Найди коррупционера. Анализ данных чиновников из проектов Канцелярской сотни (с примерами на R)
13 мин
Как определить чиновников, наиболее подозрительных с точки зрения коррупции? Проще всего — сравнив их доходы и уровень жизни.
В этой статье я хочу показать возможности сайтов с открытой информацией о чиновниках, посмотреть на то, как эти чиновники живут и попытаться определить тех, кто наиболее подозрителен с точки зрения коррупции.
Почему открытая информация о доходах чиновников важна? Потому что это позволяет их контролировать.
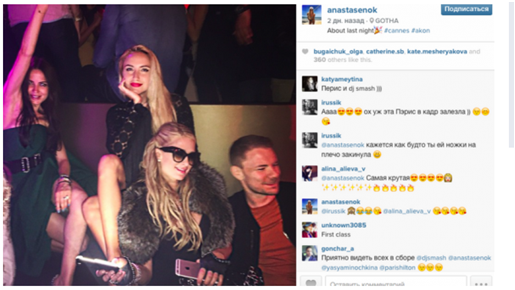
Фото из инстаграмма дочери бывшего руководителя ГАИ Украины Александра Ершова. На фото дочь Ершова в Каннах рядом с Пэрис Хилтон. В результате скандала из-за несоответствия задекларированных доходов и образа жизни семьи Ершов подал в отставку.
В этой статье я хочу показать возможности сайтов с открытой информацией о чиновниках, посмотреть на то, как эти чиновники живут и попытаться определить тех, кто наиболее подозрителен с точки зрения коррупции.
Почему открытая информация о доходах чиновников важна? Потому что это позволяет их контролировать.
Фото из инстаграмма дочери бывшего руководителя ГАИ Украины Александра Ершова. На фото дочь Ершова в Каннах рядом с Пэрис Хилтон. В результате скандала из-за несоответствия задекларированных доходов и образа жизни семьи Ершов подал в отставку.