

Планировщик распределенных ресурсов (Distributed Resource Scheduler, DRS) — необходимый компонент любой виртуализированной среды, за исключением редких случаев с небольшой и ненагруженной инфраструктурой. Основная цель DRS — выровнять нагрузку на хостах, находящихся внутри вычислительного кластера, таким образом, чтобы виртуальные машины (ВМ) и развернутые на них приложения всегда получали ресурсы в нужном объеме и работали с максимальной эффективностью, а количество задействованных физических серверов при этом оставалось минимальным.
В облаке Mail.ru Cloud Solutions используется собственная реализация механизма DRS. Я Артем Карамышев, руководитель команды системного администрирования, расскажу о базовых принципах, на которых строится работа DRS у нас в облаке.
Что такое DRS и для чего нужна балансировка в облаке
Термин DRS был впервые введен компанией VMware по названию одноименной утилиты VMware DRS, предназначенной для балансировки кластера виртуальных машин. Сбалансированным считается такой кластер, в котором хосты равномерно распределены между виртуальными машинами с точки зрения потребления ресурсов и не возникает ситуации, когда, например, один хост используется на 99%, а другой на 30%.
При подключении новой виртуальной машины к кластеру ей, как правило, автоматически выделяется наиболее оптимальный хост, исходя из ее требований к потребляемым ресурсам и состояния кластера в целом. Но время от времени рабочие нагрузки виртуальных машин сильно изменяются, что может приводить к дисбалансу в распределении ресурсов и падению общей производительности. На некоторых хостах может остаться недостаточно ресурсов, в то время как другие будут простаивать. Задача DRS — вовремя обнаруживать такой дисбаланс и, в зависимости от выбранного уровня автоматизации, либо давать рекомендации по переносу ВМ, вызвавших дисбаланс, на менее загруженные хосты, либо выполнять эту миграцию автоматически.
Для поиска наиболее оптимального для каждой ВМ хоста обычно используется специальный автоматически запускаемый алгоритм, учитывающий текущее потребление ресурсов в кластере (память, процессорное время и так далее), а также требования к ресурсам, предъявляемые самой ВМ.
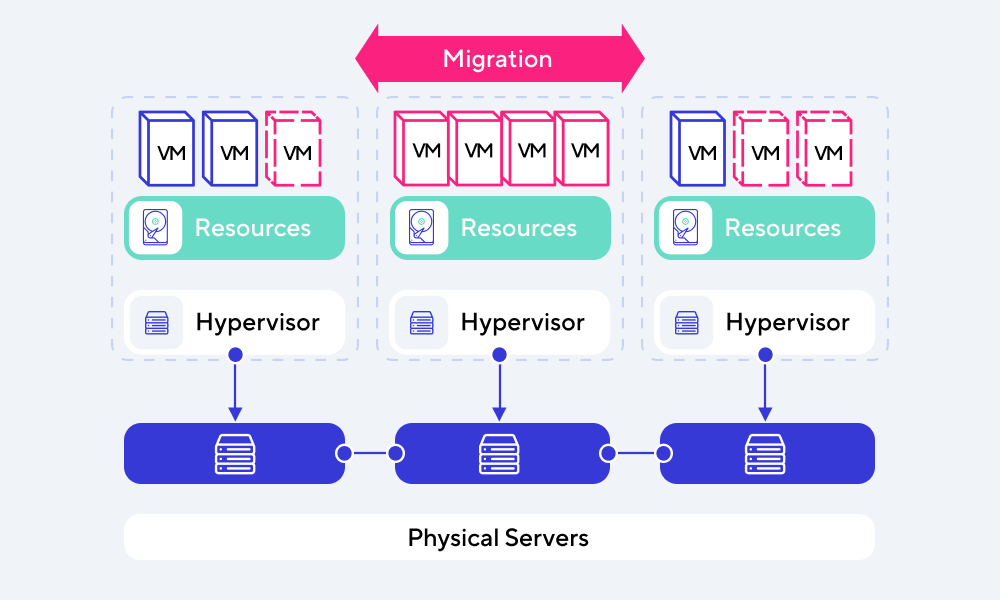
Упрощенная схема работы DRS: при обнаружении дисбаланса в кластере выполняется миграция ВМ на более оптимальные серверы
Для чего необходим DRS? Дело в том, что при отсутствии автоматизированного контроля распределение ВМ между серверами может быть крайне неэффективным. Вот лишь несколько возможных рисков:
Bin Packing Problem. Это риск «неравномерного» заполнения серверов виртуальными машинами и, соответственно, неоправданного увеличения используемых мощностей.
Невозможно заранее предсказать профиль нагрузки внутри виртуальной машины. Поэтому при определении оптимального гипервизора для создания виртуальной машины используются однозначные параметры: количество ядер, тип дисковой подсистемы, индивидуальные особенности флейвора виртуальной машины. В ходе последующей эксплуатации виртуальной машины может оказаться, что конкретно ее профиль нагрузки более (или, напротив, менее) требователен к утилизации процессора и памяти. При отсутствии DRS это крайне тяжело вовремя обнаружить, что приводит к неоптимальному использованию ресурсов.

Bin Packing Problem. Примеры неоптимального и оптимального распределения ВМ по хостам
На практике описанная проблема усложняется еще и тем, что далеко не всегда используемые физические серверы обладают одинаковой емкостью. Для построения кластеров всегда рекомендуется использовать однородное оборудование: это во многом облегчает распределение ресурсов. Но в реальной жизни конфигурации серверов, закупаемых в разное время, могут сильно различаться — по количеству ядер и мощности процессора, объему памяти, дисков и так далее. Условно говоря, в нашем примере capacity всех серверов будет не 1.4, а 1.7, 1.9, 1.5 и так далее. Кроме этого, нельзя допускать полной утилизации ресурсов на сервере: всегда должен оставаться некоторый «запас» — например, в нашем примере не подошли бы сервера с емкостью ресурсов 1. Все это еще больше усложняет ручное планирование.
Несвоевременный перенос на новые серверы в случае исчерпания ресурсов гипервизора. Если первый вид рисков не оказывает существенного влияния на клиентов облака, а лишь приводит к неэффективному использованию провайдером своих мощностей, то второй, напротив, способен существенно замедлить работу пользовательских приложений.
На гипервизоре выделение ресурсов виртуальным машинам происходит, как правило, с переподпиской. На 1 ядро процессора накладывается несколько ядер разных виртуальных машин. Поэтому, если одна из машин исчерпает выделенные ресурсы, это скажется на работе всех ВМ, размещенных на том же ядре.
Использование механизма DRS устраняет описанные риски и приносит провайдеру (а значит, и его клиентам) следующие преимущества:
- сохранение максимальной отзывчивости приложений клиентов,
- равномерное распределение нагрузки с учетом актуальных метрик с ВМ,
- повышение утилизации ресурсов и минимизация простоев оборудования,
- защита от распространенной ошибки клиентов, когда под ВМ запрашивается чрезмерное число ресурсов, не требующихся на практике.
Почему мы решили разрабатывать свое решение для DRS
Конечно, VMware DRS не единственный подобный продукт на современном IT-рынке. Наиболее известный аналог в мире OpenStack — Watcher. Однако очень часто облачные провайдеры разрабатывают свои решения. Почему так происходит? Причины могут быть разные. Чаще всего — высокая цена платных инструментов, а также недостаточность функционала бесплатных решений и/или обнаруживаемые в них сбои.
В нашем случае все было проще: DRS стал развиваться как часть уже существующей внутренней утилиты по управлению ресурсами OpenStack. Изначально эта утилита была направлена на то, чтобы облегчить работу службы поддержки. В программе можно отследить количество и состояние всех сущностей облака, включая виртуальные машины, гипервизоры, роутеры, диски, файловые хранилища, кластеры K8s, балансировщики нагрузки (Load Balancer As A Service, LBaaS) и многое другое. Утилита позволяет видеть текущее потребление ресурсов серверами и конкретными виртуальными машинами, а также прогнозировать изменение этих показателей в будущем. На основе данных, предоставляемых утилитой, оператор может своевременно видеть проблемы и находить пути их решения.
Так как всех данных, которые утилита уже извлекала для своей работы, было вполне достаточно для реализации DRS, на определенном этапе было принято решение добавить эти функции в утилиту. Это выглядело вполне логичным и обоснованным шагом, хотя сам процесс разработки оказался далеко не простым.
Схема работы DRS в облаке MCS
Схема работы DRS несколько раз менялась, совершенствуясь в ходе тестирования. Сейчас в промышленной эксплуатации находится следующая его форма:
Внутреннее название сервиса — Katana. Его бэкенд, написанный на Python, регулярно извлекает информацию о сущностях облака, используя OpenStack API. Под сущностями понимаются виртуальные машины, гипервизоры, диски и так далее. В выборку попадают только те характеристики, которые можно получить из OpenStack: количество элементов, их конфигурация и так далее. Утилизация ресурсов на этом этапе не извлекается.
Katana — Stateless-приложение, но для хранения своего кэша она использует memcached (MemCache). Отсюда данные впоследствии попадают в UI-утилиты для отображения операторам системы.
Фактически наша утилита представляет собой кэширующий слой для OpenStack. Все данные, которыми она оперирует, — это JSON, полученные из OpenStack и представленные в UI в табличном виде.
Для оптимальной работы алгоритма DRS данных из Openstack недостаточно. Поэтому сбор информации о фактическом использовании ресурсов с виртуальных машин производится с помощью специального сервиса katana-client раз в 10 секунд. Данные берутся из Libvirtd и носят инкрементный характер, так как для их получения используются нарастающие счетчики.
Данных, получаемых с katana-client, очень много, и они не преобразованы в значения per second. Поэтому собранные данные из katana-client передаются во вспомогательный HTTP + API сервис katana-collector.
Katana-collector выполняет расчет утилизации ресурсов в секунду на основе инкрементных данных, полученных из katana-client.
На основе полученных данных принимаются решения о балансировке различных кластеров гипервизоров.
Специальный алгоритм ищет гипервизоры, на которых утилизация процессора либо остаток свободной физической памяти выходят за рамки пороговых значений, указанных в настройках. Например, утилизация составляет 70% или количество физической памяти менее 64 GB. При обнаружении таких гипервизоров их ВМ перемещаются на гипервизоры с допустимым уровнем утилизации и свободной памяти — например, не более 50% и не менее 64 GB.
Для переноса выбираются, разумеется, не все ВМ с исходного гипервизора. Возможны следующие варианты:
На исходном гипервизоре чрезмерное потребление памяти. В этом случае будет выполнена миграция большого количества маленьких виртуальных машин для быстрого освобождения памяти до допустимого значения, заданного конфигурацией.
На исходном гипервизоре повышенная утилизация процессора. При таких условиях будет выполнена миграция наиболее сильно утилизирующих процессор виртуальных машин. Утилизация считается в отношении на 1 ядро, то есть в ситуации 4vCPU/400% (CPU Load) и 16vCPU/400% (CPU Load) будет выбрана виртуалка с 4 ядрами.
На исходном гипервизоре повышенная утилизация и памяти, и процессора. В таком случае для миграции будут выбраны самые небольшие ВМ, наиболее интенсивно использующие процессор. Используемая в алгоритмах функция нормализации построит дерево, которое будет в каждом случае индивидуальным.
Все фигурирующие в расчетах цифры хранятся в конфигурационном файле и при необходимости могут быть изменены. В случае ручной миграции, которая доступна непосредственно из UI утилиты, пороговые значения настраиваются в интерфейсе.
Если алгоритм, лежащий в основе автоматической миграции, находит ВМ, которые следует переместить для более оптимального распределения ресурсов, выполняется миграция с использованием OpenStack API.
Примечание: описание процесса авторизации осталось за пределами изображенной ниже схемы, но фактически пользователь получает всю информацию напрямую из Memcached через Nginx, без использования каких-либо Python-библиотек и так далее. При этом авторизация в утилите организована так, как если бы пользователь работал непосредственно с OpenStack с использованием его токена.
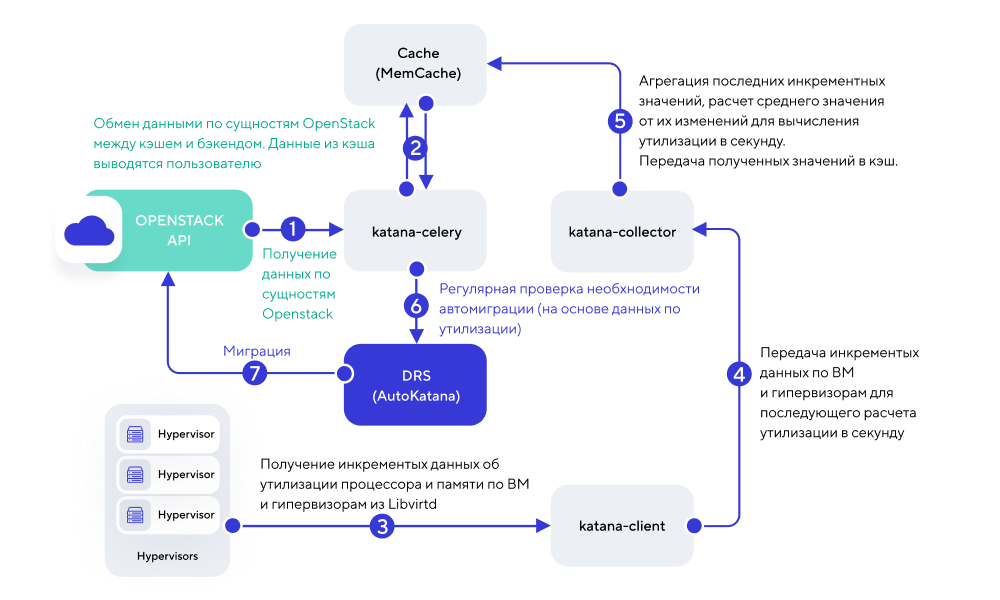
Схема работы DRS в облаке MCS. Базовые компоненты
Must-have-функции DRS и как они реализованы у нас
В хорошем решении DRS, я считаю, должны быть реализованы как минимум 5 основных функций:
Возможность выбора уровня автоматизации (вручную или автоматически). В нашем облаке миграции по умолчанию выполняются автоматически. Тем не менее мы выбираем, в каких кластерах гипервизоров использовать DRS, на основании регулярно проводимого анализа потребления ресурсов, подробно описанного выше. Однако дополнительно существует возможность проверить сбалансированность кластера и выполнить необходимые миграции вручную — непосредственно из самой утилиты.
Перед проведением миграции вручную оператору дается возможность установить произвольные пороговые значения для проверяемых ресурсов — отличные от тех, что берутся из конфигурационного файла при автоматических миграциях. Если в соответствии с введенными настройками будут обнаружены более оптимальные хосты для каких-либо ВМ, это будет указано в рекомендациях, на основании которых можно будет принять решение о необходимости миграций и запустить их.
Гибкая настройка пороговых значений для миграции. В нашей утилите предусмотрена возможность указания порогов для миграции как в ручном, так и в автоматическом режиме.
Ручная миграция может быть выполнена на уровне конкретной ВМ или гипервизора в целом. В первом случае ВМ уже выбрана и остается описать желаемый уровень утилизации ресурсов (CPU, память) на целевых гипервизорах, на которые планируется перенести эту ВМ. Во втором случае дополнительно указывается желаемый уровень утилизации CPU на исходном гипервизоре — для определения ВМ, подлежащих переносу.
Настройки для автоматической миграции указываются в отдельном конфигурационном файле. По своему составу они совпадают с параметрами ручной миграции на уровне гипервизора.
Возможность применения индивидуальных правил к определенным ВМ. Иногда может понадобиться запускать некоторые ВМ только на определенных хостах или держать группу ВМ всегда вместе — например, для соблюдения правил лицензирования или во избежание проблем с переносом ВМ, на которых установлено определенное ПО. Для реализации подобных ограничений у нас предусмотрены следующие функции:
VIP-проекты для исключения определенных ВМ из автоматических миграций. Это специальная отметка, запрещающая автоматический перенос. При необходимости такие ВМ всегда можно перенести вручную, выполнив миграцию на уровне конкретной ВМ или, в случае миграции на уровне гипервизора, указав в параметрах необходимость включения VIP-проектов.
Возможность выбора конкретной кастомной зоны (Availability Zone, AZ) или агрегата для миграции. Под агрегатом у нас понимается группа физических серверов, объединенная для какой-либо цели, например для размещения ресурсоемких приложений конкретного заказчика. По сути, зона доступности — это тот же агрегат, только более высокого уровня. При выполнении миграции вручную есть возможность явно указать зону доступности или агрегат, куда разрешено перемещать выбранные ВМ.
Получение сводки по использованию ЦП и памяти ВМ. Необходимость мониторинга, думаю, очевидна абсолютно для любой информационной системы. DRS в этом плане не исключение. В нашей утилите можно просматривать текущее потребление ресурсов (CPU и RAM) на уровне ВМ, физических серверов и агрегатов серверов.
Кроме этого, мы реализовали график, отображающий динамику потребления ресурсов по всему облаку за последние 365 дней. На графике можно увидеть, сколько в совокупности ресурсов было запрошено в каждый из дней прошедшего года. Это возможно за счет хранения даты создания всех ВМ.
Дополнительно на графике строится прогноз роста запрашиваемых ресурсов в будущем — на основе аппроксимации полиномов третьей степени методом наименьших квадратов. Если вкратце: график, построенный на основе реальных данных, достраивается графиком прогноза — полиномом третьей степени, максимально приближенным к линии, проходящей между всеми точками исходного графика. Ориентируясь на прогноз, можно своевременно предсказывать дальнейший рост облака.
Описанный график (включая прогноз) возможно построить и для других сущностей, не связанных с DRS, но отслеживаемых нашей утилитой: например, спрогнозировать рост количества дисков определенного типа, файловых хранилищ, роутеров, балансировщиков и так далее.
Поддержка «живых» миграций (Live Migration). «Живые» миграции, которые реализованы и у нас, не требуют остановки ВМ. Пользователи продолжают работать с исходным экземпляром ВМ до тех пор, пока ее данные не будут полностью перенесены на новый физический сервер. После копирования последних изменений из оперативной памяти пользователь продолжит работу с той же ВМ, которая фактически будет размещена уже на другом хосте.
Также в нашей утилите есть возможность просмотра состояния всех миграций в режиме реального времени: можно увидеть текущие и завершенные миграции, их статус, сведения о сервере-источнике и сервере-приемнике, о перенесенных ВМ и так далее.
С какими сложностями мы столкнулись
Как я уже говорил, процесс написания собственного DRS-решения был довольно непростым. Необходимо было подобрать наиболее оптимальный алгоритм, учитывающий множество факторов. Опишу некоторые из возникших сложностей и то, как их в конечном счете удалось решить:
Сбор метрик. Так как в самом OpenStack не было механизма получения метрик с гипервизоров и ВМ, пришлось разрабатывать собственные инструменты. Так появился демон katana-client, считывающий нужную нам информацию из Libvirtd. Однако возвращаемые им данные были инкрементными, так как для их получения использовались нарастающие счетчики. Поэтому мы дополнительно разработали компонент katana-collector — для агрегации последних полученных из katana-client значений, расчета дельт между ними и их усреднения. В результате мы стали получать нужную нам величину — утилизацию в секунду.
Выбор наиболее корректных метрик. Перед нами стояла задача максимально корректно определять загруженность гипервизоров. Если с оперативной памятью все было понятно, то утилизацию процессора мы пробовали находить различными способами. Изначально ориентировались на среднюю загрузку процессора (Load Average). Но впоследствии все алгоритмы были переписаны на использование метрики CPU Idle, показывающей процент свободного времени процессоров. В конечном итоге это оказалось более правильной метрикой для оценки ресурсов процессора.
Получение метрик с конкретных ВМ. Наряду с получением метрик по гипервизорам необходимо было получать аналогичную информацию по конкретным ВМ — для принятия решения о том, какие именно ВМ подлежат миграции в случае повышенной утилизации гипервизора. На первых этапах разработки сумма данных, получаемых с ВМ, расходилась с общими данными по гипервизору на 20–30%.
Правильным решением стало собирать информацию не только об утилизации всех «железных» подсистем гипервизора виртуалкой, но и об утилизации непосредственно со стороны клиентских процессов, запущенных в ней. К счастью, Libvirtd такие данные предоставлял. Мы провели ряд тестов, которые на практике подтвердили данную теорию: сумма утилизации всех виртуальных машин наконец стала совпадать с утилизацией всего сервера. Это привело к двум другим важным улучшениям:
В интерфейсе утилиты появилась возможность видеть утилизацию в разрезе конкретных виртуальных машин, а следовательно, быстро определять ВМ с наибольшим потреблением процессора и памяти.
Скорость выборок DRS — в частности, скорость вывода страниц с предлагаемыми для миграции гипервизорами — возросла в 10 раз, так как теперь все данные, участвующие в расчетах, были доступны на момент проведения миграции.
Подбор пороговых значений для автоматических миграций. В ходе тестирования мы неоднократно изменяли граничные значения утилизации ресурсов, используемые в расчетах, пытаясь вывести формулу «идеальной» сбалансированности облака. В качестве нижней границы, сигнализирующей о необходимости миграции, сейчас принято значение метрики CPU Idle 30%, но идеально для нас поддерживать данное значение не менее 50%. За достаточное количество памяти на гипервизоре принято значение 64 GB. Однако при необходимости эти границы всегда можно изменить.
Необходимость обработки ситуаций с нехваткой свободных ресурсов. В основе алгоритма лежит два простых шага: 1) выбор всех виртуальных машин для последующей миграции; 2) выбор подходящих хостов для миграции на них выбранных ранее виртуальных машин. Оптимальность второго шага определяется достаточным количеством свободных ресурсов в облаке. Таким образом, ошибки при выполнении этого шага неизбежны: может возникнуть ситуация, когда подходящие хосты не будут найдены. Алгоритм рассматривает эту ситуацию как штатную (выводя соответствующее уведомление), и это служит хорошим триггером для правильного capacity planning внутри облака.
Вместо заключения
Если вам понравилась статья и было бы интересно почитать ее продолжение с более детальной информацией на тему реализации DRS в облаке (включая код, используемый для загрузки метрик из Libvirtd, и другие технические подробности), пожалуйста, пишите комменты. Спасибо!
Погонять нашу облачную платформу можно тут.
