Вы прям как в том анекдоте: во-первых, официант, что за дрянь вы мне принесли? во-вторых, почему так мало? :D
Давайте по пунктам:
По моему мнению, псевдокода вполне достаточно. Акцент статьи на конкретном методе. Остальные приведены для справки. Моя задача была сделать статью как можно короче, чтобы не пугать читателя объёмом (как в остальных 100500 источниках по теме).
Мне оба этих изложения показались непонятными, поэтому и написал свою статью, где было бы на пальцах и в картинках изложено, что же там на самом деле происходит.
А позор это:
Считать, что все должны писать код том стиле, к которому вы привыкли.
Ожидать, что переводчик будет переписывать код, а кроме того (но это уже не к вам)
Переводить статьи без согласия (хотя бы уведомления!) автора.
На медиуме тоже есть тематические категории, в которые отбирают "кураторы", т.е. сотрудники медиума. И есть publications, которые в основном поддерживаются сторонними организациями/людьми, туда отбор вручную. Одна статья может быть сразу в нескольких категориях, но только в одной publication (либо быть вне publication). И там и там есть email-рассылки. Выдача на самом сайте в соответствии с подписками. Сильно запутано. На хабре система проще, конечно.
Ну у них есть на медиуме разбивка «по интересам». Правда, конкретно для программирования толку маловато у неё:
Зато есть аналитика по каналам, откуда люди приходят:
Я же не говорю, оптимально ли у них сделано. Я говорю, что это в принципе возможно. А так — конечно, не оптимально. Причём ничего не мешало сделать по-человечески. Даже взять этот их backquote — интерфейс пользователя для кода сделан: выделяешь кусок текста, нажимаешь `, и он форматируется в моноширинный шрифт — только вот с подсветкой синтаксиса у них как-то не сложилось.
Код вставляется отлично. Надо только поставить расширение хрома "Code Medium". Оно даёт подсветку синтаксиса через gist.github.com.
Получается примерно так
С таблицами да, беда. Только скриншотами.
Как было уже написано выше, на медиуме, чтобы получать ощутимое количество просмотров, важно писать в правильные хабы (publication'ы). Но с ними бывают неожиданные затруднения. Кто смотрел скетч "Modern Educayshun" (рекомендую на англ. смотреть) оценит такую формулировку в одном из publication'ов медиума:
In order to make space for, and give more of a voice to, under-represented people in technology, a minimum of 1/3 of the articles we publish daily will be written by women and non-binary authors.
И предлагает подождать недельку-другую перед публикацией уже готовой статьи, если вы не готовы отнести себя к вышеобозначенным группам пользователей.
The second wave of the 1918 pandemic was much deadlier than the first. The first wave had resembled typical flu epidemics; those most at risk were the sick and elderly, while younger, healthier people recovered easily. By August, when the second wave began in France, Sierra Leone, and the United States,[88] the virus had mutated to a much deadlier form. October 1918 was the deadliest month of the whole pandemic.[89]
Ага, посмотрю на досуге. Не, я же не говорю, что я не знаю, как это сделать. Вот прям по той ссылке на stackoverflow есть решение без вспомогательной функции
define pow(a, b) {
if (scale(b) == 0) {
return a ^ b;
}
return e(b*l(a));
}
– оно чуть короче, чем то, из википедии, которые вы привели.
Я просто к тому, что я ожидал бы это увидеть в калькуляторе из коробки. Скиньте где почитать про обвинения против Морриса? Не слышал эту историю.
Математики в своём стиле. 101+ функция. Возведения в дробную степень, которое есть в любом калькуляторе, где есть инженерный режим — нет. Зато есть тест гипотезы Коллатца, да. :) И непонятно, где тесты: "They may contain bugs, both on the algorithmic and programming side." не особо располагает к использованию. Хотя в образовательных целях, безусловно, полезно.
Есть ещё неплохой (хотя и древний) bc for windows http://gnuwin32.sourceforge.net/packages/bc.htm Единственное, что он не умеет, это дробные степени — почему-то для этого надо писать пользовательскую функцию (корень есть).
Есть ещё awsome python — в отличие от awsomo он без картинок, но в нём либы сгруппированы по категориям. Он есть в трёх видах:
1) исходник на гитхабе https://github.com/vinta/awesome-python — длинный список на много экранов)
2) https://awesome-python.com/ – список, свёрстаный в веб-страничку с навигацией справа (есть небольшой лаг по обновлению)
3) https://python.libhunt.com/ – целый сайт с регистрацией, новостями, тэгами, changelog'ами и пр. Основывается на списке с гитхаба, но список сильно шире за счёт добавленных пользователями библиотек.
Например, библиотек для визуализации пару лет назад было, соответственно, 9, 10 и 17. Сейчас 11, 11 и 23.
Смысл разгона питона в том, что он, мягко говоря, не самый быстродейственный язык на свете.
Смысл нумбы в том, что она разгоняет питон лучше всех остальных инструментов, при этом в отличие от асм вставок полностью сохраняется синтаксис и семантика питона, разгон осуществляется добавлением нескольких декораторов, а в отличие от GPU based библиотек код исполняется на любом компьютере, а не только на карточках с cuda capacity >x.y.
Смысл этой статьи в том, что на хабре ещё не было обзора этой либы, а документация у него хромает.
Но в любом случае спасибо за ваш комментарий, это лучше, чем молча нажать минус и уйти.
В numba есть альтернатива классам – custom dtypes из numpy (я их упоминал в первой части), они работают с нормальной скоростью, но там с синтаксисом, пока что, беда. Например, если для доступа к полям использовать обычный синтаксис полей класса (a.y2), то просто убрать @jit в процессе отладки не получится – придётся всё переписывать на a['y2']. Это можно было бы решить допиливанием numpy. Ну типа написать соответствующий враппер. Я попробовал – так сходу у меня не получилось, слишком уж много наворотили в np.ndarray.

Вы прям как в том анекдоте: во-первых, официант, что за дрянь вы мне принесли? во-вторых, почему так мало? :D
Давайте по пунктам:
По моему мнению, псевдокода вполне достаточно. Акцент статьи на конкретном методе. Остальные приведены для справки. Моя задача была сделать статью как можно короче, чтобы не пугать читателя объёмом (как в остальных 100500 источниках по теме).
Если вам нужен обфусцированный олимпиадный стиль, читайте русскую википедию https://ru.wikipedia.org/wiki/Поиск_длиннейшей_подстроки-палиндрома
если нужен код с многобуквенными переменными на несколько экранов, читайте английскую википедию
https://en.wikipedia.org/wiki/Longest_palindromic_substring
Мне оба этих изложения показались непонятными, поэтому и написал свою статью, где было бы на пальцах и в картинках изложено, что же там на самом деле происходит.
А позор это:
Считать, что все должны писать код том стиле, к которому вы привыкли.
Ожидать, что переводчик будет переписывать код, а кроме того (но это уже не к вам)
Переводить статьи без согласия (хотя бы уведомления!) автора.
На медиуме тоже есть тематические категории, в которые отбирают "кураторы", т.е. сотрудники медиума. И есть publications, которые в основном поддерживаются сторонними организациями/людьми, туда отбор вручную. Одна статья может быть сразу в нескольких категориях, но только в одной publication (либо быть вне publication). И там и там есть email-рассылки. Выдача на самом сайте в соответствии с подписками. Сильно запутано. На хабре система проще, конечно.
Ну у них есть на медиуме разбивка «по интересам». Правда, конкретно для программирования толку маловато у неё:
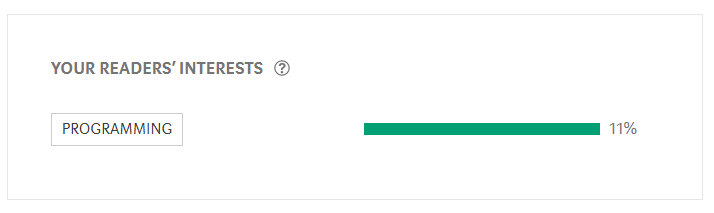
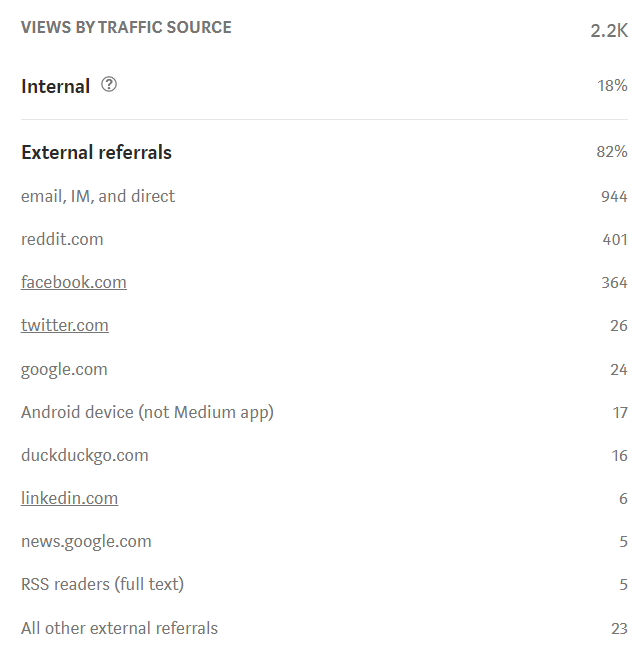
Зато есть аналитика по каналам, откуда люди приходят:
Как сделать размер изображения поменьше?
Я же не говорю, оптимально ли у них сделано. Я говорю, что это в принципе возможно. А так — конечно, не оптимально. Причём ничего не мешало сделать по-человечески. Даже взять этот их backquote — интерфейс пользователя для кода сделан: выделяешь кусок текста, нажимаешь `, и он форматируется в моноширинный шрифт — только вот с подсветкой синтаксиса у них как-то не сложилось.
Код вставляется отлично. Надо только поставить расширение хрома "Code Medium". Оно даёт подсветку синтаксиса через gist.github.com.
Получается примерно так
С таблицами да, беда. Только скриншотами.
Как было уже написано выше, на медиуме, чтобы получать ощутимое количество просмотров, важно писать в правильные хабы (publication'ы). Но с ними бывают неожиданные затруднения. Кто смотрел скетч "Modern Educayshun" (рекомендую на англ. смотреть) оценит такую формулировку в одном из publication'ов медиума:
И предлагает подождать недельку-другую перед публикацией уже готовой статьи, если вы не готовы отнести себя к вышеобозначенным группам пользователей.
f(4) == true. Серьёзно?
Достаточно реально.
Добавьте — правда не хватает!
Ну оочень hoofed.
Ага, посмотрю на досуге. Не, я же не говорю, что я не знаю, как это сделать. Вот прям по той ссылке на stackoverflow есть решение без вспомогательной функции
– оно чуть короче, чем то, из википедии, которые вы привели.
Я просто к тому, что я ожидал бы это увидеть в калькуляторе из коробки. Скиньте где почитать про обвинения против Морриса? Не слышал эту историю.
Математики в своём стиле. 101+ функция. Возведения в дробную степень, которое есть в любом калькуляторе, где есть инженерный режим — нет. Зато есть тест гипотезы Коллатца, да. :) И непонятно, где тесты: "They may contain bugs, both on the algorithmic and programming side." не особо располагает к использованию. Хотя в образовательных целях, безусловно, полезно.
Да, про scale я, конечно, в курсе. Я говорил не про дроби, я говорил про дробные степени. Например, кубический корень «из коробки» не извлекается. https://stackoverflow.com/questions/16164925/using-fractional-exponent-with-bc
Есть ещё неплохой (хотя и древний) bc for windows http://gnuwin32.sourceforge.net/packages/bc.htm Единственное, что он не умеет, это дробные степени — почему-то для этого надо писать пользовательскую функцию (корень есть).
F6 же?
Есть ещё awsome python — в отличие от awsomo он без картинок, но в нём либы сгруппированы по категориям. Он есть в трёх видах:
1) исходник на гитхабе https://github.com/vinta/awesome-python — длинный список на много экранов)
2) https://awesome-python.com/ – список, свёрстаный в веб-страничку с навигацией справа (есть небольшой лаг по обновлению)
3) https://python.libhunt.com/ – целый сайт с регистрацией, новостями, тэгами, changelog'ами и пр. Основывается на списке с гитхаба, но список сильно шире за счёт добавленных пользователями библиотек.
Например, библиотек для визуализации пару лет назад было, соответственно, 9, 10 и 17. Сейчас 11, 11 и 23.
Скорее в стилистике заголовка.
Смысл чего именно вам не ясен?
Но в любом случае спасибо за ваш комментарий, это лучше, чем молча нажать минус и уйти.
В numba есть альтернатива классам – custom dtypes из numpy (я их упоминал в первой части), они работают с нормальной скоростью, но там с синтаксисом, пока что, беда. Например, если для доступа к полям использовать обычный синтаксис полей класса (
a.y2), то просто убрать@jitв процессе отладки не получится – придётся всё переписывать наa['y2']. Это можно было бы решить допиливанием numpy. Ну типа написать соответствующий враппер. Я попробовал – так сходу у меня не получилось, слишком уж много наворотили вnp.ndarray.Я взял верхнюю строчку из таблицы в статье про хаскелл. Там g++ тоже есть.
Я его упомянул мимоходом в первой части, но, действительно, надо бы расширить.
Вряд ли Гвидо ван Россум ставил себе целью манипулировать чьим-то сознанием :)