-очень похожую картинку, т.е. у нас есть page cache, там хранятся какие-то странички, сбрасываются они через файловую систему, через VFS к файловой системе. Вместе с файловой системой обычно поставляется транзакционный лог и все это тоже проходит через планировщик ввода/вывода, и там тоже разные умные вещи происходят.

Традиционно, базы данных строились на системном вызове O_DIRECT. Это достаточно старая выжимка из письма Линуса. В общем, не приветствуется это разработчиками ОС, и у нас достаточно долго есть недопонимание между разработчиками ОС и баз данных – что должно быть.

В то время я решил, что мы не будем пытаться выкинуть ОС, как большинство разработчиков баз данных, а будем максимально использовать ее интерфейс, поскольку времени у нас мало. У нас есть замечательный системный вызов mmap, который нам поможет. У него есть все необходимые нам фичи, которые мы видели сейчас на левой картинке. Во-первых, он вытесняет странички. Когда страничка вытесняется, она пишется на диск, и она пишется атомарно, файловая система это обеспечивает. Далее mmap как-то в бэкграунде сбрасывает странички, и у нас получается персистентность. Ввод/вывод управляется ОС, у нее есть разные продвинутые планировщики ввода/вывода – это тоже нам хорошо, и у нас есть такая приятная фича, что мы даже получаем индексы бесплатно.
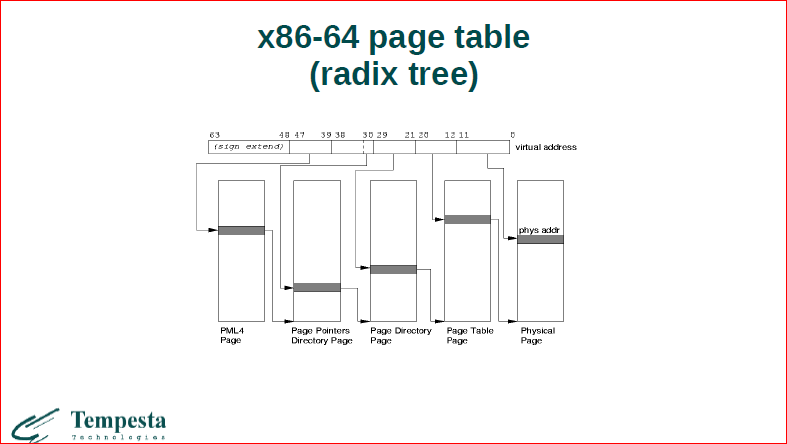
Давайте посмотрим на последнюю фичу. Mmap – это просто непрерывная область памяти, достаточно большая. Соответственно, есть виртуальные адреса, есть физические, и все обращения в память у нас, которые происходят, должны ходить через транзакцию виртуального адреса в физический. Для этого у нас используется таблица page table. Она занимается этим резолвингом. У нас есть сверху ключ 48-битный, это адрес. Из него используется только 36 бит. И здесь мы проходим, откусываем по 9 бит за раз от этого ключа и проходим по дереву. У нас получается некий такой radix tree.
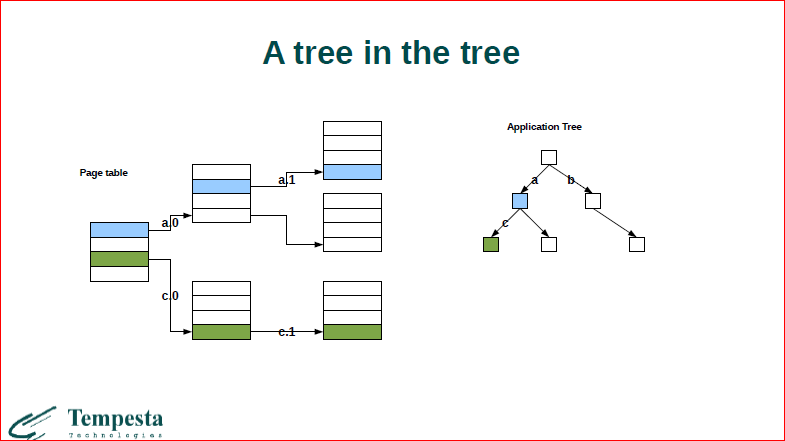
Если эту картинку пересмотреть, то будет примерно то, что показано слева. У нас первые 9 бит ключа определяют индекс в этом массиве, потом мы переходим здесь по указателю на следующий и т.д. Структура называется radix tree. И в целом, если мы строим какое-нибудь бинарное дерево в оперативной памяти, обычно бинарное дерево, скажем, какое-нибудь STL map, который использует красно-черное дерево, у нас на каждом поиске элементов, если мы спускаемся с дерева и хотим пойти до зелененького элемента из синего, то мы должны в общем случае разрезолвить адрес и, соответственно, пройти все наше большое дерево, сделать 4 обращения к памяти. Получается, что на то, чтобы пройти каждый элемент нашего прикладного дерева, мы должны пройти еще дерево таблицы страниц.

Если мы посмотрим на идею того, что у нас индекс есть из коробки, мы можем выделять непрерывную область памяти какому-то фиксированному адресу map’ом и потом брать ключи в фиксированном диапазоне, класть их на шину данных, и вот у нас будет резолвинг через таблицу страниц.

Если мы на это более внимательно посмотрим, то это на самом деле не что иное, как просто обычный СИ-шный массив, т.е. большой СИ-шный массив – это на самом деле дерево.

Мало что, наверное, с этим можно сделать, но здесь интересно то, что виртуальная память совсем нам не дешева. Первое, о чем хочу сказать – это 3-ий буллет – о том, что если если мы будем использовать виртуальную память как просто индекс из коробки, то если мы будем использовать ключи с плохой локальностью, т.е. сильно распределенные ключи, у нас все будет очень долго, потому что мы будем использовать очень много памяти. Т.е. один элемент мы храним, а используем целую страницу там, где он лежит, и каждый элемент этого дерева – это страница. Дерево – очень дорогое.
У нас это дерево кэшируется в TLB. TLB маленький и, к сожалению, мы в сontext switch’ах должны вообще инвалидировать полностью кэш первого уровня, потому что виртуальные адреса у нас могут быть одинаковые и, соответственно, у нас вылетают все эти адреса. Но хорошо то, что user-space/ kernel-space/сontext switches он оставляет кэши нетронутыми, потому что ядро и user-space работают в одной таблице страницы.

Собственно, на тот момент, когда я начал разбираться с mmap, я понял следующую вещь – о том, что, во-первых, если мы используем большие данные, нам нужно максимально держать пространственную локальность, т.е. нельзя просто так за-mmap’ить большую область и как попало использовать, нужно максимально локально ключи использовать. Большие map’ы достаточно дороги, потому что если вы mmap’ите большую область, вы тратите много на таблицу страниц, т.е. вся эта область должна как-то адресоваться.

На самом деле я далеко не первый, кто, вообще, попытался переиспользовать механизмы ОС с помощью mmap. Мы видим, что еще 35 лет назад люди задавались этим же вопросом – о том, что как-то нехорошо получается, что, вроде как, у нас все механизмы есть, но операционные системы не удовлетворяют требованиям разработчиков баз данных.
Сформулировал Michael Stonebreaker эти требования, они достаточно интересные, и интересно, что фактически все, кроме последнего, до сих пор актуальны. Т.е. за это десятилетие процессы стали достаточно легкими, у нас появились треды, у нас много всего изменилось, появился mmap (т.е. эта статья еще до появления mmap). Остальные, в принципе, более или менее, актуальны. Т.е. первое, что когда мы делаем mmap, вытесняем, мы не знаем, когда какая страница вытеснится, в каком порядке и т.д.
Далее. Обычно файловые системы, с которыми мы имеем дело, они не структурированы, они просто хранят последовательности байт. У нас совершенно нет транзакций настоящих. Т.е. с одной стороны мы говорим о том, что у нас есть транзакционный лог, с другой стороны, транзакций в смысле баз данных у нас нет. И есть проблема с непрерывностью аллокаций блоков на диске.
Последние 3 проблемы сейчас более или менее решены, а первые 3 как не были решены, так и не решились. Давайте с конца все это посмотрим.
Первое – это о локальности данных. Нам помогают extent’ы файловых систем, т.е. у современных файловых систем они аллоцируют на диске пространство достаточно большими кусками и решают проблему того, что у нас фрагментация на диске блоков файлов баз данных достаточно низкая.

Соответственно, нам здесь здорово помогает системный вызов fallocate. Если мы создаем большой файл, если мы делаем большую запись в файл, то мы можем пререзервировать последовательную область на диске и писать туда данные.
Поскольку у нас файловые системы не только аллоцируют данные extent’ом, но они их еще и адресуют, большинство файловых систем индексируют свои блоки через деревья, через B-tree, хэштрай и, чем больше блок данных они индексируют, тем ниже это дерево. Соответственно, если они индексируют большие extent’ы, то деревья получаются достаточно низкими. Если мы аллоцируем пару файлов fallocate, то у нас еще меньше индекс. Т.о., по сути, у нас дерево, которое есть у файловой системы для адресации блоков, очень низкое, и эта проблема нивелируется тоже.
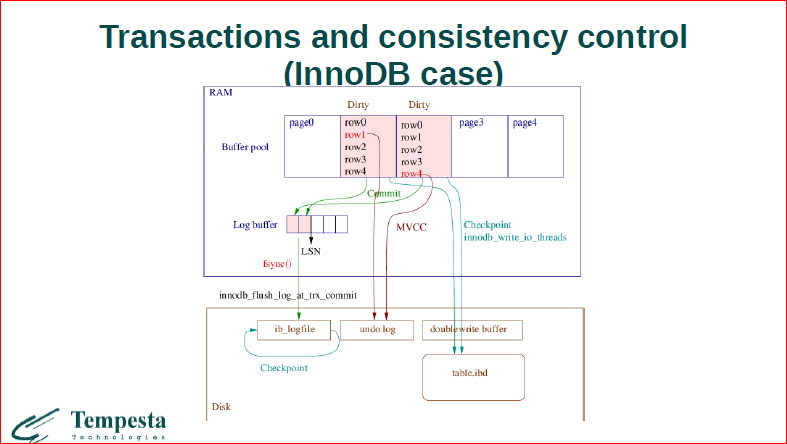
Теперь самое интересное – это то, как обрабатываются транзакции. Здесь схематично попытался нарисовать, как выглядит transaction processing в InnoDB. Давайте рассмотрим, что здесь у нас есть две грязные странички, у которых изменяются 2 записи красным цветом. И самое важное для нас, что InnoDB использует политику т.н. steal и no-force, это значит, что эти странички могут быть в любой момент сфлашены с диском, т.е. до момента коммита. Это значит, что они воруются, это steal-стратегия, а no-force говорит о том, что когда у вас проходит коммит, необязательно, что у вас будут зафиксированы все ваши данные на диске. Т.о. мы используем undo, redo log’и для того, чтобы откатить. Undo log – откатить сфлашенные до коммита данные, транзакцию, которая еще не закоммитилась, и redo – для того, чтобы восстановить.
Здесь еще интересно, что есть undo log – это основа, на чем работает мультиверсионность. И он хранит старые версии записи. В целом для базы данных ее транзакционный уровень ввода/вывода должен знать о record’ах, т.е. мы не можем реализовать достаточно гибкую стратегию фэшинга без знания семантики данных, которые мы храним, без знания record’ов.
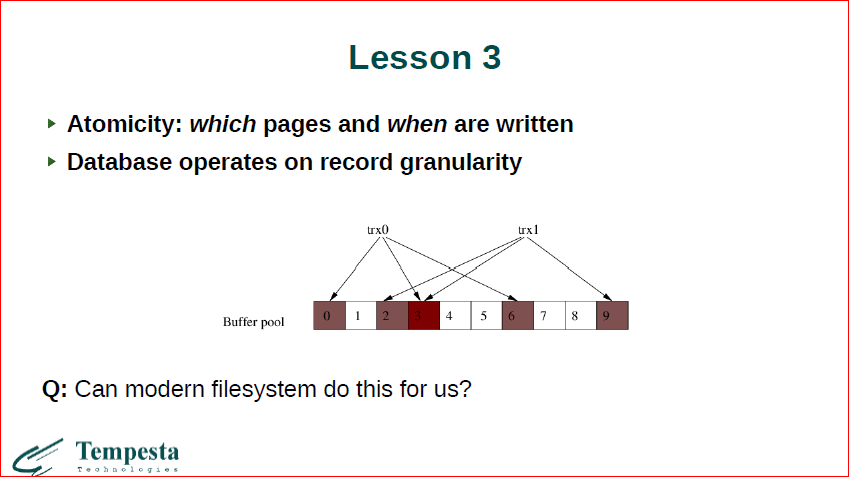
В принципе, я уже сказал о том, что мы не можем гарантировать, когда какая страница будет записана, не можем говорить о записях. И давайте посмотрим, например, что у нас будут какие-то две транзакции, которые совершенно разные страницы модифицируют, но на одной из страничек они модифицируют разные записи. У нас Linux VMM не знает о record’ах, соответственно, когда у нас первая транзакция коммитится, мы можем сказать, что у нас была изменена 3-я страничка. Но мы ее должны сфлашить. Допустим, мы ее флашим, эти первые 3 страницы, которые были изменены первой транзакцией. Но, когда мы флашим эту страницу, мы не знаем, успела ли другая транзакция сделать изменения в 3-й странице или нет. И мы вместе с первой транзакцией можем сфлашить изменения 2-ой транзакции, а можем и не сфлашить. И самое плохое, что мы этого вообще не знаем и даже не можем узнать.
Мы понимаем, что современная база данных реализует более сложные механизмы, чем файловая система, но, может быть, мы можем откусить какие-то кусочки от транзакционного движка баз данных и заменить их механизмами файловой системы? Давайте сейчас немного пробежим по тому, как файловая система устроена и потом попытаемся ответить на этот вопрос.

Первое, что хочу сказать о файловых системах – популярные файловые системы, которые большинство используют, это т.н. log-расширенные файловые системы. Т.е. есть обычная файловая система, к ней припиливается лог. Когда мы делаем запись, мы сначала пишем в транзакционный лог и потом уже пишем на диск. Соответственно, у нас получается двойная запись обязательно. Во-первых, лог транзакционный пишется последовательно, поэтому нам хорошо, он маленький, он последовательный, а во-вторых, поскольку мы уже записали в лог, мы можем отложить запись изменений, забатчить их и большим куском все вместе опустить.

Проблема двойной записи нравилась не всем, и люди делали попытку вообще уйти от двойной записи. Они говорили: «OK, давайте мы откажемся от структуры файловой системы и всю ее построим как один большой транзакционный лог. У нас изменились данные, мы их допишем в конец последовательного лога, который все растет и растет дальше. И изменяется кусок файла, мы его дописываем в конец. Теперь у нас inode, который ссылается на изначальный наш блок, должен быть изменен, т.о. мы тоже должны его копировать туда в конец транзакционного лога. И поскольку у нас теперь inode’ы плавают по диску, мы должны еще где-то держать карту inode’ов, которую тоже как-то апдейтить с этими указателями на inode’ы в конце. И получается достаточно сложная структура со сложным менеджментом, показывающая очень плохую производительность. Например, Nilfs до сих пор в ядре Linux есть, ее можно взять и запустить попробовать.

Продолжением этой идеей (что-то между первыми и вторыми) стали Copy-On-Write файловые системы. Это современный ZFS и BtrFS. Они используют такой же подход. Поскольку обе файловые системы позволяют снэпшотить, то они используют следующее свойство. Допустим у нас есть желтенькое дерево изначально, потом мы должны добавить элемент 19. Мы берем, копируем этот блок, дописываем к нему 19. Теперь мы должны ссылаться на этот блок из root’а. Root мы тоже копируем и приписываем ссылку. Эти оставляем. И в этот момент у нас остается 2 элемента, которые у нас когда-то освободятся. За счет этого мы можем делать снэпшоты. Здесь у нас похожа идея на log-структурированную файловую систему, т.е. новые изменения мы просто дописываем дальше.
И здесь получается следующее свойство. Если у нас есть файл базы данных, который примерно одного размера сохраняется, например, у вас есть 100 тыс. пользователей/клиентов, которым вы иногда изменяете записи и т.д., но примерно у вас файлы в базе данных будут одинаковые, медленно расти, но будет высокий update. Такая файловая система будет все время аллоцировать место на диске и все время будет крутить диск, и с фрагментацией тут тоже будут проблемы, потому что эти 4 блока были последовательны на диске. После того, как мы запишем вот эти блоки, слинкуем, у нас будет дырка на диске, проблема с локальностью здесь есть. С другой стороны, если мы все время дописываем новые и новые данные, то такая файловая система имеет место быть. Она пишет только один раз данные, она не пишет их 2 раза на диск. Поэтому, наверное, BtrFS лучше для OLAP-нагрузок, когда вы периодически выгружаете большие объемы данных на диск и выгружаете их последовательности. Если же у вас идет большой update (OLTP-нагрузка), то лучше классическая файловая система обычная.

Последнее о чем хотел упомянуть – это FreeBSD файловая система. Она говорит о том, что мы можем вообще не использовать никакие логи, а можем аккуратно делать update. Если мы, например, хотим добавить новый блок в файл, то мы сначала аллоцируем блок, где мы его аллоцировали, положили, и только потом мы должны записать ссылку на него в inode. Если у нас где-то посередине отвалится, ну, мы потеряем первый блок, но консистенция останется. С другой стороны, если мы сначала изменим inode, который ссылается на новый блок, а блок еще не выделен, то у нас свалится консистентность файла. Так она работает, но, понятное дело, что файловая система, опять же, не знает никаких данных, она может сохранять только консистентность своей структуры, она не может сохранять консистентность данных. В принципе, файловые системы XFS и EXT4… XFS позволяет только мета-дату делать, EXT4 можно настроить, чтобы она данные тоже логировала, т.е. EXT4 позволяет вам более консистентные данные хранить.

И мы подобрались к вопросу: можно ли все-таки механизмы баз данных выкинуть и использовать вместо них файловую систему? Yves Trudeau из Percona написал замечательный блог о том, как он попытался вытянуть doublewrite buffer и заменить его транзакционным логом файловой системы. И блог этот, насколько помню, вообще, в 2-х частях. Первая часть о том, что все замечательно, все хорошо получилось, вторая – о том, что ничего не получилось.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
Проблема в том, что мы не можем писать большие данные. Т.е. давайте рассмотрим, что мы пишем сейчас с вами… Делаем большой write, один системный вызов вызываем, который должен записать нам 3 блока. Первый пишем, второй пишем хорошо, потом мы отваливаемся. Нам файловая система не откатит изменения первого. Транзакционный лог файловой системы – это очень небольшой файлик, маленький. С другой стороны мы можем вызвать write на много-много Гбайт, например, какой-нибудь большой image blu-ray попытаться сохранить. И нет у нас места для того, чтобы все эти данные где-то сохранить. Мы можем саллоцировать большой файл и записывать там данные. Нам тоже негде все это сохранить. Файловая система максимум, что может, даже в максимальном варианте EXT4, которая должна обеспечивать консистентность данных – мы какую-то часть из данных, переданных в write VM, консистентно запишем, а какую-то – нет. Что-то у нас откатится, а что-то нет. Вообще говоря, это профанация – консистентность данных файловой системы.
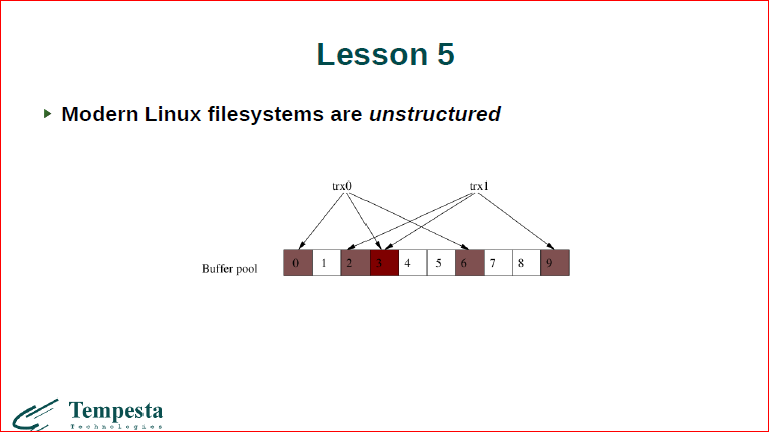
Опять же, после заключения о том, что файловые системы не структурированы, ничего не знют о данных, консистентности не дают.

Давайте еще посмотрим, как у нас вытесняются данные, флашатся из памяти на диск. Linux работает с двумя списками – активный/неактивный. Если приходит к нам какая-то новая страничка, мы почитали ее в памяти, либо поизменяли, и пока мы ее изменяем, она находится в active list, а как только она устаревает, она вытесняется в inactive list по timeout’у. Если она сколько-то пробудет в inactive list, отсюда она флашится на диск, и отсюда она может забираться аллокатором. Проблема здесь в чем? Что это две линейные структуры данных с последовательным доступом. У нас памяти может быть очень много, современные сервера — 128/512 Гбайт оперативки, делим это все на 4 Кбайта и получаем уйму страничек, которые будут лежать в линейном списке. Соответственно, если у нас доступ к нашим данным, к памяти все время меняется, мы меняем то одни странички, то другие пачкаем, у нас в эти списки оно добавляется, inactive список тоже может у нас пухнуть по каким-то своим правилам. В какой-то момент мы можем брать страничку, снова к ней обращаться, она снова сюда передернется. И это множество все время у странички может циркулировать между этими списками, когда страничка все-таки флашится на диск, она может быть снова поднята с диска при обращении и т.д. В общем, когда ядру Linux не хватает памяти, когда ему приходится сканировать эти списки, все становится очень медленным. Кстати говоря, kswapd – однопоточный демон, плюс он должен лочить эти списки, когда он по ним бегает, для того чтобы сохранить консистентность структуры данных относительно изменений, которые делают другие процессы по вставке и извлечению страничек. Ну и, в общем, все очень плохо.

Есть у нас несколько системных вызовов, которые нам помогают синхронизировать принудительно данные из открытого файла, скажем fsync, либо из mmap. Но проблема в том, что если мы внимательно посмотрим на все эти вызовы, у нас есть адрес, есть длина, offset, nbyte. Мы можем какой-то непрерывный range сбросить, мы не можем сказать: «Пожалуйста, сбрось нам 1-ую, 3-ю и 5-у странички». Так мы не можем. Если мы сбрасываем и делаем один большой write, то мы не можем его записать атомарно. И мы не контролируем, когда ядро Linux скинет определенную страничку – может быть до этого sync’а, а может быть после sync’а. Когда мы mmap’им файл, мы вообще не знаем ничего о том состоянии файла на диске, какие данные синхронизированы, а какие не синхронизированы. Это плохо.

Соответственно, мы немного можем повлиять на процессы, которые протекают в вытеснении из памяти внутри Linux, мы можем давать advice, например, advice о том, что страница определенная не нужна, если мы помечаем в mmap страницу как ненужную, то с большой вероятностью ядро ее раньше выкинет. Но, опять же, когда оно ее выкинет вообще, нам тоже гарантий никаких не дается.

Это некоторая сумма о том, что только что сказал. Первое – о том, что мы вытесняем, а когда мы вытесняем, мы не знаем, можем только немного влиять. Есть полная синхронизация файла и это, кстати, причина, почему транзакционный лог баз данных хранится в отдельном небольшом файле, потому что мы можем полностью сделать fsync на этот файл, полностью его синхронизовывать, потому что у нас нет другого выбора, как синхронизировать какую-то область, например. Почему он в table spase не хранится. Залоченые списки сканируем, это все плохо очень.

Давайте пройдемся по ресерчу, который делается в области файловых систем. Прежде всего, это Reiser4. Они добавляли транзакционность, но опять же транзакционность для небольшой записи. По-моему, это 4-32 Кбайта, атомарность давали. У них есть какая-то поддержка транзакций, но большие данные нельзя сохранить консистентно, с гарантией.
BtrFS дает нам интерфейсы по транзакциям. Мы можем сказать, что начать транзакцию, начать операцию с файловой системой, по-моему, это не только read, write в определенный файл, но это всякие перемещение файлов, удаления и т.д. Потом закончить транзакцию. Здесь есть проблемы, и это интерфейс, не рекомендованный к использованию в том, что если мы начинаем транзакцию, потом наш процесс подыхает, то больше никто не сможет обратиться к этим файлам, к которым он залочился. Т.о. транзакция не откатится.

Есть Windows TxF. Она, вроде, была в какой-то версии Windows, наверное, даже сейчас есть. Она объявлена как deprecated, тоже, насколько помню, по тем же самым причинам, что и в BtrFS. И есть еще ресерчевская достаточно свежая файловая система, которая позволяет вам на уровне самом высоком, абстрактном, делать транзакционные системные вызовы над файлами в семантике транзакций. Тоже начинаем транзакцию, коммитим, откатываем и т.д.

Далее, у нас есть еще ОС 2009-го года, которая говорит о том, что «почему бы нам, вообще, не сделать все операции в ОС транзакционынми?». Т.е. любую последовательность системных вызовов мы можем поставить под транзакцию, любую откатить, и для этих целей там патчится абсолютно все. Все структуры данных, когда вы меняете. Например, у вас есть структура task_struc t, если вы изменяете процесс, например, изменил какие-то данные по файловым дескрипторам или еще чему-то, вы копируете всю эту структуру, помечаете ту как old copy, новую как новую копию, и работаете с этими копиями. Потом их удаляете. И в целом вы можете это откатить.

Более интересный для нас пример – это оказался msync-проект. Он делает достаточно маленькие вещи, он просто дает транзакционный интерфейс к mmap’у. Он позволяет вам за- mmap’ить область памяти с новым флагом MAP_ATOMIC, msync патчат, который позволяет синхронизировать только измененные данные, причем не в последовательности, а только те, которые были недавно изменены. Добавляют REDO logging и патчат сброс страниц. Т.е. достаточно небольшие изменения, но которые позволяют нам атомарно работать с mmap’ленной областью.
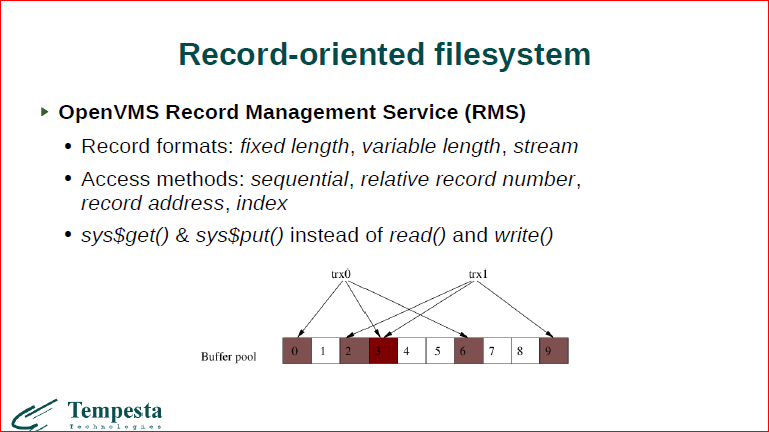
Последний пункт, который у нас был, который адресовал Michael Stonebreaker – это о том, что у нас файловые системы неструктурированные. На самом деле у нас есть файловые системы, которые структурированы, которые дают вам Record-oriented интерфейсы. И в RMS такой есть, по-моему, это было в IMB-mainframe’ах, соответственно, в mainframe’овских файловых системах у нас есть файловые системы, которые вы можете открыть sysopen – специфичными системными вызовами. Т.е. не такими как open, read, write в Linux, а используя специальные системные вызовы для открытия файла, для последовательного доступа, для доступа по индексу и т.д.
На самом деле, это получается у вас, когда вы закрываете файл, у вас все это сбрасывается обязательно. На самом деле это выглядит как база данных, она пахнет как база данных, она по сути внутри и есть база данных. У вас есть индекс, у вас есть транзакция, у вас есть интерфейс этого добавления записи, прохода по записям и т.д. По сути, это встраиваемая база данных, которая сделана на уровне ядра VMS. И, вообще говоря, это не 80-ые годы, это современная вполне вещь, и сейчас можно скачать документацию по этому, это документация современной ОС.

Подобрались уже к нашему решению. Мы тоже делаем базу данных, но нам база данных понадобилась, поскольку мы делаем веб-акселератор, то акселератор должен хранить контент страниц. Есть, например, Apache Traffic Server, который реализует некоторое подобие базы данных, он не в каждом отдельном файле хранит табличку, а в специально алоцированном спейсе, который может разбивать эффективно и адресовать.
Мы также используем базы данных, т.е. основное, для чего мы используем TempestaDB – это файловый кэш, ну, кэш ответов сервера. Там же еще у нас хранятся правила фильтра, заблокированных клиентов, там же будут храниться сессии пользователей и т.д.
Сама Tempesta работает внутри softirq. Это полностью ядерное решение, и сейчас мы начали работать над тем, чтобы открыть эти интерфейсы и сделать что-то более общее, что можно было бы использовать в новых приложениях для базы данных. Нам самим сейчас понадобились новые интерфейсы для доступа к базам данных, для того чтобы можно было удобно управлять веб-кэшом и, соответственно, нам стало не хватать ядерных баз данных, к которым тяжело получить доступ из user space. Это все сейчас находится только в разработке, сейчас в отдельной ветке на github’е это лежит.
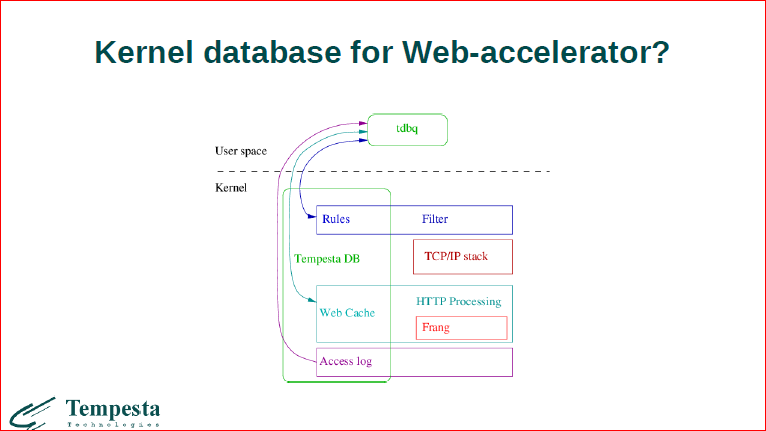
Давайте посмотрим, что делается, как все это хозяйство используется. У нас есть user space-утилитка, которая вам позволяет делать какие-то queries’ы в базу данных, отрывать таблички и т.д., т.е. достаточно проста. Остальное все, что делается – это на уровне ядра в базе данных у нас фильтр хранит правила фильтрации, здесь хранится веб-кэш, будет храниться логирование.
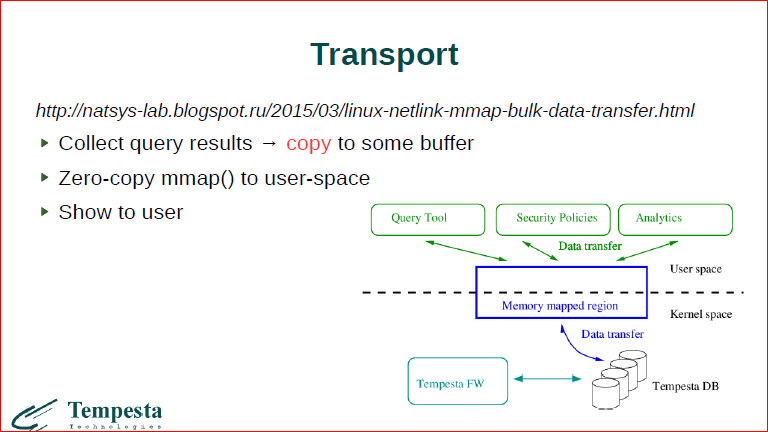
Тот интерфейс, который сейчас есть в мастере – это такой интерфейс, т.е. вся эта база данных лежит у нас внутри ядра, и мы используем netlink-mmap-интерфейс для того, чтобы передать запрос через сокет в ядро. Ядро здесь крутит запрос и потом отдает результаты в user space. Проблема в том, что сам по себе netlink-mmap может любой ядерный буфер смапить вам в user space, т.е. мы с помощью zero-copy можем передать все данные из ядра в user space. Проблема заключается в том, что в базе данных у нас много всего лежит. Если вы дадите запрос, например, «дайте мне все ответы сервера за какой-нибудь период или к какому-нибудь индексу», мы не можем просто взять и, как бы, страницы базы данных замапить в user space, потому что у нас в этих страницах будут и записи, которые соответствуют запросу, и записи, которые не соответствуют, во-первых. Во-вторых, эти записи могут меняться вот прям сейчас в онлайне. И мы поступаем так, что мы здесь, в сторонке, аллоцируем новые странички, туда собираем результаты выполнения запросов, а потом эти странички мы мапим без копирования в user space. Нам захотелось все-таки быть совсем без копирования, и чтобы у нас и user space процесс, и сама Tempesta работали с одним буфером внутри ядра Linux как с одной общей базой данных, т.е. у нас получается многопоточная база данных с одинаковыми данными.

И сейчас немного про то, как мы строимся. Во-первых, мы используем только большие страницы. Когда ОС грузится, мы откусываем от нее область памяти, большую непрерывную, так же, как делает huge tdbfs. Потом в нее мы мапим все наши данные, т.е. поскольку Tempesta – это полностью ядерное решение, оно работает в softirq. Т.е. сами треды обработки и клиентских запросов – это отложенные прерывания, спать мы там не можем, на диск мы не можем, поэтому есть жесткое требование о том, что вся база должна быть in memory, она должна быть персистентная, должна быть консистентной, но вся должна помещаться в память, чтобы пришедший запрос мог сразу отработать. Сбрасываемся мы только в отложенных нитях.
Припиливается сейчас новая файловая система, которая должна дать интерфейс к TempestaDB. Собственно, через этот интерфейс у нас будет свой mmap, похожий на msync. Используем мы сейчас стратегию no-steal force либо no-force. No-steal, напомню, это значит, что страницу мы не можем сбрасывать на диск до тех пор, пока нет коммита. А forсe, no-forсe значит то, что если у нас forсe-стратегия, то тогда, когда проходит коммит, мы обязаны все sync’ать на диск. Если no-force, то коммит прошел, но sync’а может не быть.
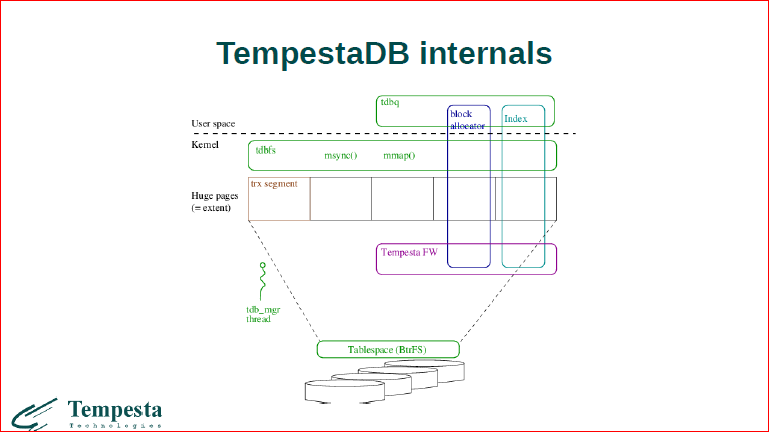
Давайте посмотрим, что происходит. Во-первых, как это все организовывается сейчас. Есть сегмент страниц этих больших, которые аллоцируются. Мы от него отрезаем небольшую область вначале. Это транзакционный сегмент, здесь у нас живут интерфейсы mmap, виртуальной файловой системы тонкой, и прикладной уровень ходит через эти интерфейсы. Получается, что вся база данных мапится в user space через mmap, на уровне user space виден как индекс, так и данные. И выводится отдельный менеджмент в потоке, который занимается синхронизацией.
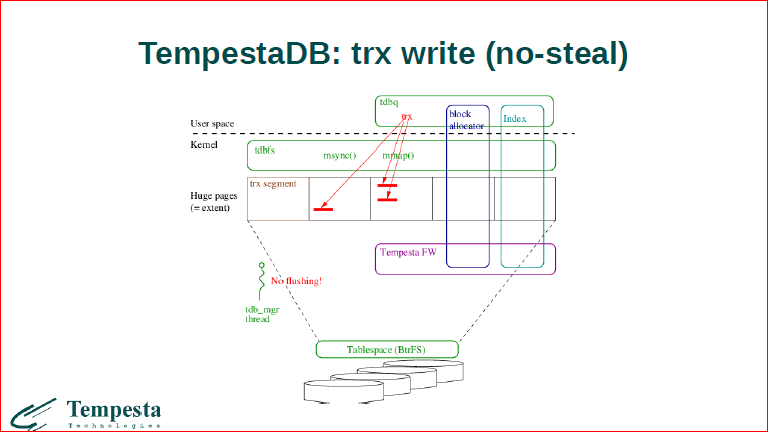
Смотрите, если у нас приходит какая-то транзакция, которая изменяет 2 странички и изменяет 3 записи. Мы изменили в huge pages данные, мы их не флашим, т.е. все это встраивается в систему VMM Linux’а, но эта специальная область не сбрасывается в бэкграунде.
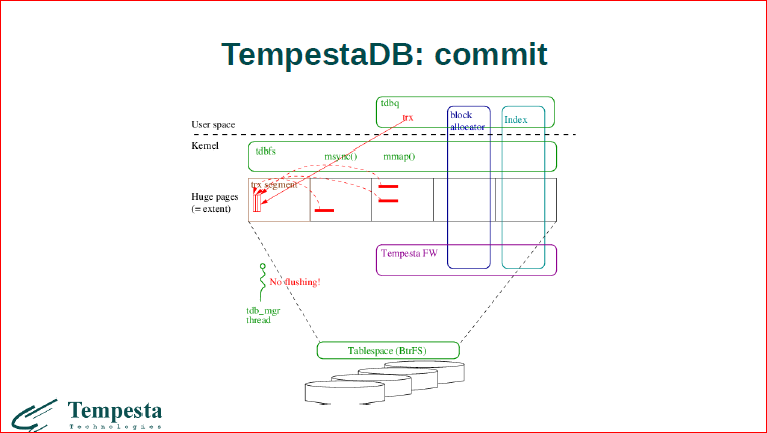
Теперь, когда мы прописали эти данные, и из user space к нам приходит коммит, мы все эти данные копируем в транзакционный сегмент, собираем их последовательно и последовательной записью в отложенном потоке потом мы это все сбросим. Сейчас мы еще пока не флашим.
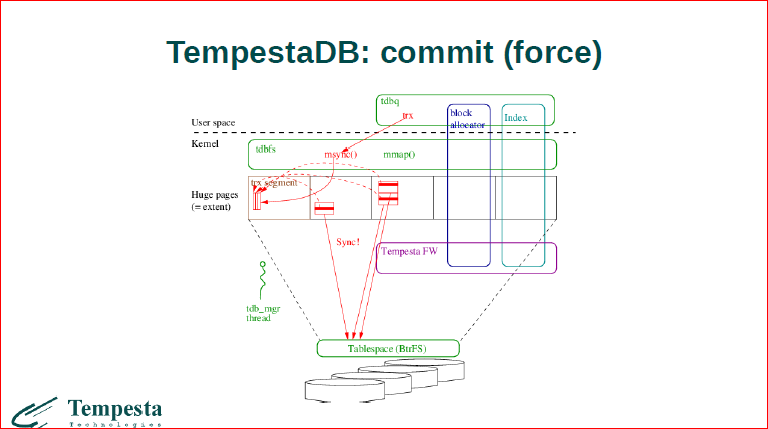
Теперь, когда коммит прошел, мы уже флашим все данные.
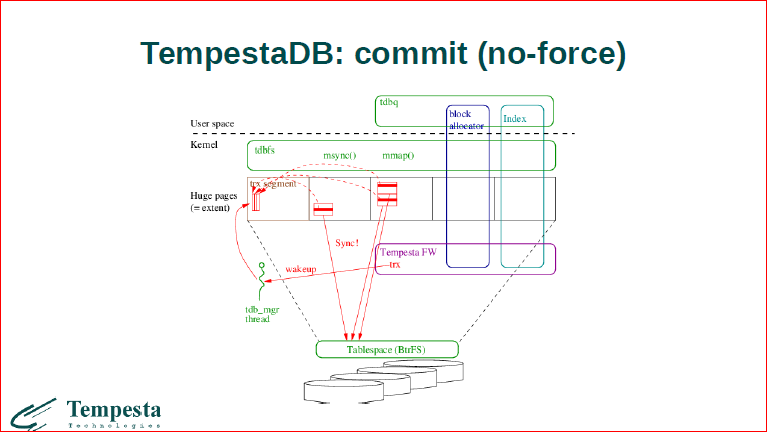
В другом сценарии, если мы пишем, делаем какую-то транзакцию из ядра Linux, то все данные, которые мы здесь изменяем, мы не можем их сбросить внутри softirq. Мы должны попросить отдельный поток, который нам их сбросит.
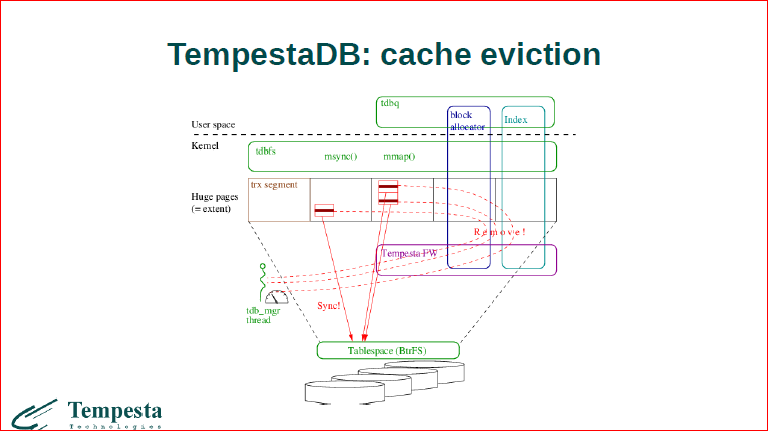
Вытеснение из кэша. Поскольку мы должны реализовать веб-кэш, в котором записи должны устаревать, мы еще прикручиваем и вытеснение из кэша. Вытеснение из кэша работает через наш вспомогательный поток и также через сброс через транзакционный лог, т.е. когда у нас есть запись в страничке, мы уже знаем, что она уже закончена, мы ее можем сбросить на диск.
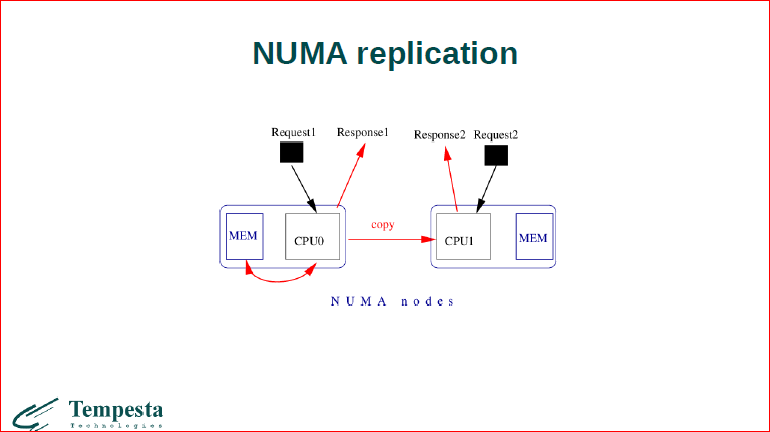
Далее еще несколько слов о том, как устроена TempestaDB. Дело в том, что современные машины построены на NUMA-архитектуре, и это значит, что доступ к разным участкам памяти занимает разное время, соответственно, одна из функций вспомогательного потока TempestaDB заключается в том, чтобы копировать, реплицировать данные между NUMA-нодами.
В TempestaDB у нас есть несколько режимов работы, если у вас очень большой контент, который вы копите в кэше, то вам имеет смысл, чтобы каждый процессор ходил в удаленную ноду. Пускай медленно, но мы храним данные только 1 раз. С другой стороны, если вам нужна очень высокая производительность, но данных немного, то мы можем скопировать данные на разные процессорные package’и, в их локальную память, и каждый процессор будет работать достаточно быстро с их локальной областью.
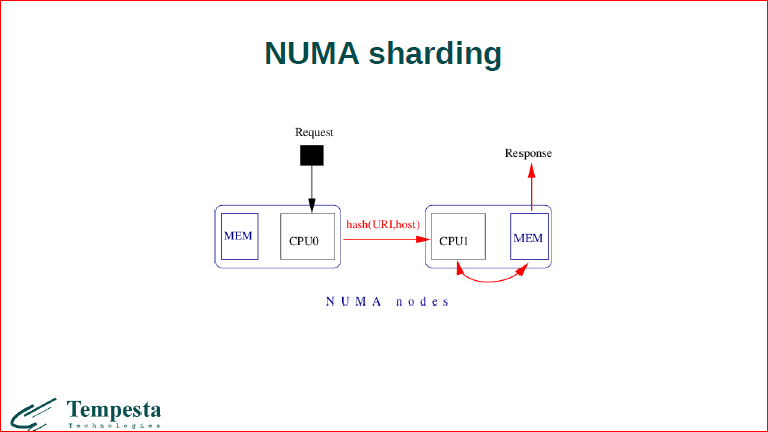
Собственно, это режим, когда у нас есть памяти мало, контента много, мы его разбиваем на разные участки, когда приходит запрос, он шардуется на тот или иной процессорный package.
И репликация – это когда у нас полностью весь контент копируется.

Мы используем достаточно специфичный индекс, это Cache conscious структура данных, которая знает о кэше, и мы стараемся в каждую кэш-линейку напихать как можно больше данных, и весь алгоритм работает с кэш-линейками.

Это то, как работает наше дерево, что из себя представляет burst hash trie. Это небольшая hash-табличка, всего из 16-ти элементов. Когда приходит некоторый ключик, мы из него высчитываем hash, берем последние 4 бита, и 4 бита нам определяют место в этой hash-таблице. Сейчас hash-таблица пуста, поэтому прямо здесь будет храниться наш ключ, т.е. как в массиве.
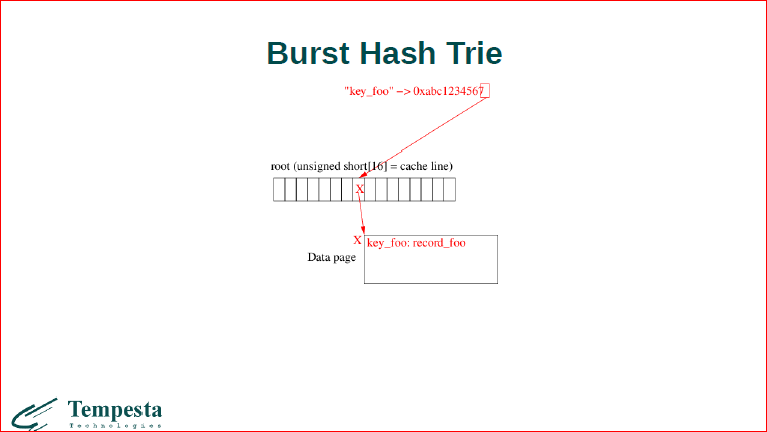
Далее, теперь если у нас приходят еще одни значения, то мы уже маленькие значения можем напихать в бакет, не больше одной страницы, работаем дальше с ним как со списком обычной hash-таблицы.
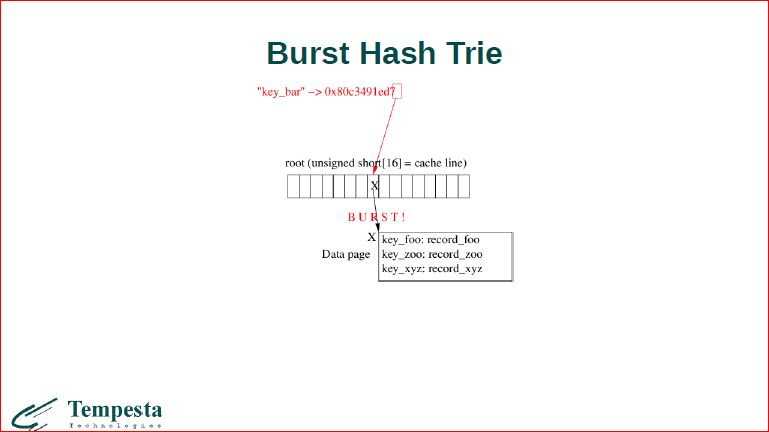
Потом, когда заканчивается у нас место в этом бакете, у нас происходит взрыв бакета.
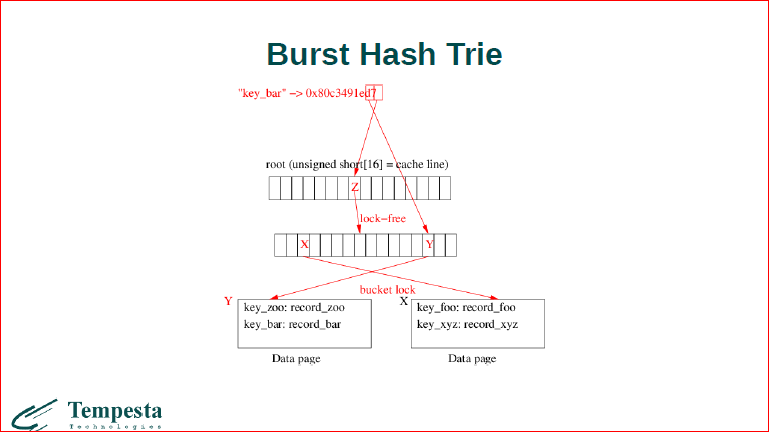
Это значит, что мы выращиваем 2-ой уровень hash-таблицы. Если у нас происходит коллизия, мы берем по первому элементу индекс в первом узле, по второму элементу мы определяем 2 других, т.е. это примерно работает как radix tree, только у него не константная высота. И мы должны перебросить все значения в новые бакеты.
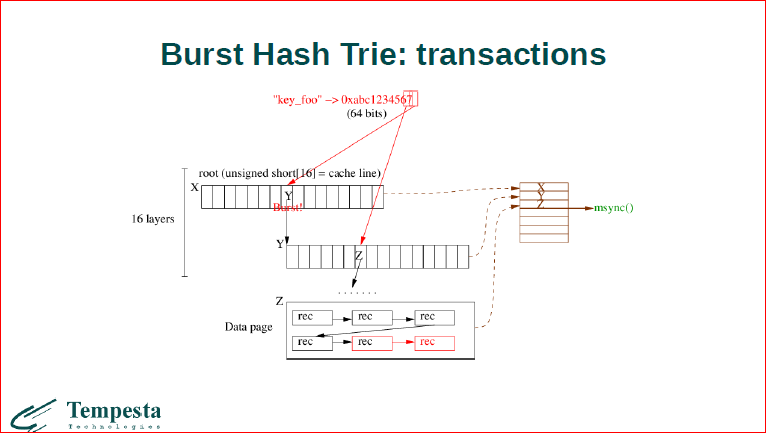
Теперь про транзакции. Когда у нас происходит изменение, оно пишется у нас в транзакционный лог внутри узлов дерева. Все это пишется в транзакционный лог, сами record’ы тоже пишутся транзакционный лог и, когда добавился полностью record, то индекс вместе с данными последовательно ложится на диск.
Всем спасибо!
Контакты
» krizhanovsky
» ak@tempesta-tech.com
» Исходный код проекта
» Блог
Этот доклад — расшифровка одного из лучших выступлений на профессиональной конференции разработчиков высоконагруженных систем HighLoad++.
Сейчас мы уже вовсю готовим конференцию 2017-года — самый большой HighLoad++
в истории. Если вам интересно и важна стоимость билетов — покупайте сейчас, пока цена ещё не высока!
Кстати, мы обязательно позовём в докладчики Александра Крижановского — на сегодняшний день это один из лучших профессионалов отрасли.
