На хабре уже было несколько статей про lock-free алгоритмы. Этот пост — это перевод статьи моего коллеги, которую мы планируем публиковать в нашем корпоративном блоге. По роду деятельности мы пишем огромное количество lock-free алгоритмов и структур данных, и этой статьей хочется показать, насколько это интересно и сложно одновременно.

Эта статья во многом похожа на эту статью, но в той статье рассматриваются не все проблемы, с которыми можно столкнуться, разрабатывая lock-free структуры данных, и уделяется очень мало внимания решению этих проблем. В этой статье хочется детально остановиться на некоторых решениях, которые мы используем в реальной реализации lock-free структур данных в нашем продукте, и больше внимания уделить оценке производительности.
По определению, lock-free алгоритм гарантирует, что время между двумя подряд идущими завершенными операциями ограничено сверху некоторой величиной, которая не зависит от того, как операционная система эти потоки распределит во времени. Такая гарантия звучит очень приятно, потому что потоки могут обращаться к одному и тому же участку памяти одновременно, и даже если операционная система решит временно усыпить один или несколько потоков посреди выполнения какой-то операции с этим участком памяти, остальные потоки продолжат работу. Как бы два или более потока не пересеклись друг с другом во времени, хотя бы один из них всегда завершится за конечное время (в отличие от wait-free, lock-free не гарантирует, что все они завершатся за конечное время).
Lock-free алгоритмы обычно противопоставляются традиционному подходу к написанию многопоточных приложений с использованием блокировок вокруг кода, обращающегося к общим участкам памяти. Когда поток хочет обратиться к памяти, он блокирует к ней доступ других потоков. Если какой-то другой поток заблокировал доступ раньше, то текущий поток ждет, пока блокировка не будет снята. Если операционная система решит временно усыпить поток, владеющий блокировкой, вся система останавливается без возможности изменить общий участок памяти.
Вместо использования блокировок, lock-free алгоритмы используют команду, известную как compare and swap (CAS). Ее логику можно описать следующим фрагментом кода, с той оговркой, что CAS выполняется атомарно:
Основными проблемами lock-free алгоритмов являются следующие три:
1. Часто lock-free реализация является менее практичной, чем реализация с блокировками.
2. Писать lock-free код не просто.
3. Писать правильный lock-free код невероятно сложно.
Чтобы доказать пункт три, расмотрим простой пример — реализацию стека на связных списках. Если попросить человека, не знакомого с lock-free написать стек, то его первая реализация будет примерно следующей:
Для операции добавления в стек, создадим новый элемент связного списка, указатель на следующий элемент которого указывает на текущую вершину стека. Затем попытаемся с помощью CAS поменять вершину стека на новый элемент. Если CAS проходит успешно, элемент вставлен. Если CAS возвращается с ошибкой (что значит, что вершина стека изменилась между тем, как мы ее прочитали, и тем, как CAS выполнился), повторим все с начала.
Для операции удаления из стека, запомним текущую вершину стека, и, с помощью CAS, попытаемся поменять ее на значение ее указателя на следующий элемент. Если CAS прошел успешно, то элемент из стека убран, иначе вершина стека была изменена другим потоком, и мы пытаемся удалить ее опять.
На С++ это будет выглядить примерно следующим образом:
К сожалению, эта, кажущаяся на первый взгляд разумной, реализация lock-free стека содержит огромное количество ошибок.
Даже самый простой тест такого стека быстро упадет с Segmentation Fault. Причина — в строке 22 мы читаем указатель на текущую вершину стека. В стоке 26 мы обращаемся к ее полю next. За время между тем, как мы прочитали указатель, и тем, как мы обратились к его полю next, одновременно выполняющийся Pop мог удалить этот элемент (строка 29), тем самым приведя к тому, что память, прочитанная в стоке 26, уже освобождена.
Для правильной работы алгоритма необходим какой-то безопасный алгоритм управления памятью.
Успешный CAS не гарантирует, что за время его выполнения память не была изменена. Он гарантирует, что ее значение в момент, когда он ее перезаписал, было равно тому значению, которое ему передано как ожидаемое. Иными словами, если вы вызываете CAS(ptr, 5, 6) в момент, когда значение в ptr равно пяти, затем другой поток меняет значение в ptr на семь, и затем обратно на пять, CAS выполнится успешно, перезависав пять шестью. Это может привести к проблеме, известной как проблема ABA. Рассмотрим следующий пример:
Допустим, что в стеке сейчас два элемента, A -> C.
Поток 1 вызывает Pop, читает в строке 22 m_head (A), в строке 26 читает old_head->next (С), а затем операционная система усыпляет поток.
Поток 2 вызывает Pop, и успешно убирает элемент A.
Поток 2 вызывает Push, и успешно вставляет элемент B.
Поток 2 вызывает Push опять, и вставляет элемент, расположенный по тому же адресу, что и A (либо A был освобожден, и затем другой элемент был заведен по тому же адресу, либо пользователь решил вставить элемент, который он только что взял со стека, обратно)
Поток 1 просыпается, и вызывает CAS. CAS выполняется успешно, не смотря на то, что за это время m_head изменился три раза! Как следствие, элемент B потерян.
Стандарт С++ не гарантирует, что new и delete являются lock-free. В чем смысл разрабатывать lock-free алгоритм, если он вызывает библиотечные функции, которые не lock-free? Для того, чтобы алгоритм был lock-free, работа с памятью тоже должна быть lock-free.
Если текущее значение в некоторой ячейке памяти равно 100, и один из потоков в данный момент пишет в нее 200, а другой поток читает ее значение (допустим, что кроме этих двух потоков в системе других потоков нет). Какое значение прочитает второй поток? Кажется разумным, что он прочитает либо 100, либо 200. Однако, это не так. В С++ описанный сценарий приводит к неопределенному поведению, и второй поток теоретически может прочитать 42. До C++11 люди использовали volatile для переменных, к которым был возможен одновременный доступ, но на самом деле volatile для этой цели использован никогда быть не должен.
В нашей реализации Push и Pop оба читают и пишут m_head, тем самым, каждое чтение m_head приводит к неопределенному поведению, и может вернуть значение, которое никогда в m_head записано не было.
Хорошо известно, что как компилятор, так и процессор могут поменять порядок выполнения команд. Рассмотрим такой пример. Пусть x и y оба равны нулю, и затем два потока выполняют следующий код:
Поток 1: print x; x = 1; print y;
Поток 2: print y; y = 1; print x;
Допустим, что оба потока вывели два нуля. Из этого следует, что первый поток вывел y до того, как второй поток присвоил ему единицу, что произошло перед тем, как второй поток вывел x, что произошло перед тем, как первый поток присвоил ему единицу, что произошло перед тем, как первый поток вывел y. То есть первый поток вывел y прежде, чем он вывел y, что не имеет смысла. Однако, такой сценарий возможен, потому что как компилятор, так и процессор могли поменять порядок чтения и записи x и y врутри потоков.
В нашей реализации lock-free стека мы можем видеть значение в указателе на следующий элемент, которое было давно изменено, и, как следствие, можем обратиться к памяти, которая была освобождена.
Большинство описанных проблем имеют более одного решения. Здесь приводятся решения, которые мы используем в нашей работе как для стека, так и для других структур данных.
Прежде, чем удалить участок памяти, надо убедиться, что никто эту память не читает. Первая мысль, которая приходит на ум, это использовать счетчик ссылок, но это решение не работает: между тем, как мы получили адрес, и тем, как мы увеличили счетчик ссылок, память могла быть освобождена. Мы используем решение, которое называется «Hazard Pointers». В случае для стека, каждый поток имеет спецальный видимый всем указатель (назовем его «локальный указатель»), где хранится адрес элемента, с которым данный поток работает в настоящий момент. Прежде, чем удалить любой элемент, удаляющий поток убеждается, что этот элемент не содержится ни в одном из локальных указателей. Если он содержится в локальных указателях, удалять элемент нельзя. Можно либо подождать и попробовать снова, либо занести элемент в очередь на удаление и доверить другим потокам удалить его позже.
Каждый поток, который хочет сделать какую-либо операцию на вершине стека сначала сохраняет вершину стека в свой локальный указатель, затем убеждается, что сохраненный в локальный указатель элемент все еще является вершиной стека (он мог быть убран и память могла быть освобождена пока мы сохраняли его в локальный указатель). После этого поток может быть уверен, что память, занятая элементом, освобождена не будет.
Большим недостатком может являться то, что для удаления элемента требуется просканировать массив, размер которого равен количеству потоков в системе. Один из вариантов оптимизации может быть следующий: вместо удаления элемента всегда класть его в очередь, и только когда очередь набирает достаточно большое количество элементов на удаление (сравнимое с количеством потоков), удалить их все сразу. В этом случае можно скопировать значения всех локальных указателей на тот момент в какую-то структуру данных с быстрым поиском (например, хеш-таблицу), и использовать эту структуру данных, чтобы проверять, можно ли удалить элемент.
Для структур данных сложнее, чем стек (связные списки, skiplists) может потребоваться более одного локального указателя на поток.
Чтобы ABA проблема никогда не происходила, достаточно гарантировать, что m_head никогда не примет одно и тоже значение дважды. Для этого можно хранить с указателем 64-ех битное число (назовем его версией), которое увеличивается на единицу с каждой операцией. Для того, чтобы менять указатель и версию одновременно, нам понадобится Double CAS, который доступен на всех современных процессорах.
Чтобы решить проблему с заведением памяти, можно просто не заводить память. В нашем коде мы сохраняем указатель на следующий элемент прямо в структуре элемента. Но это не всегда является приемлемым решением, потому что расходуется 8 байт на каждый элемент, даже если элемент не находится в стеке.
Мы используем boost::atomic для переменных, к которым возможен доступ из нескольких потоков. Хотя в компиляторе, который мы используем (g++ 4.6) уже есть реализация std::atomic, она значительно менее эффективна, чем boost::atomic, потому что использует memory_barrier после каждой операции, даже если memory_barrier после нее не нужен.
В С++11 была введена новая модель памяти и правила обращения к памяти для atomic переменных. Для каждой операции чтения или записи можно указать, какие гарантии требуются. Для обращений к вершине lock-free стека мы вынуждены использовать CompareAndSwap с гарантией sequential consistency (это самая строгая гарантия, и, как следствие, самая медленная). Sequential consistency значит, что для всех операций чтения и записи, выполненных в некоторый промежуток времени всеми потоками, существует порядок такой, что каждый поток видел эти операции, как если бы они произошли в этом порядке.
Если вы понимаете модель памяти С++11, и попытаетесь проанилизировать, какие гарантии следует использовать для работы с локальными указателями (hazard pointers), вы можете предположить, что aqcuire/release достаточны.
Мы использовали acquire/release некоторое время, пока в один день сервер не упал на удачно поставленном assert. Детальный анализ ошибки показал, что при использовании acquire/release возможен следующий сценарий:
Поток 1 готовится выполнить Pop и читает вершину стека
Поток 1 пишет вершину стека в свой локальный указатель (используя release гарантию)
Поток 1 читает вершину стека снова, она не изменилась
Поток 2 убирает вершину стека, и решает ее удалить (или добавляет в очередь на удаление, и другой поток решает ее удалить — назовем поток, удаляющий элемент, Поток 3)
Поток 3 читает массив локальных указателей с гарантией acquire. Здесь возникает пробоема — не гарантируется, что мы видим изменение, сделанное Потоком 1.
Поток 3 удаляет память.
Поток 1 разыменовывает сохраненную вершину стека, которая была удалена, и падает с SegFault.
Если же использовать Sequential Consistency как для доступа к локальным указателям, так и для работы с вершиной стека, такой сценарий не возможен. Поскольку порядок операций для всех потоков одинаков, то либо Поток 2 убрал элемент с вершины стека прежде, чем Поток 1 проверил его после записи в локальный указатель (тогда Поток 1 поймет, что вершина стека изменилась, и начнет сначала), либо Поток 1 успешно сравнил свой локальный указатель с вершиной стека прежде, чем Поток 2 убрал элемент с вершины стека, что значит, что Поток 3 увидит удаляемую вершину стека в локальном указателе.
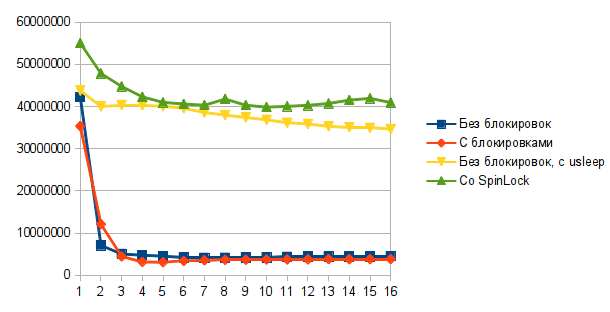
Для этой статьи мы написали две реализации стека: одну lock-free, другую — с использованием std::mutex. Тестовая программа запускала несколько потоков, и вызывала Push и Pop с равной вероятностью в бесконечном цикле. Для замеров использовался Dell Precision T5500. Результаты показаны на графике ниже. Ось X — количество потоков, ось Y — количество операций в секунду.
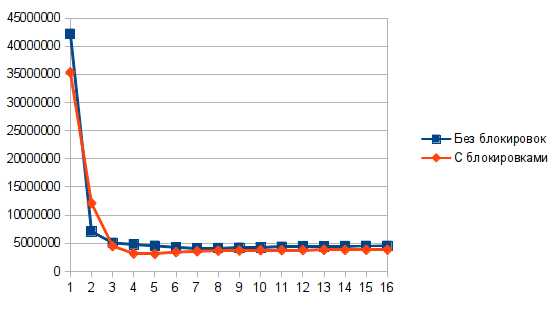
Выглядит не очень впечатляюще.
Одна из проблем заключается в том, что по своей природе стек имеет очень узкое место — его вершину. Все потоки сражаются за то, чтобы изменить ее первыми, и производительность будет настолько высока, насколько быстро есть теоретическая возможность менять вершину. Операции Push и Pop настолько просты, что даже при использовании одного потока упираются в лимит количества изменений вершины стека в единицу времени. Добавление новых потоков только замедляет общую производительность, потому что теперь надо синхронизировать изменения вершины стека между потоками.
Другая проблема заключается в том, что когда несколько потоков одновременно пытаются поменять вершину стека, только один из них это успешно сделает, и все остальные потоки пойдут на новую итерацию. Это проблема. Как известно, у каждой проблемы есть быстрое, красивое но неправильное решение. Таким решением для этой проблемы будет добавить usleep(250) после неудачного CAS. Это простой, но не оптимальный способ заставить потоки меньше пересекаться при изменении вершины стека. Результат может показаться удивительным — добавление usleep(250) улучшает производительность в 10 раз! На практике мы используем немного более сложные подходы для уменьшения количества неудачных CAS, но как видно, даже такой простой подход, как usleep, дает отличные результаты.
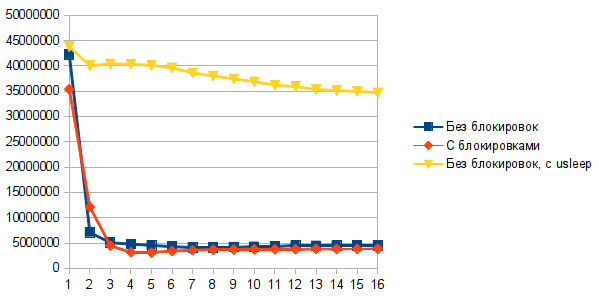
Интересно также посмотреть на то, сколько ресурсов потребляют различные реализации:
Вот так выглядит HTOP для запуска с lock-free стеком без usleep в 16 потоках:
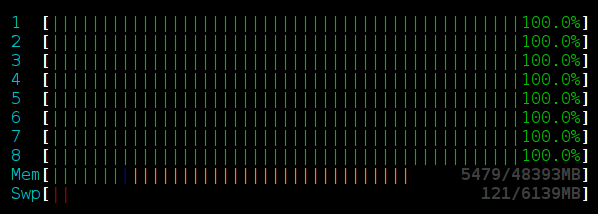
Как видно, процессор занят на 100%. Это связано с тем, что все потоки в цикле пытаются изменить вершину стека, снова и снова выполняя новую итерацию, целиком потребляя доступное им процессорное время.
Вот так выглядит HTOP для запуска с lock-free стеком с usleep в 16 потоках:
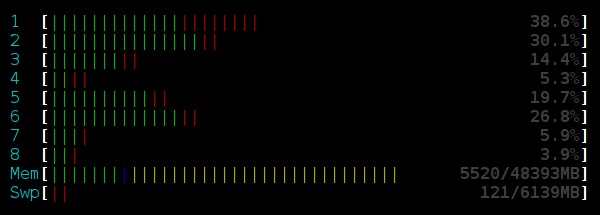
Процессор почти простаивает. Потоки, не сумевшие сразу поменять вершину, спят, не занимая процессор. Это удивительное наблюдение — добавление usleep не только увеличило полезную производительность в 10 раз, но и заметно понизило потребление процессорного времени.
Вот так выглядит HTOP для запуска со стеком с блокировками в 16 потоках:
Здесь хорошо видно, что процессор целиком занят системными вызовами. Иными словами, почти все процессорное время затрачено на работу с блокировками.
Lock-free гарантирует, что система всегда будет выполнять полезную работу, даже если часть потоков была приостановлена операционной системой. Но lock-free не гарантирует, что это будет достигнуто эффективно. Кроме того, lock-free алгоритмы часто содержат ошибки, которые не всегда легко заметить или воспроизвести. Простая реализация стека в начале этой статьи содержала пять различных ошибок, и по производительности уступала реализации с блокировками. Если вы хотите использовать lock-free алгоритмы, убедитесь, что они того стоят, как с точки зрения производительности, так и с точки зрения сложности реализации. Старайтесь не изобретать свои собственные lock-free алгоритмы, а находить готовые реализации или научные работы.
Код бенчмарка также доступен на github (если вы хотите запустить тест локально):
https://github.com/memsql/lockfree-bench
По предложению lostmsu добавил в бенчмарк стек со spinlock вместо std::mutex. Для чистоты эксперемента использовал spinlock, который, как и lockfree реализация, спит 250 миллисекунд, если не удается захватить блокировку с первой попытки. Не неожиданно, такая реализация оказалась производительнее и lock-free реализации, и реализации с std::mutex. Потребление процессора визуально такое же, как и у lock-free реализации с usleep(250).
Репозиторий на гитхабе тоже обновлен с новой реализацией.

Эта статья во многом похожа на эту статью, но в той статье рассматриваются не все проблемы, с которыми можно столкнуться, разрабатывая lock-free структуры данных, и уделяется очень мало внимания решению этих проблем. В этой статье хочется детально остановиться на некоторых решениях, которые мы используем в реальной реализации lock-free структур данных в нашем продукте, и больше внимания уделить оценке производительности.
По определению, lock-free алгоритм гарантирует, что время между двумя подряд идущими завершенными операциями ограничено сверху некоторой величиной, которая не зависит от того, как операционная система эти потоки распределит во времени. Такая гарантия звучит очень приятно, потому что потоки могут обращаться к одному и тому же участку памяти одновременно, и даже если операционная система решит временно усыпить один или несколько потоков посреди выполнения какой-то операции с этим участком памяти, остальные потоки продолжат работу. Как бы два или более потока не пересеклись друг с другом во времени, хотя бы один из них всегда завершится за конечное время (в отличие от wait-free, lock-free не гарантирует, что все они завершатся за конечное время).
Lock-free алгоритмы обычно противопоставляются традиционному подходу к написанию многопоточных приложений с использованием блокировок вокруг кода, обращающегося к общим участкам памяти. Когда поток хочет обратиться к памяти, он блокирует к ней доступ других потоков. Если какой-то другой поток заблокировал доступ раньше, то текущий поток ждет, пока блокировка не будет снята. Если операционная система решит временно усыпить поток, владеющий блокировкой, вся система останавливается без возможности изменить общий участок памяти.
Вместо использования блокировок, lock-free алгоритмы используют команду, известную как compare and swap (CAS). Ее логику можно описать следующим фрагментом кода, с той оговркой, что CAS выполняется атомарно:
1 bool CompareAndSwap(Value* addr, Value oldVal, Value newVal){
2 if(*addr == oldVal){
3 *addr = newVal;
4 return true;
5 }else{
6 return false;
7 }
8 }
Основными проблемами lock-free алгоритмов являются следующие три:
1. Часто lock-free реализация является менее практичной, чем реализация с блокировками.
2. Писать lock-free код не просто.
3. Писать правильный lock-free код невероятно сложно.
Чтобы доказать пункт три, расмотрим простой пример — реализацию стека на связных списках. Если попросить человека, не знакомого с lock-free написать стек, то его первая реализация будет примерно следующей:
Для операции добавления в стек, создадим новый элемент связного списка, указатель на следующий элемент которого указывает на текущую вершину стека. Затем попытаемся с помощью CAS поменять вершину стека на новый элемент. Если CAS проходит успешно, элемент вставлен. Если CAS возвращается с ошибкой (что значит, что вершина стека изменилась между тем, как мы ее прочитали, и тем, как CAS выполнился), повторим все с начала.
Для операции удаления из стека, запомним текущую вершину стека, и, с помощью CAS, попытаемся поменять ее на значение ее указателя на следующий элемент. Если CAS прошел успешно, то элемент из стека убран, иначе вершина стека была изменена другим потоком, и мы пытаемся удалить ее опять.
На С++ это будет выглядить примерно следующим образом:
1 template <class Entry>
2 class LockFreeStack{
3 struct Node{
4 Entry* entry;
5 Node* next;
6 };
7
8 Node* m_head;
9
10 void Push(Entry* e){
11 Node* n = new Node;
12 n->entry = e;
13 do{
14 n->next = m_head;
15 }while(!CompareAndSwap(&m_head, n->next, n));
16 }
17
18 Entry* Pop(){
19 Node* old_head;
20 Entry* result;
21 do{
22 old_head = m_head;
23 if(old_head == NULL){
24 return NULL;
25 }
26 }while(!CompareAndSwap(&m_head, old_head, old_head->next));
27
28 result = old_head->entry;
29 delete old_head;
30 return result;
31 }
32 }
К сожалению, эта, кажущаяся на первый взгляд разумной, реализация lock-free стека содержит огромное количество ошибок.
SegFault
Даже самый простой тест такого стека быстро упадет с Segmentation Fault. Причина — в строке 22 мы читаем указатель на текущую вершину стека. В стоке 26 мы обращаемся к ее полю next. За время между тем, как мы прочитали указатель, и тем, как мы обратились к его полю next, одновременно выполняющийся Pop мог удалить этот элемент (строка 29), тем самым приведя к тому, что память, прочитанная в стоке 26, уже освобождена.
Для правильной работы алгоритма необходим какой-то безопасный алгоритм управления памятью.
Потеря элемента
Успешный CAS не гарантирует, что за время его выполнения память не была изменена. Он гарантирует, что ее значение в момент, когда он ее перезаписал, было равно тому значению, которое ему передано как ожидаемое. Иными словами, если вы вызываете CAS(ptr, 5, 6) в момент, когда значение в ptr равно пяти, затем другой поток меняет значение в ptr на семь, и затем обратно на пять, CAS выполнится успешно, перезависав пять шестью. Это может привести к проблеме, известной как проблема ABA. Рассмотрим следующий пример:
Допустим, что в стеке сейчас два элемента, A -> C.
Поток 1 вызывает Pop, читает в строке 22 m_head (A), в строке 26 читает old_head->next (С), а затем операционная система усыпляет поток.
Поток 2 вызывает Pop, и успешно убирает элемент A.
Поток 2 вызывает Push, и успешно вставляет элемент B.
Поток 2 вызывает Push опять, и вставляет элемент, расположенный по тому же адресу, что и A (либо A был освобожден, и затем другой элемент был заведен по тому же адресу, либо пользователь решил вставить элемент, который он только что взял со стека, обратно)
Поток 1 просыпается, и вызывает CAS. CAS выполняется успешно, не смотря на то, что за это время m_head изменился три раза! Как следствие, элемент B потерян.
Не lock-free
Стандарт С++ не гарантирует, что new и delete являются lock-free. В чем смысл разрабатывать lock-free алгоритм, если он вызывает библиотечные функции, которые не lock-free? Для того, чтобы алгоритм был lock-free, работа с памятью тоже должна быть lock-free.
Одновременный доступ к памяти
Если текущее значение в некоторой ячейке памяти равно 100, и один из потоков в данный момент пишет в нее 200, а другой поток читает ее значение (допустим, что кроме этих двух потоков в системе других потоков нет). Какое значение прочитает второй поток? Кажется разумным, что он прочитает либо 100, либо 200. Однако, это не так. В С++ описанный сценарий приводит к неопределенному поведению, и второй поток теоретически может прочитать 42. До C++11 люди использовали volatile для переменных, к которым был возможен одновременный доступ, но на самом деле volatile для этой цели использован никогда быть не должен.
В нашей реализации Push и Pop оба читают и пишут m_head, тем самым, каждое чтение m_head приводит к неопределенному поведению, и может вернуть значение, которое никогда в m_head записано не было.
Порядок обращений к памяти
Хорошо известно, что как компилятор, так и процессор могут поменять порядок выполнения команд. Рассмотрим такой пример. Пусть x и y оба равны нулю, и затем два потока выполняют следующий код:
Поток 1: print x; x = 1; print y;
Поток 2: print y; y = 1; print x;
Допустим, что оба потока вывели два нуля. Из этого следует, что первый поток вывел y до того, как второй поток присвоил ему единицу, что произошло перед тем, как второй поток вывел x, что произошло перед тем, как первый поток присвоил ему единицу, что произошло перед тем, как первый поток вывел y. То есть первый поток вывел y прежде, чем он вывел y, что не имеет смысла. Однако, такой сценарий возможен, потому что как компилятор, так и процессор могли поменять порядок чтения и записи x и y врутри потоков.
В нашей реализации lock-free стека мы можем видеть значение в указателе на следующий элемент, которое было давно изменено, и, как следствие, можем обратиться к памяти, которая была освобождена.
Так как же написать lock-free стек?
Большинство описанных проблем имеют более одного решения. Здесь приводятся решения, которые мы используем в нашей работе как для стека, так и для других структур данных.
SegFault
Прежде, чем удалить участок памяти, надо убедиться, что никто эту память не читает. Первая мысль, которая приходит на ум, это использовать счетчик ссылок, но это решение не работает: между тем, как мы получили адрес, и тем, как мы увеличили счетчик ссылок, память могла быть освобождена. Мы используем решение, которое называется «Hazard Pointers». В случае для стека, каждый поток имеет спецальный видимый всем указатель (назовем его «локальный указатель»), где хранится адрес элемента, с которым данный поток работает в настоящий момент. Прежде, чем удалить любой элемент, удаляющий поток убеждается, что этот элемент не содержится ни в одном из локальных указателей. Если он содержится в локальных указателях, удалять элемент нельзя. Можно либо подождать и попробовать снова, либо занести элемент в очередь на удаление и доверить другим потокам удалить его позже.
Каждый поток, который хочет сделать какую-либо операцию на вершине стека сначала сохраняет вершину стека в свой локальный указатель, затем убеждается, что сохраненный в локальный указатель элемент все еще является вершиной стека (он мог быть убран и память могла быть освобождена пока мы сохраняли его в локальный указатель). После этого поток может быть уверен, что память, занятая элементом, освобождена не будет.
Большим недостатком может являться то, что для удаления элемента требуется просканировать массив, размер которого равен количеству потоков в системе. Один из вариантов оптимизации может быть следующий: вместо удаления элемента всегда класть его в очередь, и только когда очередь набирает достаточно большое количество элементов на удаление (сравнимое с количеством потоков), удалить их все сразу. В этом случае можно скопировать значения всех локальных указателей на тот момент в какую-то структуру данных с быстрым поиском (например, хеш-таблицу), и использовать эту структуру данных, чтобы проверять, можно ли удалить элемент.
Для структур данных сложнее, чем стек (связные списки, skiplists) может потребоваться более одного локального указателя на поток.
Потеря элемента
Чтобы ABA проблема никогда не происходила, достаточно гарантировать, что m_head никогда не примет одно и тоже значение дважды. Для этого можно хранить с указателем 64-ех битное число (назовем его версией), которое увеличивается на единицу с каждой операцией. Для того, чтобы менять указатель и версию одновременно, нам понадобится Double CAS, который доступен на всех современных процессорах.
Не lock-free
Чтобы решить проблему с заведением памяти, можно просто не заводить память. В нашем коде мы сохраняем указатель на следующий элемент прямо в структуре элемента. Но это не всегда является приемлемым решением, потому что расходуется 8 байт на каждый элемент, даже если элемент не находится в стеке.
Одновременный доступ к памяти
Мы используем boost::atomic для переменных, к которым возможен доступ из нескольких потоков. Хотя в компиляторе, который мы используем (g++ 4.6) уже есть реализация std::atomic, она значительно менее эффективна, чем boost::atomic, потому что использует memory_barrier после каждой операции, даже если memory_barrier после нее не нужен.
Порядок обращений к памяти
В С++11 была введена новая модель памяти и правила обращения к памяти для atomic переменных. Для каждой операции чтения или записи можно указать, какие гарантии требуются. Для обращений к вершине lock-free стека мы вынуждены использовать CompareAndSwap с гарантией sequential consistency (это самая строгая гарантия, и, как следствие, самая медленная). Sequential consistency значит, что для всех операций чтения и записи, выполненных в некоторый промежуток времени всеми потоками, существует порядок такой, что каждый поток видел эти операции, как если бы они произошли в этом порядке.
Если вы понимаете модель памяти С++11, и попытаетесь проанилизировать, какие гарантии следует использовать для работы с локальными указателями (hazard pointers), вы можете предположить, что aqcuire/release достаточны.
Что такое acquire/release
Гарантия acquire/release может быть описана следующим сценарием: если Поток 1 поменял переменную A с гарантией release, а затем переменную B с гарантией release, а Поток 2 прочитал B с гаранией acquire, и увидел значение, записанное Потоком 1, то гарантируется, что если затем Поток 2 прочитает A с гарантией acquire, то он увидит изменение, сделанное Потоком 1.
Мы использовали acquire/release некоторое время, пока в один день сервер не упал на удачно поставленном assert. Детальный анализ ошибки показал, что при использовании acquire/release возможен следующий сценарий:
Поток 1 готовится выполнить Pop и читает вершину стека
Поток 1 пишет вершину стека в свой локальный указатель (используя release гарантию)
Поток 1 читает вершину стека снова, она не изменилась
Поток 2 убирает вершину стека, и решает ее удалить (или добавляет в очередь на удаление, и другой поток решает ее удалить — назовем поток, удаляющий элемент, Поток 3)
Поток 3 читает массив локальных указателей с гарантией acquire. Здесь возникает пробоема — не гарантируется, что мы видим изменение, сделанное Потоком 1.
Поток 3 удаляет память.
Поток 1 разыменовывает сохраненную вершину стека, которая была удалена, и падает с SegFault.
Если же использовать Sequential Consistency как для доступа к локальным указателям, так и для работы с вершиной стека, такой сценарий не возможен. Поскольку порядок операций для всех потоков одинаков, то либо Поток 2 убрал элемент с вершины стека прежде, чем Поток 1 проверил его после записи в локальный указатель (тогда Поток 1 поймет, что вершина стека изменилась, и начнет сначала), либо Поток 1 успешно сравнил свой локальный указатель с вершиной стека прежде, чем Поток 2 убрал элемент с вершины стека, что значит, что Поток 3 увидит удаляемую вершину стека в локальном указателе.
Производительность
Для этой статьи мы написали две реализации стека: одну lock-free, другую — с использованием std::mutex. Тестовая программа запускала несколько потоков, и вызывала Push и Pop с равной вероятностью в бесконечном цикле. Для замеров использовался Dell Precision T5500. Результаты показаны на графике ниже. Ось X — количество потоков, ось Y — количество операций в секунду.

Выглядит не очень впечатляюще.
Одна из проблем заключается в том, что по своей природе стек имеет очень узкое место — его вершину. Все потоки сражаются за то, чтобы изменить ее первыми, и производительность будет настолько высока, насколько быстро есть теоретическая возможность менять вершину. Операции Push и Pop настолько просты, что даже при использовании одного потока упираются в лимит количества изменений вершины стека в единицу времени. Добавление новых потоков только замедляет общую производительность, потому что теперь надо синхронизировать изменения вершины стека между потоками.
Другая проблема заключается в том, что когда несколько потоков одновременно пытаются поменять вершину стека, только один из них это успешно сделает, и все остальные потоки пойдут на новую итерацию. Это проблема. Как известно, у каждой проблемы есть быстрое, красивое но неправильное решение. Таким решением для этой проблемы будет добавить usleep(250) после неудачного CAS. Это простой, но не оптимальный способ заставить потоки меньше пересекаться при изменении вершины стека. Результат может показаться удивительным — добавление usleep(250) улучшает производительность в 10 раз! На практике мы используем немного более сложные подходы для уменьшения количества неудачных CAS, но как видно, даже такой простой подход, как usleep, дает отличные результаты.

Интересно также посмотреть на то, сколько ресурсов потребляют различные реализации:
Вот так выглядит HTOP для запуска с lock-free стеком без usleep в 16 потоках:

Как видно, процессор занят на 100%. Это связано с тем, что все потоки в цикле пытаются изменить вершину стека, снова и снова выполняя новую итерацию, целиком потребляя доступное им процессорное время.
Вот так выглядит HTOP для запуска с lock-free стеком с usleep в 16 потоках:

Процессор почти простаивает. Потоки, не сумевшие сразу поменять вершину, спят, не занимая процессор. Это удивительное наблюдение — добавление usleep не только увеличило полезную производительность в 10 раз, но и заметно понизило потребление процессорного времени.
Вот так выглядит HTOP для запуска со стеком с блокировками в 16 потоках:

Здесь хорошо видно, что процессор целиком занят системными вызовами. Иными словами, почти все процессорное время затрачено на работу с блокировками.
Заключение
Lock-free гарантирует, что система всегда будет выполнять полезную работу, даже если часть потоков была приостановлена операционной системой. Но lock-free не гарантирует, что это будет достигнуто эффективно. Кроме того, lock-free алгоритмы часто содержат ошибки, которые не всегда легко заметить или воспроизвести. Простая реализация стека в начале этой статьи содержала пять различных ошибок, и по производительности уступала реализации с блокировками. Если вы хотите использовать lock-free алгоритмы, убедитесь, что они того стоят, как с точки зрения производительности, так и с точки зрения сложности реализации. Старайтесь не изобретать свои собственные lock-free алгоритмы, а находить готовые реализации или научные работы.
Код
Исходный код
С блокировками:
Без блокировок (в коде отсутствует логика, отвечающая за очистку памяти)
1 #include <mutex>
2 #include <stack>
3
4 template<class T>
5 class LockedStack{
6 public:
7 void Push(T* entry){
8 std::lock_guard<std::mutex> lock(m_mutex);
9 m_stack.push(entry);
10 }
11
12 // For compatability with the LockFreeStack interface,
13 // add an unused int parameter.
14 //
15 T* Pop(int){
16 std::lock_guard<std::mutex> lock(m_mutex);
17 if(m_stack.empty()){
18 return nullptr;
19 }
20 T* ret = m_stack.top();
21 m_stack.pop();
22 return ret;
23 }
24
25 private:
26 std::stack<T*> m_stack;
27 std::mutex m_mutex;
28 };
Без блокировок (в коде отсутствует логика, отвечающая за очистку памяти)
1 class LockFreeStack{
2 public:
3 // Элементы стека должны наследоваться от Node
4 //
5 struct Node{
6 boost::atomic<Node*> next;
7 };
8
9
10 // К сожалению, нет платформо-независимого способа написать этот класс.
11 // Приведенный код работает для gcc на архитектуре x86_64.
12 //
13 class TaggedPointer{
14 public:
15 TaggedPointer(): m_node(nullptr), m_counter(0) {}
16
17 Node* GetNode(){
18 return m_node.load(boost::memory_order_acquire);
19 }
20
21 uint64_t GetCounter(){
22 return m_counter.load(boost::memory_order_acquire);
23 }
24
25 bool CompareAndSwap(Node* oldNode, uint64_t oldCounter, Node* newNode, uint64_t newCounter){
26 bool cas_result;
27 __asm__ __volatile__
28 (
29 "lock;"
30 "cmpxchg16b %0;"
31 "setz %3;"
32
33 : "+m" (*this), "+a" (oldNode), "+d" (oldCounter), "=q" (cas_result)
34 : "b" (newNode), "c" (newCounter)
35 : "cc", "memory"
36 );
37 return cas_result;
38 }
39 private:
40 boost::atomic<Node*> m_node;
41 boost::atomic<uint64_t> m_counter;
42 }
43 // Выравнивание по 16 байтам необходимо для правильной работы double cas
44 //
45 __attribute__((aligned(16)));
46
47
48 bool TryPushStack(Node* entry){
49 Node* oldHead;
50 uint64_t oldCounter;
51
52 oldHead = m_head.GetNode();
53 oldCounter = m_head.GetCounter();
54 entry->next.store(oldHead, boost::memory_order_relaxed);
55 return m_head.CompareAndSwap(oldHead, oldCounter, entry, oldCounter + 1);
56 }
57
58 bool TryPopStack(Node*& oldHead, int threadId){
59 oldHead = m_head.GetNode();
60 uint64_t oldCounter = m_head.GetCounter();
61 if(oldHead == nullptr){
62 return true;
63 }
64 m_hazard[threadId*8].store(oldHead, boost::memory_order_seq_cst);
65 if(m_head.GetNode() != oldHead){
66 return false;
67 }
68 return m_head.CompareAndSwap(oldHead, oldCounter, oldHead->next.load(boost::memory_order_acquire), oldCounter + 1);
69 }
70
71 void Push(Node* entry){
72 while(true){
73 if(TryPushStack(entry)){
74 return;
75 }
76 usleep(250);
77 }
78 }
79
80 Node* Pop(int threadId){
81 Node* res;
82 while(true){
83 if(TryPopStack(res, threadId)){
84 return res;
85 }
86 usleep(250);
87 }
88 }
89
90 private:
91 TaggedPointer m_head;
92 // Умножение на восемь позволяет каждому локальному указателю быть в
93 // своей собственной кеш-линии, что заметно ускоряет работу с ними.
94 //
95 boost::atomic<Node*> m_hazard[MAX_THREADS*8];
96 };
Код бенчмарка также доступен на github (если вы хотите запустить тест локально):
https://github.com/memsql/lockfree-bench
Update:
По предложению lostmsu добавил в бенчмарк стек со spinlock вместо std::mutex. Для чистоты эксперемента использовал spinlock, который, как и lockfree реализация, спит 250 миллисекунд, если не удается захватить блокировку с первой попытки. Не неожиданно, такая реализация оказалась производительнее и lock-free реализации, и реализации с std::mutex. Потребление процессора визуально такое же, как и у lock-free реализации с usleep(250).

Репозиторий на гитхабе тоже обновлен с новой реализацией.
