Перевод статьи подготовлен в преддверии старта курса «Machine Learning» от OTUS.

В этом руководстве мы используем датасет Bitcoin vs USD.

Вышеприведенный датасет содержит ежедневную сводку цен, где колонка CHANGE – это изменение цены в процентах от цены за предыдущий день (PRICE) по отношению к новой (OPEN).
Цель: Чтобы упростить задачу, мы сосредоточимся на прогнозировании того, возрастет ли цена (CHANGE > 0) или упадет (CHANGE < 0) на следующий день. (Так мы потенциально сможем использовать предсказания «в реальной жизни»).
Требования
Для начала давайте импортируем нужные библиотеки:
А теперь вытащим данные через OpenBlender API.
Для начала определим параметры (в нашем случае это просто id датасета биткоина):
Примечание: вам нужно будет завести аккаунт на openblender.io (это бесплатно) и добавить токен (его вы найдете во вкладке «Учетная запись»):
А теперь давайте положим данные в Dataframe ‘df’:
И посмотрим на них:

Примечание: значения могут отличаться, поскольку датасет обновляется ежедневно!
Для начала нам нужно создать таргет для прогнозирования, который будет заключаться в том будет ли «CHANGE» увеличиваться или уменьшаться. Для этого добавим 'success_thr_over': 0 в параметры target threshold:
Если мы снова подтянем данные из API:
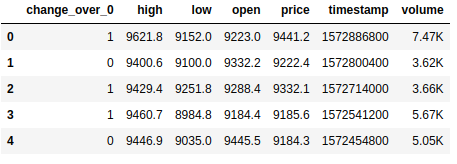
Признак «CHANGE» был заменен на новый признак ‘change_over_0’, который встает в значение 1, если «CHANGE» положителен и в 0, если нет. Это будет таргетом для машинного обучения.
Если мы хотим предсказать наблюдение на «завтра», мы не сможем использовать информацию из завтрашнего дня, поэтому давайте добавим задержку на один период.

Это просто выровняет ‘change_over_0’ с данными за предыдущий день (период) и изменит его имя на ‘TARGET_change_over_0’.
Давайте посмотрим на зависимость:
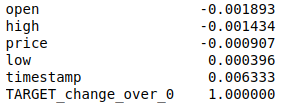
Они линейно независимы и вряд ли будут полезны.
После поиска зависимостей в OpenBlender, я нашел датасет Fox Business News, который поможет генерировать хорошие прогнозы для нашего таргета.

Нам нужно найти способ преобразовать значения столбца ‘title’ в числовые характеристики, подсчитав повторения слов и групп слов в сводке новостей, и сопоставить их по времени с нашим датасетом биткоина. Это проще, чем кажется.
Для начала нужно создать TextVectorizer для признака ‘title’ у новости:
Мы создадим векторизатор, чтобы получить все признаки как слова-токены в виде чисел. Выше мы указали следующее:
А теперь запустим это:
Ответ:
Был создан TextVectorizer, который сгенерировал 4270 n-грам по нашей конфигурации. Чуть позже нам понадобится сгенерированный id:
5dc1a404951629331f6359dd
Теперь нам нужно сопоставить по времени новостную сводку и данные о курсе биткоина. В целом, это значит, что нужно объединить два набора данных, используя в качестве ключа временную метку. Давайте добавим объединенные данные к нашим исходным параметрам извлечения данных:
Выше мы указали следующее:
Наконец, просто добавляем фильтр по дате 'date_filter', начиная с 20 августа, поскольку именно тогда Fox News начали сбор данных, и ‘drop_non_numeric’, чтобы мы получали только цифры:
Примечание: Я указал 4 ноября в качестве ‘end_date’, поскольку это был день, когда я писал этот код, вы можете изменить дату.
Давайте снова получим данные:
(57, 2115)

Теперь у нас есть больше 2000 признаков с токенами и 57 наблюдений.
Теперь у нас, наконец, есть чистый датасет, и он выглядит именно так, как нам нужно, со смещением таргета по времени и сопоставленными числовыми данными.
Давайте посмотрим на самые высокие корреляции с ‘Target_change_over_0’:
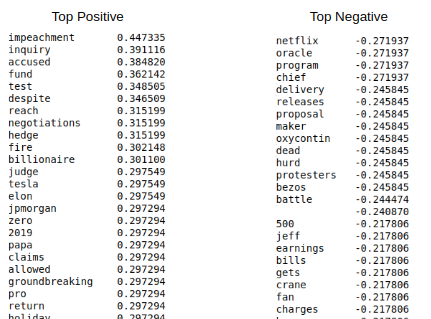
Теперь у нас есть несколько коррелирующих признаков. Давайте разделим датасет на тренировочный и тестовый в хронологическом порядке, чтобы мы могли обучать модель на ранних наблюдениях и тестировать на поздних.

У нас есть 40 наблюдений для обучения и 17 для тестирования.
Теперь импортируем необходимые библиотеки:
А теперь давайте используем случайный лес (RandomForest) и сделаем предсказание:
Чтобы было проще разобраться, давайте поместим предсказания и y_test в Dataframe:
Наш реальный ‘y_test’ – бинарный, но прогнозы у нас типа float, поэтому давайте округлим их, предположив, что если они больше 0.5, то это означает рост цены, а если меньше 0.5 – понижение.
Теперь, чтобы лучше понимать полученные результаты, получим AUC, матрицу ошибок и показатель точности:

Мы получили 64,7% правильных предсказаний с 0.65 AUC.
Узнать подробнее о курсе.
Задача
В этом руководстве мы используем датасет Bitcoin vs USD.
Вышеприведенный датасет содержит ежедневную сводку цен, где колонка CHANGE – это изменение цены в процентах от цены за предыдущий день (PRICE) по отношению к новой (OPEN).
Цель: Чтобы упростить задачу, мы сосредоточимся на прогнозировании того, возрастет ли цена (CHANGE > 0) или упадет (CHANGE < 0) на следующий день. (Так мы потенциально сможем использовать предсказания «в реальной жизни»).
Требования
- В системе должен быть установлен Python 2.6+ или 3.1+
- Установите pandas, sklearn и openblender (с помощью pip)
$ pip install pandas OpenBlender scikit-learnШаг 1. Получим данные о биткоине
Для начала давайте импортируем нужные библиотеки:
import OpenBlender
import pandas as pd
import jsonА теперь вытащим данные через OpenBlender API.
Для начала определим параметры (в нашем случае это просто id датасета биткоина):
# It only contains the id, we'll add more parameters later.
parameters = {
'id_dataset':'5d4c3af79516290b01c83f51'
}Примечание: вам нужно будет завести аккаунт на openblender.io (это бесплатно) и добавить токен (его вы найдете во вкладке «Учетная запись»):
parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51'
}А теперь давайте положим данные в Dataframe ‘df’:
# This function pulls the data and orders by timestamp
def pullObservationsToDF(parameters):
action = 'API_getObservationsFromDataset'
df = pd.read_json(json.dumps(OpenBlender.call(action,parameters)['sample']), convert_dates=False,convert_axes=False) .sort_values('timestamp', ascending=False)
df.reset_index(drop=True, inplace=True)
return df
df = pullObservationsToDF(parameters)И посмотрим на них:
Примечание: значения могут отличаться, поскольку датасет обновляется ежедневно!
Шаг 2. Подготовка данных
Для начала нам нужно создать таргет для прогнозирования, который будет заключаться в том будет ли «CHANGE» увеличиваться или уменьшаться. Для этого добавим 'success_thr_over': 0 в параметры target threshold:
parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change', 'success_thr_over': 0}
}Если мы снова подтянем данные из API:
df = pullObservationsToDF(parameters)
df.head() Признак «CHANGE» был заменен на новый признак ‘change_over_0’, который встает в значение 1, если «CHANGE» положителен и в 0, если нет. Это будет таргетом для машинного обучения.
Если мы хотим предсказать наблюдение на «завтра», мы не сможем использовать информацию из завтрашнего дня, поэтому давайте добавим задержку на один период.
parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change','success_thr_over' : 0},
'lag_target_feature':{'feature':'change_over_0', 'periods' : 1}
}
df = pullObservationsToDF(parameters)
df.head()Это просто выровняет ‘change_over_0’ с данными за предыдущий день (период) и изменит его имя на ‘TARGET_change_over_0’.
Давайте посмотрим на зависимость:
target_variable = 'TARGET_change_over_0'
df = df.dropna()
df.corr()[target_variable].sort_values()Они линейно независимы и вряд ли будут полезны.
Шаг 3. Получим данные Business News
После поиска зависимостей в OpenBlender, я нашел датасет Fox Business News, который поможет генерировать хорошие прогнозы для нашего таргета.
Нам нужно найти способ преобразовать значения столбца ‘title’ в числовые характеристики, подсчитав повторения слов и групп слов в сводке новостей, и сопоставить их по времени с нашим датасетом биткоина. Это проще, чем кажется.
Для начала нужно создать TextVectorizer для признака ‘title’ у новости:
action = 'API_createTextVectorizer'
vectorizer_parameters = {
'token' : 'your_token',
'name' : 'Fox Business TextVectorizer',
'sources':[{'id_dataset' : '5d571f9e9516293a12ad4f6d',
'features' : ['title']}],
'ngram_range' : {'min' : 1, 'max' : 2},
'language' : 'en',
'remove_stop_words' : 'on',
'min_count_limit' : 2
}Мы создадим векторизатор, чтобы получить все признаки как слова-токены в виде чисел. Выше мы указали следующее:
- name: назовем его ‘Fox Business TextVectorizer’;
- anchor: id датасета и названия признаков, которые нам нужно будет использовать в качестве источника (в нашем случае только столбец ‘title’);
- ngram_range: минимальная и максимальная длина набора слов для токенизации;
- language: Английский
- remove_stop_words: чтобы удалить стоп-слова из источника;
- min_count_limit: минимальное количество повторений, которое следует считать за токен (единичные вхождения редко полезны).
А теперь запустим это:
res = OpenBlender.call(action, vectorizer_parameters)
resОтвет:
{
'message' : 'TextVectorizer created successfully.'
'id_textVectorizer' : '5dc1a404951629331f6359dd',
'num_ngrams': 4270
}Был создан TextVectorizer, который сгенерировал 4270 n-грам по нашей конфигурации. Чуть позже нам понадобится сгенерированный id:
5dc1a404951629331f6359dd
Шаг 4. Совместим новостную сводку с датасетом биткоина
Теперь нам нужно сопоставить по времени новостную сводку и данные о курсе биткоина. В целом, это значит, что нужно объединить два набора данных, используя в качестве ключа временную метку. Давайте добавим объединенные данные к нашим исходным параметрам извлечения данных:
parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'specifications':{'time_interval_size' : 3600*12 }}]
}Выше мы указали следующее:
- id_blend: id нашего textVectorizer;
- blend_type: ‘text_ts’, чтобы Python понял, что это смесь текста и временной метки;
- restriction: ‘predictive’, чтобы не происходило «смешивания» новостей из будущего со всеми наблюдениями, а только с теми, которые были опубликованы раньше указанного времени.
- blend_class : ‘closest_observation’, чтобы «смешивались» только самые близкие по времени наблюдения;
- specifications: максимально возможное количество прошедшего времени для переноса наблюдения, в данном случае 12 часов (3600*12). Это значит, что каждое наблюдение за ценой биткоина будет предсказано на основании новостей последних 12 часов.
Наконец, просто добавляем фильтр по дате 'date_filter', начиная с 20 августа, поскольку именно тогда Fox News начали сбор данных, и ‘drop_non_numeric’, чтобы мы получали только цифры:
parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'blend_class' : 'closest_observation',
'specifications':{'time_interval_size' : 3600*12 }}],
'date_filter':{'start_date':'2019-08-20T16:59:35.825Z',
'end_date':'2019-11-04T17:59:35.825Z'},
'drop_non_numeric' : 1
}Примечание: Я указал 4 ноября в качестве ‘end_date’, поскольку это был день, когда я писал этот код, вы можете изменить дату.
Давайте снова получим данные:
df = pullObservationsToDF(parameters)
print(df.shape)
df.head()(57, 2115)
Теперь у нас есть больше 2000 признаков с токенами и 57 наблюдений.
Шаг 5. Применим ML к таргету предсказания
Теперь у нас, наконец, есть чистый датасет, и он выглядит именно так, как нам нужно, со смещением таргета по времени и сопоставленными числовыми данными.
Давайте посмотрим на самые высокие корреляции с ‘Target_change_over_0’:
Теперь у нас есть несколько коррелирующих признаков. Давайте разделим датасет на тренировочный и тестовый в хронологическом порядке, чтобы мы могли обучать модель на ранних наблюдениях и тестировать на поздних.
X = df.loc[:, df.columns != target_variable].values
y = df.loc[:,[target_variable]].values
div = int(round(len(X) * 0.29))
# We take the first observations as test and the last as train because the dataset is ordered by timestamp descending.
X_test = X[:div]
y_test = y[:div]
print(X_test.shape)
print(y_test.shape)
X_train = X[div:]
y_train = y[div:]
print(X_train.shape)
print(y_train.shape)У нас есть 40 наблюдений для обучения и 17 для тестирования.
Теперь импортируем необходимые библиотеки:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
from sklearn import metricsА теперь давайте используем случайный лес (RandomForest) и сделаем предсказание:
rf = RandomForestRegressor(n_estimators = 1000)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)Чтобы было проще разобраться, давайте поместим предсказания и y_test в Dataframe:
df_res = pd.DataFrame({'y_test':y_test[:,0], 'y_pred':y_pred})
df_res.head()Наш реальный ‘y_test’ – бинарный, но прогнозы у нас типа float, поэтому давайте округлим их, предположив, что если они больше 0.5, то это означает рост цены, а если меньше 0.5 – понижение.
threshold = 0.5
preds = [1 if val > threshold else 0 for val in df_res['y_pred']]Теперь, чтобы лучше понимать полученные результаты, получим AUC, матрицу ошибок и показатель точности:
print(roc_auc_score(preds, df_res['y_test']))
print(metrics.confusion_matrix(preds, df_res['y_test']))
print(accuracy_score(preds, df_res['y_test']))Мы получили 64,7% правильных предсказаний с 0.65 AUC.
- 9 раз мы предсказали понижение, и цена уменьшилась (верно);
- 5 раз мы предсказали понижение, а цена увеличилась (неверно);
- 1 раз мы предсказали повышение, а цена уменьшилась неверно);
- 2 раза мы предсказали повышение, и цена увеличилась (верно).
Узнать подробнее о курсе.
