Как относитесь к использованию публичных полей вместо свойств? Коллеги меня убеждали, что это последний писк джава-моды, и геттеры-сеттеры уже никто не генерит, даже ломбоком.
Код, конечно может выглядеть более громоздко, чем аннотация, но если учесть, что он реально защищает от NPE, а аннотации — нет, может оно того и стоит.
Отвечая на свой же первый вопрос, нагуглилась вот такая штука: https://checkerframework.org/manual/#nullness-checker. Есть ли у кого-нибудь опыт использования на практике? По идее, статическая проверка должна быть лучше, чем Lombok...
Статья навеяла несколько вопросов о работе с null:
Можно ли прикрутить к @NonNull какие-нибудь статические проверки, что null туда реально не попадает? Что делать (и как вообще это узнать), когда аннотация поставлена неправильно?
Стоит ли NPE в рантайме, которую генерирует Lombok, таких усилий по разметке аннотациями всех полей, тестированию этого всего? Будет ли сильно хуже, если все эти аннотации просто выкинуть?
Почему нельзя использовать Optional? Оно хотя бы гарантирует корректную обработку nullable-значений на уровне компилятора, их уже не перепутаешь с non-null (хотя в обратную сторону — легко).
Java в Android застряла на уровне седьмой версии с некоторыми фишками из восьмой…
Kotlin же развивается более-менее предсказуемо и предоставляет обертки, которые позволяют использовать все современные возможности языка...
Вот здесь не понял логику. Если используемые Java-библиотеки переехали на Java 8/11/12, которая не поддерживается в Android, как Kotlin решает эту проблему?
Мне кажется, ключевой фичей такой системы должно быть как раз то, что она показывает каждому конкретному юзеру только небольшой фрагмент реального пула проксей. Причем, приглашенным юзерам она покажет тот же фрагмент, что и пригласившему их.
Пока цензоры будут строить карту проксей, система будет строить карту цензоров. Кто закончит быстрее — мне кажется это зависит от отношения количества проксей к количеству учеток цензоров. Если проксей гораздо больше — есть шанс на успех. Второй вопрос — где их столько взять. Может IPv6 как-то поможет?
Ваши пункты 3 и 4 исходят из того, что проксей будет мало. Но если их будет много, то такие атаки не сработают. Чем больше проксей, тем точнее можно вычислить цензоров. Одно дело, если каким-то прокси пользовался миллион человек и его заблокировали, и совсем другое, если им пользовалось всего 10 человек.
Пункты 2 и 5 исходят из того, что цензор сможет зарегить большое количество учеток в системе. Насколько я понимаю, авторы проекта собираются верифицировать юзеров, т.е. нарегить виртуалов будет не так просто. Если сделать, чтобы приглашенным юзерам выдавались только прокси, которые уже видел пригласивший их — ущерб от блокировки будет минимальным, а вычислить и перебанить "цензоров", наоборот, довольно легко.
противодействие атакам осуществляется с помощью требований предоставить при регистрации в системе ссылку на действующий аккаунт в соцсети или получить рекомендацию пользователя с высоким уровнем доверия.
Если сделать это по уму, миллион виртуальных учеток завести не получится.
Вычислить все равно будет возможно при условии, что количество проксей в пуле сильно больше (желательно, на порядки), чем есть учеток в этой системе у цензора.
Как минимум синтез на русском языке у них работает весьма неплохо по сравнению с тем же гуглом. Желающие могут сравнить сами, у них есть демо на https://voicefabric.ru/ Там правда нет Варвары, о которой речь в новости, но есть другие женские голоса.
Ну когда технические вопросы решаются нетехническими аргументами, тут больше вопрос к девелоперам, согласны ли они тратить свое время на такие проекты. Выбор-то всегда есть.
Если вы писали production-level спарк джобы и на скале и на джаве, юзали спарк-шелл, сами скажите, только честно, какой язык больше подходит для спарка?
К сожалению, не вижу прагматических соображений. Вижу домыслы, основанные на слухах.
Потому что для компании Одерского Scala уже два года как не приоритет.
Одерский занимается dotty (которая Scala 3.0), "компания Одерского" (Lightbend) готовится к релизу Scala 2.13. Если для них Scala уже два года как не приоритет, то что тогда приоритет, неужели Java? И еще вопрос, а для Оракла Java точно приоритет?
Да, ресурсы Oracle и Lightbend несопоставимы, да, Java-community гораздо больше, чем Scala. Но все равно Scala технически круче Java. Это хотя бы факты, а не странные домыслы насчет приоритетов.
Последний параграф, по-моему, несколько противоречит сам себе. Если синтаксически не сильно отличается, откуда возьмутся проблемы с поиском программистов? Ну и плюс Спарк же врядли перепишут на джаву, так что для него аргументы в пользу скалы будут в силе и через 5 лет.
Запустите опрос о том, кто и на чём на Spark пишет.
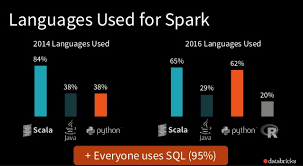
В ход пошли нетехнические аргументы? Я нашел статистику от датабрикс за 2016 год. Если у кого есть свежее, пожалуйста, делитесь:
Да и, вопрос, если BigData, то Spark ли… И стоит для Ignite или Flink использовать что-то кроме Java?
Обычно инструмент подбирают исходя из задачи, а не из предпочтений относительно ЯП. Если нужен Spark и уже знаете Java — разумнее всего сделать полшага вперед и перейти на Scala. Если конечно это прагматический вопрос, а не религиозный.
Не совсем. Во-первых, с большой вероятностью придется читать код спарка, который на Scala, т.е. не знать ее нельзя. Во-вторых, если знаешь Scala, зачем писать более многословный, сложночитаемый и склонный к ошибкам код, если можно этого не делать?

А остальные высокоуровненые языки программирования разве нужны для чего-то другого?
Как относитесь к использованию публичных полей вместо свойств? Коллеги меня убеждали, что это последний писк джава-моды, и геттеры-сеттеры уже никто не генерит, даже ломбоком.
Если сталкивающиеся газ и антигаз электрически нейтральны, они могут аннигилировать только за счет сильного и слабого взаимодействия, правильно?
Попробую возразить по поводу
Optional.Возможность передачи
nullвместоOptionalэто конечно беда, от этого придется защищаться статическими проверками (вроде как Findbugs что-то умеет http://findbugs.sourceforge.net/bugDescriptions.html#NP_OPTIONAL_RETURN_NULL). Плюс видимо придется защищаться отOptional.get().Код, конечно может выглядеть более громоздко, чем аннотация, но если учесть, что он реально защищает от NPE, а аннотации — нет, может оно того и стоит.
Отвечая на свой же первый вопрос, нагуглилась вот такая штука: https://checkerframework.org/manual/#nullness-checker. Есть ли у кого-нибудь опыт использования на практике? По идее, статическая проверка должна быть лучше, чем Lombok...
UPD: есть еще набор проверок в Findbugs: http://findbugs.sourceforge.net/bugDescriptions.html#NP_ALWAYS_NULL
Статья навеяла несколько вопросов о работе с
null:Можно ли прикрутить к
@NonNullкакие-нибудь статические проверки, чтоnullтуда реально не попадает? Что делать (и как вообще это узнать), когда аннотация поставлена неправильно?Стоит ли NPE в рантайме, которую генерирует Lombok, таких усилий по разметке аннотациями всех полей, тестированию этого всего? Будет ли сильно хуже, если все эти аннотации просто выкинуть?
Почему нельзя использовать
Optional? Оно хотя бы гарантирует корректную обработку nullable-значений на уровне компилятора, их уже не перепутаешь с non-null (хотя в обратную сторону — легко).Интересно, спринговые аннотации уже тьюринг-полны?
Название статьи не соответствует содержанию.
Вот здесь не понял логику. Если используемые Java-библиотеки переехали на Java 8/11/12, которая не поддерживается в Android, как Kotlin решает эту проблему?
Мне кажется, ключевой фичей такой системы должно быть как раз то, что она показывает каждому конкретному юзеру только небольшой фрагмент реального пула проксей. Причем, приглашенным юзерам она покажет тот же фрагмент, что и пригласившему их.
Пока цензоры будут строить карту проксей, система будет строить карту цензоров. Кто закончит быстрее — мне кажется это зависит от отношения количества проксей к количеству учеток цензоров. Если проксей гораздо больше — есть шанс на успех. Второй вопрос — где их столько взять. Может IPv6 как-то поможет?
Ваши пункты 3 и 4 исходят из того, что проксей будет мало. Но если их будет много, то такие атаки не сработают. Чем больше проксей, тем точнее можно вычислить цензоров. Одно дело, если каким-то прокси пользовался миллион человек и его заблокировали, и совсем другое, если им пользовалось всего 10 человек.
Пункты 2 и 5 исходят из того, что цензор сможет зарегить большое количество учеток в системе. Насколько я понимаю, авторы проекта собираются верифицировать юзеров, т.е. нарегить виртуалов будет не так просто. Если сделать, чтобы приглашенным юзерам выдавались только прокси, которые уже видел пригласивший их — ущерб от блокировки будет минимальным, а вычислить и перебанить "цензоров", наоборот, довольно легко.
Если сделать это по уму, миллион виртуальных учеток завести не получится.
Вычислить все равно будет возможно при условии, что количество проксей в пуле сильно больше (желательно, на порядки), чем есть учеток в этой системе у цензора.
Да, тоже с таким сталкивался у них. Но мой вопрос к комментатору выше был больше про сами подходы к синтезу/распознаванию.
ПС. Если не секрет, у кого в итоге купили голосовой движок?
Хотелось бы узнать, почему вы так считаете?
Как минимум синтез на русском языке у них работает весьма неплохо по сравнению с тем же гуглом. Желающие могут сравнить сами, у них есть демо на https://voicefabric.ru/ Там правда нет Варвары, о которой речь в новости, но есть другие женские голоса.
Ну когда технические вопросы решаются нетехническими аргументами, тут больше вопрос к девелоперам, согласны ли они тратить свое время на такие проекты. Выбор-то всегда есть.
Если вы писали production-level спарк джобы и на скале и на джаве, юзали спарк-шелл, сами скажите, только честно, какой язык больше подходит для спарка?
К сожалению, не вижу прагматических соображений. Вижу домыслы, основанные на слухах.
Одерский занимается dotty (которая Scala 3.0), "компания Одерского" (Lightbend) готовится к релизу Scala 2.13. Если для них Scala уже два года как не приоритет, то что тогда приоритет, неужели Java? И еще вопрос, а для Оракла Java точно приоритет?
Да, ресурсы Oracle и Lightbend несопоставимы, да, Java-community гораздо больше, чем Scala. Но все равно Scala технически круче Java. Это хотя бы факты, а не странные домыслы насчет приоритетов.
Последний параграф, по-моему, несколько противоречит сам себе. Если синтаксически не сильно отличается, откуда возьмутся проблемы с поиском программистов? Ну и плюс Спарк же врядли перепишут на джаву, так что для него аргументы в пользу скалы будут в силе и через 5 лет.
"Один раз — не скалист" — такая логика, что ли :)
Про "обязательно", я вроде и не писал нигде. Можно конечно и на джаве превозмогать, если есть время и желание.
В ход пошли нетехнические аргументы? Я нашел статистику от датабрикс за 2016 год. Если у кого есть свежее, пожалуйста, делитесь:
Обычно инструмент подбирают исходя из задачи, а не из предпочтений относительно ЯП. Если нужен Spark и уже знаете Java — разумнее всего сделать полшага вперед и перейти на Scala. Если конечно это прагматический вопрос, а не религиозный.
Не совсем. Во-первых, с большой вероятностью придется читать код спарка, который на Scala, т.е. не знать ее нельзя. Во-вторых, если знаешь Scala, зачем писать более многословный, сложночитаемый и склонный к ошибкам код, если можно этого не делать?