PostgreSQL Query Profiler: как сопоставить план и запрос
6 min
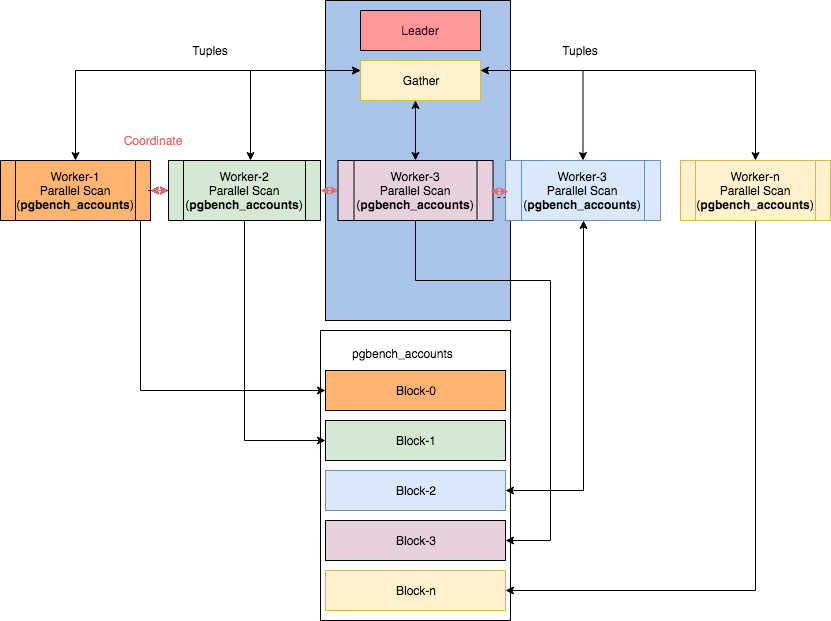
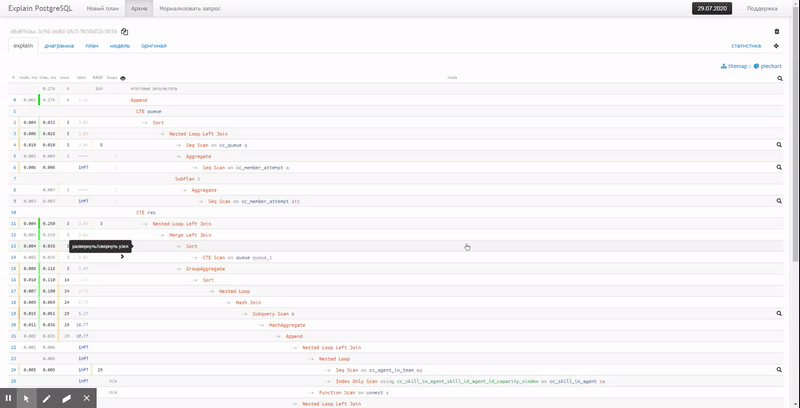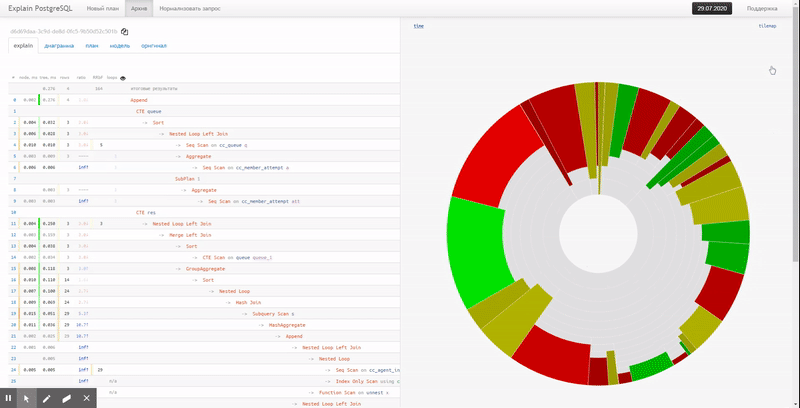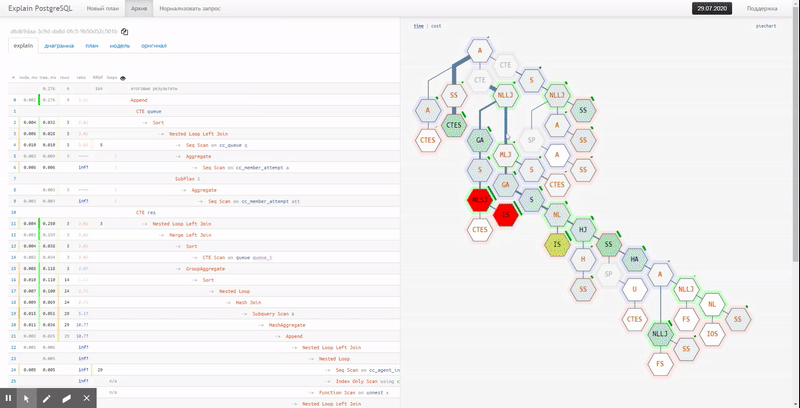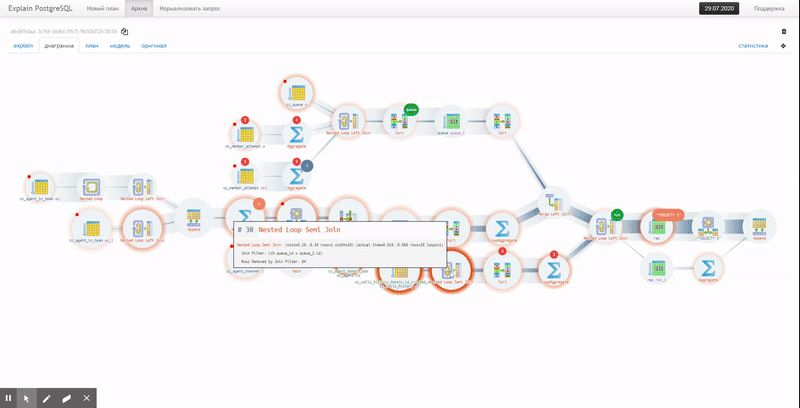
Многие, кто уже пользуется explain.tensor.ru — нашим сервисом визуализации планов PostgreSQL, возможно, не в курсе одной из его суперсособностей — превращать сложно читаемый кусок лога сервера…

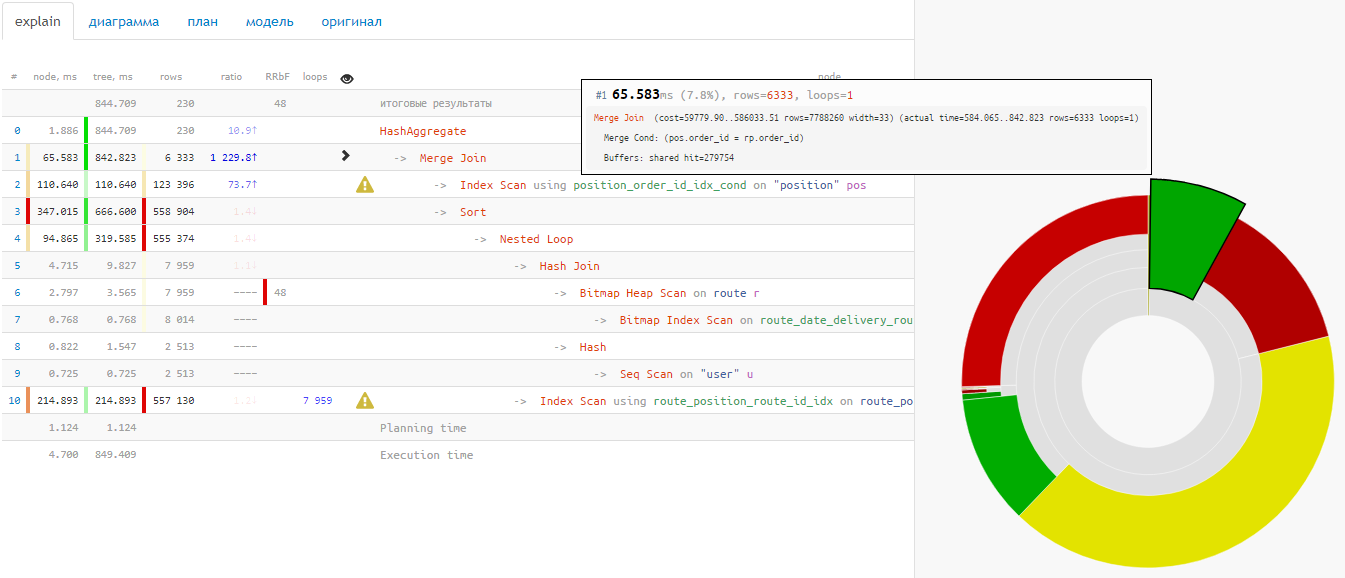
… в красиво оформленный запрос с контекстными подсказками по соответствующим узлам плана:

В этой расшифровке второй части своего доклада на PGConf.Russia 2020 я расскажу, как нам удалось это сделать.
… в красиво оформленный запрос с контекстными подсказками по соответствующим узлам плана:
В этой расшифровке второй части своего доклада на PGConf.Russia 2020 я расскажу, как нам удалось это сделать.
С транскриптом первой части, посвященной типовым проблемам производительности запросов и их решениям, можно ознакомиться в статье «Рецепты для хворающих SQL-запросов».