
ОВР — Очень Важные Реакции
2 мин
Так уж исторически сложилось, что одной из самых сложных задач школьной химии всегда являлись окислительно-восстановительные реакции. Электронные конфигурации атомов, комплексные соединения, и даже устройство солей перксеноновой кислоты не вызывают у детей столько оторопи, сколько уравнивание ОВР. Так как часть нашей команды занимается созданием сервисов для школьников, мы захотели помочь решить проблему с поиском окислительно-восстановительных реакций. Разумеется, нам очень не хотелось потворствовать списыванию, поэтому мы постарались сделать наш сервис обучающим, чтобы любому школьнику стало понятно, как же уравниваются те самые ОВР.
В первую очередь для всех имеющихся у нас окислительно-восстановительных реакций мы стали показывать соответствующие полуреакции.
Например, вот так:
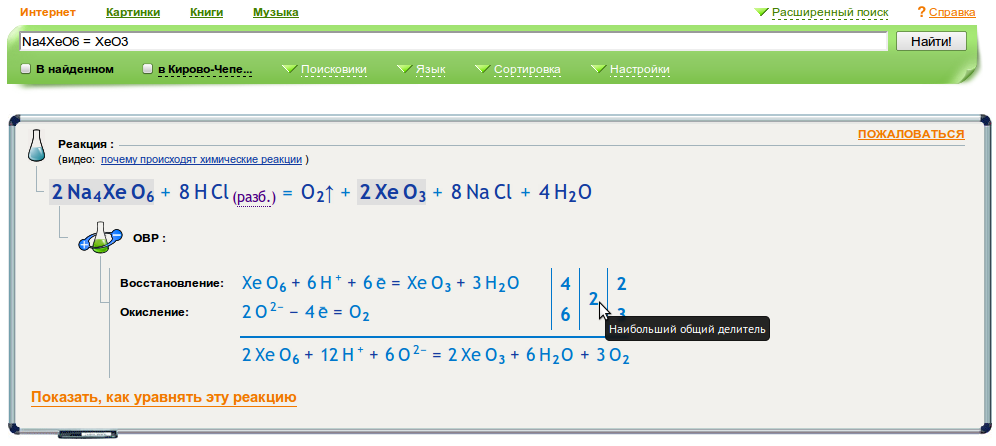
В первую очередь для всех имеющихся у нас окислительно-восстановительных реакций мы стали показывать соответствующие полуреакции.
Например, вот так:

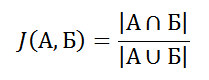


 Судоку — популярная головоломка, основной задачей которой является размещение цифр в правильном порядке.
Судоку — популярная головоломка, основной задачей которой является размещение цифр в правильном порядке.