Комментарии 31
Ваш бенчмарк выдает разные результаты даже у пустых исходников
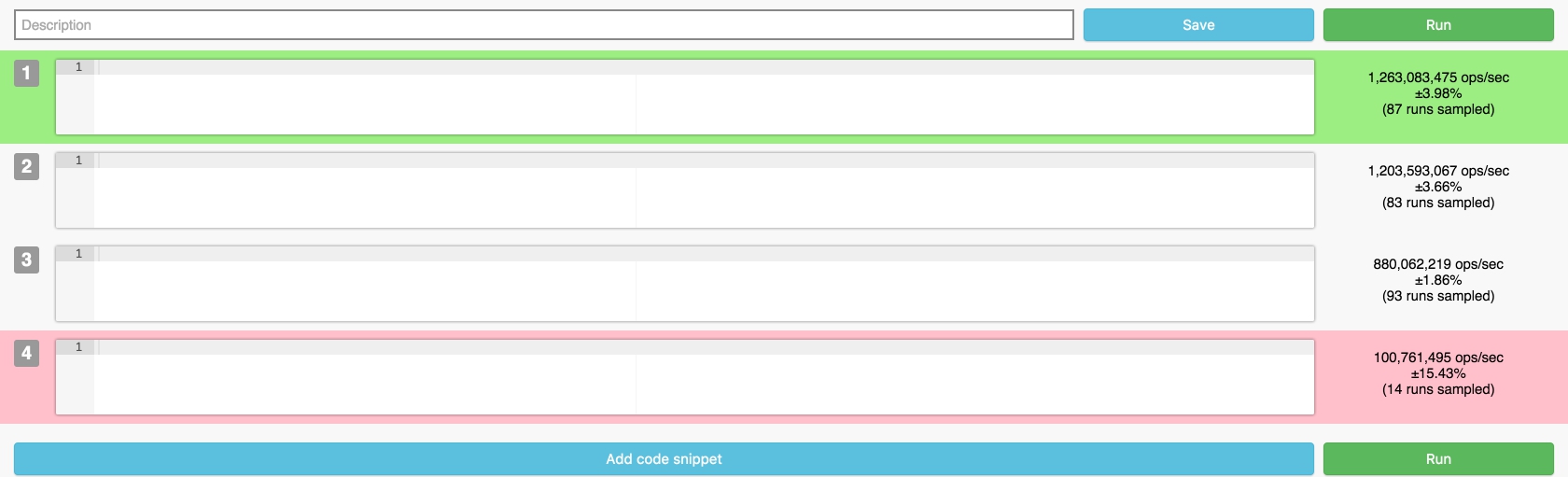
Как написано в статье, внутри используется benchmarkjs.com, это он выдает такие результаты, на jsperf ровно такая же картина с пустыми тестами. Такие результаты получаются из-за любого тормоза на вашем компьютере или переключением между вкладками, да даже движение мышки могло повлиять на результаты прогона пустышек. По сути вы протестировали работу самого benchmarkjs.
Да, и задача на исключение «пустышек» стоит: #15
Ага, при этом показывается погрешность результата ±4%. Это ж какая доверительная вероятность должна быть, чтобы так ошибиться? Или здесь что-то совсем не так, или этот benchmarkjs полное говнище, которое просто врет.
Вполне нормальная погрешность при прогоне «пустышки». На результат работы может повлиять любой «чих» в браузере во время прогона, например уход со страницы или её прокрутка, либо любые другие фоновые процессы. Если запустить этот же тест через NodeJS, будет примерно такая картина:
#1 x 749,382,154 ops/sec ±0.61% (100 runs sampled)
#2 x 753,619,434 ops/sec ±0.29% (100 runs sampled)
#3 x 748,112,204 ops/sec ±0.71% (98 runs sampled)
#4 x 742,616,805 ops/sec ±0.66% (94 runs sampled)
#1 x 749,382,154 ops/sec ±0.61% (100 runs sampled)
#2 x 753,619,434 ops/sec ±0.29% (100 runs sampled)
#3 x 748,112,204 ops/sec ±0.71% (98 runs sampled)
#4 x 742,616,805 ops/sec ±0.66% (94 runs sampled)
Фактическая погрешность то может и нормальная, только вот это не отменяет того факта, что бенчмарк тупо врет: зачем показывать пределы погрешности в несколько процентов, если на любом простом примере видно что это не правда?
Я так не считаю, во вторых, отличается он в Chrome/V8, например в FireFox картина ровная, как и в Safari. + у меня Chrome результаты немного отличается, первый тест чуть «медленней», последующие уже ровные.
Это не погрешность измерений, а разброс результатов.
Да, и они наглядно демонстрируют, что бенчмарк не состоятелен. Кстати, разброс результатов тоже должен считаться с определенной и вполне конкретной доверительной вероятностью. А я так понимаю, никто даже не знает ни какая она, ни по какой формуле считается результат.
Очень много умных слов использовано в довольно бессмысленном тексте. :(
Каждый инструмент предназначен для своих измерений. Пример выше показывает, что для измерения холостых циклов этот инструмент не подходит — уровень шумов системы слишком высок.
В принципе, можно при тестировании любой задачи запустить что-то вроде CPUburn и получить гигантский разброс результатов. И «доказать» несостоятельность бенчмарка, в которую даже кто-то необразованный поверит.
Каждый инструмент предназначен для своих измерений. Пример выше показывает, что для измерения холостых циклов этот инструмент не подходит — уровень шумов системы слишком высок.
В принципе, можно при тестировании любой задачи запустить что-то вроде CPUburn и получить гигантский разброс результатов. И «доказать» несостоятельность бенчмарка, в которую даже кто-то необразованный поверит.
В принципе, можно при тестировании любой задачи запустить что-то вроде CPUburn и получить гигантский разброс результатов. И «доказать» несостоятельность бенчмарка, в которую даже кто-то необразованный поверит.Нет, потому что в этом случае хороший инструмент отобразит не только разбросы результатов, но и громадные допустимые интервалы.
Инструмент? Что он должен сделать? Написать — «Не трожь мышку, придурок!», — если разброс времени выполнения превышает 0.1 (взял из головы) от времени выполнения 1 итерации?
Не предполагается, что пользователь инструмента об этом должен быть в курсе и так? :)
Не предполагается, что пользователь инструмента об этом должен быть в курсе и так? :)
Я же написал вам, что дожно происходить в таком случае – бенчмарк должен отобразить большой разброс времени выполнения. А пользователь уже сам должен думать, как этот диапазон сузить (что ему не трогать, какие процесы завершить, какой приоритет браузеру поставить и т.д.).
Я пишу «должен» не потому, что у бенчмарка есть какие-то там обязательства перед пользователем, а потому что так, блин, работает статистика в нашем мире. А у benchmark.js видимо какая-то инопланетная статистика используется, если исходить из того, что он показывает в качестве результата.
Я пишу «должен» не потому, что у бенчмарка есть какие-то там обязательства перед пользователем, а потому что так, блин, работает статистика в нашем мире. А у benchmark.js видимо какая-то инопланетная статистика используется, если исходить из того, что он показывает в качестве результата.
Ну тогда JS Benchmark'и не для вас, ибо другого инструмента, для быстрого сравнения производительности в js нет, точнее есть, но он уже сложней и не про бенчмарки.
Ну и если откинуться на спинку стула и закрыть фоновые вкладки, результат в Chrome тоже выравнивается:
Chrome
FireFox
Safari
Еще раз: проблема не в том, что результаты отличаются, это как раз легко объяснить, а в том, что результаты бенчмарка выглядят так, будто бы ожидаемое время работы тестов действительно отличается. Нормальный бенчмарк должен был бы в этом случае показать, что мат. ожидания сильно отличаются, но и доверительный интервал достаточно большой для того, чтобы результаты имели возможность совпасть. В этом бенчмарке этого не происходит. И речь не только о «пустых» тестах. Любые одинаковые тесты выявляют эту проблему. Предлагаете запретить запускать одинаковые тесты, чтобы не палиться?
Тут мимоходом сформулирована, ЕМНИП, одна из задач на миллион. Будем ждать выхода такого бенчмарка. :)
Вы прикалываетесь? Речь идет о правильном применении статистики, не более того. Посмотрите как работает протокол синхронизации времени NTP, как он опрашивает различные сервера и пользуется доверительными интервалами для latency, у вас же я надеюсь не возникает сомнений, что он работает?
Вот так ведет себя нормальный бенчмарк в «хороших условиях»:
А вот так этот же бенчмарк ведет себя в условиях хаотичной нагрузки на CPU для четырех идентичных тестов:
Обратите внимание, как сильно увеличился разброс во втором случае и на то, что при любых обстоятельствах все результаты лежат в пределах интервалов погрешностей друг друга.
Вот так ведет себя нормальный бенчмарк в «хороших условиях»:
test tests::bench_a ... bench: 2,637 ns/iter (+/- 410)
test tests::bench_b ... bench: 2,673 ns/iter (+/- 539)
test tests::bench_c ... bench: 2,688 ns/iter (+/- 438)
test tests::bench_d ... bench: 2,666 ns/iter (+/- 502)
А вот так этот же бенчмарк ведет себя в условиях хаотичной нагрузки на CPU для четырех идентичных тестов:
test tests::bench_a ... bench: 3,015 ns/iter (+/- 1,647)
test tests::bench_b ... bench: 3,438 ns/iter (+/- 6,231)
test tests::bench_c ... bench: 3,366 ns/iter (+/- 2,614)
test tests::bench_d ... bench: 3,095 ns/iter (+/- 2,632)
Обратите внимание, как сильно увеличился разброс во втором случае и на то, что при любых обстоятельствах все результаты лежат в пределах интервалов погрешностей друг друга.
Тут ключевое слово «хаотичной».
Объясните пожалуйста, что вы имеете ввиду. Вот результаты, когда сторонняя нагрузка случилась во время выполнения первых двух тестов, и не затронула последние два:
test tests::bench_a ... bench: 2,825 ns/iter (+/- 1,167)
test tests::bench_b ... bench: 3,179 ns/iter (+/- 1,343)
test tests::bench_c ... bench: 2,491 ns/iter (+/- 458)
test tests::bench_d ... bench: 2,630 ns/iter (+/- 410)
Видно, что нагрузка точечная, т.е. сильно изменяется разброс, но при этом среднее (или это медиана?) меняется не сильно.
Потому естественно, все средние попадают в диапазоны разброса друг-друга.
В примере с пустыми тестами же было видно, что нагрузка просто нагибает тестера, и со стороны инструмента нет никакой возможности понять, виноват в этом тестируемый код или нет.
Гипотетически. Если взять bench_b и запустить его на процессоре на 3-4 семейств старше, то его данные будут ровными (т.е. с малым разбросом), но при этом с заметно отличающимся от остальных тестов средним.
Ну или более наглядный пример: стрельба из ружья. Одно дело трясти ружье и другое — просто поменять гравитацию для одного из тестов. Инструмент не знает что происходит «снаружи», он видит только набор дырок на мишени и оценивает их кучность и место.
Равенство условий тестов между собой — задача тестировщика, а не инструмента.
ИМХО. :)
P.S. О, кто-то добрый сделал мне 1 раз в 5 минут :)
Так что отвечу на второй комментарий тоже тут.
При низких результатах разброс не обязан быть большим. Они могут быть стабильно низкими ;)
Потому естественно, все средние попадают в диапазоны разброса друг-друга.
В примере с пустыми тестами же было видно, что нагрузка просто нагибает тестера, и со стороны инструмента нет никакой возможности понять, виноват в этом тестируемый код или нет.
Гипотетически. Если взять bench_b и запустить его на процессоре на 3-4 семейств старше, то его данные будут ровными (т.е. с малым разбросом), но при этом с заметно отличающимся от остальных тестов средним.
Ну или более наглядный пример: стрельба из ружья. Одно дело трясти ружье и другое — просто поменять гравитацию для одного из тестов. Инструмент не знает что происходит «снаружи», он видит только набор дырок на мишени и оценивает их кучность и место.
Равенство условий тестов между собой — задача тестировщика, а не инструмента.
ИМХО. :)
P.S. О, кто-то добрый сделал мне 1 раз в 5 минут :)
Так что отвечу на второй комментарий тоже тут.
При низких результатах разброс не обязан быть большим. Они могут быть стабильно низкими ;)
Видно, что нагрузка точечная, т.е. сильно изменяется разброс, но при этом среднее (или это медиана?) меняется не сильно.Там используется медина, поскольку это позволяет уменьшить влияние выбросов. Именно из-за использования медианы разброс изменяется «не сильно».
Ваш пример с ружьем и изменением гравитации не совсем корректен, потому что не соответствует тому, как работает процессор. Реально в один момент времени у вас выполняется только один поток на ядро, так что гравитация будет скорее не «постоянным» явлением (систематическая ошибка), а «периодическим» (иногда влиять на пулю, а иногда нет).
Чем больше время выполнения одной итерации, тем значительнее мешающий поток будет замедлять результаты. Если итерация теста выполняется очень быстро (например, если речь идет о пустом тесте), то довольно часто будут происходить ситуации, когда целая итерация будет выполнена в тот момент, когда мешающий поток будет спать и не будет влиять на время конкретно этой итерации вообще. Именно из-за этого будет сильно увеличиватся разброс времени выполнения.
К тому же «быстрые» тесты можно повторить большее количество раз, в то время как «тяжелые» тесты приходится выполнять меньшее количество раз, что так же сказывается на точности результатов. Так что проблема «гравитации», которую вы описали, имеет отношение только к тяжелым тестам, но никак не к быстрым тестам и тем более пустышкам. Для таких тестов ситуация будет скорее похожа на то, как если бы вы трясли ружье, но только вниз, что кстати хорошо видно в том примере, который я выше привел: медиана просела, но доверительный интервал увеличился примерно на величину проседания медианы.
Равенство условий тестов между собой — задача тестировщика, а не инструмента.Полностью согласен, но инструмент должен сигнализировать о наличии проблемы с условиями тестирования. По-этому бенчмарки не просто показывают среднее или медиану, но еще указывают доверительный интервал, который позволяет оценить, насколько сильно можно доверять результату теста.
В данном случае интервал тоже отображается, но он не корректен, и позволяет мне сделать не верный вывод о том, что результаты тестов очень точны, хотя это очевидно не так.
Я не знаю как еще переформулировать фразу так, чтобы она стала понятной.
Может быть низкий разброс результатов внутри одного тестирования, но большой разброс между тестируемыми образцами. В этом случае инструмент не способен принять решения: виноваты тестируемые скрипты (мы же подразумеваем, что они разные) или же окружающая среда, о которой инструмент не имеет представления.
Но это все, конечно, теория. :) Возможно в тех либах кривой код.
Может быть низкий разброс результатов внутри одного тестирования, но большой разброс между тестируемыми образцами. В этом случае инструмент не способен принять решения: виноваты тестируемые скрипты (мы же подразумеваем, что они разные) или же окружающая среда, о которой инструмент не имеет представления.
Но это все, конечно, теория. :) Возможно в тех либах кривой код.
Может быть низкий разброс результатов внутри одного тестирования, но большой разброс между тестируемыми образцами.Теоретически да, но нужно очень сильно постаратся, чтобы добиться такой ситуации с нормальным бенчмарком (в предыдущем комментарии я объяснил почему). И, опять же, такое поведение можно будет добится только для тяжелых тестов. Для быстрых тестов и тестов пустышек как не нагружай, получите вот это:
test tests::bench_a ... bench: 80 ns/iter (+/- 40)
test tests::bench_b ... bench: 86 ns/iter (+/- 14)
test tests::bench_c ... bench: 188 ns/iter (+/- 2,588)
test tests::bench_d ... bench: 186 ns/iter (+/- 2,597)
В последних двух тестах шла постоянная нагрузка на все ядра с повышенным приоритетом. Так что я не представляю, как вы практически собираетесь изменить медиану, не затронув разброс.
Ещё раз: результат идентичного куска кода будет отличаться, не сильно, но будет, происходит это из-за множества внешних, а главное внутренних факторов (фоновых процессов, применение оптимизаций и т.п.) браузерных js-движков, которые нельзя изолировать.
Последний раз: у меня нет претензий к тому, что результаты тестов отличаются, у меня претензия к тому, что библиотека не умеет правильно измерять разброс для таких результатов.
Задача бенчмарка не только посчитать среднее арифметисеское времени работы всех запусков, но и правильно оценить диапазон, в котором лежит реальное время работы. В противном случае толку от такого бенчмарка?
Задача бенчмарка не только посчитать среднее арифметисеское времени работы всех запусков, но и правильно оценить диапазон, в котором лежит реальное время работы. В противном случае толку от такого бенчмарка?
Если кому-то еще интересно запускать тесты с jsperf на ноде, то я тут пытался автоматизировать это дело: github.com/OrKoN/jsperf
Автор, если подскажете, как правильно скачивать тесты с jsbench, то я думаю, что смогу поддерживать jsbench в том числе.
Автор, если подскажете, как правильно скачивать тесты с jsbench, то я думаю, что смогу поддерживать jsbench в том числе.
Сохраненный тест, это простой gist из двух файлов html и js, вот пример: gist.github.com/RubaXa/a4612afd0cd26e911ee8
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Создаём проект c OAuth и NoSQL за $0,00