
Библиотека puppeteer для Node.js позволяет автоматизировать работу с браузером Google Chrome. В частности, с помощью
Сегодня мы поговорим о создании веб-скрапера на базе Node.js и
Перед началом работы вам понадобится Node 8+. Найти и загрузить его можно здесь, выбрав текущую (Current) версию. Если вы никогда раньше не работали с Node, взгляните на эти учебные курсы или поищите другие материалы, благо, их в Сети предостаточно.
После установки Node создайте папку для проекта и установите
После установки
Для начала создадим файл
Построчно разберём этот код. Сначала покажем общую картину.
В этой строке мы подключаем ранее установленную библиотеку
Тут представлена главная функция,
В этой строке мы вызываем функцию
Важно обратить внимание на то, что функция
Благодаря использованию при определении функции ключевого слова
Теперь разберём код функции
Тут мы запускаем
Здесь мы создаём в браузере, управляемом посредством программного кода, новую страницу. А именно, запрашиваем эту операцию, ожидаем её завершения и записываем ссылку на страницу в константу
Используя переменную
Здесь мы запрашиваем у
Функция
Вышеописанный код, сохранённый в файле
Вот что получится после того, как он успешно отработает:
Замечательно! А теперь, чтобы было веселей (и чтобы облегчить отладку), мы можем выполнить те же действия, запустив Chrome в обычном режиме.
Что бы это значило? Попробуйте и увидите сами. Для этого нужно заменить эту строку кода:
На эту:
Сохраним файл и снова его запустим с помощью Node:
Здорово, правда? Передавая объект
Прежде чем идти дальше, сделаем ещё кое-что. Вы заметили, что скриншот, который делает программа, включает в себя лишь часть страницы? Так происходит из-за того, что окно браузера немного меньше размера веб-страницы. Исправить это можно с помощью следующей строчки, меняющей размер окна:
Её надо добавить в код сразу после команды перехода по URL. Это приведёт к тому, что программа сделает скриншот, который выглядит гораздо лучше:
Вот как будет выглядеть итоговый вариант кода:
Теперь, когда вы освоили основы автоматизации Chrome с помощью
Сначала стоит взглянуть на документацию к
Мы будем собирать данные с сайта Books To Scrape. Это — имитация электронного книжного магазина, созданная для экспериментов по веб-скрапингу.
В той же директории, где лежит файл
В идеале, после разбора первого примера, вы уже должны понять то, как устроен этот код. Но если это не так — ничего страшного.
В этом фрагменте мы подключаем ранее установленный
Проверим этот код, добавив в функцию
После этого запустим программу командой
Сначала надо создать экземпляр браузера, открыть новую страницу и перейти по URL. Вот как мы всё это сделаем:
Разберём этот код.
В этой строке мы создаём экземпляр браузера и устанавливаем параметр
Здесь создаём новую страницу в браузере.
Переходим по адресу
Тут добавляем задержку в 1000 миллисекунд для того, чтобы дать браузеру время на полную загрузку страницы, но обычно этот шаг можно опустить.
Здесь закрываем браузер и возвращаем результат.
Предварительная подготовка завершена, теперь займёмся скрапингом.
Как вы уже, наверное, поняли, на сайте Books To Scrape имеется большой каталог настоящих книг, снабжённых условными данными. Мы собираемся взять первую книгу, расположенную на странице, и вернуть её название и цену. Вот домашняя страница сайта. Щёлкнем по первой книге (она выделена красной рамкой).
В документации по
Конструкция вида
Очень хорошо то, что инструменты разработчика Google Chrome позволяют, без особых сложностей, определить селектор конкретного элемента. Для того, чтобы это сделать, достаточно щёлкнуть правой кнопкой мыши по изображению и выбрать команду
Эта команда откроет панель
Отлично! Теперь у нас имеется селектор и всё готово для того, чтобы сформировать метод
Теперь программа имитирует щелчок по первому изображению товара, что приводит к открытию страницы этого товара.
На этой новой странице нас интересует название книги и её цена. Они выделены на нижеприведённом рисунке.
Для того, чтобы добраться до этих значений, мы будем пользоваться методом
Для начала вызовем метод
В этой функции мы можем выбирать необходимые элементы. Для того, чтобы понять, как описать то, что нам нужно, снова воспользуемся инструментами разработчика Chrome. Для этого щёлкнем правой кнопкой по названию книги и выберем команду
В панели
Так как нам нужен текст, содержащийся в этом элементе, нам понадобится воспользоваться свойством
Такой же подход поможет нам выяснить то, как взять со страницы цену книги.
Можно заметить, что строчке с ценой соответствует класс
Теперь, когда мы вытащили со страницы название книги и её цену, мы можем возвратить всё это из функции в виде объекта:
В результате получается следующий код:
Здесь мы считываем со страницы название книги и цену, сохраняем их в объекте и возвращаем этот объект, что приводит к записи его в
Теперь осталось лишь вернуть константу
Полный код этого примера будет выглядеть так:
Теперь можно запустить программу с помощью Node:
Если всё сделано правильно, в консоль будет выведено название книги и её цена:
Собственно говоря, всё это и есть веб-скрапинг и вы только что сделали первые шаги в этом занятии.
Тут у вас могут появиться вполне резонные вопросы: «Зачем щёлкать по ссылке, ведущей к странице книги, если и её название, и цена, отображаются на домашней странице? Почему бы не взять их прямо оттуда? И, если мы смогли это сделать, почему бы не прочитать названия и цены всех книг?».
Ответ на эти вопросы заключается в том, что существует множество подходов к веб-скрапингу! К тому же, если ограничиться данными, выводимыми на домашней странице, можно столкнуться с тем, что названия книг будут укорочены. Однако, все эти размышления дают вам отличную возможность попрактиковаться.
Ваша цель — считать все заголовки книг и их цены с домашней страницы и вернуть их в виде массива объектов. Вот какой массив получился у меня:

Можете приступать. Не читайте пока дальше, попробуйте сделать всё сами. Надо сказать, что эта задача очень похожа на ту, которую мы только что решили.
Получилось? Если нет — тогда вот подсказка.
Главное отличие этой задачи от предыдущего примера заключается в том, что тут нам надо пройтись по списку данных. Вот как это можно сделать:
Если и сейчас вам не удаётся решить задачу, в этом нет ничего страшного. Это — вопрос практики. Вот один из возможных вариантов её решения.
Из этого материала вы узнали о том как пользоваться браузером Google Chrome и библиотекой Puppeteer для создания системы веб-скрапинга. А именно, мы рассмотрели структуру кода, способы программного управления браузером, методику создания копий экрана, методы имитации работы пользователя со страницей и подходы к чтению и сохранению данных, размещаемых на веб-страницах. Если это было ваше первое знакомство с веб-скрапингом, надеемся, теперь у вас есть всё необходимое для того, чтобы вытащить из интернета всё, что вам нужно.
Уважаемые читатели! Пользуетесь ли вы библиотекой Puppeteer и браузером Google Chrome без пользовательского интерфейса?
puppeteer можно создавать программы для автоматического сбора данных с веб-сайтов, так называемые веб-скраперы, имитирующие действия обычного пользователя. В подобных сценариях может применяться браузер без пользовательского интерфейса, так называемый «Headless Chrome». Используя puppeteer, можно управлять и браузером, который запущен в обычном режиме, что особенно полезно при отладке программ. Сегодня мы поговорим о создании веб-скрапера на базе Node.js и
puppeteer. Автор материала стремился к тому, чтобы статья была интересна как можно более широкой аудитории программистов, поэтому пользу из него извлекут как те веб-разработчики, которые уже имеют некоторый опыт работы с puppeteer, так и те, которые впервые сталкиваются с таким понятием, как «Headless Chrome».Предварительная подготовка
Перед началом работы вам понадобится Node 8+. Найти и загрузить его можно здесь, выбрав текущую (Current) версию. Если вы никогда раньше не работали с Node, взгляните на эти учебные курсы или поищите другие материалы, благо, их в Сети предостаточно.
После установки Node создайте папку для проекта и установите
puppeteer. Вместе с ним будет установлена и актуальная версия Chromium, который гарантированно будет работать с интересующим нас API. Сделать это можно с помощью следующей команды:npm install --save puppeteerПример №1: создание копий экрана
После установки
puppeteer разберём простой пример. Он, с небольшими изменениями, повторяет документацию к библиотеке. Код, который мы сейчас рассмотрим, делает скриншот заданной веб-страницы.Для начала создадим файл
test.js и поместим в него следующее:const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://google.com');
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();Построчно разберём этот код. Сначала покажем общую картину.
const puppeteer = require('puppeteer');В этой строке мы подключаем ранее установленную библиотеку
puppeteer в качестве зависимости.async function getPic() {
...
}Тут представлена главная функция,
getPic(). Эта функция содержит код, автоматизирующий работу с браузером.getPic();В этой строке мы вызываем функцию
getPic(), то есть, выполняем её.Важно обратить внимание на то, что функция
getPic() является асинхронной, она определена с ключевым словом async. В ней используется конструкция async / await из ES 2017. Так как getPic() — функция асинхронная, она, при вызове, возвращает объект Promise. Такие объекты обычно называют «промисами». Когда функция, определённая с ключевым словом async, завершает работу и возвращает некое значение, промис либо будет разрешён (в случае успешного завершения операции), либо отклонён (если произойдёт ошибка).Благодаря использованию при определении функции ключевого слова
async, мы можем выполнять в ней вызовы других функций с ключевым словом await. Оно приостанавливает выполнение функции и позволяет дождаться разрешения соответствующего промиса, после чего работа функции продолжится. Если это всё вам пока не понятно — просто читайте дальше и постепенно всё начнёт становиться на свои места.Теперь разберём код функции
getPic().const browser = await puppeteer.launch();Тут мы запускаем
puppeteer. Фактически это означает, что мы запускаем экземпляр браузера Chrome и записываем ссылку на него в только что созданную константу browser. Так как в этой строке использовано ключевое слово await, выполнение основной функции будет приостановлено до разрешения соответствующего промиса. В данном случае это означает ожидание либо успешного запуска экземпляра Chrome, либо возникновения ошибки.const page = await browser.newPage();Здесь мы создаём в браузере, управляемом посредством программного кода, новую страницу. А именно, запрашиваем эту операцию, ожидаем её завершения и записываем ссылку на страницу в константу
page.await page.goto('https://google.com');Используя переменную
page, созданную в предыдущей строке, мы можем дать странице команду по переходу на указанный URL. В данном примере мы переходим на https://google.com. Выполнение кода, как и в предыдущих строках, приостановится до завершения операции.await page.screenshot({path: 'google.png'});Здесь мы запрашиваем у
puppeteer создание скриншота текущей страницы, представленной константой page. Метод screenshot() принимает, в виде параметра, объект. Тут можно указать путь, по которому нужно сохранить скриншот в формате .png. Опять же, здесь используется ключевое слово await, что приводит к приостановке выполнения функции до завершения операции.await browser.close();Функция
getPic() завершает работу и мы закрываем браузер.Запуск примера
Вышеописанный код, сохранённый в файле
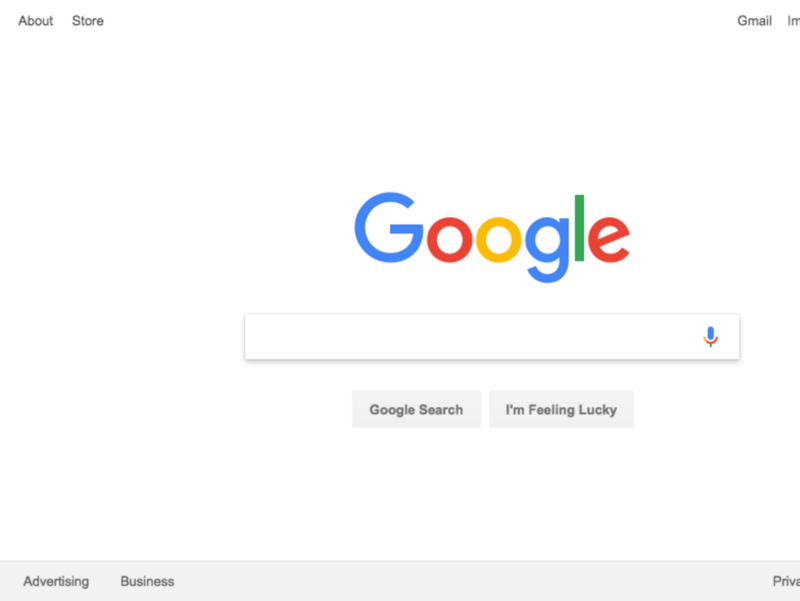
test.js, можно запустить с помощью Node следующим образом:node test.jsВот что получится после того, как он успешно отработает:
Замечательно! А теперь, чтобы было веселей (и чтобы облегчить отладку), мы можем выполнить те же действия, запустив Chrome в обычном режиме.
Что бы это значило? Попробуйте и увидите сами. Для этого нужно заменить эту строку кода:
const browser = await puppeteer.launch();На эту:
const browser = await puppeteer.launch({headless: false});Сохраним файл и снова его запустим с помощью Node:
node test.jsЗдорово, правда? Передавая объект
{headless: false} в качестве параметра при запуске браузера мы можем наблюдать за тем, как код управляет работой Google Chrome.Прежде чем идти дальше, сделаем ещё кое-что. Вы заметили, что скриншот, который делает программа, включает в себя лишь часть страницы? Так происходит из-за того, что окно браузера немного меньше размера веб-страницы. Исправить это можно с помощью следующей строчки, меняющей размер окна:
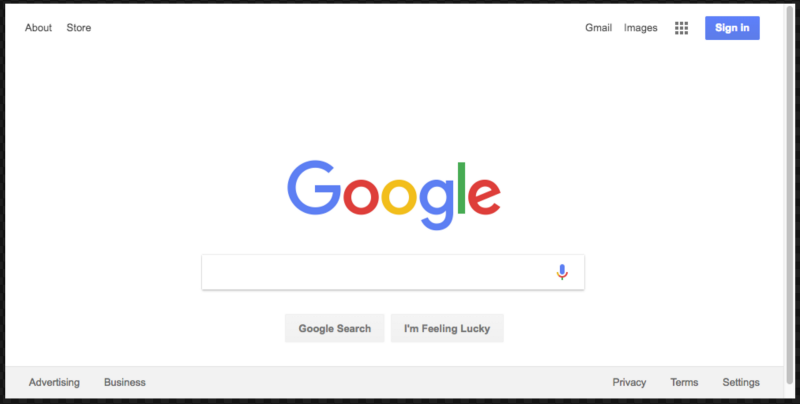
await page.setViewport({width: 1000, height: 500})Её надо добавить в код сразу после команды перехода по URL. Это приведёт к тому, что программа сделает скриншот, который выглядит гораздо лучше:
Вот как будет выглядеть итоговый вариант кода:
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://google.com');
await page.setViewport({width: 1000, height: 500})
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();Пример №2: веб-скрапинг
Теперь, когда вы освоили основы автоматизации Chrome с помощью
puppeteer, разберём более сложный пример, в котором займёмся сбором данных с веб-страниц.Сначала стоит взглянуть на документацию к
puppeteer. Можно обратить внимание на то, что тут имеется огромное количество различных методов, которые позволяют нам не только имитировать щелчки мышью по элементам страниц, но и заполнять формы, и читать со страниц данные.Мы будем собирать данные с сайта Books To Scrape. Это — имитация электронного книжного магазина, созданная для экспериментов по веб-скрапингу.
В той же директории, где лежит файл
test.js, создайте файл scrape.js и вставьте туда следующую заготовку:const puppeteer = require('puppeteer');
let scrape = async () => {
// Здесь выполняются операции скрапинга...
// Возврат значения
};
scrape().then((value) => {
console.log(value); // Получилось!
});В идеале, после разбора первого примера, вы уже должны понять то, как устроен этот код. Но если это не так — ничего страшного.
В этом фрагменте мы подключаем ранее установленный
puppeteer. Далее, у нас имеется функция scrape(), в которую, ниже, мы добавим код для скрапинга. Эта функция возвратит некое значение. И, наконец, мы вызываем функцию scrape() и работаем с тем, что она возвратила. В данном случае — просто выводим это в консоль.Проверим этот код, добавив в функцию
scrape() возврат строки:let scrape = async () => {
return 'test';
};После этого запустим программу командой
node scrape.js. В консоли должно появиться слово test. Работоспособность кода мы подтвердили, нужное значение попадает в консоль. Теперь можно заняться веб-скрапингом.▍Шаг 1: настройка
Сначала надо создать экземпляр браузера, открыть новую страницу и перейти по URL. Вот как мы всё это сделаем:
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.waitFor(1000);
// Код для скрапинга
browser.close();
return result;
};Разберём этот код.
const browser = await puppeteer.launch({headless: false});В этой строке мы создаём экземпляр браузера и устанавливаем параметр
headless в false. Это позволяет нам наблюдать за тем, что происходит.const page = await browser.newPage();Здесь создаём новую страницу в браузере.
await page.goto('http://books.toscrape.com/');Переходим по адресу
http://books.toscrape.com/.await page.waitFor(1000);Тут добавляем задержку в 1000 миллисекунд для того, чтобы дать браузеру время на полную загрузку страницы, но обычно этот шаг можно опустить.
browser.close();
return result;Здесь закрываем браузер и возвращаем результат.
Предварительная подготовка завершена, теперь займёмся скрапингом.
▍Шаг 2: скрапинг
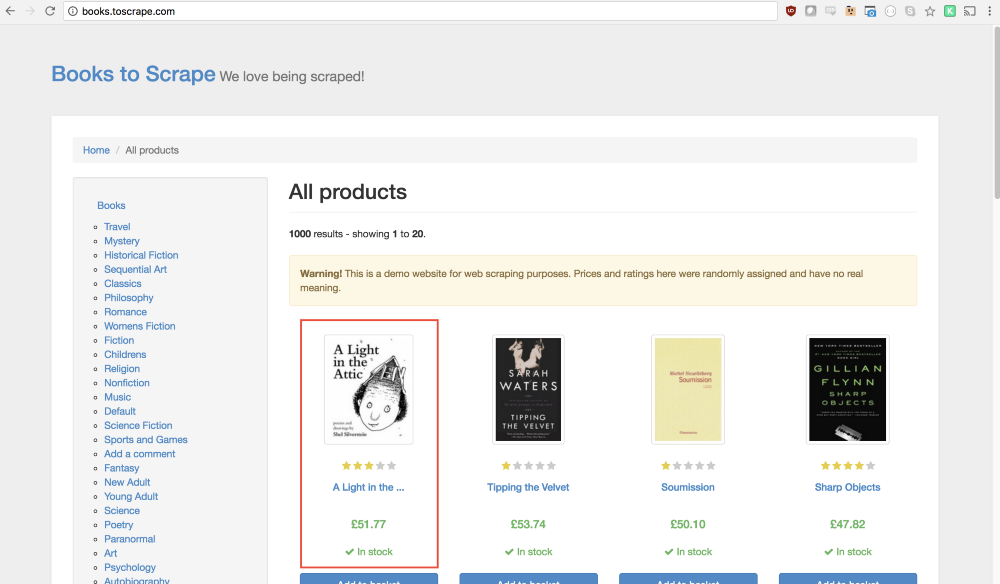
Как вы уже, наверное, поняли, на сайте Books To Scrape имеется большой каталог настоящих книг, снабжённых условными данными. Мы собираемся взять первую книгу, расположенную на странице, и вернуть её название и цену. Вот домашняя страница сайта. Щёлкнем по первой книге (она выделена красной рамкой).
В документации по
puppeteer можно найти метод, который позволяет имитировать щелчки мышью по странице:page.click(selector[, options])Конструкция вида
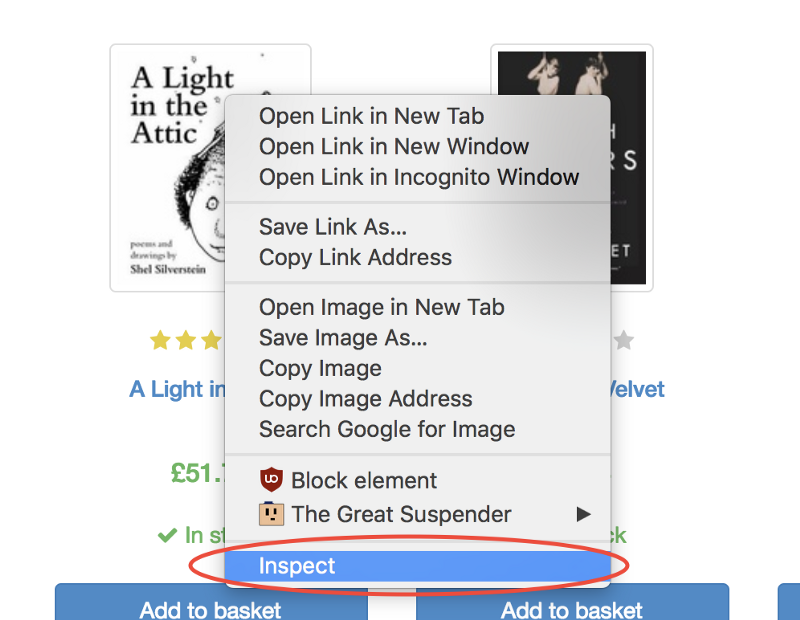
selector <string> представляет собой селектор для поиска элемента, по которому нужно щёлкнуть. Если обнаружено несколько элементов, удовлетворяющих селектору, то щелчок будет сделан по первому из них.Очень хорошо то, что инструменты разработчика Google Chrome позволяют, без особых сложностей, определить селектор конкретного элемента. Для того, чтобы это сделать, достаточно щёлкнуть правой кнопкой мыши по изображению и выбрать команду
Inspect (Просмотреть код).Эта команда откроет панель
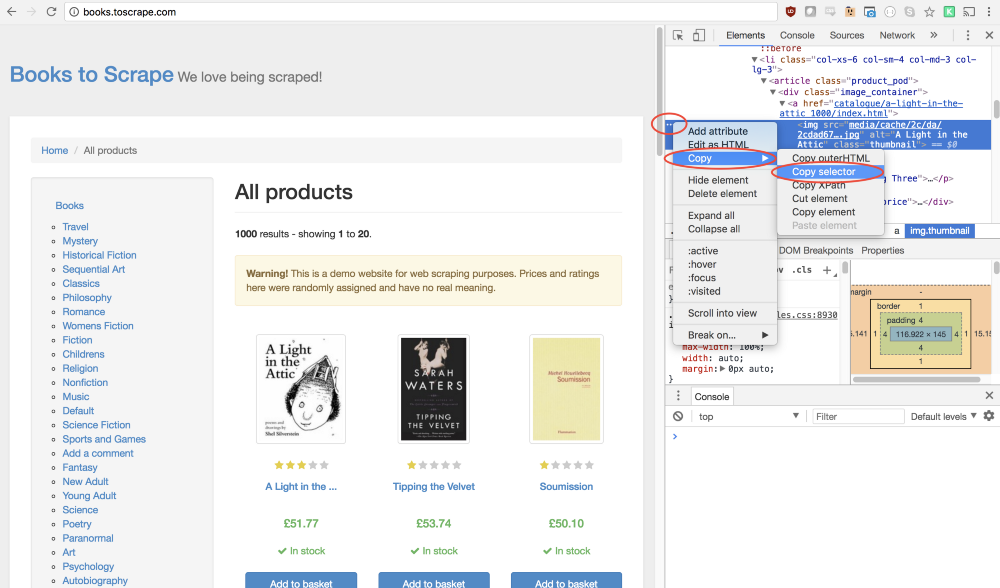
Elements (Элементы), в которой будет представлен код страницы, фрагмент которого, соответствующий интересующему нас элементу, будет выделен. После этого можно щёлкнуть по кнопке с тремя точками слева и в появившемся меню выбрать команду Copy → Copy selector (Копировать → Копировать селектор).Отлично! Теперь у нас имеется селектор и всё готово для того, чтобы сформировать метод
click и вставить его в программу. Вот как это будет выглядеть:await page.click('#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img');Теперь программа имитирует щелчок по первому изображению товара, что приводит к открытию страницы этого товара.
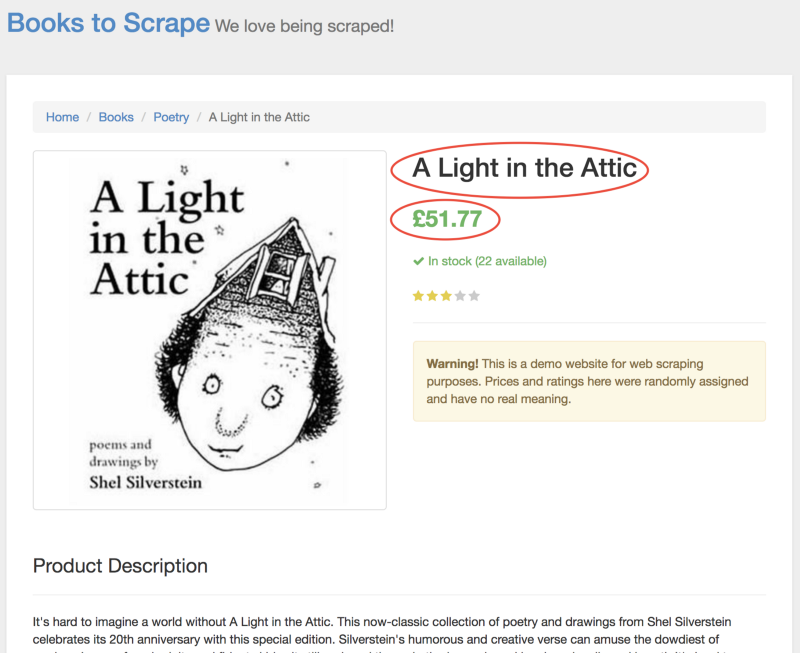
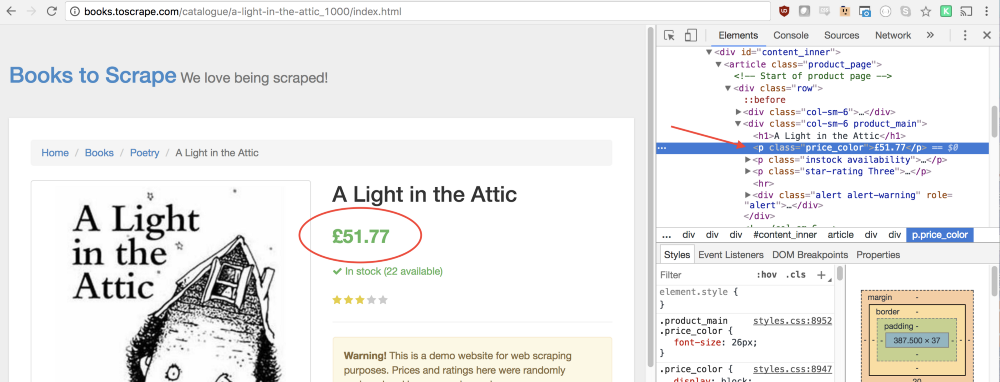
На этой новой странице нас интересует название книги и её цена. Они выделены на нижеприведённом рисунке.
Для того, чтобы добраться до этих значений, мы будем пользоваться методом
page.evaluate(). Этот метод позволяет использовать методы JavaScript для работы с DOM, наподобие querySelector().Для начала вызовем метод
page.evaluate() и присвоим возвращённое им значение константе result:const result = await page.evaluate(() => {
// что-нибудь возвращаем
});В этой функции мы можем выбирать необходимые элементы. Для того, чтобы понять, как описать то, что нам нужно, снова воспользуемся инструментами разработчика Chrome. Для этого щёлкнем правой кнопкой по названию книги и выберем команду
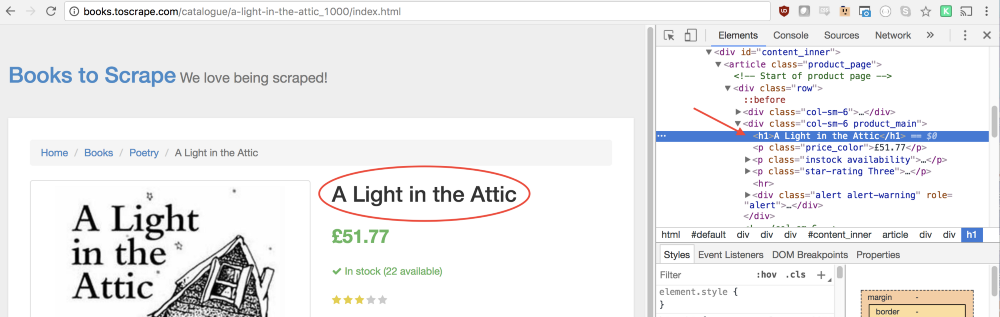
Inspect (Просмотреть код).В панели
Elements (Элементы) можно увидеть, что название книги — это обычный заголовок первого уровня, h1. Выбрать этот элемент можно с помощью следующего кода:let title = document.querySelector('h1');Так как нам нужен текст, содержащийся в этом элементе, нам понадобится воспользоваться свойством
.innerText. В итоге приходим к следующей конструкции:let title = document.querySelector('h1').innerText;Такой же подход поможет нам выяснить то, как взять со страницы цену книги.
Можно заметить, что строчке с ценой соответствует класс
price_color. Мы можем использовать этот класс для того, чтобы выбрать элемент и прочитать содержащийся в нём текст:let price = document.querySelector('.price_color').innerText;Теперь, когда мы вытащили со страницы название книги и её цену, мы можем возвратить всё это из функции в виде объекта:
return {
title,
price
}В результате получается следующий код:
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}
});Здесь мы считываем со страницы название книги и цену, сохраняем их в объекте и возвращаем этот объект, что приводит к записи его в
result.Теперь осталось лишь вернуть константу
result и вывести её содержимое в консоль.return result;Полный код этого примера будет выглядеть так:
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.click('#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img');
await page.waitFor(1000);
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}
});
browser.close();
return result;
};
scrape().then((value) => {
console.log(value); // Получилось!
});Теперь можно запустить программу с помощью Node:
node scrape.jsЕсли всё сделано правильно, в консоль будет выведено название книги и её цена:
{ title: 'A Light in the Attic', price: '£51.77' }Собственно говоря, всё это и есть веб-скрапинг и вы только что сделали первые шаги в этом занятии.
Пример №3: улучшаем программу
Тут у вас могут появиться вполне резонные вопросы: «Зачем щёлкать по ссылке, ведущей к странице книги, если и её название, и цена, отображаются на домашней странице? Почему бы не взять их прямо оттуда? И, если мы смогли это сделать, почему бы не прочитать названия и цены всех книг?».
Ответ на эти вопросы заключается в том, что существует множество подходов к веб-скрапингу! К тому же, если ограничиться данными, выводимыми на домашней странице, можно столкнуться с тем, что названия книг будут укорочены. Однако, все эти размышления дают вам отличную возможность попрактиковаться.
▍Задача
Ваша цель — считать все заголовки книг и их цены с домашней страницы и вернуть их в виде массива объектов. Вот какой массив получился у меня:
Можете приступать. Не читайте пока дальше, попробуйте сделать всё сами. Надо сказать, что эта задача очень похожа на ту, которую мы только что решили.
Получилось? Если нет — тогда вот подсказка.
▍Подсказка
Главное отличие этой задачи от предыдущего примера заключается в том, что тут нам надо пройтись по списку данных. Вот как это можно сделать:
const result = await page.evaluate(() => {
let data = []; // Создаём пустой массив
let elements = document.querySelectorAll('xxx'); // Выбираем всё
// Проходимся в цикле по всем товарам
// Выбираем название
// Выбираем цену
data.push({title, price}); // Помещаем данные в массив
return data; // Возвращаем массив с данными
});Если и сейчас вам не удаётся решить задачу, в этом нет ничего страшного. Это — вопрос практики. Вот один из возможных вариантов её решения.
▍Решение задачи
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
const result = await page.evaluate(() => {
let data = []; // Создаём пустой массив для хранения данных
let elements = document.querySelectorAll('.product_pod'); // Выбираем все товары
for (var element of elements){ // Проходимся в цикле по каждому товару
let title = element.childNodes[5].innerText; // Выбираем название
let price = element.childNodes[7].children[0].innerText; // Выбираем цену
data.push({title, price}); // Помещаем объект с данными в массив
}
return data; // Возвращаем массив
});
browser.close();
return result; // Возвращаем данные
};
scrape().then((value) => {
console.log(value); // Получилось!
});Итоги
Из этого материала вы узнали о том как пользоваться браузером Google Chrome и библиотекой Puppeteer для создания системы веб-скрапинга. А именно, мы рассмотрели структуру кода, способы программного управления браузером, методику создания копий экрана, методы имитации работы пользователя со страницей и подходы к чтению и сохранению данных, размещаемых на веб-страницах. Если это было ваше первое знакомство с веб-скрапингом, надеемся, теперь у вас есть всё необходимое для того, чтобы вытащить из интернета всё, что вам нужно.
Уважаемые читатели! Пользуетесь ли вы библиотекой Puppeteer и браузером Google Chrome без пользовательского интерфейса?
