Рекурсия — очень мощный и удобный механизм, если над связанными данными делаются одни и те же действия «вглубь». Но неконтролируемая рекурсия — зло, которое может приводить или к бесконечному выполнению процесса, или (что случается чаще) к «выжиранию» всей доступной памяти.

СУБД в этом отношении работают по тем же принципам — "сказали копать, я и копаю". Ваш запрос может не только затормозить соседние процессы, постоянно занимая ресурсы процессора, но и «уронить» всю базу целиком, «съев» всю доступную память. Поэтому защита от бесконечной рекурсии — обязанность самого разработчика.
В PostgreSQL возможность использовать рекурсивные запросы через
На самом деле, PostgreSQL предоставляет достаточно большое количество функционала, которым можно воспользоваться, чтобы не применять рекурсию.
Иногда можно просто взглянуть на задачу «с другой стороны». Пример такой ситуации я приводил в статье «SQL HowTo: 1000 и один способ агрегации» — перемножение набора чисел без применения пользовательских агрегатных функций:
Такой запрос можно заменить на вариант от знатоков математики:
Допустим, перед нами стоит задача сгенерировать все возможные префиксы для строки
Точно-точно тут нужна рекурсия?.. Если воспользоваться
Например, у вас есть таблица сообщений форума со связями кто-кому ответил или тред в социальной сети:
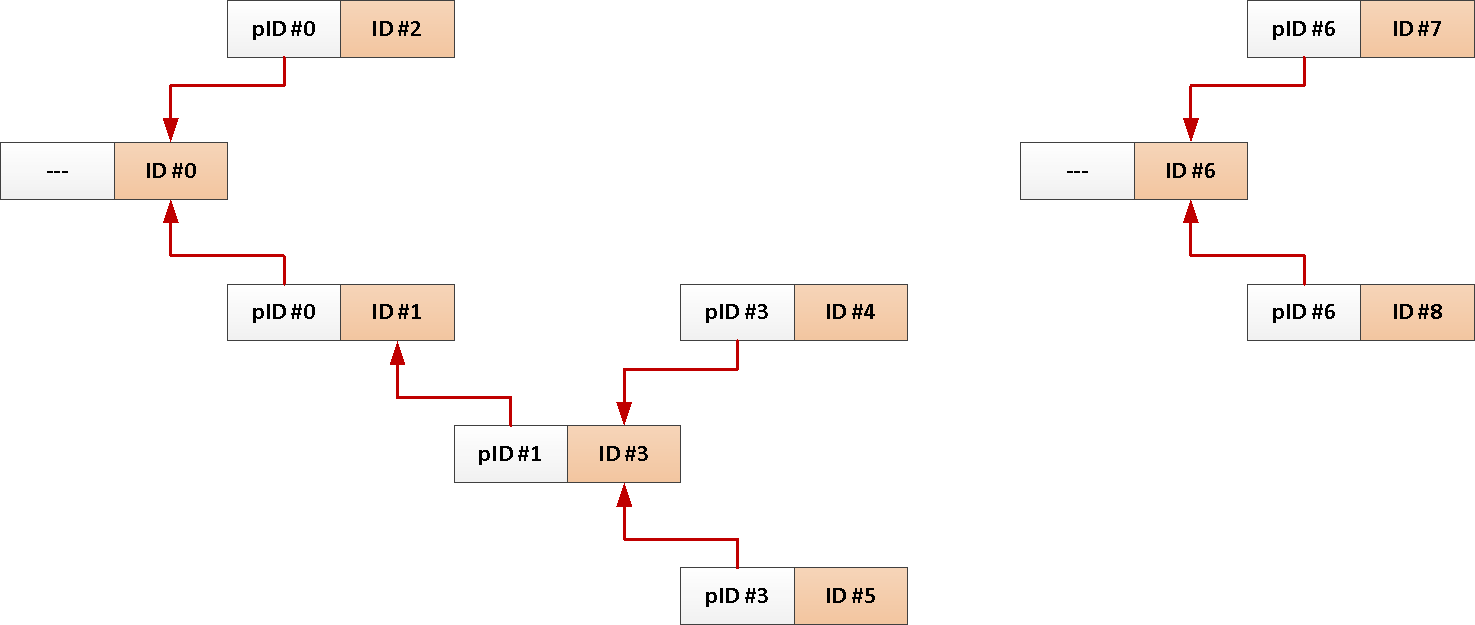
Ну и типовой запрос загрузки всех сообщений по одной теме выглядит примерно так:
Но раз у нас всегда нужна вся тема от корневого сообщения, то почему бы нам не добавлять его идентификатор в каждую запись автоматом?

Теперь весь наш рекурсивный запрос может быть сведен всего лишь к вот такому:
Если поменять структуру базы мы не в силах по каким-то причинам, давайте посмотрим, на что можно опереться, чтобы даже наличие ошибки в данных не приводило к бесконечному выполнению рекурсии.
Просто увеличиваем счетчик на единицу на каждом шаге рекурсии вплоть до момента достижения предела, который мы считаем заведомо неадекватным:
Pro: При попытке зацикливания мы все равно сделаем не более указанного лимита итераций «вглубь».
Contra: Нет гарантии, что мы не обработаем повторно одну и ту же запись — например, на глубине 15 и 25, ну и дальше будет каждые +10. Да и про «вширь» никто ничего не обещал.
Формально, такая рекурсия не будет бесконечной, но если на каждом шаге количество записей увеличивается по экспоненте, мы все хорошо знаем, чем это кончается…
 см. «Задача о зёрнах на шахматной доске»
см. «Задача о зёрнах на шахматной доске»
Поочередно дописываем все встретившиеся нам по пути рекурсии идентификаторы объектов в массив, который является уникальным «путем» до него:
Pro: При наличии цикла в данных мы абсолютно точно не станем обрабатывать повторно одну и ту же запись в рамках одного пути.
Contra: Но при этом мы можем обойти, буквально, все записи, так и не повторившись.
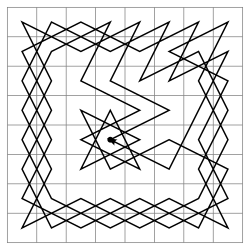 см. «Задача о ходе коня»
см. «Задача о ходе коня»
Чтобы избежать ситуации «блуждания» рекурсии на непонятной глубине, мы можем скомбинировать два предыдущих метода. Или, если не хотим поддерживать лишних полей, дополнить условие продолжения рекурсии оценкой длины пути:
Выбирайте способ на свой вкус!
СУБД в этом отношении работают по тем же принципам — "сказали копать, я и копаю". Ваш запрос может не только затормозить соседние процессы, постоянно занимая ресурсы процессора, но и «уронить» всю базу целиком, «съев» всю доступную память. Поэтому защита от бесконечной рекурсии — обязанность самого разработчика.
В PostgreSQL возможность использовать рекурсивные запросы через
WITH RECURSIVE появилась еще в незапамятные времена версии 8.4, но до сих пор можно регулярно встретить потенциально-уязвимые «беззащитные» запросы. Как избавить себя от проблем подобного рода?Не писать рекурсивные запросы
А писать нерекурсивные. С уважением, Ваш К.О.На самом деле, PostgreSQL предоставляет достаточно большое количество функционала, которым можно воспользоваться, чтобы не применять рекурсию.
Использовать принципиально другой подход к задаче
Иногда можно просто взглянуть на задачу «с другой стороны». Пример такой ситуации я приводил в статье «SQL HowTo: 1000 и один способ агрегации» — перемножение набора чисел без применения пользовательских агрегатных функций:
WITH RECURSIVE src AS (
SELECT '{2,3,5,7,11,13,17,19}'::integer[] arr
)
, T(i, val) AS (
SELECT
1::bigint
, 1
UNION ALL
SELECT
i + 1
, val * arr[i]
FROM
T
, src
WHERE
i <= array_length(arr, 1)
)
SELECT
val
FROM
T
ORDER BY -- отбор финального результата
i DESC
LIMIT 1;Такой запрос можно заменить на вариант от знатоков математики:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
exp(sum(ln(prime)))::integer val
FROM
src;Использовать generate_series вместо циклов
Допустим, перед нами стоит задача сгенерировать все возможные префиксы для строки
'abcdefgh':WITH RECURSIVE T AS (
SELECT 'abcdefgh' str
UNION ALL
SELECT
substr(str, 1, length(str) - 1)
FROM
T
WHERE
length(str) > 1
)
TABLE T;Точно-точно тут нужна рекурсия?.. Если воспользоваться
LATERAL и generate_series, то даже CTE не понадобятся:SELECT
substr(str, 1, ln) str
FROM
(VALUES('abcdefgh')) T(str)
, LATERAL(
SELECT generate_series(length(str), 1, -1) ln
) X;Изменить структуру БД
Например, у вас есть таблица сообщений форума со связями кто-кому ответил или тред в социальной сети:
CREATE TABLE message(
message_id
uuid
PRIMARY KEY
, reply_to
uuid
REFERENCES message
, body
text
);
CREATE INDEX ON message(reply_to);Ну и типовой запрос загрузки всех сообщений по одной теме выглядит примерно так:
WITH RECURSIVE T AS (
SELECT
*
FROM
message
WHERE
message_id = $1
UNION ALL
SELECT
m.*
FROM
T
JOIN
message m
ON m.reply_to = T.message_id
)
TABLE T;Но раз у нас всегда нужна вся тема от корневого сообщения, то почему бы нам не добавлять его идентификатор в каждую запись автоматом?
-- добавим поле с общим идентификатором темы и индекс на него
ALTER TABLE message
ADD COLUMN theme_id uuid;
CREATE INDEX ON message(theme_id);
-- инициализируем идентификатор темы в триггере при вставке
CREATE OR REPLACE FUNCTION ins() RETURNS TRIGGER AS $$
BEGIN
NEW.theme_id = CASE
WHEN NEW.reply_to IS NULL THEN NEW.message_id -- берем из стартового события
ELSE ( -- или из сообщения, на которое отвечаем
SELECT
theme_id
FROM
message
WHERE
message_id = NEW.reply_to
)
END;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER ins BEFORE INSERT
ON message
FOR EACH ROW
EXECUTE PROCEDURE ins();Теперь весь наш рекурсивный запрос может быть сведен всего лишь к вот такому:
SELECT
*
FROM
message
WHERE
theme_id = $1;Использовать прикладные «ограничители»
Если поменять структуру базы мы не в силах по каким-то причинам, давайте посмотрим, на что можно опереться, чтобы даже наличие ошибки в данных не приводило к бесконечному выполнению рекурсии.
Счетчик «глубины» рекурсии
Просто увеличиваем счетчик на единицу на каждом шаге рекурсии вплоть до момента достижения предела, который мы считаем заведомо неадекватным:
WITH RECURSIVE T AS (
SELECT
0 i
...
UNION ALL
SELECT
i + 1
...
WHERE
T.i < 64 -- предел
)Pro: При попытке зацикливания мы все равно сделаем не более указанного лимита итераций «вглубь».
Contra: Нет гарантии, что мы не обработаем повторно одну и ту же запись — например, на глубине 15 и 25, ну и дальше будет каждые +10. Да и про «вширь» никто ничего не обещал.
Формально, такая рекурсия не будет бесконечной, но если на каждом шаге количество записей увеличивается по экспоненте, мы все хорошо знаем, чем это кончается…
Хранитель «пути»
Поочередно дописываем все встретившиеся нам по пути рекурсии идентификаторы объектов в массив, который является уникальным «путем» до него:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) -- не совпадает ни с одним из
)Pro: При наличии цикла в данных мы абсолютно точно не станем обрабатывать повторно одну и ту же запись в рамках одного пути.
Contra: Но при этом мы можем обойти, буквально, все записи, так и не повторившись.
Ограничение длины пути
Чтобы избежать ситуации «блуждания» рекурсии на непонятной глубине, мы можем скомбинировать два предыдущих метода. Или, если не хотим поддерживать лишних полей, дополнить условие продолжения рекурсии оценкой длины пути:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) AND
array_length(T.path, 1) < 10
)Выбирайте способ на свой вкус!
