
Чуть больше года назад мы делали обзор на приложение Splunk Machine Learning Toolkit, с помощью которого можно анализировать машинные данные на платформе Splunk, используя различные алгоритмы машинного обучения.
Сегодня мы хотим рассказать о тех обновлениях, которые появились за последний год. Вышло множество новых версий, добавлены различные алгоритмы и визуализации, которые позволят поднять анализ данных в Splunk на новый уровень.
Новые алгоритмы
Прежде чем говорить о алгоритмах следует отметить, что существует ML-SPL API, с помощью которого можно подгрузить любой алгоритм с открытым кодом из более 300 алгоритмов на языке Python. Однако для этого необходимо в некоторой степени уметь программировать на Python.
Поэтому мы обратим внимание на те алгоритмы, которые раньше были доступны только после манипуляций с Python-ом, а сейчас внедрены в приложение и могут легко использоваться каждым.
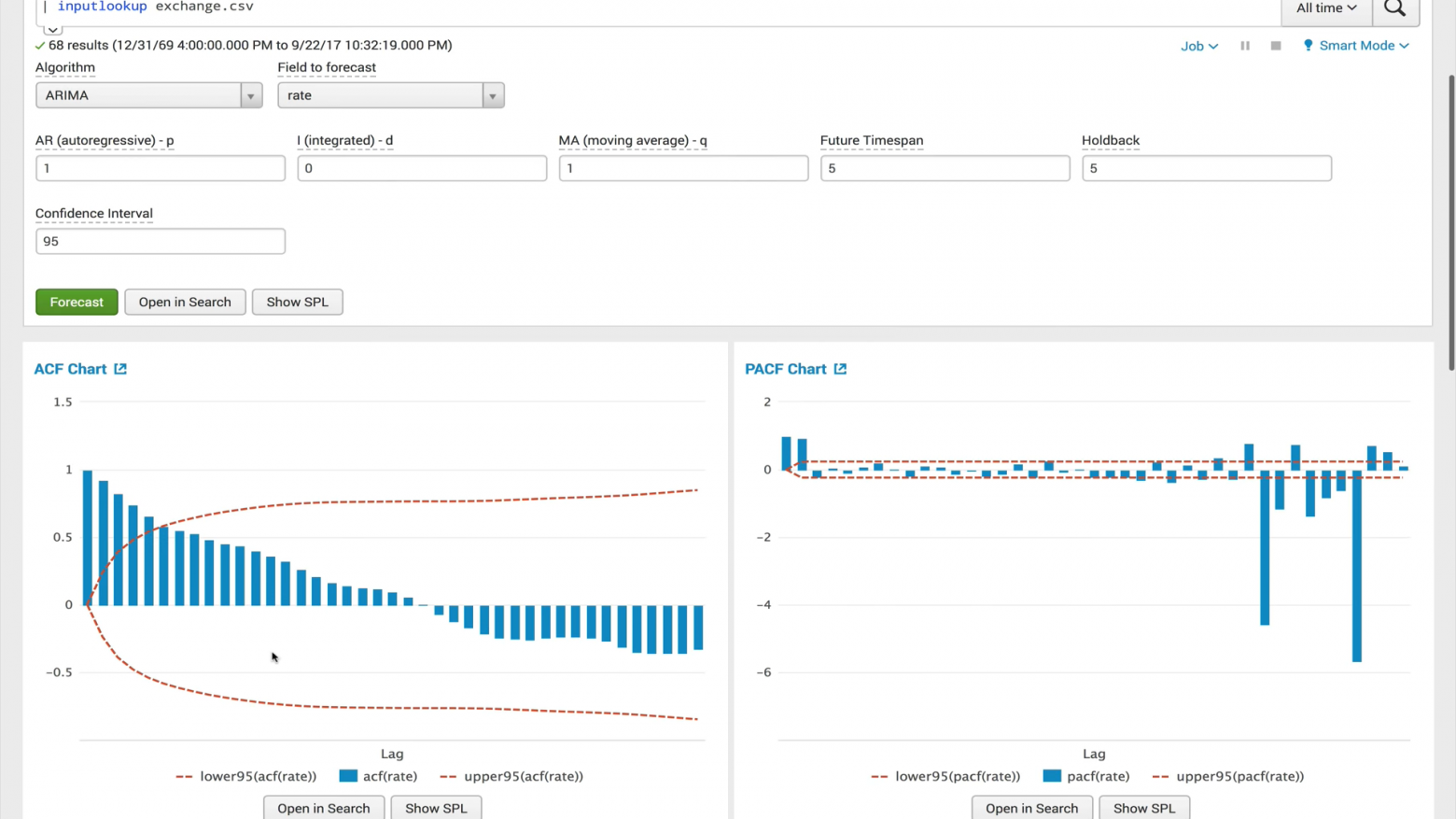
ACF (автокорреляционная функция)
Автокорреляционная функция показывает взаимосвязь между функцией и её сдвинутой копией на величину временного сдвига. ACF помогает находить повторяющиеся участки или определять частоту сигнала, скрытую из-за наложений шума и колебаний на других частотах.
PACF (функция частичной автокорреляции)
Частная автокорреляционная функция показывает корреляцию между двумя переменными, за вычетом влияния всех внутренних значений автокорреляции. Частная автокорреляция на определенном лаге схожа с обычной автокорреляцией, но при её вычислении исключается влияние автокорреляций с меньшими лагами. На практике, частная автокорреляция даёт более «чистую» картину периодических зависимостей.
ARIMA (интегрированный процесс авторегрессии и скользящего среднего)
Модель ARIMA – одна из наиболее популярных моделей для построения краткосрочных прогнозов. Значения авторегрессии выражают зависимость текущего значения временных рядов от предыдущих, а скользящее среднее модели определяет влияние предыдущих ошибок прогноза (также называемых белым шумом) на текущее значение.
Gradient Boosting Classifier и Gradient Boosting Regressor
Градиентный бустинг – это метод машинного обучения, используемый для задач регрессии и классификации, который создает модель прогнозирования в виде ансамбля слабых моделей, обычно деревьев решений. Он строит модель поэтапно, когда каждый следующий алгоритм стремится компенсировать недостатки композиции всех предыдущих алгоритмов. Изначально понятие бустинга возникло в работах в связи с вопросом, возможно ли, имея множество плохих (незначительно отличающихся от случайного определения) алгоритмов обучения, получить хороший. В течение последних 10 лет бустинг остаётся одним из наиболее популярных методов машинного обучения, наряду с нейронными сетями. Основные причины — простота, универсальность, гибкость (возможность построения различных модификаций), и, главное, высокая обобщающая способность.
X-means
Алгоритм кластеризации X-means представляет собой расширенный алгоритм k-means, который автоматически определяет количество кластеров на основе информационного байесовского критерия (BIC). Этот алгоритм удобно использовать, когда нет предварительной информации о числе кластеров, на которые эти данные могут быть разделены.
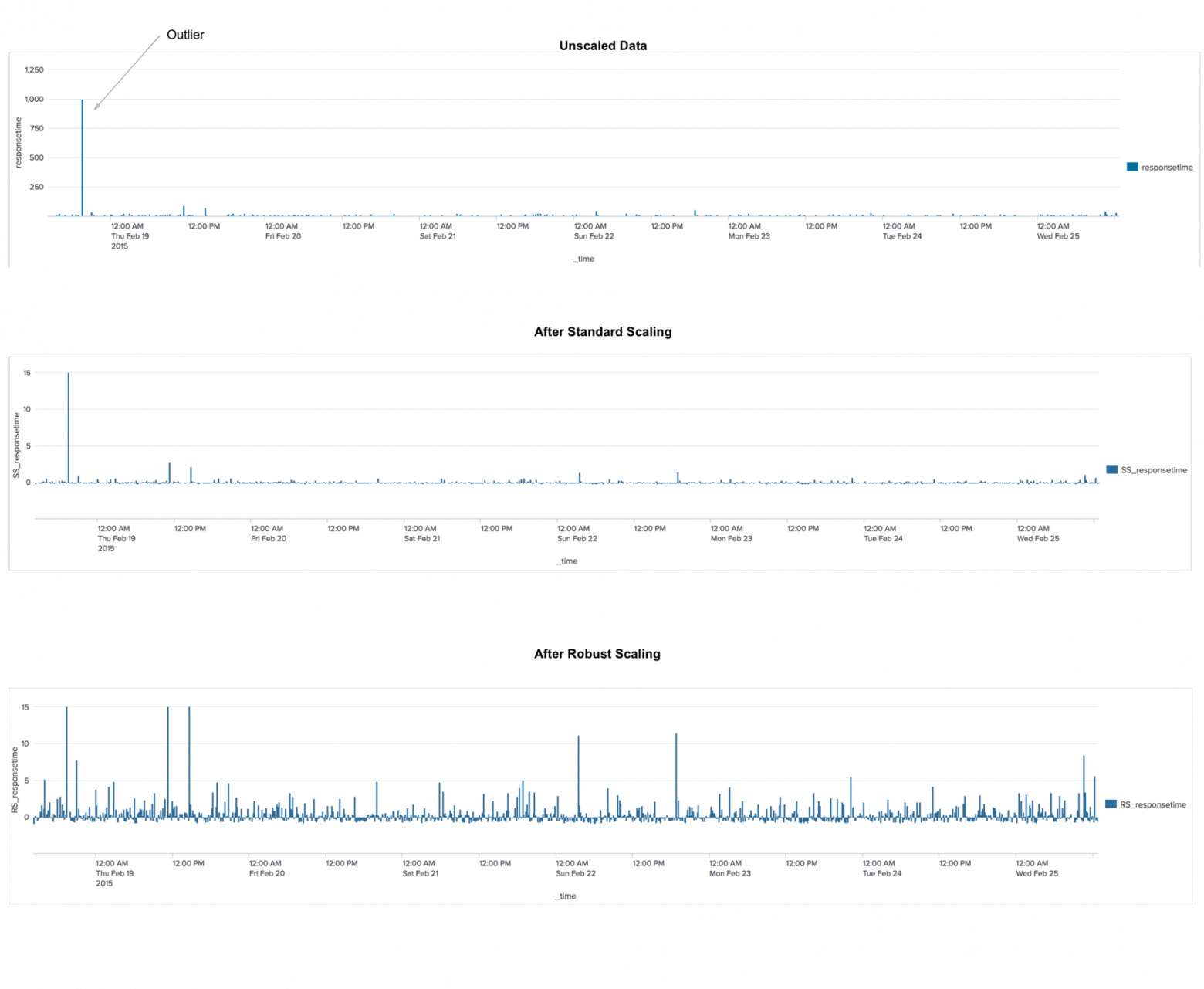
RobustScaler
Это алгоритм предварительной обработки данных. По применению схож с алгоритмом StandardScaler, который преобразует данные так, что для каждого признака среднее будет равно 0, а дисперсия будет равна 1, в результате чего все признаки будут иметь один и тот же масштаб. Однако это масштабирование не гарантирует получение каких-то конкретных минимальных и максимальных значений признаков. RobustScaler аналогичен StandardScaler в том плане, что в результате его применения признаки будут иметь один и тот же масштаб. Однако RobustScaler вместо среднего и дисперсии использует медиану и квартили. Это позволяет RobustScaler игнорировать выбросы или ошибки измерений, которые могут стать проблемой для остальных методов масштабирования.
TFIDF
Статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью коллекции документов. Принцип такой: если слово встречается в каком-либо документе часто, при этом встречаясь редко во всех остальных документах, следовательно это слово имеет большую значимость для того самого документа.
MLPClassifier
Первый алгоритм нейронных сетей в Splunk. Алгоритм построен на основе многослойного персептрона, который позволит улавливать нелинейные отношения в данных.

Администрирование
В новых версиях существенно преобразилось администрирование приложения.
Во-первых, добавлена ролевая модель доступа к различным моделям и экспериментам.
Во-вторых, внедрен новый интерфейс для управления моделями. Теперь можно легко увидеть, какие типы моделей у вас есть, проверить настройки каждой модели (например, какие переменные использовались для ее обучения) и просмотреть или обновить настройки совместного доступа к каждой модели.
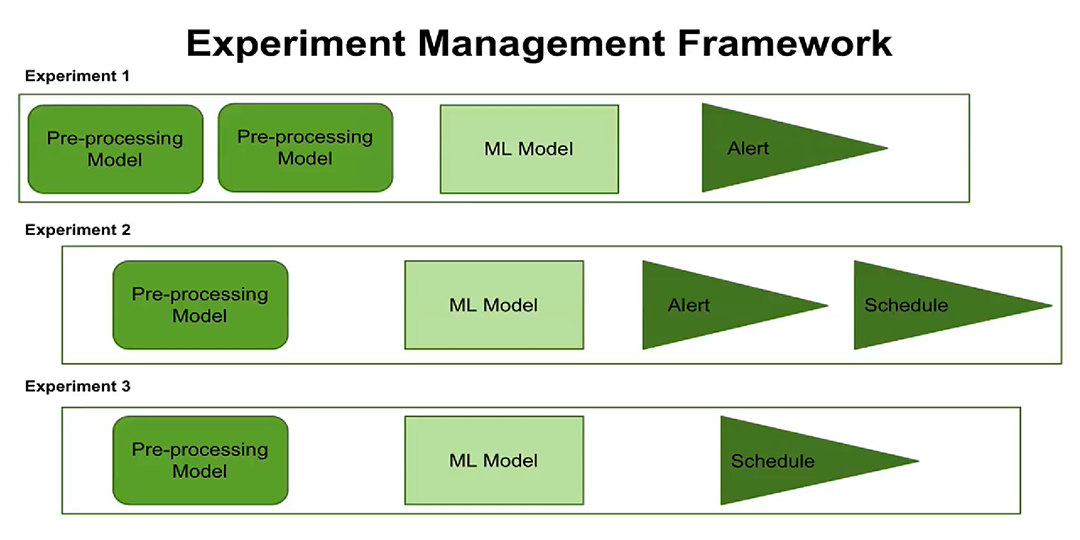
В-третьих, появление концепции управления экспериментами. Теперь можно настроить выполнение экспериментов по расписанию, настроить оповещения. Пользователи могут увидеть, когда запланировано выполнение каждого эксперимента, какие этапы обработки и параметры настроены для каждого эксперимента.
Новая концепция управления экспериментами теперь дает вам возможность создавать и управлять несколькими экспериментами сразу, записывать, когда эти эксперименты выполнялись и какие результаты были получены.
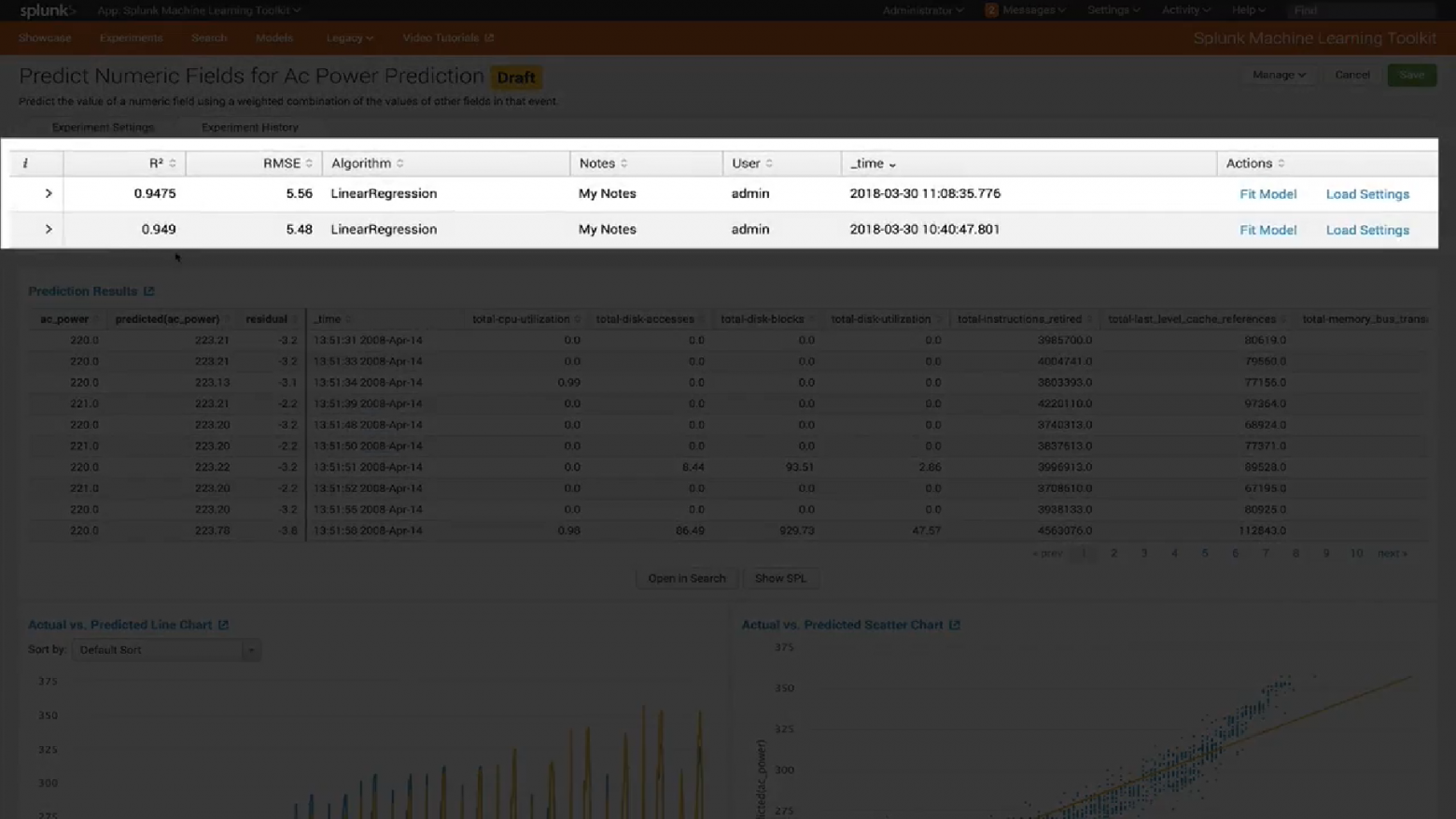
Визуализация
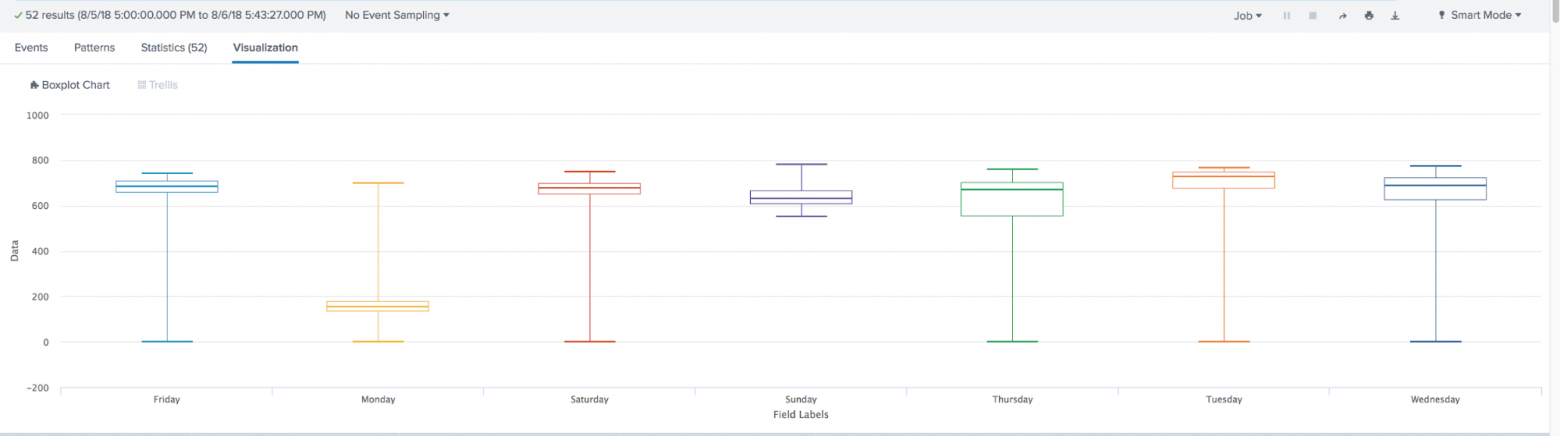
В последней версии MLTK 3.4 был добавлен новый тип визуализации. Знаменитый Box Plot или, как у нас его еще называют, «Ящики с усами».
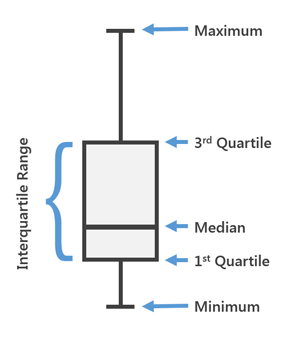
Box Plot используют в описательной статистике, с помощью него можно в удобной форме увидеть медиану (или, если нужно, среднее), нижний и верхний квартили, минимальное и максимальное значение выборки и выбросы. Несколько таких ящиков можно нарисовать бок о бок, чтобы визуально сравнивать одно распределение с другим. Расстояния между различными частями ящика позволяют определить степень разброса (дисперсии) и асимметрии данных и выявить выбросы.
Подводя итоги, за год машинное обучение в Splunk сделало большой шаг вперед. Появились:
- Множество новых встроенных алгоритмов, таких как: ACF, PACF, ARIMA, Gradient BoostingClassifier, Gradient Boosting Regressor, X-means, RobustScaler, TFIDF, MLPClassifier;
- Ролевая модель доступа и возможность управления моделями и экспериментами;
- Визуализация Box Plot

