
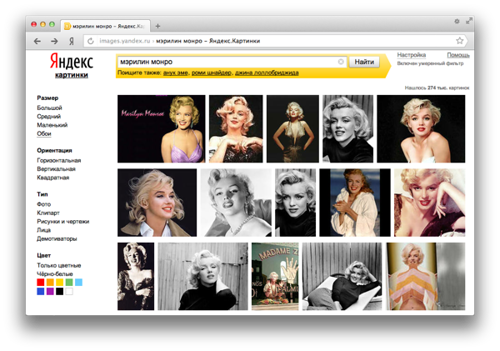
Каждый месяц на Яндексе поиском по картинкам пользуется больше 20 миллионов человек. И если кто-то из них ищет фотографии [Мэрилин Монро], это не значит, что им нужно найти лишь самые знаменитые снимки актрисы. В такой ситуации результаты, в которых большая часть найденных изображений будет копиями одних и тех же картинок, вряд ли устроят пользователей. Им придётся пролистать большое количество страниц, чтобы увидеть разные фотографии Монро. Для того чтобы облегчать людям подобные задачи, нам нужно сортировать картинки в результатах поиска так, чтобы они не повторялись. И мы научились «раскладывать их по полочкам».
Когда в 2002 году в Яндексе появился поиск по картинкам, технологий, позволяющих компьютерам непосредственно «видеть», какие объекты есть на изображении, не было вообще. Они появляются сейчас, но пока степени их развития не достаточно для того, чтобы компьютер узнавал в лицо Мэрилин Монро или распознавал на фотографии лес и сразу показывал его по соответствующему запросу. Поэтому задача совершенствовать те методы, которые были придуманы на первых этапах, остаётся актуальной.
Итак, компьютеру всё равно нужно понять, что изображено на картинке. Он не умеет «видеть», но при этом у нас есть технологии, которые хорошо ищут текстовые документы. И именно они нам им и помогут: изображение в интернете почти всегда сопровождается каким-то текстом. Он необязательно непосредственно описывает то, что изображено на картинке, но почти всегда связан с ней по смыслу и содержанию. То есть мы предполагаем, что рядом с фотографией Эйнштейна с высокой вероятностью будет упомянута его фамилия. Подобные тексты мы называем прикартиночными.
Опираясь на эти данные, компьютер понимает, какие именно документы показать пользователю по запросу [Мэрилин Монро]. В итоге, в результатах поиска человек увидит миниатюры релевантных изображений или, как их еще можно назвать, тумбнейлы. Они будут одинаковыми для копий одних и тех же изображений. Отсюда и появилось наше для них название – тумбнейлерные дубликаты. Одинаковые по сути картинки могут быть разных размеров и степеней сжатия, но содержания изображения это не меняет. А иногда в картинки могут внести некоторые изменения. Например, добавить водяные знаки или логотипы, изменить цвета или обрезать. Но этого будет недостаточно, чтобы считать это изображение новым. Наша задача – сделать так, чтобы на странице с результатами поиска по картинкам не было дублирующихся миниатюр и для каждой группы копий показывалась одна, объединяющая их все.
Данные прикартиночных текстов в принципе дали нам понять, что на найденных фотографиях Мэрилин Монро. Но их мало, чтобы определить, какие из них дубликаты. И на этом этапе нам могут помочь существующие технологии компьютерного зрения.
Когда мы с вами говорим о том, что ребенок похож на родителей, то зачастую это звучит как «папин нос» или «мамины глаза». То есть, отмечаем какие-то черты лиц родителей, которые сохранились у ребёнка.
А что если попробовать научить компьютер использовать похожий принцип? В таком случае на первом этапе он должен понять, на какие точки на картинке надо смотреть. Для этого изображение обрабатывается специальными фильтрами, которые помогают выделить их контуры. По ним компьютер находит ключевые точки, которые не меняются ни при каких изменениях самих изображений, и смотрит, что находится вокруг них. Для того чтобы компьютер мог «рассмотреть» эти фрагменты, их нужно перевести в цифровой формат. Так описание останется верным, даже если картинку растягивать, поворачивать или подвергать еще каким-то трансформациям. Фактически, мы в какой-то степени обучаем компьютер смотреть на образ так, как на него смотрит человек.
В результате, каждая картинка получает набор описаний того, что находится у её ключевых точек. И если множество этих областей одного изображения похожи на множество областей другого изображения, то можно сделать выводы о степени их схожести в целом.
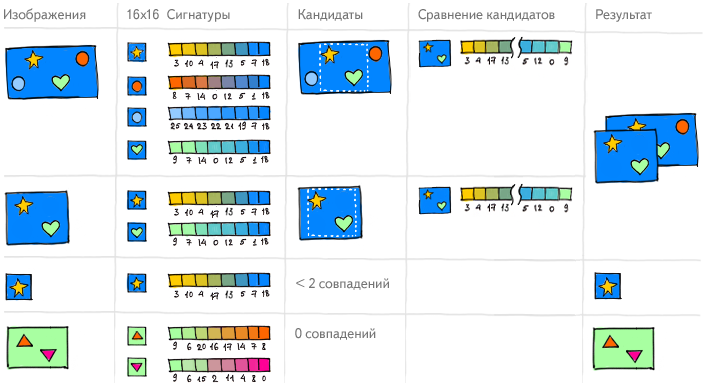
Но тут возникает проблема. Невозможно принять решение о том, что изображения являются дубликатами, не зная, что на них изображено. Мы можем решить для себя, что изменение лишь 5% площади позволяет считать их таковыми, но представьте себе фотографии шахматной доски до начала партии и после одного-двух ходов. Это разные картинки, хотя формально изменилось не больше 5% от них. А если к одному из изображений шахматной доски с одинаковыми позициями добавить, например, логотип, то они тоже будут различаться на 5%, но при этом оставаться дубликатами. Да, в какой-то степени мы научили компьютер видеть картинку, но пока технологии не дошли до абсолютного понимания предметной области изображений, и мы продолжаем работать над решением этой задачи.
Все описанные выше операции нужно проводить с каждой проиндексированной нами картинкой, а всего в нашем индексе присутствует 10 миллиардов изображений. И это не конечная цифра. Чтобы соответствовать темпам роста контента в интернете, используя наш старый алгоритм, нужно бы было невероятно быстро наращивать ресурсы. Естественно, понадобилось найти более рациональное решение этой инфраструктурной задачи. И мы смогли это сделать.
Теперь, например, чтобы добавить и обработать 10 миллионов новых изображений, которые каждый день проходят через Яндекс.Картинки, не нужно заново запускать процесс на уже существующие в базе миллиарды.
Кроме того, информация о том, что какие-то изображения в интернете являются копиями друг друга, помогает нам в ранжировании веб-документов в большой поисковой выдаче. Одинаковые картинки, как и ссылки, связывают документы между собой. Благодаря этому, мы можем учесть, насколько ценна та или иная страница для ответа на поисковый запрос. Поэтому вышеописанная технология важна не только для Яндекс.Картинок, но и в принципе для нашего поиска.
А если вернуться непосредственно к поиску по картинкам, то есть еще одна попутная задача, которая решается благодаря склеиванию дубликатов — мы можем находить похожее изображение даже тогда, когда оно не сопровождается прикартиночным текстом. Это полезно в случае, когда именно в таком виде картинка соответствует нужному человеку качеству.
Когда в 2002 году в Яндексе появился поиск по картинкам, технологий, позволяющих компьютерам непосредственно «видеть», какие объекты есть на изображении, не было вообще. Они появляются сейчас, но пока степени их развития не достаточно для того, чтобы компьютер узнавал в лицо Мэрилин Монро или распознавал на фотографии лес и сразу показывал его по соответствующему запросу. Поэтому задача совершенствовать те методы, которые были придуманы на первых этапах, остаётся актуальной.
Итак, компьютеру всё равно нужно понять, что изображено на картинке. Он не умеет «видеть», но при этом у нас есть технологии, которые хорошо ищут текстовые документы. И именно они нам им и помогут: изображение в интернете почти всегда сопровождается каким-то текстом. Он необязательно непосредственно описывает то, что изображено на картинке, но почти всегда связан с ней по смыслу и содержанию. То есть мы предполагаем, что рядом с фотографией Эйнштейна с высокой вероятностью будет упомянута его фамилия. Подобные тексты мы называем прикартиночными.
Опираясь на эти данные, компьютер понимает, какие именно документы показать пользователю по запросу [Мэрилин Монро]. В итоге, в результатах поиска человек увидит миниатюры релевантных изображений или, как их еще можно назвать, тумбнейлы. Они будут одинаковыми для копий одних и тех же изображений. Отсюда и появилось наше для них название – тумбнейлерные дубликаты. Одинаковые по сути картинки могут быть разных размеров и степеней сжатия, но содержания изображения это не меняет. А иногда в картинки могут внести некоторые изменения. Например, добавить водяные знаки или логотипы, изменить цвета или обрезать. Но этого будет недостаточно, чтобы считать это изображение новым. Наша задача – сделать так, чтобы на странице с результатами поиска по картинкам не было дублирующихся миниатюр и для каждой группы копий показывалась одна, объединяющая их все.
Данные прикартиночных текстов в принципе дали нам понять, что на найденных фотографиях Мэрилин Монро. Но их мало, чтобы определить, какие из них дубликаты. И на этом этапе нам могут помочь существующие технологии компьютерного зрения.
Когда мы с вами говорим о том, что ребенок похож на родителей, то зачастую это звучит как «папин нос» или «мамины глаза». То есть, отмечаем какие-то черты лиц родителей, которые сохранились у ребёнка.
А что если попробовать научить компьютер использовать похожий принцип? В таком случае на первом этапе он должен понять, на какие точки на картинке надо смотреть. Для этого изображение обрабатывается специальными фильтрами, которые помогают выделить их контуры. По ним компьютер находит ключевые точки, которые не меняются ни при каких изменениях самих изображений, и смотрит, что находится вокруг них. Для того чтобы компьютер мог «рассмотреть» эти фрагменты, их нужно перевести в цифровой формат. Так описание останется верным, даже если картинку растягивать, поворачивать или подвергать еще каким-то трансформациям. Фактически, мы в какой-то степени обучаем компьютер смотреть на образ так, как на него смотрит человек.
В результате, каждая картинка получает набор описаний того, что находится у её ключевых точек. И если множество этих областей одного изображения похожи на множество областей другого изображения, то можно сделать выводы о степени их схожести в целом.
Но тут возникает проблема. Невозможно принять решение о том, что изображения являются дубликатами, не зная, что на них изображено. Мы можем решить для себя, что изменение лишь 5% площади позволяет считать их таковыми, но представьте себе фотографии шахматной доски до начала партии и после одного-двух ходов. Это разные картинки, хотя формально изменилось не больше 5% от них. А если к одному из изображений шахматной доски с одинаковыми позициями добавить, например, логотип, то они тоже будут различаться на 5%, но при этом оставаться дубликатами. Да, в какой-то степени мы научили компьютер видеть картинку, но пока технологии не дошли до абсолютного понимания предметной области изображений, и мы продолжаем работать над решением этой задачи.
Все описанные выше операции нужно проводить с каждой проиндексированной нами картинкой, а всего в нашем индексе присутствует 10 миллиардов изображений. И это не конечная цифра. Чтобы соответствовать темпам роста контента в интернете, используя наш старый алгоритм, нужно бы было невероятно быстро наращивать ресурсы. Естественно, понадобилось найти более рациональное решение этой инфраструктурной задачи. И мы смогли это сделать.
Теперь, например, чтобы добавить и обработать 10 миллионов новых изображений, которые каждый день проходят через Яндекс.Картинки, не нужно заново запускать процесс на уже существующие в базе миллиарды.
Кроме того, информация о том, что какие-то изображения в интернете являются копиями друг друга, помогает нам в ранжировании веб-документов в большой поисковой выдаче. Одинаковые картинки, как и ссылки, связывают документы между собой. Благодаря этому, мы можем учесть, насколько ценна та или иная страница для ответа на поисковый запрос. Поэтому вышеописанная технология важна не только для Яндекс.Картинок, но и в принципе для нашего поиска.
А если вернуться непосредственно к поиску по картинкам, то есть еще одна попутная задача, которая решается благодаря склеиванию дубликатов — мы можем находить похожее изображение даже тогда, когда оно не сопровождается прикартиночным текстом. Это полезно в случае, когда именно в таком виде картинка соответствует нужному человеку качеству.
