

Экспериментальный проект по максимальному уменьшению ELF-файла с программой Hello, World! под целевую систему Linux x64 с помощью NASM. В предыдущем опыте начала 2000-х удалось добиться размера рабочего файла в 45 байтов, но с тех пор ядро сильно изменилось. Каков же будет минимальный жизнеспособный ELF в 2021?
Небольшое дополнение: пока я работаю над полноценным обновлением, хочу отметить, что несколько участников на reddit и hackernews указали способы для уменьшения общего размера программы до 112 байт с сохранением вывода всей строки «Hello, world!». Вот несколько приёмов, о которых при написании статьи я не знал:
- Более короткий способ инициализации регистров.
- В начале выполнения Linux инициализирует состоянии регистров как 0.
- (Тот же пост, что и выше) Поле заголовка программы size in file может быть больше, чем сам файл при условии, что будет вписываться в объём памяти.
- Можно переписать количество заголовков разделов, если размер заголовка раздела установлен на
0.
Мотив проекта
Много лет назад я наткнулся на известную статью, которая сильно повлияла на дальнейшее развитие моей карьеры. В то время я в качестве стажёра работал над системой сборки для откровенно большой базы Java-кода. Именно поэтому меня особо привлекла статья, в которой автор стремился сделать противоположное «энтерпрайзной Java»: удалить все, кроме наиболее важных компонентов, необходимых для определения валидной программы Linux. (А потом удалить ещё!).
Если вкратце, то та статья описывает создание двоичного файла Linux размером 45 байт (!). И даже при том, что итоговый бинарник явно нельзя назвать «валидным» файлом ELF, в Linux он всё же запускался. По крайней мере в то время. Не знаю, к сожалению или к лучшему, но позже эта ОС стала более строгой в отношении загрузки ELF (Точную дату публикации оригинальной статьи отследить мне не удалось, но в начале 2000-х она уже точно была, а миграция многих систем на 64-битные CPU снизила актуальность 32-битных ELF-ов).
Мои цели
Как и автор той самой вдохновившей меня статьи, я намерен создать наименьший ELF-файл, способный выполняться в современной среде Linux (на момент написания ядро 5.14). При этом я буду, как и в оригинальной публикации, также использовать ассемблер NASM, поскольку его легко установить, мне нравится его синтаксис, и он остаётся одним из лучших ассемблеров для x86 из доступных.
Тем не менее некоторые из моих целей отличаются от задач оригинальной статьи:
- Я буду создавать файл под x64_64 (64-битная архитектура AMD/Intel) Linux, так как будет преувеличением заявить, что 32-битный формат Intel (использованный в оригинале) актуален в настоящее время.
- В качестве дополнительной задачи я решил создать программу
Hello, world!(выводящую в stdout текстHello, world!, сопровождаемый переносом строки), вместо менее впечатляющего варианта из оригинала, где программа завершалась с кодом42. Как станет ясно позже, в итоге это потребовало совсем немного байтов. - Моя программа должна успешно завершаться с кодом
0.
Справка по формату ELF64
Файлы ELF используются в Linux (да и во многих других ОС) повсеместно и служат в качестве простых исполняемых программ, статических библиотек, создаваемых компиляторами, динамических библиотек и другого. Двоичный файл ELF, который и станет героем этой статьи, содержит следующие компоненты:
- Заголовок ELF верхнего уровня.
- Таблицу заголовков программы, где указано, какие части файла и куда нужно загружать в память. Иногда она также называется таблица заголовков сегментов.
- Таблица заголовков разделов, где указываются разделы файла ELF. Для простой загрузки файла она не является обязательной, но информация о разделах важна для другой функциональности ELF, например компоновки.
- Фактический исполняемый байткод и любые нужные ему данные.
В формате ELF на удивление мало жёстких требований к расположению разных элементов метаданных, кроме того, что заголовок верхнего уровня должен находиться в начале. Таблица заголовков программы и таблица заголовков разделов могут находиться в любом месте файла, так как заголовок верхнего уровня будет содержать их смещения.
В качестве дополнительного пояснения приведу схематическое изображение структуры формата ELF.

Полномасштабная версия схемы тут
Начало: минимальный, но валидный ELF «Hello world»
Даже те, кто в них не заглядывал, наверняка поняли, что типичные создаваемые
gcc бинарники полны элементов, вовсе не обязательных для простого Hello world. Для тех же, кто хочет в этом убедиться, в оригинальной статье рассматривается несколько итераций версии на Си, которая не требует обновления для актуального использования даже в современных средах.Так что вместо того, чтобы воссоздавать полный аналог предыдущей статьи, я перейду сразу к коду ассемблера и определю весь валидный ELF-файл.
Вот что у меня получилось:
; Использование ассемблера:
; nasm -f bin -o hello_world hello_world.asm
[bits 64]
; Виртуальный адрес, в который наш ELF должен отображаться в памяти.
; Его выбор произволен, но он не должен быть 0 и лучше, если он
; будет выровнен по страницам.
file_load_va: equ 4096 * 40
; Заголовок ELF.
; Сигнатура.
db 0x7f, 'E', 'L', 'F'
; "Class" = 2, 64-bit
db 2
; Порядок следования байтов = 1, от младшего к старшему.
db 1
; Версия ELF = 1
db 1
; OS ABI, не используется, должен быть 0.
db 0
; Байт расширенного ABI + 7 байт заполнения. Оставляем 0, они игнорируются.
dq 0
; Типа файла ELF. 2 = исполняемый
dw 2
; Целевая архитектура. 0x3e = x86_64
dw 0x3e
; Дополнительная информация о версии ELF. Оставляем как 1.
dd 1
; Адрес точки входа.
dq entry_point + file_load_va
; Смещение заголовка программы. Мы поместим его сразу после заголовка ELF.
dq program_headers_start
; Смещение заголовка раздела. Поместим его после заголовков программы.
dq section_headers_start
; Дополнительные флаги. Насколько знаю, не используются.
dd 0
; Размер этого заголовка, 64 байта.
dw 64
; Размер записи заголовка программы.
dw 0x38
; Количество записей заголовков программы.
dw 1
; Размер записи заголовка раздела.
dw 0x40
; Количество записей заголовков разделов.
dw 3
; Индекс раздела, содержащего таблицу строк с именами разделов.
dw 2
program_headers_start:
; Первое поле: тип заголовка программы. 1 = загружаемый сегмент.
dd 1
; Флаги заголовка программы. 5 = без возможности записи. (биты 0, 1 и 2 = исполняемый, с
;возможностью записи и чтения соответственно).
dd 5
; Смещение загружаемого сегмента в файле. Оно будет содержать весь файл, значит
;устанавливаем 0.
dq 0
; Виртуальный адрес для размещения сегмента.
dq file_load_va
; "Физический адрес". Не думайте, что он используется, установите то же значение, что и для
;виртуального.
dq file_load_va
; Размер сегмента в файле. Заканчивается в таблице строк.
dq string_table
; Размер сегмента в памяти.
dq string_table
; Выравнивание сегмента.
dq 0x200000
; У нас будет только два раздела: .text и .shstrtab. Хотя заголовок первого должен быть NULL.
section_headers_start:
; Заголовок раздела в индексе 0 является нулевым заголовком раздела, заполненным нулём.
times 0x40 db 0
; Смещение имени ".text" в таблице строк.
dd text_section_name - string_table
; Его тип – загружаемый раздел "bits"
dd 1
; Флаги для раздела. Биты 0, 1 и 2 означают "с возможностью записи", "размещённый" и
; "исполняемый" соответственно.
dq 6
; "Виртуальный адрес" раздела.
dq file_load_va
; Смещение в файле.
dq 0
; Размер раздела.
dq file_end
; Связанный индекс раздела. Оставляем 0.
dd 0
; "info" раздела. Оставляем 0 (может с ним нужно что-то ;сделать?)
dd 0
; Выравнивание. Неважно.
dq 16
; Размер записи раздела. 0.
dq 0
; Далее, раздел таблицы строк.
dd string_table_name - string_table
; Раздел таблицы строк.
dd 3
; Не нужно загружать.
dq 0
; Этот раздел содержит только таблицу строк, но не весь файл
dq file_load_va + string_table
dq string_table
dq string_table_end - string_table
dd 0
dd 0
dq 1
dq 0
; Мы прошли все заголовки программы и разделов. Далее идёт фактический код.
entry_point:
; Номер системного вызова 1: write.
mov rax, 1
; Номер файлового дескриптора 1.
mov rdi, 1
; Буфер.
mov rsi, file_load_va + message
; Длина буфера.
mov rdx, message_length
syscall
; Номер системного вызова 60: exit.
mov rax, 60
; Код выхода.
mov rdi, 0
syscall
message: db `Hello, world!\n`, 0
message_length: equ $ - messageЗдесь доступна версия без комментариев.
Если кому нужно, то вот краткая справка по синтаксису
nasm:- Строки, начинающиеся с
;являются комментариями. db,dw,ddиdq– это псевдоинструкции, выводящие инициализированные байты, 2-байтовые слова, 4-байтовые двойные слова и 8-байтовые счетверённые слова соответственно.- Метки размещаются в начале строки и заканчиваются на
:. NASM позволяет использовать их в простых арифметических выражениях вместо чисел. - Директива
equиспользуется для связывания метки не с расположением в файле, а с произвольным числом. - Символ
$можно использовать в выражениях для представления в байткоде текущего смещения в байтах. (Здесь есть и другие нюансы, но при создании плоского двоичного файла они обычно не имеют значения). - Весь код написан с помощью синтаксиса ассемблера в формате Intel x86.
Этот ассемблер напрямую определяет необходимые для 64-битного исполняемого ELF метаданные, так что линкер для его получения вам не потребуется. Вместо этого мы соберём его, используя возможность NASM, позволяющую выводить плоские бинарники, и с помощью вызова
chmod отметим его как исполняемый.При условии сохранения файла как
hello_world.asm можете скомпилировать и выполнить его так:nasm -f bin -o hello_world hello_world.asm
chmod +x hello_world
./hello_worldОчевидно, что вам нужно будет использовать 64-битный Linux с
nasm, установленным и доступным в PATH. nasm совсем невелик, и я рекомендую использовать его всем, кто пишет много кода на ассемблере x86.Что включено в файл?
По сути, это минимальный «рабочий» файл ELF, какой я смог получить. Он содержит список разделов, включая
.text для исполняемого кода и .shstrtab (Section Header String Table), где содержатся имена всех разделов (включая его собственное). Весь файл после сборки занял 383 байта, что уже весьма немного, хотя и далеко от возможного.Так как эта начальная версия делалась сообразно формату ELF, просмотр её содержимого при помощи стандартных инструментов Linux работает исправно. По мере удаления из неё содержимого мы будем постепенно эту возможность утрачивать. Например, сейчас
readelf -SW показывает, что наши разделы .text и .shstrtab определены верно:В смещении 0x78 находятся три заголовка разделов:
Section Headers:
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
[ 0] NULL 0000000000000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 0000000000028138 000138 000027 00 AX 0 0 16
[ 2] .shstrtab STRTAB 000000000002816e 00016e 000011 00 0 0 1Аналогичным образом
objdump -M intel -d без проблем дизассемблирует код в разделе .text:Дизассемблированный .text:
0000000000028138 <.text>:
28138: b8 01 00 00 00 mov eax,0x1
2813d: bf 01 00 00 00 mov edi,0x1
28142: 48 be 5f 81 02 00 00 movabs rsi,0x2815f
28149: 00 00 00
2814c: ba 0f 00 00 00 mov edx,0xf
28151: 0f 05 syscall
28153: b8 3c 00 00 00 mov eax,0x3c
28158: bf 00 00 00 00 mov edi,0x0
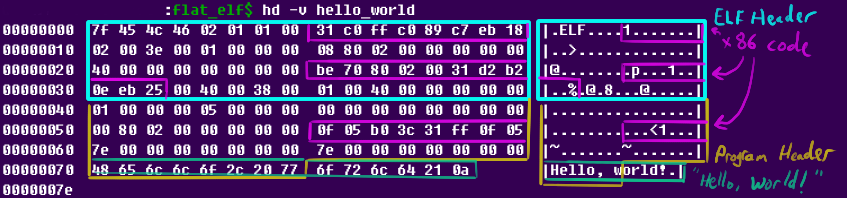
2815d: 0f 05Прежде чем продолжать, можно взглянуть на фактические байты в нашем ELF и подписать их роль в нем:

Даже навскидку связанная с разделами информация занимает слишком много места. Как я уже говорил, всё это не нужно, если нас интересует лишь загрузка ELF в память и его запуск. Но можно ли взять и просто эту информацию удалить?
Удаление информации разделов
Ответ: «Да».
Для этого устанавливаем количество заголовков разделов на
0 и удаляем эти разделы. Ниже показано, как выглядит код после. Его можно собрать и выполнить так же, как и предыдущую версию. Кроме того, я дополнительно убрал все комментарии, кроме аннотаций изменённых строк: [bits 64]
file_load_va: equ 4096 * 40
db 0x7f, 'E', 'L', 'F'
db 2
db 1
db 1
db 0
dq 0
dw 2
dw 0x3e
dd 1
dq entry_point + file_load_va
dq program_headers_start
; Смещение заголовка раздела. Разделов у нас нет, значит пусть он пока будет 0.
dq 0
dd 0
dw 64
dw 0x38
dw 1
; Размер записи заголовка раздела.
dw 0x40
; Количество записей заголовков разделов. Сейчас 0, так как у нас их нет.
dw 0
; Раздел, содержащий имена разделов. Больше не используется, значит устанавливаем как 0.
dw 0
program_headers_start:
dd 1
dd 5
dq 0
dq file_load_va
dq file_load_va
; Мы изменим наш единственный заголовок программы, включив в него весь файл.
dq file_end
dq file_end
dq 0x200000
entry_point:
mov rax, 1
mov rdi, 1
mov rsi, file_load_va + message
mov rdx, message_length
syscall
mov rax, 60
mov rdi, 0
syscall
code_end:
message: db `Hello, world!\n`
message_length: equ $ - message
file_end:Удаление информации разделов сокращает размер файла до 173 байтов, экономя более 200 байт в сравнении с первым вариантом, который уже был мал. Очевидно, что так наш файл теряет кое-какие полезные метаданные, в результате чего некоторые утилиты, та же
objdump, не смогут найти нужный код. Но при этом работоспособность не нарушена полностью. К примеру, readelf –SW по-прежнему работает и корректно указывает, что ELF не содержит разделов.Если заглянуть в байткод ELF, то здесь ничего особо интересного. Все, как и раньше, только нет информации разделов:

Итак, что дальше? Другую информацию просто так удалить нельзя: нам нужен код, строка
Hello, world!, заголовок ELF и заголовок программы. Однако есть одна деталь, которую можно уменьшить, ничего не сломав: сам код.Уменьшение размера кода
Байткод х86 определенно не является самой большой частью файла, но он всё равно недостаточно оптимизирован по размеру, занимая 39 из 173 байтов. В данный момент весь код программы состоит из всего восьми инструкций. Неплохо! Но можно заменить эти инструкции более короткими альтернативами. Поскольку изначально их всего восемь, то я просто пройдусь по ним поочерёдно:
mov rax, 1: для начала устанавливаем регистрraxна хранение номера системного вызоваwrite: 1. (Если не знакомы с номерами системных вызовов в Linux, то рекомендую заглянуть сюда. С их помощью мы просим Linux выполнить нужную работу от лица программы). Если вы изучили дизассемблированный код выше, то могли заметить, что наш ассемблер автоматически конвертировал эту инструкцию вmov eax, 1, так как установкаeax(младшие 32 битаrax) автоматически очищает старшие 32 битаrax. И всё жеmov eax, 1занимает целых 5 байтов. Можно это улучшить:
xor eax, eax: обнулить все биты в регистреeax. Это также обнулит все старшие битыrax, всего заняв два байта.inc eax: инкрементироватьeaxна 1, что тоже займёт два байта.
Вместе эти две инструкции займут 4 байта, сэкономив нам 1 байт в сравнении с
mov eax, 1.mov rdi, 1: далее мы устанавливаем первый аргумент системного вызова в регистреrdi, чего требует интерфейс системных вызовов Linux x86_64. Файловым дескриптором для stdout является 1, значит устанавливаемrdiна1. Опять же, ассемблер автоматически заменил эту инструкцию на её 5-байтовый эквивалентmov edi, eax. Однако мы уже установилиraxна1, поэтому можно вместо этого использоватьmov edi, eax, чтобы скопировать содержимоеeaxвedi(и очистить старшие битыrdi). Эта новая инструкция занимает два байта, то есть мы экономим ещё 3.mov rsi, file_load_va + message: очередной аргумент системного вызова, виртуальный адрес выводимой строки, отправляется в регистрrsi. Мы вычисляем его здесь на основе произвольного виртуального адреса файла, который выбираем сами, и смещения строки в файле. В итоге эта инструкция занимает 10 байтов: два байта для кода операции и 8 полных байтов для адреса. Можно заменить её наmov esi, file_load_va + message, сэкономив 5 байтов: переход наesiтребует на один байт меньше для опкода и использует четырехбайтовый непосредственный операнд. (Не сработает этот приём, только еслиfile_load_vaне вместится в 32 бита).mov rdx, message_length: последним аргументом для системного вызова будет длина выводимой строки. Здесь, как и в предыдущих случаях, произошла автоматическая замена на эквивалентmov edx, message_length. Тем не менее эта инструкция занимает аж 5 байтов, что вполне можно оптимизировать так:
xor edx, edx: установитьedx(и, как следствие,rdx) на0, что займет два байта.mov dl, message_length: установить младшие 8 битrdxна длину сообщения. Это также займёт два байта и будет работать при условии, что длина строки менее 256.
Итак, мы сократили код с 5 байт до 4.
syscall: эта инструкция будет вызывать системный вызовwriteдля вывода строки и займёт два байта. Здесь, насколько я понимаю, улучшить уже ничего нельзя.mov rax, 60: теперь, когда мы активировали системный вызовwrite, нужно активировать системный вызовexit. Его номер 60. Эта инструкция занимает 5 байтов, и в этом случае можно получить куда меньший размер, если предположить, чтоwriteвыполнится успешно: возвращаемое системным вызовом значение записывается в регистрraxи в случае успеха должно быть0. Предполагая, что так и есть, нам не потребуется обнулять битыrax, и мы сможем просто установить его младший байт на 60, используя инструкциюmov al, 60. Всё это займёт всего два байта, экономя нам ещё 3.mov rdi, 0: единственным аргументом для системного вызоваexitбудет код выхода. В случае успеха он должен быть0, значит устанавливаемrdiна0. И здесь NASM снова сформирует 5-байтовую инструкцию, которую можно заменить наxor edi, edi. Таким образом, мы добьёмся того же результата, уложившись в два байта.syscall: теперь осуществляем системный вызовexit, чтобы завершить программу. В данном случае более краткой альтернативы я не знаю.
После всех этих манипуляций код будет выглядеть так:
[bits 64]
file_load_va: equ 4096 * 40
db 0x7f, 'E', 'L', 'F'
db 2
db 1
db 1
db 0
dq 0
dw 2
dw 0x3e
dd 1
dq entry_point + file_load_va
dq program_headers_start
dq 0
dd 0
dw 64
dw 0x38
dw 1
dw 0x40
dw 0
dw 0
program_headers_start:
dd 1
dd 5
dq 0
dq file_load_va
dq file_load_va
dq file_end
dq file_end
dq 0x200000
entry_point:
; Устанавливаем eax (и, как следствие, rax) на 1. (Номер системного вызова write).
xor eax, eax
inc eax
; Устанавливаем edi (и, как следствие, rdi) на 1. (Файловый дескриптор для stdout).
mov edi, eax
; Устанавливаем esi (и, как следствие, rsi) на виртуальный адрес строки.
mov esi, file_load_va + message
; Устанавливаем edx (и, как следствие, rdx) на длину строки.
xor edx, edx
mov dl, message_length
; Осуществляем системный вызов write.
syscall
; Предполагая успешность write, rax уже равен 0, значит устанавливаем номер следующего
;системного вызова на 60 для совершения exit.
mov al, 60
; Устанавливаем статус exit на 0.
xor edi, edi
; Выходим из программы.
syscall
code_end:
message: db `Hello, world!\n`
message_length: equ $ - message
file_end:Его можно собрать и выполнить аналогично предыдущим примерам, и укорачивание исполняемого байткода никак не повлияет на формат ELF. Внесение этих изменений сократило размер файла до 157 байт – то есть минус ещё 16. При этом он всё ещё остаётся вполне дееспособным бинарником Linux. Мы перешли от восьми инструкций, занимавших 39 байтов, к десяти, которые занимают 23. Шестнадцатеричный дамп байтов с прошлого раза изменился не сильно:

Код заметно сократился, и размер в 157 байт можно назвать очень мелким для исполняемого файла. Кроме того, несмотря на недостаток большого количества метаданных, ничто в программе не «сломано» полностью – в ней есть полные, пока ещё заполненные, заголовок ELF и заголовок программы, а также небольшой блок кода для выполнения. Другими словами, у Linux нет серьёзных оснований для отказа в его выполнении. Но это скоро изменится.
Перемещение кода
Оказывается, что сокращение кода имеет и ещё одно преимущество: в нём используются более короткие инструкции, которые можно разбить на сжатые детализированные части и объединить с помощью инструкций
jmp. Но в чем здесь польза?Если вы следовали ходу моей мысли и прочли раздел «Мотивация» в начале статьи, то наверняка поймеёте, что я имеют в виду: несколько полей в заголовке ELF и заголовке программы загрузчиком ELF в Linux не проверяются, и мы можем переписать их собственным кодом. Это позволит полностью удалить байты, занимаемые кодом, переназначив имеющиеся байты заголовков для двух задач.
Но какие байты заголовков можно переписать? Это легко проверить: заменить их в ассемблере на произвольное содержимое и посмотреть, заработает ли программа. Так я и поступил, а результаты записал в таблицу:

В этой таблице каждый байт в заголовке ELF и заголовке программы показаны в отдельных строках. Поля, которые можно переписать мусором, выделены зелёным, а те, которые проверяются или являются необходимыми – красным. Мы воспользуемся этой информацией, чтобы упаковать код (и даже строку
Hello, world!\n) в неиспользуемые байты (по факту, непроверяемые байты). Обновлённый код получится таким:[bits 64]
file_load_va: equ 4096 * 40
db 0x7f, 'E', 'L', 'F'
db 2
db 1
db 1
db 0
; Мы перепишем поле EABI + 7 байт заполнения нашими 8 байтами
;кода. (Я наперёд проверил, чтобы эти инструкции занимали ровно 8 байтов).
entry_point:
xor eax, eax
inc eax
mov edi, eax
; Переходим к следующему месту, которое можно заместить нашим кодом, так как следующее
;поле заместить не можем (тип ELF).
jmp code_chunk_2
dw 2
dw 0x3e
dd 1
dq entry_point + file_load_va
dq program_headers_start
; Далее мы перепишем 8-байтовое поле смещения заголовка раздела, а также 4-байтовое поле
;“flags”, идущее за ним.
code_chunk_2:
mov esi, file_load_va + message
xor edx, edx
mov dl, message_length
; Перескакиваем к заключительной части кода и добавляем один байт нулей, заполняя 12-й
;байт двух перезаписываемых полей.
jmp code_chunk_3
db 0
dw 64
dw 0x38
dw 1
dw 0x40
dw 0
dw 0
program_headers_start:
dd 1
dd 5
dq 0
dq file_load_va
; Мы перепишем 8-байтовое поле "physical address"в заголовке программы нашими 8 байтами
;кода. Эти четыре инструкции займут ровно 8 байтов.
code_chunk_3:
syscall
mov al, 60
xor edi, edi
syscall
dq file_end
dq file_end
; Мы можем переписать заключительное 8-байтовое поле "alignment" в заголовке программы и
;сделаем это первыми 8 байтами строки "Hello, world!".
message: db `Hello, world!\n`
message_length: equ $ - message
file_end:И снова его можно собрать и выполнить подобно всем предыдущим примерам. Теперь он занимает всего 126 байтов: 31 байт мы сократили за счёт удаления всех байтов кода и 8 байт за счёт строки
Hello, world!. К сожалению, мы не можем упаковать всю строку в какой-либо из доступных промежутков, так как ей требуется 14 байтов, а в заголовках нет последовательности из 14 допускающих замещение байтов. В таком виде заголовок ELF и заголовок программы занимают 120 байтов, и строка «выпирает» из-за последнего ещё 6 байтами. Вот теперь несколько стандартных инструментов, о которых я говорил ранее, уже не одобряют тот факт, что мы заместили так много полей в заголовках. Например,
readelf – WlS начала жаловаться, что смещение заголовка раздела не равно нулю. Утилита objdump при попытке её применения к файлу просто выдаёт ошибку File truncated. И хоть конкретики в этой ошибке нет, я полагаю, что она также вызвана смещением заголовка раздела, так как другие поля, которые мы заместили, представляли просто заполнение, неиспользуемый физический адрес и выравнивание сегмента в памяти. Несмотря на то, что с виду к утрате функционала objdump может привести замещение выравнивания, я убедился, что это не так: установка выравнивания сегмента обратно на 1 (его значение до его замещения строкой) не восстановило работоспособность objdump.В завершение hex-дамп текущей версии стал весьма интересен и отлично демонстрирует то, как мы исковеркали файл:
Но на этом ещё не все!
Финальная версия
Мы можем сделать ещё кое-что: аналогично тому, как мы наложили код, можно также наложить сами заголовки.
В конце заголовка ELF указано количество заголовков программы, сопровождаемое размером и количеством заголовков разделов, после чего идёт индекс раздела, содержащий таблицу имён разделов. Нам однозначно нужно оставить количество заголовков программы как
1, а количество заголовков разделов как 0, но оказывается, что размер заголовка раздела и индекс таблицы имён разделов можно переписать при условии, что мы не будем определять какие-либо разделы. По отдельности каждое из этих полей занимает всего два байта.А что произойдёт, если начать первый заголовок программы сразу после количества этих заголовков? Как оказалось, это отлично сработает: несмотря на то, что заголовок программы начинается с четырехбайтового поля
type, которое не должно быть нулевым, у этого поля установлен только нижний байт – остальные представлены нулями. Так что, если мы начнём наши шесть байт заголовка программы до завершения заголовка ELF, то поле type перехлёстывается с допускающим наложение section header size; полем заголовка ELF, а также количеством заголовков разделов. Однако байты, перекрывающие количество заголовков разделов, представлены нулями: что нам и нужно. Далее поле
flags заголовка программы (которое тоже не может быть равно нулю) перекрывает поле таблицы строк имён разделов, которое мы, как и говорилось, не используем ввиду отсутствия самих разделов.В итоге код ассемблера изменился не сильно, но уже представляет финальную версию:
[bits 64]
file_load_va: equ 4096 * 40
db 0x7f, 'E', 'L', 'F'
db 2
db 1
db 1
db 0
entry_point:
xor eax, eax
inc eax
mov edi, eax
jmp code_chunk_2
dw 2
dw 0x3e
dd 1
dq entry_point + file_load_va
dq program_headers_start
code_chunk_2:
mov esi, file_load_va + message
xor edx, edx
mov dl, message_length
jmp code_chunk_3
db 0
dw 64
dw 0x38
dw 1
; Мы просто удалили три двухбайтовых поля, которые раньше здесь были. Единственное, которое ;имело значение – количество заголовков разделов – по-прежнему будет нулевым, так как два ;старших байта этого поля в начале заголовка программы нулевые.
program_headers_start:
; Следующие два поля также служат в качестве последних шести байт заголовка ELF.
dd 1
dd 5
dq 0
dq file_load_va
code_chunk_3:
syscall
mov al, 60
xor edi, edi
syscall
dq file_end
dq file_end
message: db `Hello, world!\n`
message_length: equ $ - message
file_end:Как и прежде, этот код можно собрать и выполнить аналогично самому первому примеру. После реализации шестибайтового нахлеста между заголовками он сократился до 120 байтов. В обычных условиях этот размер был бы равен суммарному размеру заголовка ELF и одного заголовка программы — наименьшему, какой можно ожидать от исполняемого файла ELF без кода. Для полноты можно также заглянуть в итоговый байткод:

Можно ли пойти ещё дальше?
120 байт – это серьёзный результат. Такой файл может уместиться в одно текстовое сообщение. Он занимает меньше 1/34 от 4Кб-страницы, что намного меньше, чем можно было желать. Если бы мы отклонились от изначальной цели написать полноценную программу
Hello, world!, то могли бы срезать ещё шесть байт, получив итоговый размер 114. Можете попробовать сами, изменив код так, чтобы строка Hello, world!\n занимала ровно 8 байт. Например, если заменить соответствующую строку на message: db ‘Hi!!!!!\n’, то в итоге получится рабочий 114-байтовый файл.Попытки ещё больше укоротить эту строку приведут к чрезмерному сокращению заголовка программы, создав исполняемый файл, который Linux откажется запускать. И здесь открывается интересный нюанс. Это значит, что если мы решим использовать программу
return 42 из оригинальной статьи, а не нашу версию с Hello, world!, то меньше 114 байт уже не опустимся – ограничивающим фактором становится наша невозможность дальнейшего наложения поверх заголовка ELF и одного необходимого заголовка программы.А можно вообще больше не накладывать ничего поверх заголовков? Всё же автор оригинальной статьи смог уменьшить свой ELF вплоть до 45 байтов. К сожалению, это более не является возможным: для этого нужно, чтобы Linux автоматически заполняла незавершённые остатки заголовка ELF и заголовка программы нулями, чего эта система больше не делает. Однако в оригинальной 45-байтовой версии заголовок программы идёт сразу после сигнатуры
0x7f, E, L, F в начале файла. Неужели для нас действительно невозможно найти лучший способ перекрыть заголовок ELF и заголовок программы?К сожалению, мне кажется, что здесь мы добиваемся наилучшего из возможных на сегодня результатов. Вернитесь ещё раз к скриншоту таблицы, где показано, какие байты можно заместить в заголовке ELF и заголовке программы. Увеличенный размер 64-битного заголовка программы существенно ограничивает возможности наложения, и после тщательной проверки байт за байтом я могу уверенно сказать, что лучшего не добиться, по крайней мере в современных сборках Linux x86-64. Для полноты я приведу шаги, которым следовал, чтобы прийти к такому заключению:
program header offsetв заголовке ELF и полеsize in fileв заголовке программы должны оба вписываться в один байт (в противном случае получится файл размером больше 255 байтов). При этом они не могут быть идентичны, так что эти 8-байтовые поля вообще не могут накладываться.- Размер заголовков и тот факт, что заголовок ELF должен идти в начале файла, вместе с предыдущим доводом означают, что поле
size in fileв заголовке программы должно идти полностью после поляprogram header offsetв заголовке ELF. - Если попробовать обойти предыдущий пункт, разместив поле
size in fileсразу после поляprogram header offset, то поляtypeиflagsзаголовка программы (которые не могут быть нулевыми) окажутся в полеprogram header offset, которое, как говорилось, переписывать нельзя. - Если и предыдущий пункт попробовать обойти, поместив поля
flagsиtypeсразу после поляprogram header offset, тогда поляELF header sizeиprogram header entry sizeв заголовке ELF перекроются полем заголовка программыoffset in file, который должен быть не более одного байта, не может совпадать с размерами заголовка ELF или заголовка программы и, следовательно, не может быть переписан. К сожалению, эти поля размеров проверяются ядром Linux (чего во времена написания оригинальной статьи не происходило). - Если мы переместим поля
flagsиtypeзаголовка программы так, что они будут идти сразу после двух вышеупомянутых полей размера, тогда они перекроют полеnumber of program headersзаголовка ELF, которое должно быть1. Поле заголовка программы также равно1, и это, вроде бы, должно радовать. Но нет, не сработает…поскольку в результате этого наложения полеflagsляжет поверх количества заголовков разделов. Количество заголовков разделов должно быть равно нулю, а флаги нулевыми быть не могут, потому что битыreadable+executableдолжны быть установлены. - Наконец, если мы переместим поле заголовка программы за размеры заголовка ELF и заголовка программы, то оно перекроет поле
section header sizeв заголовке ELF. Такой вариант сработает, причины чего описывались выше, и именно на этом заканчивается наша финальная версия.
Заключение
Несмотря на то, что это далеко не так впечатляет, как 45-байтовый исполняемый файл в уже далёком прошлом, многие из крайних приёмов оптимизации до сих пор остаются возможными в современных 64-битных системах Linux. 120 байт (или даже минимум в 114 байтов) – это невероятно крохотная программа по меркам времени, когда раздутое ПО очень уж часто принимается как должное.
Конечно, многое из проделанного нами ушло далеко за устранение «раздутости», но посыл при этом сохраняется: «Наверняка можно устранить куда больше программных излишеств, чем кажется на первый взгляд. А вот вопрос «Стоит ли это приложенных усилий?» уже заслуживает отдельного обсуждения».


{kind=link}