
Оптимизация скриптов для витрин данных: от суток к часам
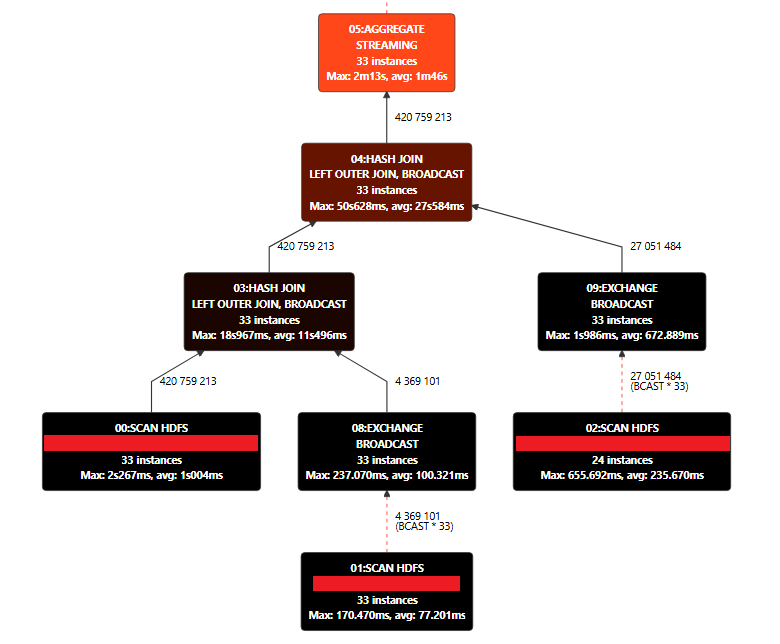
В 2022 году я присоединился к команде Газпромбанка в должности дата-инженера. В мои обязанности входила поддержка витрин данных для машинного обучения. Главной проблемой, с которой мне пришлось столкнуться, оказалось непомерно долгое время обработки данных при использовании устаревших скриптов. Например, расчет среза одной из витрин занимал более суток! Причина крылась в неоптимизированных скриптах, которые изначально разрабатывались для гораздо меньших объемов данных. Со временем объем обрабатываемой информации значительно увеличился, что закономерно привело к драматическому ухудшению производительности. В этой статье поделюсь своим опытом решения проблемы и расскажу о подходах, которые помогли сократить время выполнения с суток до нескольких часов.