Ни для кого не секрет, что бизнес непрерывно стремится к повышению своей конкурентоспособности. Кажется, что проще всего это сделать через инновации, давайте повысим эффективность одного-двух-трех бизнес-процессов с помощью современной, высокотехнологичной системы и будет нам счастье. Эта схема работает до тех пор, пока сложность нашей IT-системы не начинает работать против нас.
Вы знаете, насколько эффективно работают элементы вашей IT- инфраструктуры? Как они влияют друг на друга? Может быть, какой-нибудь элемент ухудшает работу системы в целом? Как понять, что это за элемент?
В нашей статье мы хотим рассказать о решении, которое может помочь в анализе и мониторинге эффективности работы как каждого отдельного элемента, так и всей IT-системы в целом, определения зависимостей между сервисами, оповещения при изменении показателей эффективности ниже или выше порогового уровня.
Речь идет о Splunk IT Service Intelligence (ITSI). Это инструмент для мониторинга и анализа работы IT-инфраструктуры, работающий на платформе операционной аналитики Splunk, о котором мы рассказывали ранее.

Платформа позволяет собирать, мониторить данные с различных устройств, систем и приложений. Процесс работы ITSI обеспечивает видимость показателей работоспособности элементов системы, основных KPI, а также поведения критически важных IT- и бизнес-сервисов и связанных с ними поддерживающих сервисов.
С помощью одного инструмента можно решить множество задач в области IT, в том числе анализ событий, метрик, журналов, позволяющий идентифицировать и исправить наиболее важные проблемы в работе элементов IT-инфраструктуры.
Давайте рассмотрим основные элементы Splunk IT Service Intelligence, а также зачем они нужны:
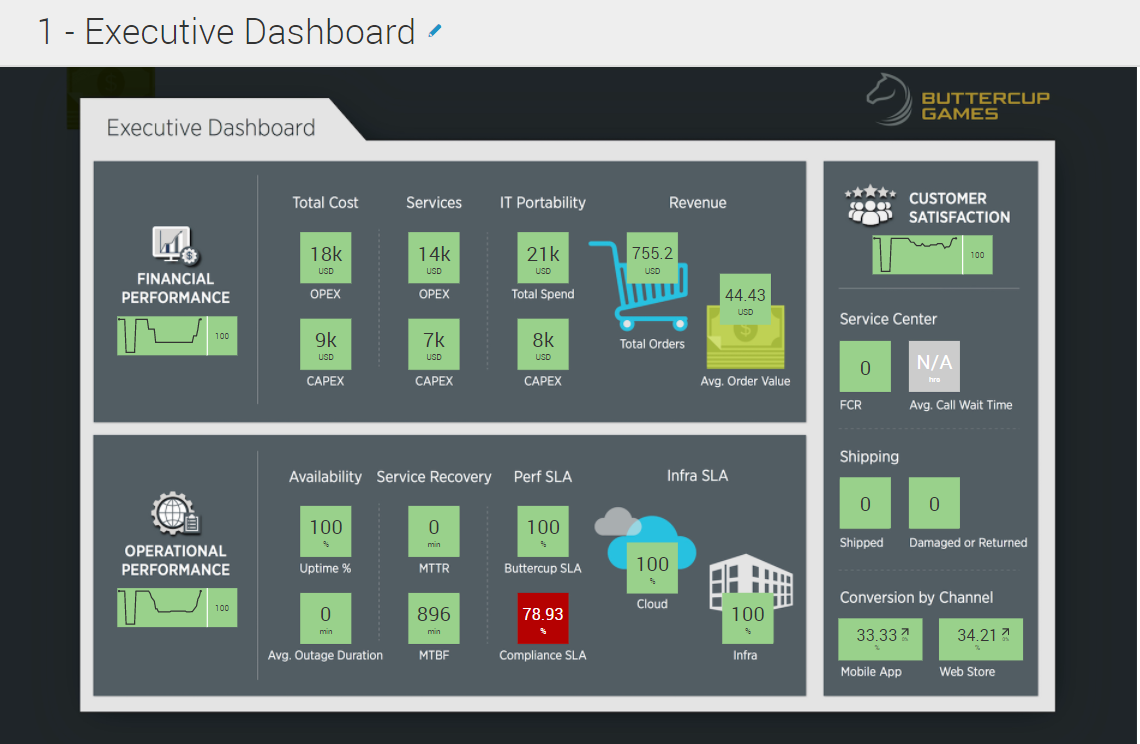
Это очевидно, что всем хочется получить наиболее важную информацию максимально понятно и быстро. Именно для этого служит стартовая страница ITSI — Service Analyzer. Заходя в приложение, можно одним взглядом оценить общую уровень работы всей IT-системы.
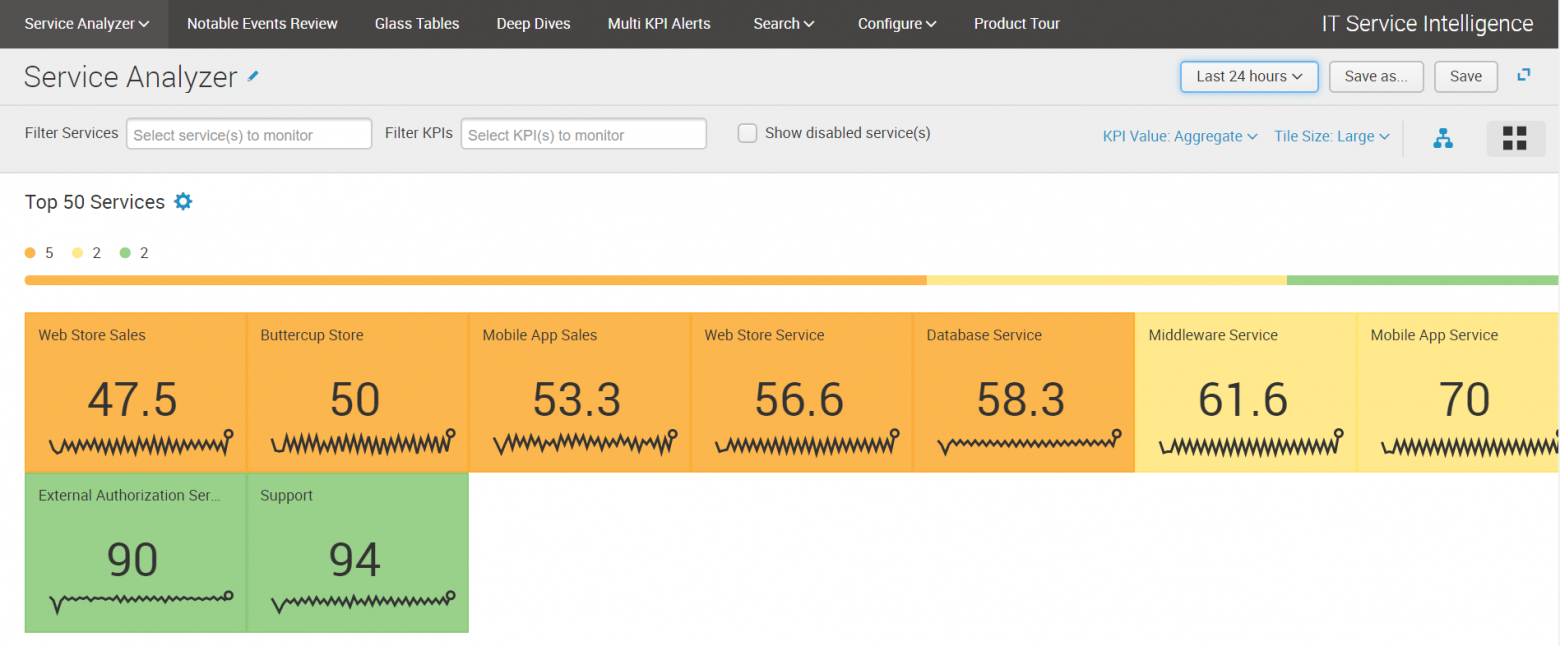
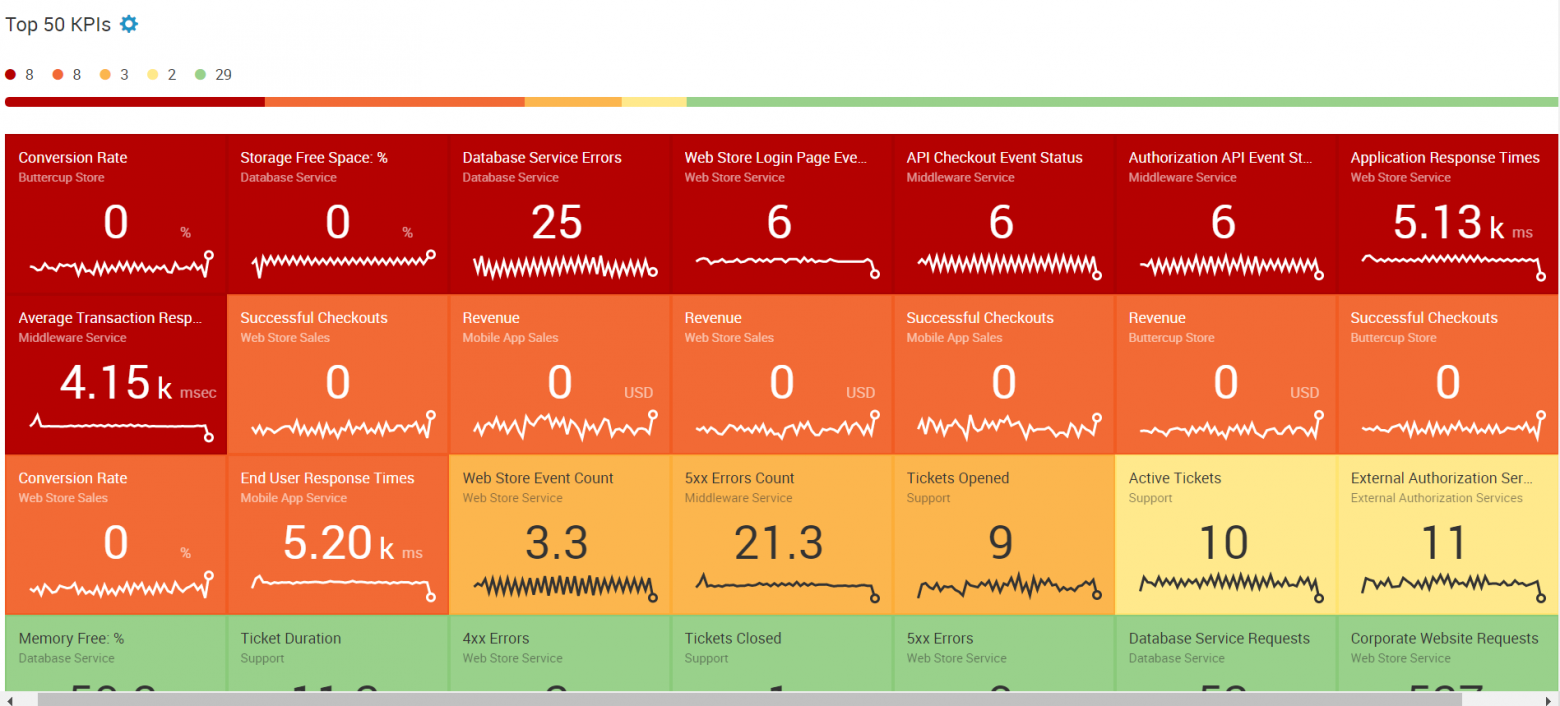
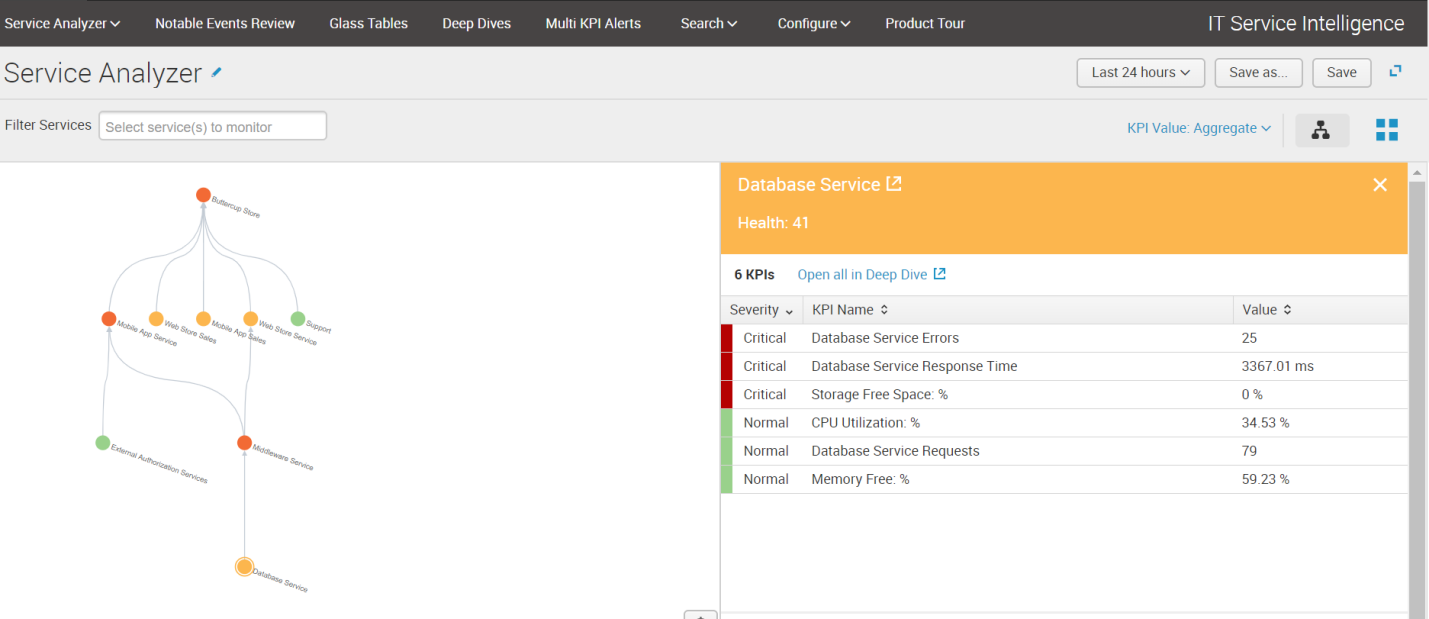
Существует два представления Service Analyzer: вид плитки и древовидная структура, которая позволяет видеть, как одни сервисы влияют на другие.
В виде плиток представлены показатели работоспособности и основные связанными с ними KPI, имеющие цветовой индикатор и отсортированные по текущему уровню состояния.
Древовидное представление отображает все сервисы в виде графа, в котором узлы показывают уровень работоспособности узла. Каждый узел можно раскрыть и увидеть связанные с ним показатели эффективности.
В приведенном ниже примере служба магазина Buttercup зависит от продаж веб-магазина, продаж мобильных приложений, службы веб-магазина, служб мобильного приложения и служб поддержки. Служба мобильных приложений зависит от службы промежуточного ПО и службы внешней авторизации, которая зависит от работы базы данных.
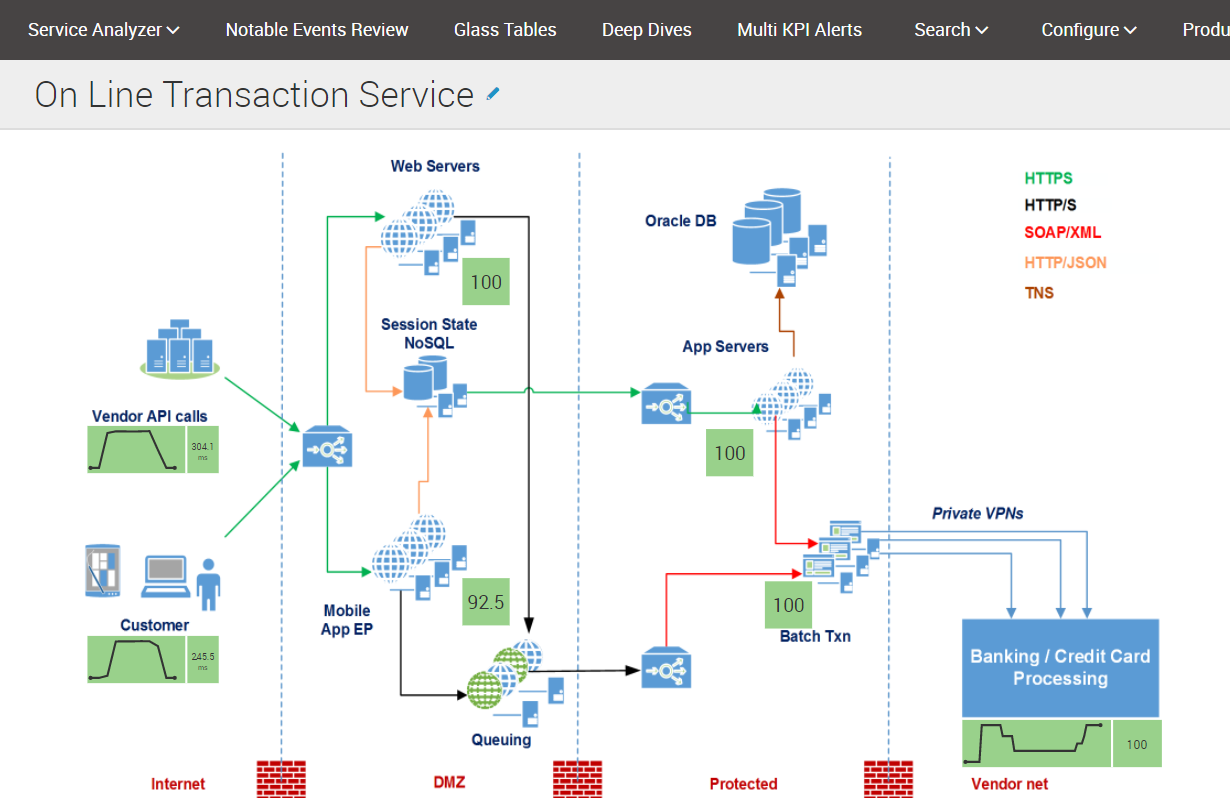
Далеко не всем пользователям удобно, понятно, да и просто необходимо разбираться в структуре всей системы для получения полезной информации. Glass Tables представляет собой наглядную и удобную визуализацию, которая будет понятна практически любому пользователю. «Таблицы» позволяют узнать о состоянии сервисов и значениях показателей эффективности в интерфейсе схем работы или бизнес-процессов. Для удобства можно использовать различные виджеты и значки для отображения показателей эффективности KPI.
После того, как мы узнали, как работаю сервисы, хочется узнать почему они так работают, какие события влияют на их работу и как-то повлиять на них. Для этого существует панель Notable Events Review.
Панель мониторинга «заметных событий» используется, чтобы увидеть предупреждения о проблемах, которые в настоящее время оказывают влияние на службы или могут потенциально повлиять на сервисы. Панель отображает заметные события предупреждения, генерируемые Multi KPI Alerts, корреляционными поисками и алгоритмами обнаружения аномалий.
Под «заметным событием» может подразумеваться:
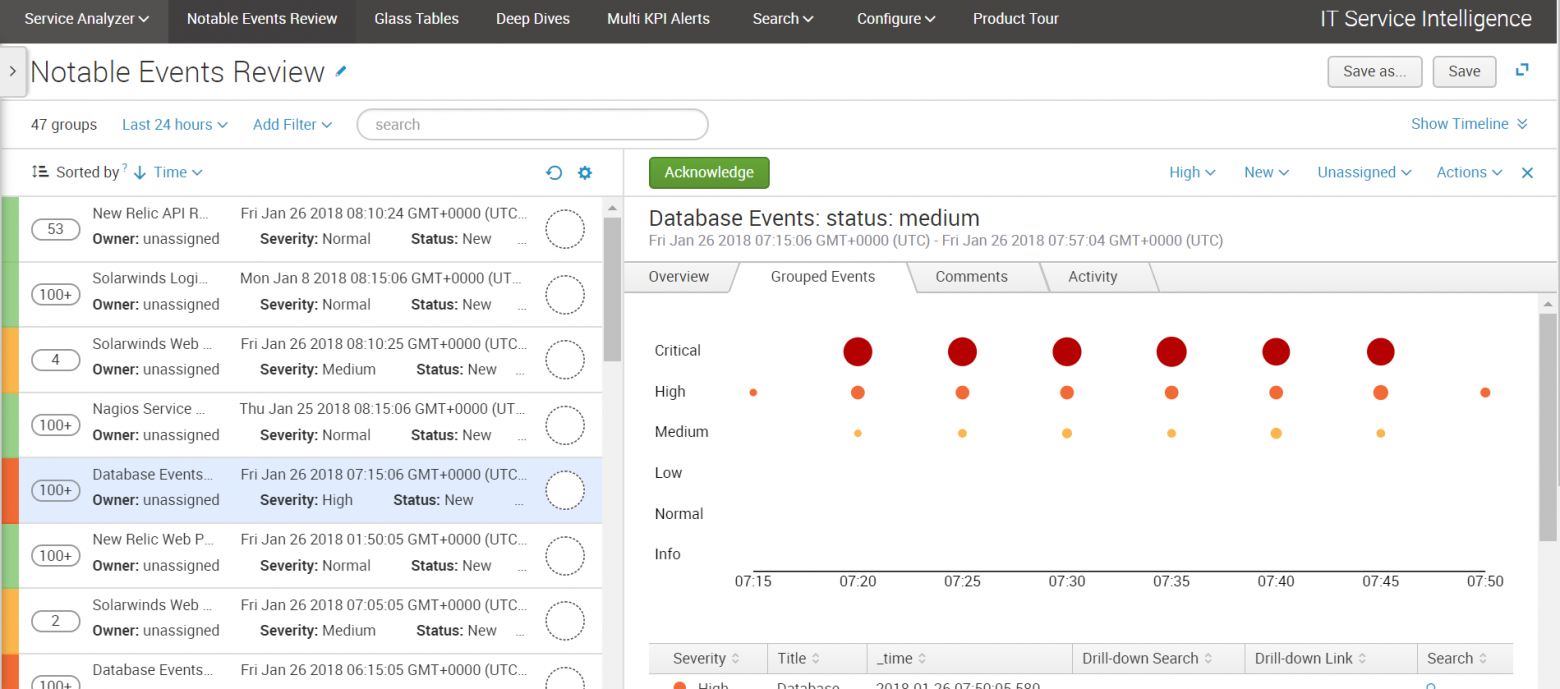
Для удобства предтавления все события сгруппированы с помощью алгоритмов машинного обучения, определяющее похожие события. На информационной панели отображаются сведения о каждой группе событий, такие как количество событий в группе, временной диапазон событий в группе, владелец, степень серьезности, статус и описание. Нажав на группу, можно получить детальную информацию о событиях внутри группы.
Мы можем управлять событиями, устанавливать определенные действия и скрипты на реализацию события, например, отправлять уведомления на электронную почту или во внешние системы.
Конечно, видя только состояние системы в данный момент, мы видим только верхушку айсберга. Поэтому весьма полезно иметь возможность мониторинга состояний в течении времени. Как долго продолжается снижение эффективности работы? Сейчас все хорошо, но были ли проблемы час-два или день назад? Почему?
В разделе Deep Dives добавляется история показателей KPI, то есть мы можем увидеть состояние системы не только сейчас, но и несколько часов назад и сравнить результаты работы разных элементов системы в один и тот же момент времени или сравнить результаты одного сервиса с тем что было день, неделю или месяц назад.
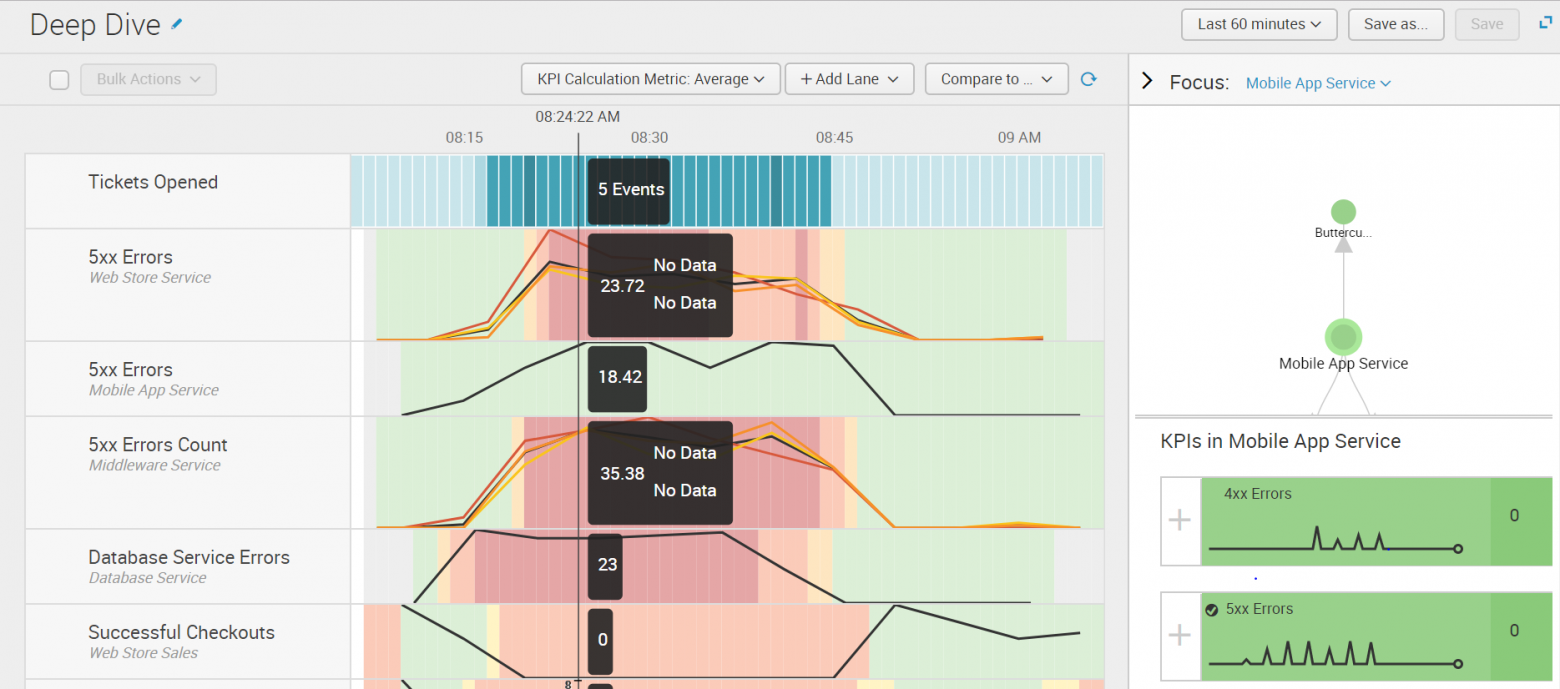
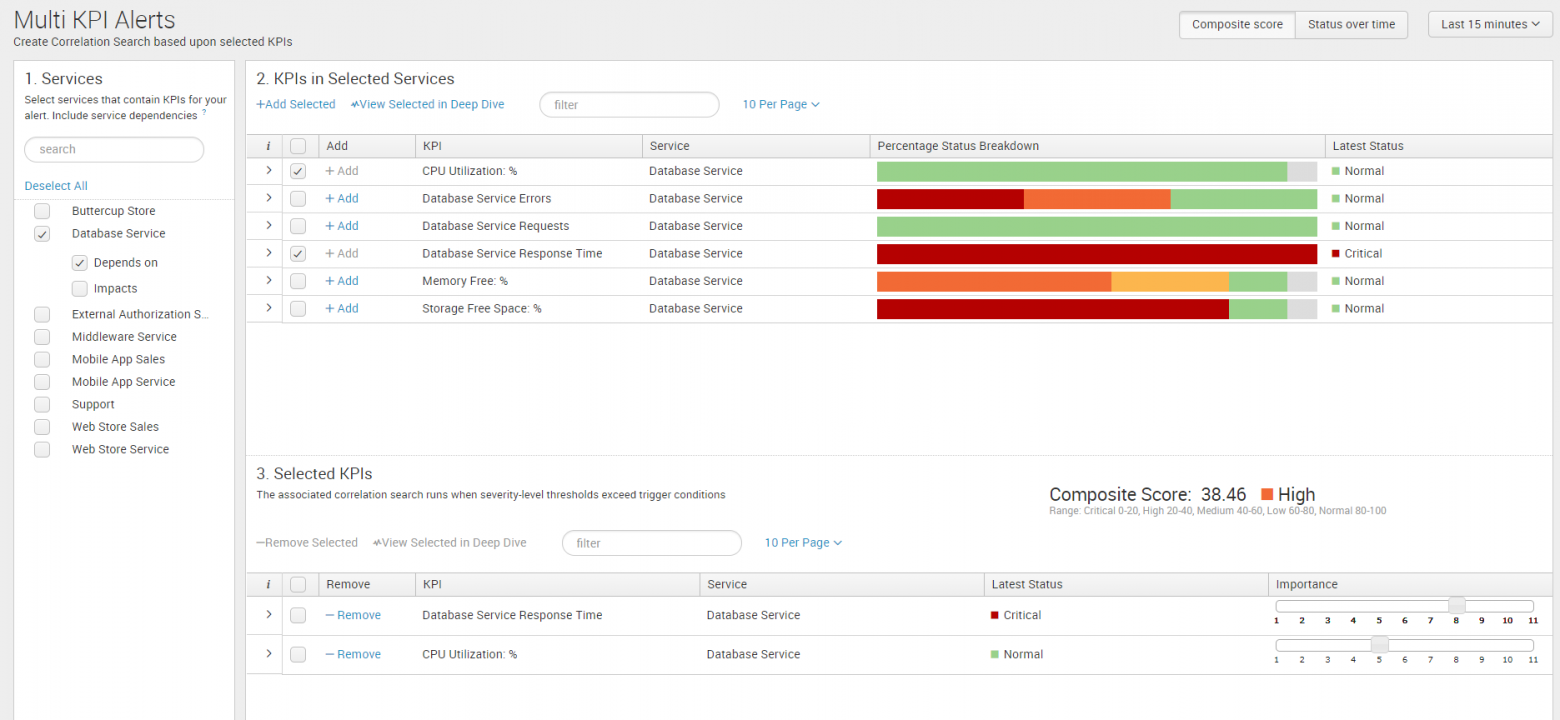
Часто о проблеме нам может сказать только совокупность факторов, поэтому необходима возможность срабатывания предупреждений, основанных на нескольких KPI или зависимых от продолжительности достижения показателем какого-то определенного значения.
В разделе Multi KPI Alerts возможно создание таких композиционных показателей эффективности, в которых можно учитывать вес влияния каждого фактора на общую проблему.
Резюмируя описанное выше:
Описанные выше примеры не охватывают на 100% весь функционал системы, но в целом позволяют решить основные задачами компаниям с широкими IT ландшафтами. Совершенно точно можно сказать, что ITSI просто необходим для тех, кто хочет держать свою IT-инфраструктуру под контролем.
Мы рады ответить на все ваши вопросы и комментарии по данной теме. Также, если вас интересует что-то конкретно в этой области, или в области анализа машинных данных в целом — мы готовы доработать существующие решения для вас, под вашу конкретную задачу. Для этого можете написать об этом в комментариях или просто отправить нам запрос через форму на нашем сайте.
Вы знаете, насколько эффективно работают элементы вашей IT- инфраструктуры? Как они влияют друг на друга? Может быть, какой-нибудь элемент ухудшает работу системы в целом? Как понять, что это за элемент?
В нашей статье мы хотим рассказать о решении, которое может помочь в анализе и мониторинге эффективности работы как каждого отдельного элемента, так и всей IT-системы в целом, определения зависимостей между сервисами, оповещения при изменении показателей эффективности ниже или выше порогового уровня.
Речь идет о Splunk IT Service Intelligence (ITSI). Это инструмент для мониторинга и анализа работы IT-инфраструктуры, работающий на платформе операционной аналитики Splunk, о котором мы рассказывали ранее.
Платформа позволяет собирать, мониторить данные с различных устройств, систем и приложений. Процесс работы ITSI обеспечивает видимость показателей работоспособности элементов системы, основных KPI, а также поведения критически важных IT- и бизнес-сервисов и связанных с ними поддерживающих сервисов.
С помощью одного инструмента можно решить множество задач в области IT, в том числе анализ событий, метрик, журналов, позволяющий идентифицировать и исправить наиболее важные проблемы в работе элементов IT-инфраструктуры.
Давайте рассмотрим основные элементы Splunk IT Service Intelligence, а также зачем они нужны:
Service Analyzer
Это очевидно, что всем хочется получить наиболее важную информацию максимально понятно и быстро. Именно для этого служит стартовая страница ITSI — Service Analyzer. Заходя в приложение, можно одним взглядом оценить общую уровень работы всей IT-системы.
Существует два представления Service Analyzer: вид плитки и древовидная структура, которая позволяет видеть, как одни сервисы влияют на другие.
В виде плиток представлены показатели работоспособности и основные связанными с ними KPI, имеющие цветовой индикатор и отсортированные по текущему уровню состояния.
Древовидное представление отображает все сервисы в виде графа, в котором узлы показывают уровень работоспособности узла. Каждый узел можно раскрыть и увидеть связанные с ним показатели эффективности.
В приведенном ниже примере служба магазина Buttercup зависит от продаж веб-магазина, продаж мобильных приложений, службы веб-магазина, служб мобильного приложения и служб поддержки. Служба мобильных приложений зависит от службы промежуточного ПО и службы внешней авторизации, которая зависит от работы базы данных.
Glass Tables
Далеко не всем пользователям удобно, понятно, да и просто необходимо разбираться в структуре всей системы для получения полезной информации. Glass Tables представляет собой наглядную и удобную визуализацию, которая будет понятна практически любому пользователю. «Таблицы» позволяют узнать о состоянии сервисов и значениях показателей эффективности в интерфейсе схем работы или бизнес-процессов. Для удобства можно использовать различные виджеты и значки для отображения показателей эффективности KPI.
Notable Events Review
После того, как мы узнали, как работаю сервисы, хочется узнать почему они так работают, какие события влияют на их работу и как-то повлиять на них. Для этого существует панель Notable Events Review.
Панель мониторинга «заметных событий» используется, чтобы увидеть предупреждения о проблемах, которые в настоящее время оказывают влияние на службы или могут потенциально повлиять на сервисы. Панель отображает заметные события предупреждения, генерируемые Multi KPI Alerts, корреляционными поисками и алгоритмами обнаружения аномалий.
Под «заметным событием» может подразумеваться:
- Один из KPI, если он превышает заданный порог;
- Результат работы Multi KPI Alerts, который генерирует предупреждение, основанное на состоянии нескольких KPI;
- Результат корреляционного поиска, который ищет отношения между точками данных.
Для удобства предтавления все события сгруппированы с помощью алгоритмов машинного обучения, определяющее похожие события. На информационной панели отображаются сведения о каждой группе событий, такие как количество событий в группе, временной диапазон событий в группе, владелец, степень серьезности, статус и описание. Нажав на группу, можно получить детальную информацию о событиях внутри группы.
Мы можем управлять событиями, устанавливать определенные действия и скрипты на реализацию события, например, отправлять уведомления на электронную почту или во внешние системы.
Deep Dives
Конечно, видя только состояние системы в данный момент, мы видим только верхушку айсберга. Поэтому весьма полезно иметь возможность мониторинга состояний в течении времени. Как долго продолжается снижение эффективности работы? Сейчас все хорошо, но были ли проблемы час-два или день назад? Почему?
В разделе Deep Dives добавляется история показателей KPI, то есть мы можем увидеть состояние системы не только сейчас, но и несколько часов назад и сравнить результаты работы разных элементов системы в один и тот же момент времени или сравнить результаты одного сервиса с тем что было день, неделю или месяц назад.
Multi KPI Alerts
Часто о проблеме нам может сказать только совокупность факторов, поэтому необходима возможность срабатывания предупреждений, основанных на нескольких KPI или зависимых от продолжительности достижения показателем какого-то определенного значения.
В разделе Multi KPI Alerts возможно создание таких композиционных показателей эффективности, в которых можно учитывать вес влияния каждого фактора на общую проблему.
Заключение
Резюмируя описанное выше:
- Services и KPIs показывают, какие сервисы в данный момент работают нормально, а какие имеют отклонения.
- Glass Tables позволяют сгруппировать показатели по специфическим группам и наглядно визуализировать их.
- Deep Dives позволяет сравнивать состояние показателей во времени и определять из какого источника началась та или иная проблема.
- Multu-KPI Alerts и Notable Events выявляют какие-то конкретные важные события и позволяют управлять ими.
Описанные выше примеры не охватывают на 100% весь функционал системы, но в целом позволяют решить основные задачами компаниям с широкими IT ландшафтами. Совершенно точно можно сказать, что ITSI просто необходим для тех, кто хочет держать свою IT-инфраструктуру под контролем.
Мы рады ответить на все ваши вопросы и комментарии по данной теме. Также, если вас интересует что-то конкретно в этой области, или в области анализа машинных данных в целом — мы готовы доработать существующие решения для вас, под вашу конкретную задачу. Для этого можете написать об этом в комментариях или просто отправить нам запрос через форму на нашем сайте.
