Эффективная FIFO-обработка для Node.js и Chrome
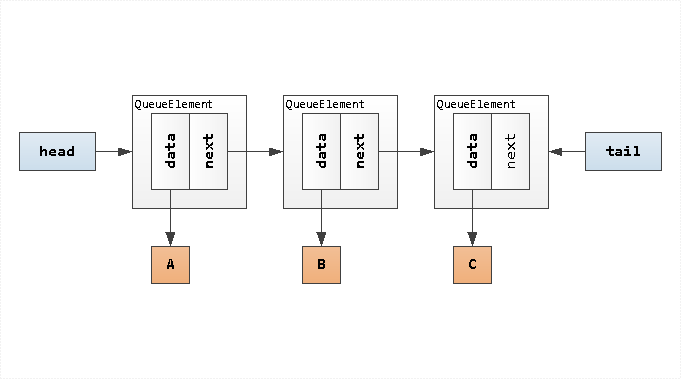
"По классике" FIFO-очередь для обработки некоторого потока задач обычно реализуется в виде связанного списка элементов. Но для JavaScript такой подход нехорош - он требует либо создания "обвязки" над элементом очереди в виде дополнительного объекта, содержащего ссылки на сам элемент и указатель на следующий, либо превращения элемента в объект и расширения его таким же указателем.
В таких нагруженных системах, как коллектор нашего сервиса мониторинга PostgreSQL-серверов, создание и последующая подчистка Garbage Collector'ом подобных избыточных объектов и полей - непозволительная роскошь.
Но если внимательно посмотреть на эту схему, то можно заметить, что сами элементы очереди A, B, C линейно упорядочены. Так нельзя ли использовать в качестве очереди обычный массив с его .push() и .shift()?..
Насколько это будет эффективно, какие грабли встретятся на этом пути, и как их можно обойти - сегодня об этом.