

Николай Сивко ( NikolaySivko, okmeter.io)
Этот текст — расшифровка очень давнего, но не теряющего актуальности выступления Николая.
Я бы хотел поговорить о том, зачем, вообще, нам мониторинг, о содержательной части. Мотивация простая — если у нас ресурс лежит 1 минуту (HeadHunter), мы посчитали, что это затрагивает 30 тыс. пользователей днем в будни. Для сравнения — это 15 аудиторий HighLoad++ этого года. Олег говорил, что тут около 2000 человек, так это 15 таких аудиторий. Задача эксплуататоров, на мой взгляд, это не то, чтобы оптимизировать мониторинг, а то, чтобы их сайт работал. Т.е. бизнес-задачу решать. Какие задачи нужно решать?

- Первое — узнать, что сломалось, т.е. хорошо/плохо — эти два состояния системы надо уметь отличать.
- Второе — быстро узнать, где сломалось, чтобы быстро бежать чинить.
- После того, как вы внесли всякие изменения, вернули все, как было, оно заработало, нужно обязательно проверить, что оно работает так, как до факапа.
- На мониторинг также можно сгрузить несколько таких не совсем авральных задач, как разгребание инцидентов — это capacity planning, т.е. понимать, сколько у вас есть ресурсов, чтобы обслуживать новых и новых пользователей.
- Планировать оптимизации для того, чтобы эти ресурсы высвобождать. Когда вы понимаете, что у вас ресурсы железа скоро кончатся, либо докупайте, либо понимайте, что мы можем вот здесь подкрутить, и тогда железо покупать не придется.
- И, что не менее важно, это проконтролировать, что ваша оптимизация сработала.

Немножко ограничим scope. Мы будем говорить про то, на какие метрики надо смотреть, чтобы понимать свою систему. Мы попытаемся понять, как их лучше нарисовать, будем говорить про графики, мы будем пытаться понять, как их правильно нарисовать, чтобы быстро все понимать. Потому что на графике с 10 тыс. линиями ничего не понято.

Мы не будем говорить о том, чем рисовать графики, как тюнить ваш мониторинг, как шардировать мониторинг, как там прокси, все такое. Мы не будем говорить про конкретные алерты и про методологию, т.е. workflow, кто за что отвечает, какие KPI у эксплуатации… Я делал на весенней конференции доклад, вот ссылка. Там есть слайды, плюс-минус все понятно.
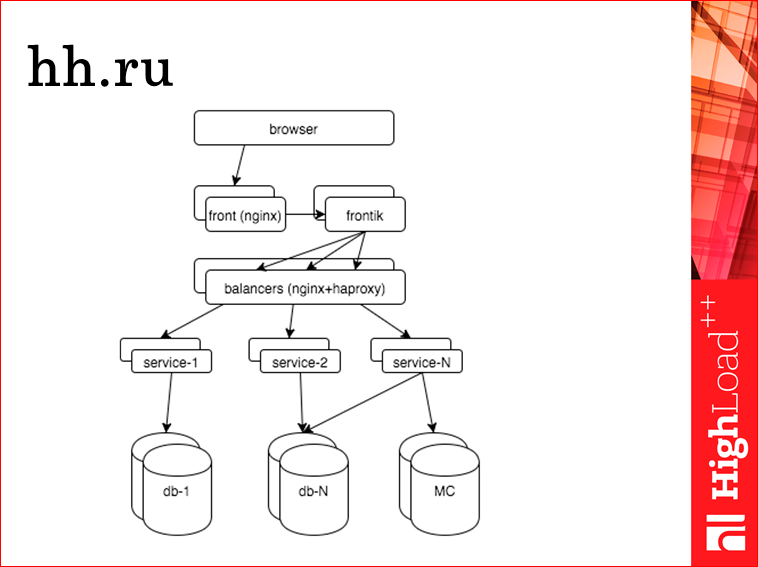
Итак, поехали. С чем мы имеем дело? Упрощенно HH.ru выглядит так. Сверху — браузер, наш пользователь, он приходит искать работу. Попадает на фронтенды. Там nginx, дальше там отдается статика, кэшируется, насколько это возможно, дальше запрос приходит на наш сервер-сборщик, мы называем его фронтик. Т.к. у нас SOA, нам страницу надо собирать из кусков. Фронтик, как раз, этим и занимается. Он делает запросы к разным сервисам, шаблонизирует и отдает страницу пользователю. Дальше фронтик идет к сервисам, но т.к. все должно быть масштабируемым, отказоустойчивым, он идет через балансеры. Внутренние балансеры у нас — это nginx+haproxy. Дальше, образно я нарисовал три разных сервиса, на самом деле их около 40-50. Эти сервисы делают какую-то бизнес-логику, ходят в какие-то свои хранилища, в подавляющем большинстве это postgres, также они общаются с memcached, у нас есть немного даже cassandra и т.д.

Что мы хотим понять? Мы хотим понять, как видит пользователь наш сайт. Причем, т.к. пользователей у нас много, мы хотим понимать сразу все. Т.е. кто как видит, какой процент плохо видит, какой процент хорошо видит. Мы хотим видеть, что происходит в каждой подсистеме, потому что если у нас что-то сломалось, вы физически не можете прочитать 40 разных логов, еще у каждой по 3-10-20-30 реплик.
На что уходят ресурсы нужно понимать, потому что любой мониторинг состояния приложения — это понимать, где находится управление в приложении в каждый момент времени. Т.к. мы хотим исторические данные, то это надо какие-то стадии работы приложения и т.д. Я про это потом подробнее расскажу. И все это недостаточно понимать в виде лампочки «хорошо»/«плохо». Надо понимать во времени, потому что иногда надо уметь сравнить с тем, как было час назад, минуту назад, в прошлый понедельник, в четверг, две недели назад.
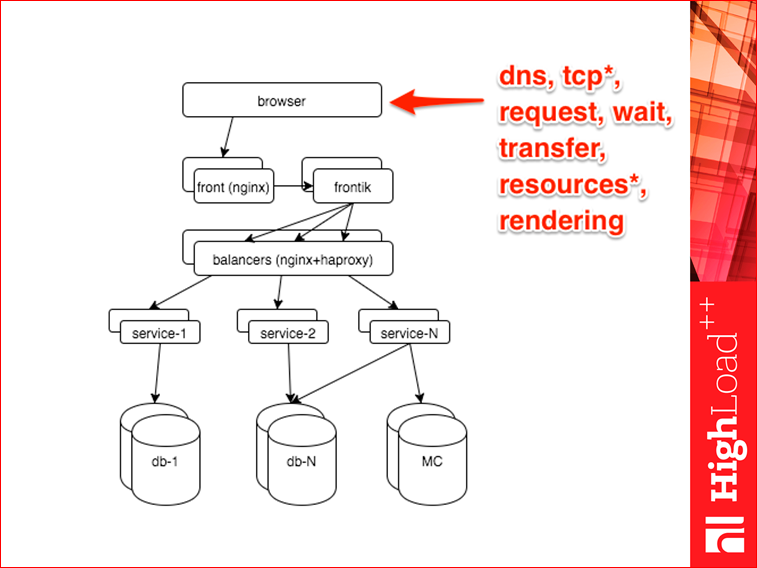
Обещал по слоям, будем по слоям. Первый слой — браузер. Что можно достать из браузера? Есть там возможность снять всякие тайминги — сколько делался dns запрос, сколько обслуживалось наше сетевое соединение, это tcp connect, tss handshake, сколько отправлялся запрос на сервер, сколько сервер думал, сколько трансферились данные, сколько погружались картинки, статика, все такое. И, наконец, код, который работает в браузере, бывает замороченный — сколько это все можно снять.

Я не фронтендер, поэтому про этот слой расскажу впробежку. Есть Navigation timing API. Про него знают практически все фронтендеры, про него, по-моему, есть доклад на этой конференции. Суть такова, что мы снимаем тайминги с браузера и отстреливаем их get-запросом на наш сервер. На сервере ничего не нужно в realtime обрабатывать, достаточно в nginx повесить возврат 204-го статуса, и записать весь этот get-запрос в url, и потом распарсить.
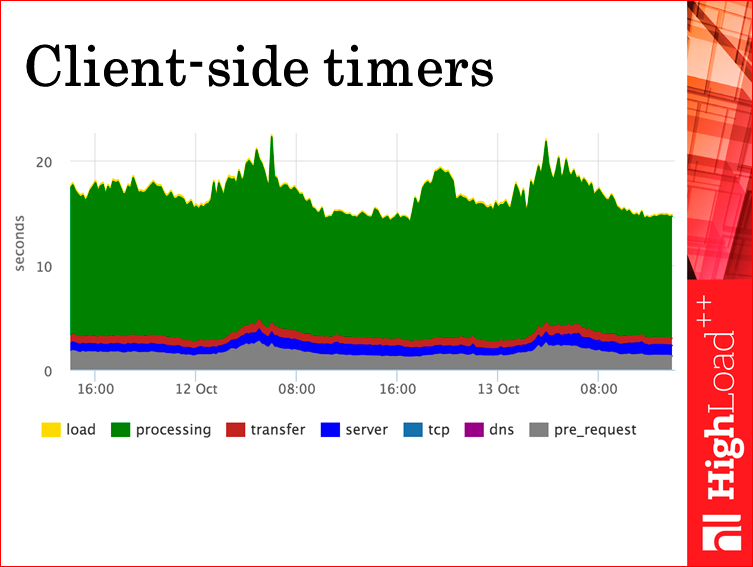
В результате мы получим примерно такую картинку. Не спрашивайте у меня, почему зеленого 20 секунд. Но мы видим, по крайней мере, интересные эксплуататору метрики — как у нас работает сервер с точки зрения конкретного браузера, как у нас работает канал, т.е. сколько это все трансферится. Мы видим, что это занимает приемлемое время, никаких скачков нет — все, свою задачу мы решили. Дальше спрашивайте фронтендеров, какие нужны им метрики, рисуйте для них, или они сами нарисуют, не суть.
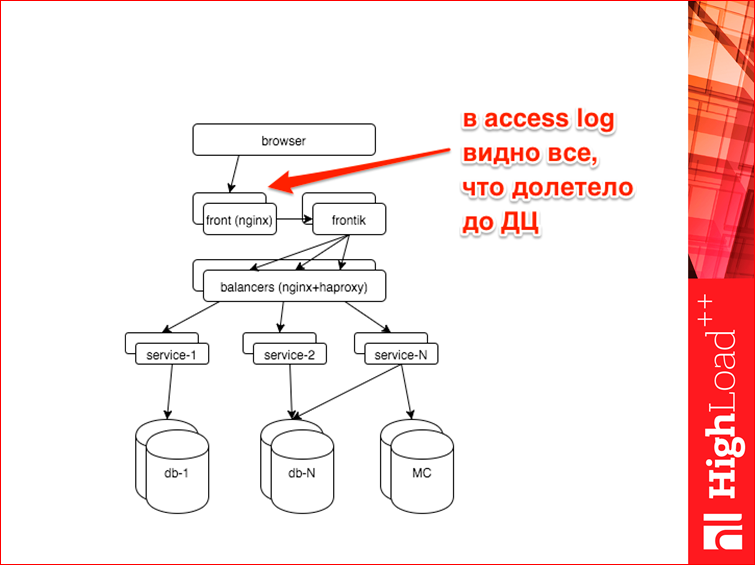
Дальше начинаются слои фронтендов. Мы в логе nginx видим все, что долетело до нашего дата-центра. Почему может не долететь? Не долететь может, потому что ваш домен не резолвится из какого-то места. Не долететь может, потому что у вас просто связанность отсутствует. В этом случае можно что-то сделать — опять же фронтендеры знают, есть какой-то механизм, отстреливать такие штуки на какой-то другой хост — не подскажу конкретно, но он есть, знайте про это, и этого достаточно.

Что мы хотим на этом слое получить? Мы хотим полную картину того, как работает сайт. Есть ошибки, нет ошибок? Если есть, то сколько, какую часть пользователей они аффектят — это один пользователь, 10%, 100%? Быстро работает сайт или медленно? Опять же — в каких масштабах? У одного тупит или тупит у всех, или тупит у всех из Воронежа? Сколько запросов у вас в секунду сейчас есть? Потому что, есть кейсы, когда приходят боты, и тогда у вас возрастает rps. Это нужно знать, это вам поможет для восстановления вашей системы. Или у вас лег канал — там провал, ничего нет. Или у вас провал на треть, потому что Ростелеком что-то раскопал на границе, там, с Украиной… И, бывает, что тупит канал, где-то там задержки, потери — на этот вопрос тоже бы хотелось отвечать.

Все это есть в логе nginx. Но не в стандартном лог формате. Нужно добавить туда request_time — это время от получения первого байта от клиента до отправки последнего байта ответа в клиентский сокет. Соответственно, как-то эта метрика отражает даже характеристики от канала до клиента — быстрый он, медленный. Потому что бывают у нас еще всякие чуваки на модемах. Также, если вы хотите отличать проблемы с каналом от проблемы с бэкендом, есть upstream_response_time — это время, проведенное в ожидании бэкенда, одного, нескольких, не важно. Сюда не включены никакие задержки до клиента, и это просто время, которое вы потратили для вычисления странички. Опционально там есть всякие полезные параметры. Зачитывать не буду, это для понимания, что там происходит.
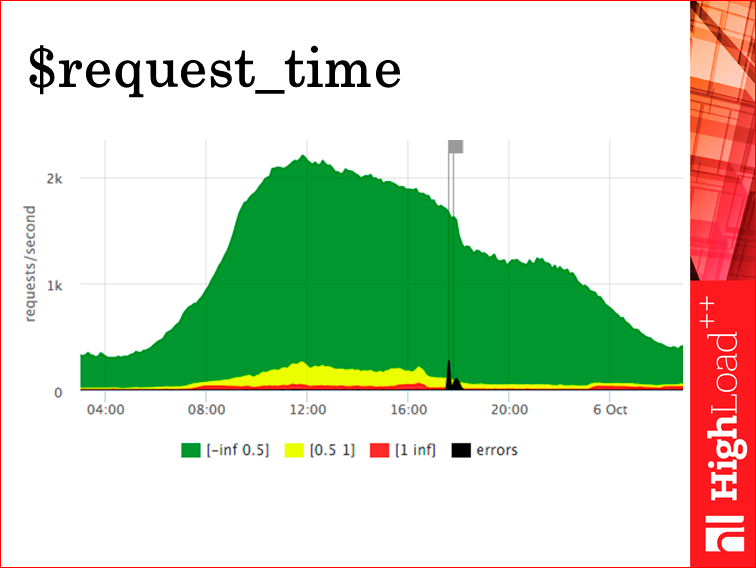
Как на это смотреть? Мы на это смотрим вот так. Называется это в нашей терминологии «светофором». По оси Y — запросы в секунду. У нас их чуть больше 2000 (какое-то время назад я эту презентацию готовил). Зелененькая область — это rps, которые обрабатывались меньше 500 мс. Желтые — те, которые отрабатывались 500 мсе и секунду, красные — больше секунды, это долго. И черное — мы добавили сюда ошибки, их ласково называют «нефтью». Это rps пятисоток. Соответственно, здесь включен трансфер для клиента, потому что это request_time, о котором слайд назад мы говорили.
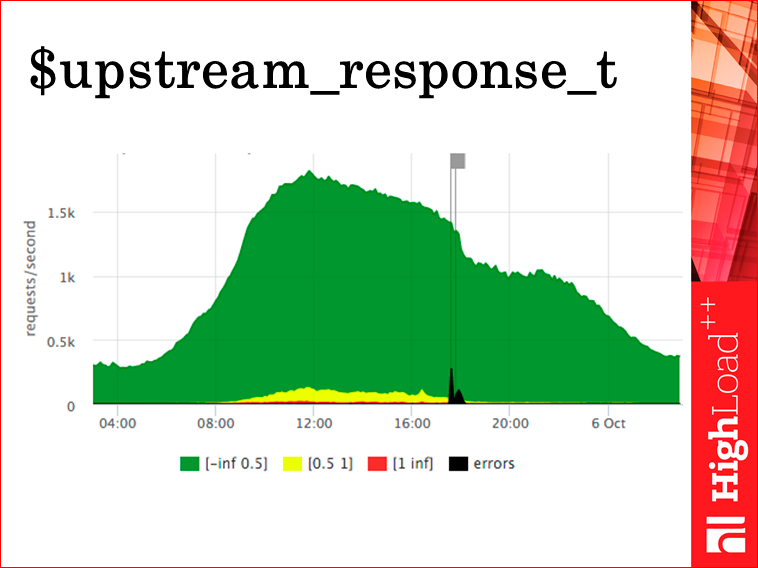
Upstream_response_time, во-первых, меньше rps, потому что что-то там из кэша отдалось, что-то там отрулилось куда-то. Соответственно, upstream_response_time у нас, как мы видим — красненького меньше, потому что трансферы ушли, т.е. на самом деле мы работаем еще лучше, но пятисотки при нас.
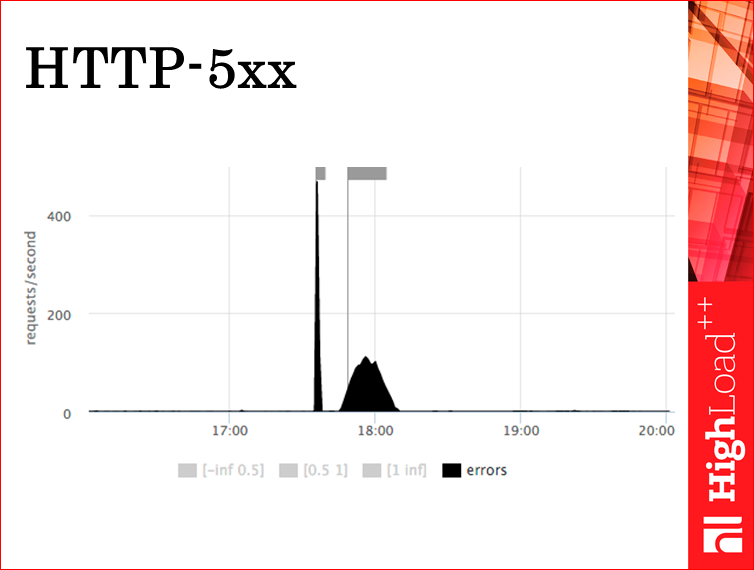
Можем на том же самом графике оставить только пятисотки. Мы понимаем, что у нас было два всплеска. Один больше 400 rps, а второй — чуть больше 100. Очень удобно для понимания. Т.е. мы, в принципе, практически на все вопросы ответили двумя графиками. А в ситуации, когда нам интересен только сервер, то одним.
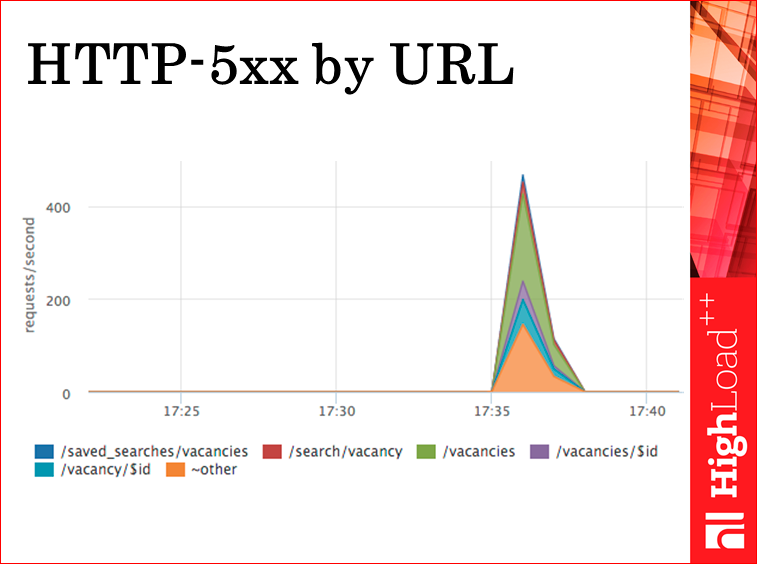
Пятисотки мы умеем раскладывать по url’ам в realtime. Видим — могут пятисотить все url’ы сразу, в пропорции такой, какой у нас есть rps. А можем увидеть конкретно url, если сломался какой-то хендлер, какой-то сервис, или притупил конкретный запрос из базы.
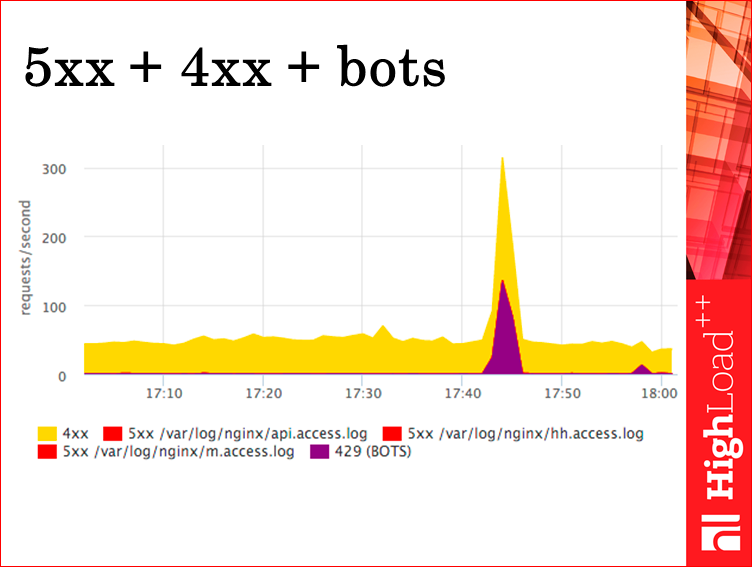
Также есть такой график, он дублирует пятисотки. Мы это смотрим по разным логам. Цвета одинаковые, чтобы в легенде понимать, какой пятисотит. У нас есть API для мобильного приложения, есть основной сайт HH, и есть мобильный сайт. Отдельно мы выделяем ботов — это запросы, которые попали в лимит количества запросов в секунду в nginx, тогда мы отдаем им 429-ый статус. Сюда он рисуется. Мы рисуем все статусы, а сюда мы выводим только 429-ый, потому что бывало всякое, начинает тупить, незафильтровали там все, допустим, спутник когда-то был молодой, он нам прикладывал часто, пока мы его не забанили. Но видеть сам факт того, что пришли боты — это очень полезно.

Дальше мы умеем смотреть на трафик по url’ам. Это трафик только статики, сюда не включена динамика. Мы видим — вышел релиз, обновились CCS, JS, был всплеск, пользователи начали качать свежие версии, потом он успокоился и перешел в нормальный режим. Классно понимать, что происходит, потому что если вы видите незнакомый всплеск на трафике, вы: «Блин, что это?». А тут сразу видно все.

Про урлы немножко расскажу. Можно настраивать парсинг логов так, что вы будете говорить: «Я знаю такие-то урлы — вакансия, поиск вакансии и т.д.». Но это все устаревает моментально, потому что приложение развивается, когда разработчики переименуют урлы или как-то там переделают, вам никто об этом не скажет, вы пойдете смотреть чего-нибудь по урлам, а там тыква.
Что надо сделать? Надо, во-первых, попытаться нормализировать урлы. Т.е. убрать все аргументы, попытаться вычленить какие-то хэши или id из урла, заменить все это на какие-то placeholder’ы, неважно какие, и строить динамический топ. У нас динамический топ по сумме $upstream_response_time, т.е. в топ попадают урлы, которые больше всего занимают реального процессорного времени. Можно по rps, можно сделать отдельно по ошибкам. Но обязательно надо отсечь снизу, потому что запросы от ботов, как правило, собирают все ваши пятисоточки, все четырехсоточки и т.д.
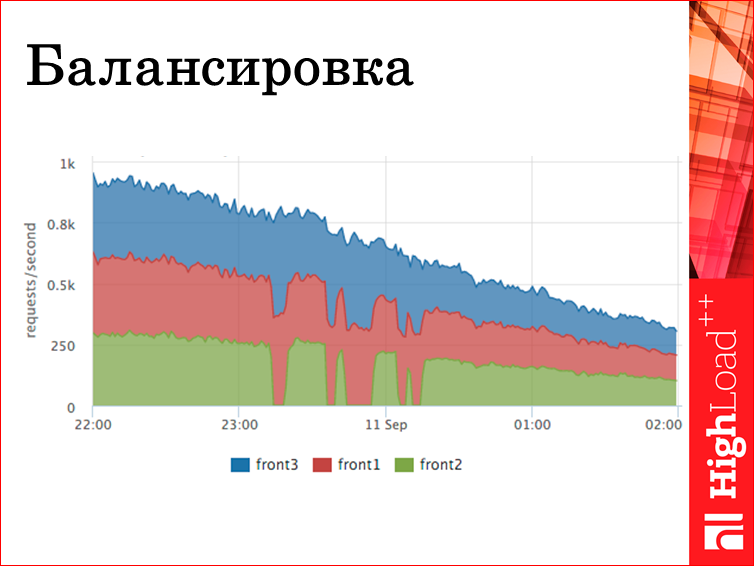
Также по логам. Если у вас есть несколько фронтендов, и вы собираете метрики со всех, можете это сагрегировать и видеть, как у вас работает балансировка — хорошо, плохо, как куда перетекал трафик. На этом примере front2 выводили из кластера, там какие-то работы, причем несколько раз. Мы видим, что, во-первых, на остальные серверы перетекла от балансировщика нагрузка. Соответственно, суммарный rps никак не зааффектился, т.е. мы это безболезненно сделали для пользователей. Но такая картинка крайне полезна.
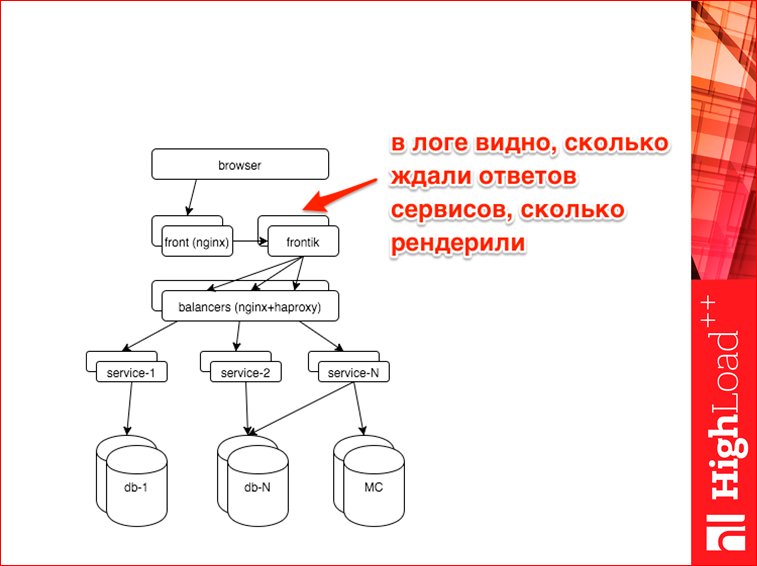
Дальше. Пойдем вниз. Понимаем, как работает, теперь решаем задачу «быстро понимать, что сломалось». На фронтике у нас тоже лог есть.

Это один из типов строчек, выглядит так. Здесь мы для каждого хендлера, в данном случае vacancy.Page, пишем все стадии в миллисекундах, сколько мы занимали. Стадия — это какой-то код, который выполняется. Все стадии идут последовательно. Допустим, сессия — это поход к сервису сессий и получение сессии, это берем куку, что-то там делаем, получаем сессию, знаем о пользователе больше. Потом с этими данными идем на на page — это параллельный поход по всем сервисам, которые нужно находить для этого хендлера. Т.е. внутри этой стадии там параллельные запросы. Но нас интересует суммарные. Xsl. У нас все шаблонизируется xsl. Рostprocess — это накладывание переводов на всякие… там страница собирается, там placeholder’ы, потом специальный процесс проходит по странице, заменяет placeholder’ы на переводы.
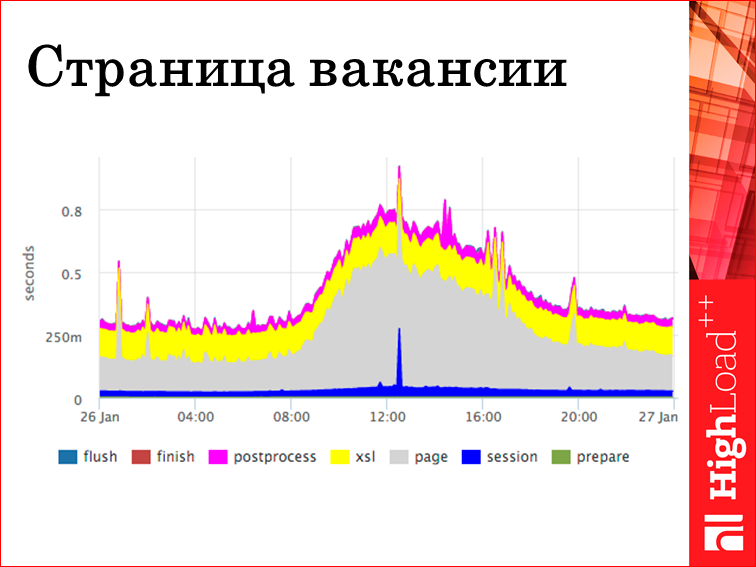
Вот мы получили картинку из этого лога. Видно, это стек 95-ых перцентилей каждой стадии. У перцентиля есть свои плюсы и недостатки, но в данном случае это удобно. Во-первых, мы понимаем, что стрельнуло. В середине графика синий выстрел — это притупил сервис сессии. Если стрельнет другая стадия, мы это сразу узнаем. Т.е., в принципе, по каждой странице есть такая картинка. Можно как-то сагрегировать по всем страницам, по всем хендлерам. Но это уже на вкус и цвет.
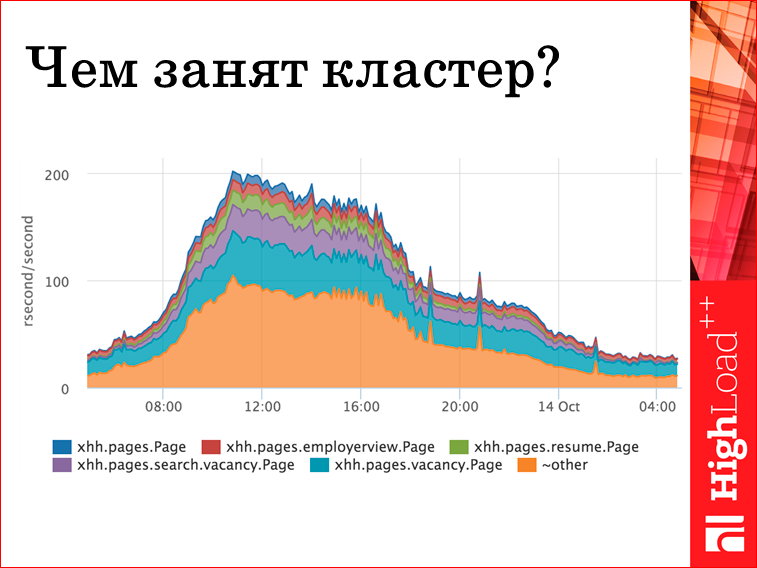
Удобный прием еще — просуммировать время ответа. Казалось бы, тупняковая метрика «просуммировать время ответа». На самом деле, классная штука. Мы, суммируя на самом верхнем слое время ответа, получаем в каких-то единицах, я называю это «ресурсные секунды в секунду», сколько и, вообще, чем занимается кластер. Т.е. если мы разделили их по хендлерам, мы получаем, что 20-30% занимает голубое — это vacancy.Page. Т.е. суммарно, вне зависимости ни от чего, ни от количества запросов, мы занимаемся отдачей страницы вакансий. Следующее — поиск вакансий и т.д. Если у нас вылезет какая-нибудь бяка, которая будет считаться час, но в один поток, мы ее здесь не увидим, и это правильно. Т.е. это реальный ответ на вопрос, чем занят кластер.

Шаблонизация. Фронтик также пишет, какой шаблон накладывался и сколько.
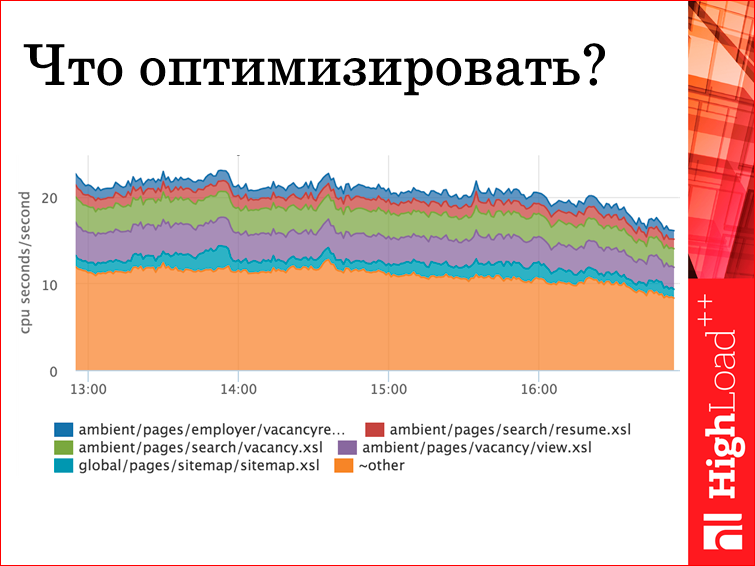
Логично сделать из этого график, мы прям получаем, какой шаблон сколько занимает CPU секунд, потому что шаблонизация — это CPU-баум задача. Соответственно, мы можем выбрать, что оптимизировать. Мы руководствуемся не rps, т.е. не сколько конкретный шаблон раз вызывался, накладывался и т.д., а сколько в сумме он дал веса и сколько, в принципе, CPU может высвободиться.
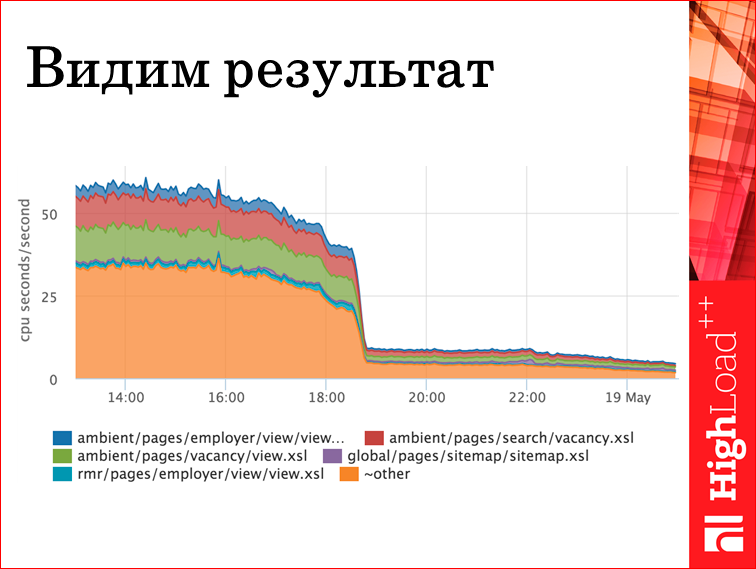
Вот пример. Правда, я тут вам рассказываю про то, какой у нас шаблон, но полезли оптимизировать, выяснили, что оптимизировать можно кусок генерации меню, который остальные шаблоны инклудят. Вот его оптимизировали, вот так рухнуло. Т.е. если бы после этой задачи оптимизация выходит в прод, мы понимаем, что картинка не изменилась, надо было ее откатить и ничего больше не делать, потому что если нет эффекта, задачу можно выкинуть. Здесь есть эффект. Классно, мы оценили, сколько. Мы по итогам пяток машин из кластера фронтиков убрали.
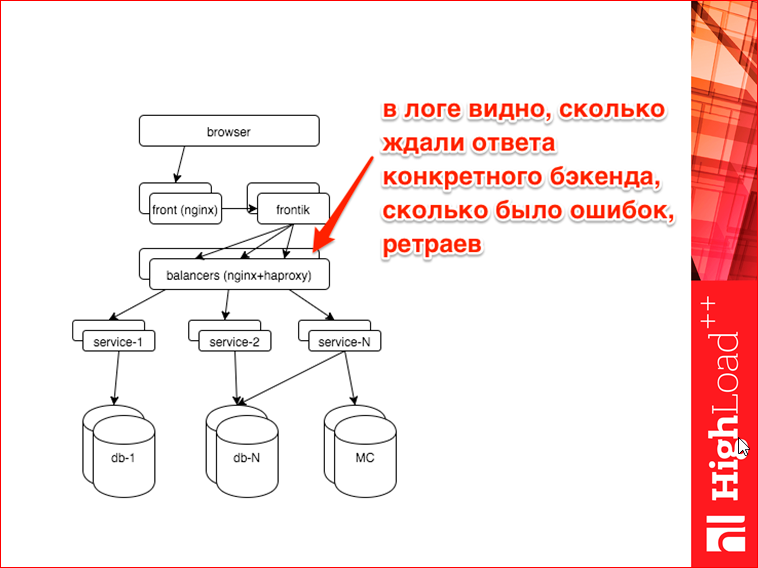
Дальше на балансерах.
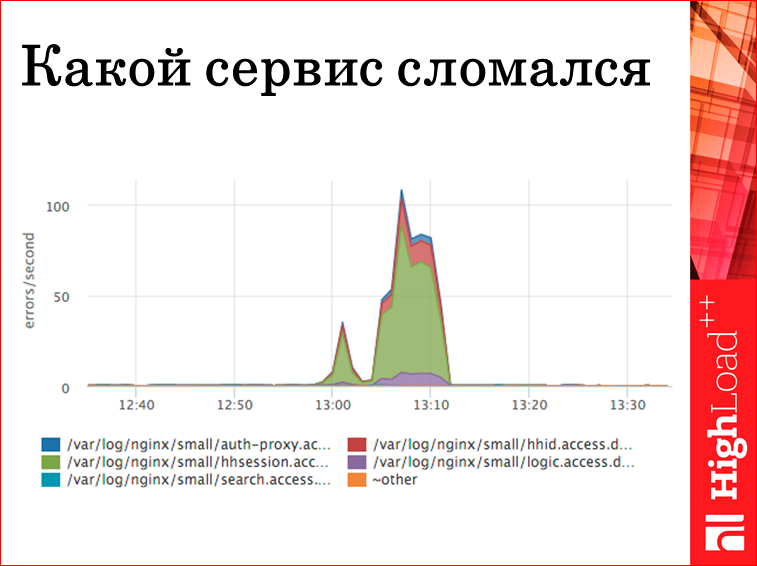
Тут тот же nginx, те же картинки, но у нас SОА, у нас много сервисов, самый юзабельный для нас график — это ответ на вопрос «какой сервис пятисотит?». В данном случае, это топ-5. Динамический. Т.е. если вылезет сервис, у которого 2 rps, и он начнет нам давать 10 тыс. пятисоток в секунду, он здесь вылезет автоматом. Соответственно, зеленое мы видим — сервис сессии сыпет около 70 запросов в секунду. Мы получили ответ, по крайней мере, мы можем пойти уже логи почитать, если у нас по этому сервису ничего нет.

Но давайте посмотрим, чего можно из каждого сервиса вытащить?

Опять стадии. Ничего кроме стадий, в принципе, не нужно, потому что дебажить по логам все равно сложно. Т.е. это отдельные логи. Если программисту нужна информация по бизнес-логике, он это пишет отдельно, а агент вытаскивает из лога только то, что ему интересно. Нам интересны стадии, нам интересно, куда уходит время. В данном случае, запрос на сессию выполнялся 10 мс, 6 из которых ушло на поход к сервису HHid. Это такой сервис, который знает пользователя и не знает ничего больше. Он его обогащает, т.е. результат ответа этого сервиса, HhSession обогащает из базы, у него запрос в базу заняло 3 мс.
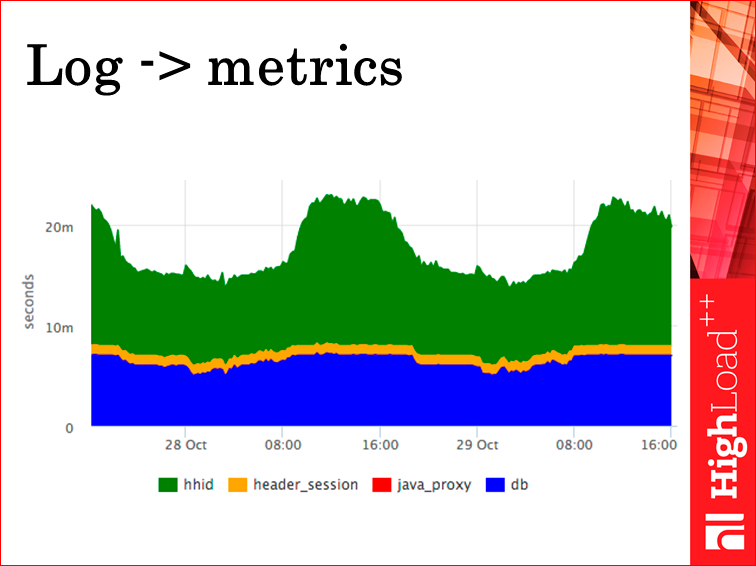
Соответственно, лог есть, есть картинка. Мы видим, что запрос «время ожидания базы» константное, и видим, что на этом фоне прыгает время ответа Hhid. Т.е. если база вдруг притупит, мы увидим выброс на базе, т.е. мы получаем ответы на свои главные вопросы — куда бежать дальше в случае факапа.
Весь мой рассказ построен на том, что я хочу максимально быстро понимать, что произошло. Т.е. это оптимизация работы эксплуататора.
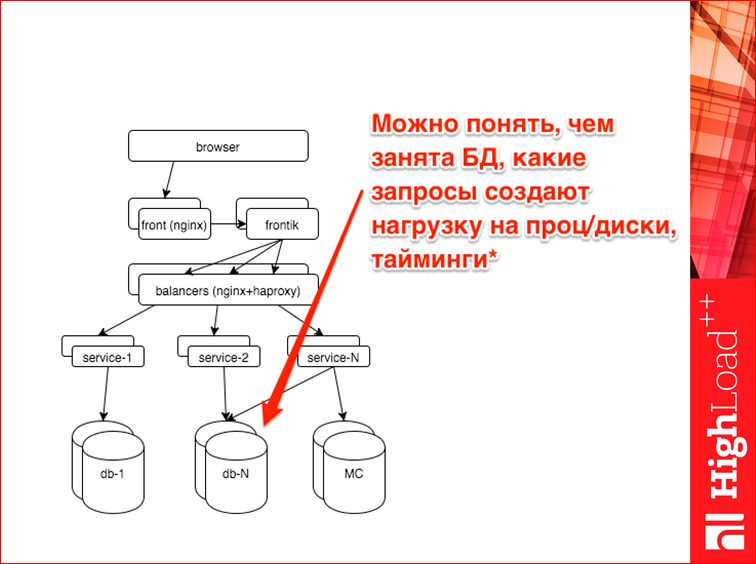
По базе. Т.е. вам сказали: «Тупит база». Что можно сделать по базе?
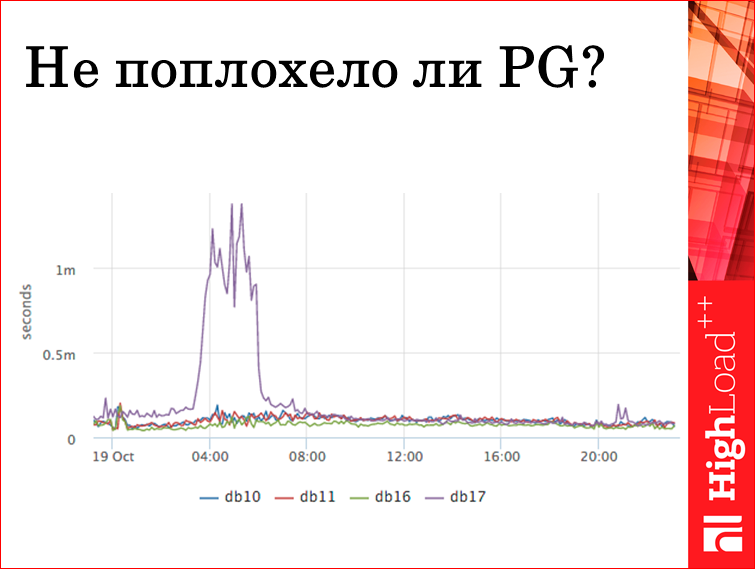
Во-первых, есть, как это не банально звучит, среднее время ответа базы. Это берется из postgres, из pg stat statements. Потому что ничего более внятного оттуда взять нельзя. Поэтому среднее время. Но оно показательно. Вот все четыре наши базы. Это какой-то конкретный кусок. Мы видим, что все работают нормально, но ночью одна притупливает. Это мастер, и мы потом попытаемся понять, что с ним было. Т.е. если вдруг вы приходите, и вам говорят, что база тупит, вы смотрите на этот график, а там все так же, как и было, вы сразу говорите: «Нет, с базой все хорошо». И это будет правда.
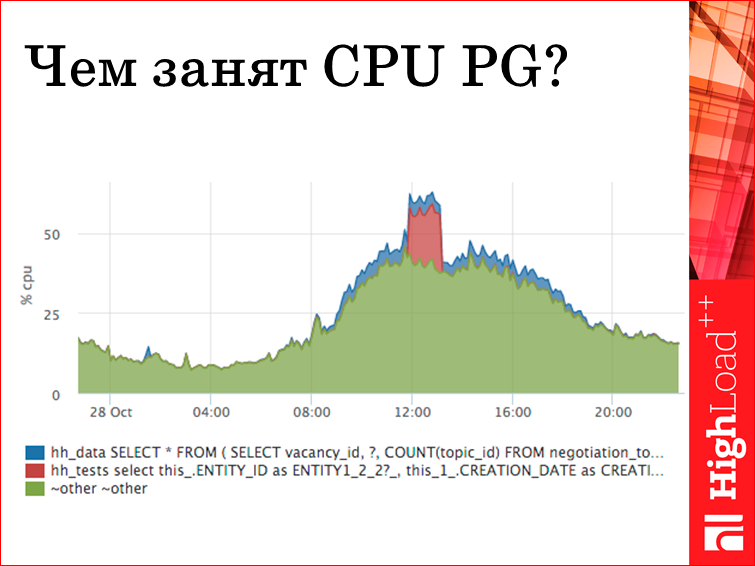
Если вдруг на базе скакнул CPU, в принципе, из pg stat statements мы можем понять, какой конкретно запрос вычислялся. В данном случае мы видим выброс красненький — это пришел запрос в базу, hh_test, и там весь его текст? и с holder-‘ами. Он тут обрезан, но его можно всего скопировать и понять, откуда он, убрать, эксплейнить, все что угодно.
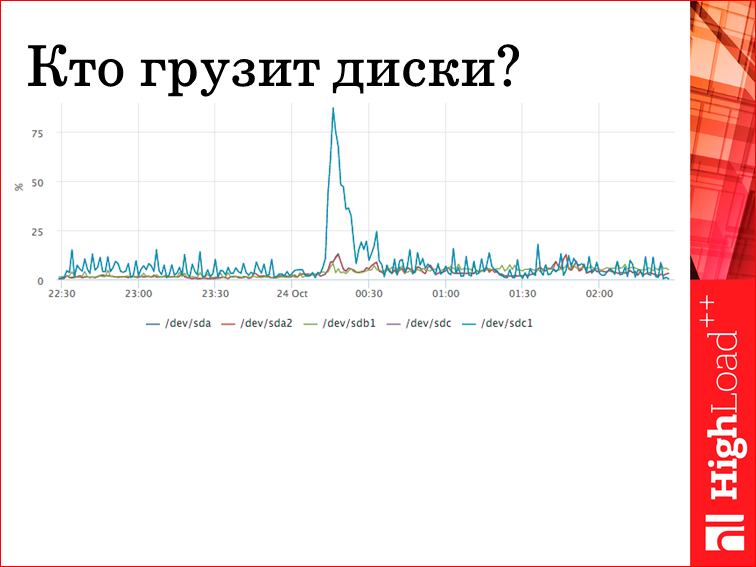
База также обладает слабым местом — это диски. Естественно, там все лежит, все данные.
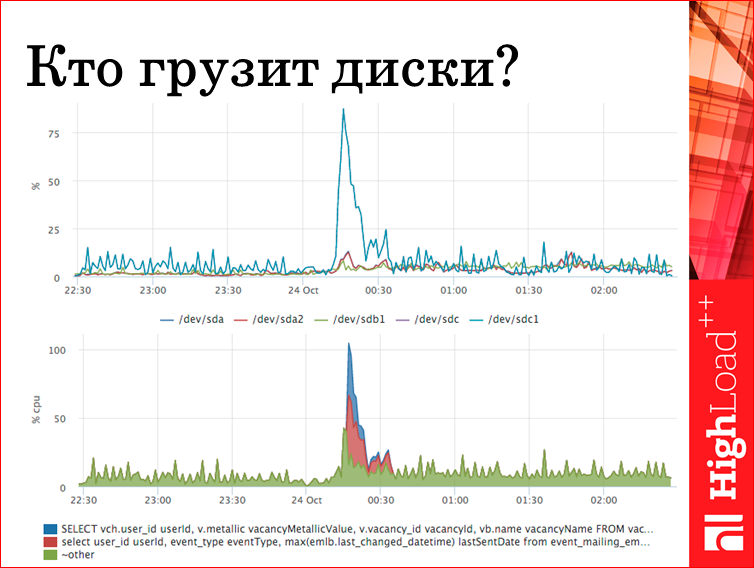
Кто прогрузил диски? В pg stat statements есть счетчики, сколько ждали ответа с диска. Соответственно, мы видим конкретные два запроса, которые диск убивают. Мы приходим, с ними разбираемся, если нужно. Если это нормальная, штатная ситуация, то мы просто знаем, что это за пик. Отвечать на вопрос «что это было?» — это самое главное. Т.е. если есть в вашей системе какие-то выбросы, которые вы не понимаете, вам надо более детальную информацию о вашей системе собирать.
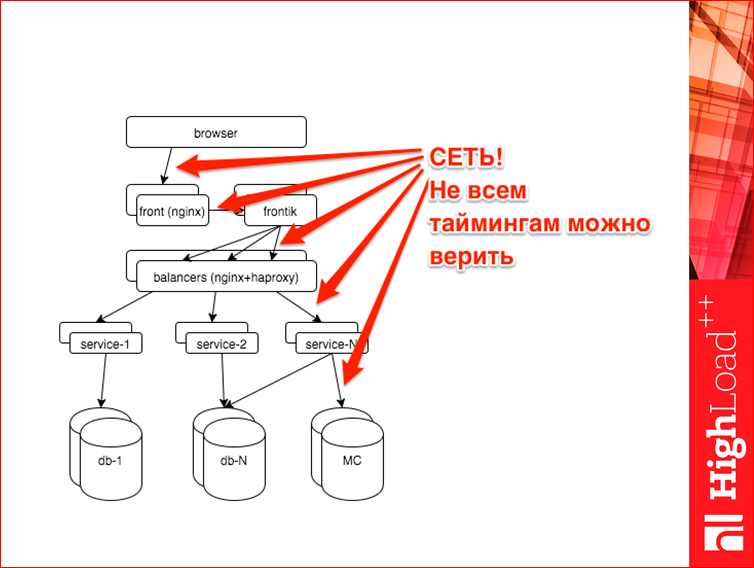
И все было бы просто, если бы между всем этим не было сети. Можно сказать, что поэтому, в том числе, мы снимаем все тайминги со всех сервисов, даже если они повторяются. Потому что погрешность измерения в веб-приложении может быть достаточно существенной. Потому что, у вас, допустим, какое-то асинхронное приложение, которое на event loop построено, где-нибудь замеряет, сколько оно ждет ответа и при этом что-то считает, управление не вернулось в его loop, то оно вам насчитает много всего.

Вопросы. Допустим, мы в логе сервиса сессии видим, что он ходил в hhid 150 мс, у нас у всех запросов есть request_id, т.е. мы можем их по логам провязать и сопоставить два конкретных запроса, и сказать, что это был запрос — столько видела сессия, столько hhid. Идем в hhid, он говорит: «Я отвечал 5 мс, ничего не знаю». Приходят разработчики и говорят: «У вас сеть тупит». Ну, блин, достало! И мы решили думать, чего делать. При этом пинговать со всех машин все машины как-то, мягко говоря, странно. И тем более, до первого факапа непонятно, с каких машин, что делать. Надо исключить сеть.

Есть такая штука TCP RTT — Round-Trip Time. Это время, начиная с отправки сегмента в сеть TCP, заканчивая получением acknowledge. Но это время не стоит сравнивать с пингом. Стоит рассматривать это как некий тренд, потому что TCP — непростая штука, мягко говоря.
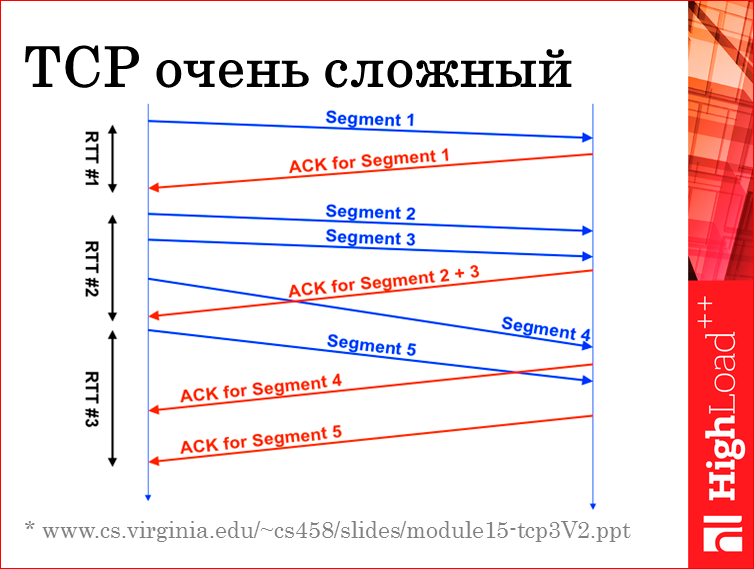
Я спер слайд из презентации — это какой-то курс по сетям американского университета, здесь говорится о том, что на самом деле у одного TCP соединения всего один таймер RTT. Т.е. в первом случае мы замерили реально время от отправки сегмента до ACK’а. Все хорошо. Если убрать погрешность на количество переданных байт, то примерно получим нормальный RTT. Во втором случае у RTT нам насчиталась отправка 2,5 сегментов и получение 2-х ACK’ов. Потому что в TCP есть избирательные acknowledge и прочее. Там очень много наворотов, плюс ко всему, если там ломается какой-нибудь порядок отправки сегментов, и там вообще начинается мясо.

Но все равно мы решили попробовать это померить. Мы со всех хостов раз в минуту снимаем RTT всех соединений, но тупо снимать, агрегировать по всему. Мы агрегируем между двумя IP локалки. Если это IP не из локалки, мы говорим «азер» и агрегируем. Если IP в локалке, то для каждого IP у нас есть метрика с каждого хоста. И еще разбиваем по listen_port, если на нашей стороне listen. Пытаемся посмотреть, что можно по этим метрикам сказать.

Вот пример картинки. Это RTT между репликой и мастером. Реплика находится в удаленном дата-центе. В этот день были работы на дата-центрах, два раза гасился полностью канал. Во-первых, мы видим, что TCP RTT при пинге меньше миллисекунды 7 мс, но классно, что он константный, т.е. тренд нам все-таки отражает. На этой картинке видно два провала. По крайней мере, нам будут говорить: «Пропадала сеть». Мы такие посмотрим и скажем: «Реально пропадала». И после восстановления мы видим, что сеть притупила два раза, все захотели посинкаться и т.д. И потом все пришло в норму, что тоже классно, мы это увидели. В принципе, стало понятнее, т.е. метрика непонятная, потому что мы не знаем, что под этим RTT внутри скрывается фактически, но тренд есть и это, мне кажется, в 100 раз лучше, чем ничего.

И про операционку. Тут все банально, как у всех, разве что акцентирую внимание, что все смотрят на swap и не смотрят на swap i/o. Swap i/o гораздо полезнее. Если у вас кто-то сидит в swap и ничего оттуда не читает и не пишет, то пусть сидит, не жалко.
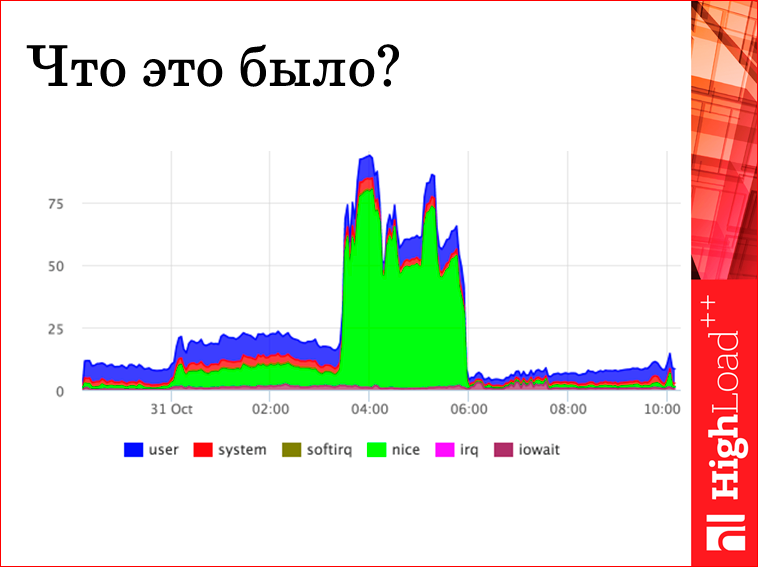
Но имея CPU, сложно сказать, что это за фигня. Потому что мы приходим на работу в 10 утра, смотрим на график, что это?

Мы снимаем еще системные метрики по каждому процессу с пользователя. Самые полезные из них — это CPU, Disk i/o, Swap, Swap I/O и до кучи (нам надоела проблема too many open files) мы снимаем по каждому процессу, сколько дескрипторов открыли, сокетов, файлов, н0е важно, и каков лимит.
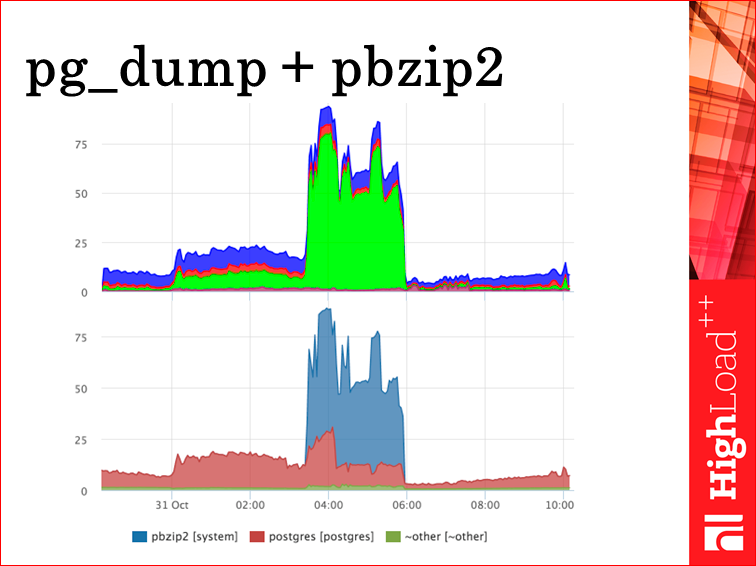
И мы сразу видим, что ночью на мастере был бэкап, и рbzip жрал CPU. В принципе, простая метрика, просто хорошая гранулярность, и все ответы мы получаем.

Давайте заканчивать и подытожим. Я хотел вам рассказать про то, что надо думать не о том, сколько там точек, сколько хостов мониторить, какие порты у них чекать раз в минуту, а сделайте хорошие правильные графики для своей системы, и они вам могут повысить в разы скорость выяснения причин факапов.
Важно не останавливаться, если… Допустим, мы на фронтендах видим всю картину, мы могли бы дальше по логам не идти, но мы поняли, что после того, как мы понимаем, есть проблема или нет проблемы, у нас уходит 10 минут днем на то, чтобы логи почитать. Но мы там покрыли мониторингом и увидели, что это время сократилось в 10 раз. Дальше, видим проблемы с базой. Раньше мы такие: «У нас postgres consulting DB админы аутсорсные!». Мы звоним и говорим: «Ребята, смотрите, чего с базой?». Сейчас мы, по крайней мере, понимаем, есть на базе чего, или нет ничего. Потому что любая коммуникация между людьми — она долгая, компьютер быстрее, и если вы сделаете правильные метрики… Хотя бы сделайте метрики не для того, чтобы они вам ответы давали, а сделайте, чтобы исключать наиболее вероятные проблемы. И чем детальнее метрика, тем проще, потому что если мы там все усредним, возьмем перцентили, гистограммы и прочее, ничего не будет понятно, и вы все равно полезете в логи. Попытайтесь сделать так, чтобы в логи ходить, вообще, не надо было.
Это все, что я хотел вам рассказать. Спасибо за внимание!
Контакты
NikolaySivko
n.sivko@gmail.com
sivko@hh.ru
Блог компании HeadHunter
Блог компании okmeter.io
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++. Сейчас мы активно готовим конференцию 2017 года — в этом году HighLoad++ пройдёт в Сколково, 7 и 8 ноября.
Тема мониторинга поднимается на HighLoad++ каждый год, вот, например, некоторые из докладов 2017-го:
- Мониторинг облачной CI-системы на примере Jenkins / Александр Акбашев (HERE Technologies);
- Logging and ranting / Vytis Valentinavičius (Lamoda)
- Zabbix: рецепты высокопроизводительного мониторинга / Алексей Владышев (Zabbix);
- и даже Мониторинг производительности фронтенда в Badoo / Александр Гутников (Badoo).
Ну а сам Николай собирается прочитать философско-систематизирующий доклад на тему "Эксплуатация container based инфраструктур".
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
