Warning FailedCreatePodSandBox 1m (x8 over 1m) kubelet, kub-2 Failed create pod sandbox.
Что-то пошло не так между kubelet и docker. Думается мне и flannel потому же лежит. Что интересного в логах у kubelet на kub-2? Групайте на предмет "createPodSandbox for pod"
Контекст: событие создается тут, а парой строк выше в лог отправляется конкретная ошибка.
В этом кстати просматривается положительная черта k8s, его относительно просто дебажить если вы поняли общий принцип работы. Вся информация на тему ошибок будет в логах, частично всплывая и в "пользовательський" интерфейс через события. Мониторинг можно легко построить на prometheus, так как все компоненты экспортируют метрики, рантайм (docker или rkt) можно изучить отдельно от kubelet и разобраться что и где пошло не так.
Я на самом деле не использую swarm, так что для меня корректнее звучало бы "а что есть такого в swarm из-за чего я хотел бы переехать на него".
Навскидку, в k8s ingress и сетевые политики. Первое в swarm можно решить "руками", второе заменить на calico cni.
StatefulSet в k8s более фичаст чем service swarm'a и с ним проще масштабировать сервисы которые сами кластеризируются.
Кастомные ресурсы тоже классная штука. У меня базы и юзеры мускуля вынесены в ресурсы и контроллер сам их настраивает. Это позволяет держать определения БД там же где и прочие зависимости приложения.
Возможность мапить секреты в env/файлы — очень удобно и постоянно пользуюсь. В swarm можно наверно использовать vault для замены? но это требует опять же движений руками.
что из коробки в созданном kubernetes решении сервисы точно так же смогут пинговать друг друга по имени
да
и трафик будет раутиться по наименее загруженному каналу к наименее загруженной копии сервиса
docker swarm поддерживает только round robin для сервисов же? k8s может тоже самое через iptables, в 1.9 упала поддержка ipvs и всех политик которые приходят с ним.
А, я понял — вы про изменение размера диска внутри виртуалки.
Очень редко с таким сталкиваюсь, всегда проще нарезать новую, а данные на загрузочном диске и не хранятся. Я даже не уверен что облака AWS / GCP поддерживают такое.
Как это решается? примитивным скриптом. Отресайзить единственный раздел и отресайзить фс. Если на лету страшно — то ребутнуть машину, coloudinit отресайзит на загрузке.
Если вы в k8s поднимете mysql в StatefulSet с одним инстансом и PersistentVolumeClaim для хранилища — это фактически ничем не будет отличаться от mysql вне k8s.
В самой простой ситуации вы прибиваете Volume на каталог хост машины и получаете 1:1 ту же надежность как и вне кластера (машина умерла — БД умерла с ней).
Как это можно улучшить уже средствами k8s? Можно использовать сетевое хранилище для PVC, например ceph rbd, aws ebs, iscsi или даже nfs. Таким образом при потере машины, рабочая нагрузка мигрирует на другую, а хранилище перемонтируется. Это не гарантирует отсутствие даунтайма, и потенциально медленнее (сетевое хранилище хуже чем локальный SSD).
Дальше в дело вступает репликация. Если ваша БД может комфортно работать в режиме master-master, то вы просто поднимаете N реплик тем же StatefulSet и потеря любой из них не будет вас волновать, мастера догонятся друг от друга. В таком случае можно использовать эфемерное хранилище (тот же локальный диск), т.к. потеря данных одной ноды не критична.
Наконец, можно делать R/W + R/O реплики (для mysql это, наверно, оптимальный вариант для быстрого чтения и наименьшего простоя). У k8s прямо в доках есть пример для mysql. Тут первая реплика это R/W с персистентным хранилищем, а последующие — R/O с эфемерным и они догоняются от реплики N-1. Падение машины с первой репликой дает вам даунтайм на запись (пока mysql запускается на другой ноде), потеря R/O реплик полностью незаметна, плюс R/O реплики читают с локального быстрого диска.
TL;DR: БД отлично работают в контейнерах, просто надо понимать где вы выигрываете, и что теряете.

Warning FailedCreatePodSandBox 1m (x8 over 1m) kubelet, kub-2 Failed create pod sandbox.Что-то пошло не так между kubelet и docker. Думается мне и flannel потому же лежит. Что интересного в логах у kubelet на kub-2? Групайте на предмет "createPodSandbox for pod"
Контекст: событие создается тут, а парой строк выше в лог отправляется конкретная ошибка.
В этом кстати просматривается положительная черта k8s, его относительно просто дебажить если вы поняли общий принцип работы. Вся информация на тему ошибок будет в логах, частично всплывая и в "пользовательський" интерфейс через события. Мониторинг можно легко построить на prometheus, так как все компоненты экспортируют метрики, рантайм (docker или rkt) можно изучить отдельно от kubelet и разобраться что и где пошло не так.
Во-первых, посмотрите что в журнале событий:
$ kubectl describe pod nginx-deployment-569477d6d8-ks262там может быть конкретная причина.
Если в events ничего интересного нет (или вообще нет событий), посмотрите там же на какую ноду под зашедулился и гляньте логи kubectl.
Эо объясняет как поднять кластер с нуля и кто вообще внутри происходит. Если надо просто кластер на поиграться есть minikube / kubeadm / kops наконец.
А ошибку какую возвращал?
Kubelet на нодах может съесть до сотни мб. Нагрузка на процессор незначительна по сравнению с рабочими подами.
Вот скриншот с master-ноды у меня на стейджинге:
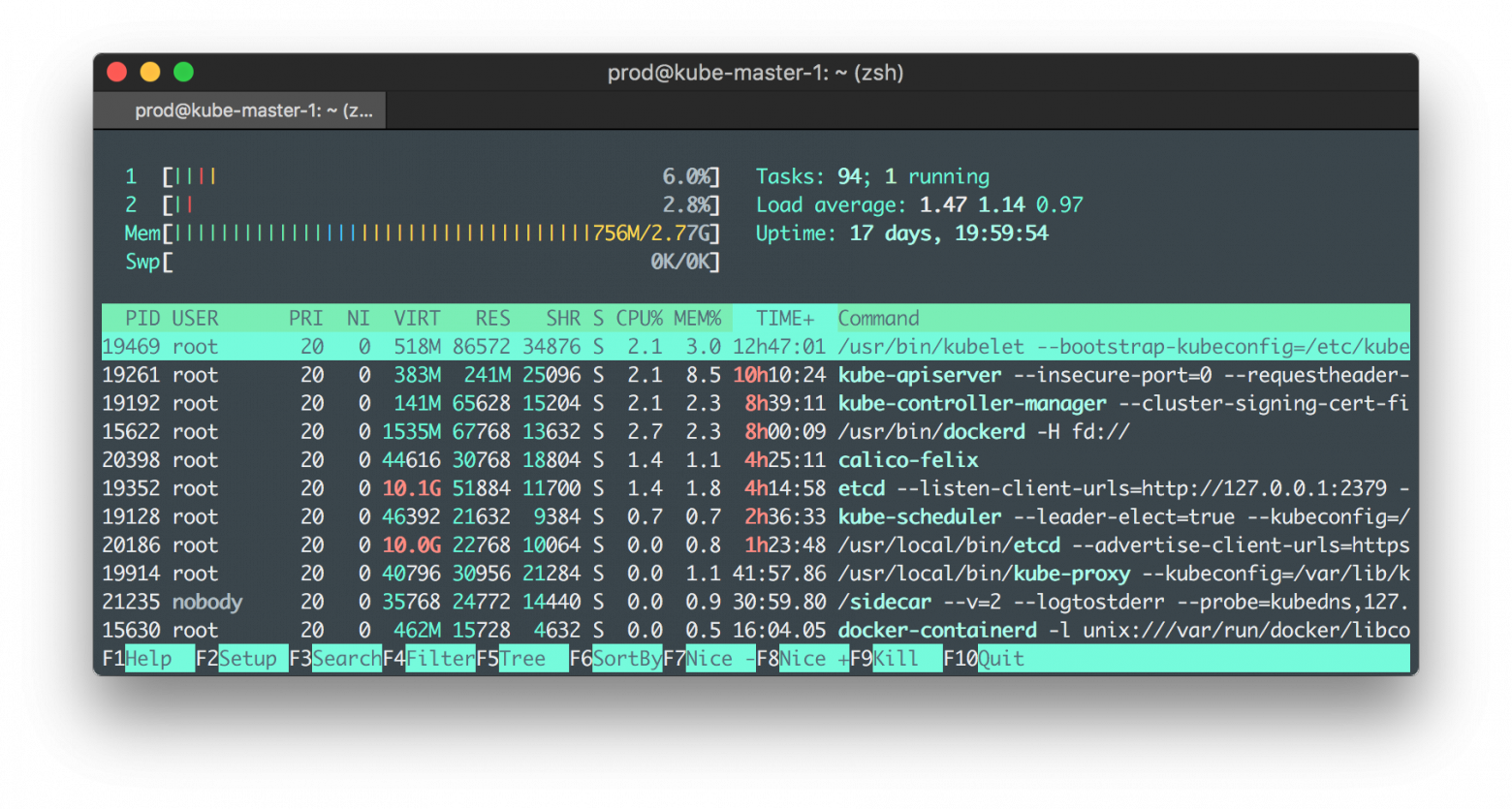
Еще раз — она есть. Вот свежий релиз миникуба и там дока как его запустить на винде: https://github.com/kubernetes/minikube/releases/tag/v0.23.0
Но, minikube это готовый кластер. Поставил и работай. Это не "собери k8s из исходников и пойми как работает паззл".
Ну так я же и говорю — я swarm уже давно не видел. Замечательно что он развивается.
Да я знаю, рассеянность внимания, многабукаф, все дела :-) почитайте и поиграйтесь все же. Полезно.
Не знаю, его точно можно запускать через minikube (кубовое окружение для разработки), вот например дока для винды.
Но для KTHW надо машинку с линуксом, там же все руками. Ну или руками адаптировать под винду.
я так тоже раньше думал. Очень помогает поднятие кластера полностью руками, тот же kubernetes the hard way.
Я на самом деле не использую swarm, так что для меня корректнее звучало бы "а что есть такого в swarm из-за чего я хотел бы переехать на него".
Навскидку, в k8s ingress и сетевые политики. Первое в swarm можно решить "руками", второе заменить на calico cni.
StatefulSet в k8s более фичаст чем service swarm'a и с ним проще масштабировать сервисы которые сами кластеризируются.
Кастомные ресурсы тоже классная штука. У меня базы и юзеры мускуля вынесены в ресурсы и контроллер сам их настраивает. Это позволяет держать определения БД там же где и прочие зависимости приложения.
Возможность мапить секреты в env/файлы — очень удобно и постоянно пользуюсь. В swarm можно наверно использовать vault для замены? но это требует опять же движений руками.
да
docker swarm поддерживает только round robin для сервисов же? k8s может тоже самое через iptables, в 1.9 упала поддержка ipvs и всех политик которые приходят с ним.
delk8s значительно больше умеет.
https://kubernetes.io/docs/concepts/services-networking/service/ + https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/ + https://kubernetes.io/docs/concepts/services-networking/ingress/ + https://kubernetes.io/docs/concepts/services-networking/network-policies/
А, я понял — вы про изменение размера диска внутри виртуалки.
Очень редко с таким сталкиваюсь, всегда проще нарезать новую, а данные на загрузочном диске и не хранятся. Я даже не уверен что облака AWS / GCP поддерживают такое.
Как это решается? примитивным скриптом. Отресайзить единственный раздел и отресайзить фс. Если на лету страшно — то ребутнуть машину, coloudinit отресайзит на загрузке.
Хранить виртуалки на LVM или Ceph? Всегда так делаю :-)
Ну так сделайте один раздел на весь диск и на нем хоть LVM, хоть Ceph Bluestore.
LVM существенно сложнее GPT. В LVM нетривиально получить данные по логическому смещению.
Разобрался. Вообще идея хорошая, но создать рутовый акк надо было, чтоб все как по привычке.
Потом берем токен из
kube-system/root-token-xxxxи куда-то надежно прячем.Есть еще вот эта замечательная дока про k8s с нуля: kubernetes the hard way
Аналогично :-)
Но admission controller'ы все еще не могут мутировать ничего кроме image, так что sidecar контейнер вставить не выйдет.
Если вы в k8s поднимете mysql в StatefulSet с одним инстансом и PersistentVolumeClaim для хранилища — это фактически ничем не будет отличаться от mysql вне k8s.
В самой простой ситуации вы прибиваете Volume на каталог хост машины и получаете 1:1 ту же надежность как и вне кластера (машина умерла — БД умерла с ней).
Как это можно улучшить уже средствами k8s? Можно использовать сетевое хранилище для PVC, например ceph rbd, aws ebs, iscsi или даже nfs. Таким образом при потере машины, рабочая нагрузка мигрирует на другую, а хранилище перемонтируется. Это не гарантирует отсутствие даунтайма, и потенциально медленнее (сетевое хранилище хуже чем локальный SSD).
Дальше в дело вступает репликация. Если ваша БД может комфортно работать в режиме master-master, то вы просто поднимаете N реплик тем же StatefulSet и потеря любой из них не будет вас волновать, мастера догонятся друг от друга. В таком случае можно использовать эфемерное хранилище (тот же локальный диск), т.к. потеря данных одной ноды не критична.
Наконец, можно делать R/W + R/O реплики (для mysql это, наверно, оптимальный вариант для быстрого чтения и наименьшего простоя). У k8s прямо в доках есть пример для mysql. Тут первая реплика это R/W с персистентным хранилищем, а последующие — R/O с эфемерным и они догоняются от реплики N-1. Падение машины с первой репликой дает вам даунтайм на запись (пока mysql запускается на другой ноде), потеря R/O реплик полностью незаметна, плюс R/O реплики читают с локального быстрого диска.
TL;DR: БД отлично работают в контейнерах, просто надо понимать где вы выигрываете, и что теряете.