Этот вопрос уже давно подробно изучен, и наиболее широкое распространение получил метод полярных координат, предложенный Джорджем Боксом, Мервином Мюллером и Джорджем Марсальей в 1958 году. Данный метод позволяет получить пару независимых нормально распределенных случайных величин с математическим ожиданием 0 и дисперсией 1 следующим образом:
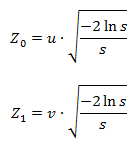
где Z0 и Z1 — искомые значения, s = u2 + v2, а u и v — равномерно распределенные на отрезке (-1, 1) случайные величины, подобранные таким образом, чтобы выполнялось условие 0 < s < 1.
Многие используют эти формулы, даже не задумываясь, а многие даже и не подозревают об их существовании, так как пользуются готовыми реализациями. Но есть люди, у которых возникают вопросы: «Откуда взялась эта формула? И почему получается сразу пара величин?». Далее я постараюсь дать наглядный ответ на эти вопросы.
Для начала напомню, что такое плотность вероятности, функция распределения случайной величины и обратная функция. Допустим, есть некая случайная величина, распределение которой задано функцией плотности f(x), имеющей следующий вид:
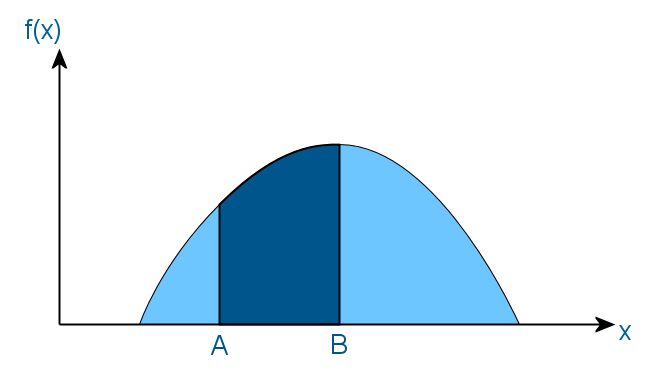
Это означает, что вероятность того, что значение данной случайной величины окажется в интервале (A, B), равняется площади затененной области. И как следствие, площадь всей закрашенной области должна равняться единице, так как в любом случае значение случайной величины попадет в область определения функции f.
Функция распределения случайной величины является интегралом от функции плотности. И в данном случае ее примерный вид будет такой:
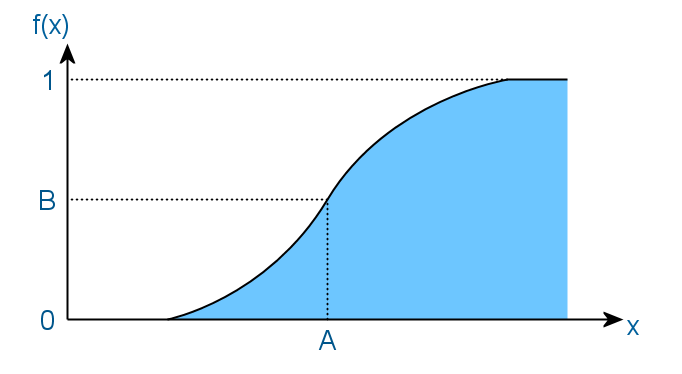
Тут смысл в том, что значение случайной величины будет меньше чем A с вероятностью B. И как следствие, функция никогда не убывает, а ее значения лежат в отрезке [0, 1].
Обратная функция — это функция, которая возвращает аргумент исходной функции, если в нее передать значение исходной функции. Например, для функции x2 обратной будет функция извлечения корня, для sin(x) это arcsin(x) и т.д.
Так как большинство генераторов псевдослучайных чисел на выходе дают только равномерное распределение, то часто возникает необходимость его преобразования в какое-либо другое. В данном случае в нормальное Гауссовское:
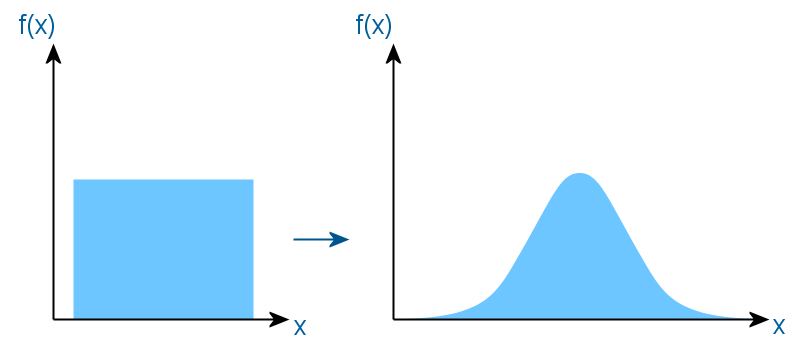
Основу всех методов преобразования равномерного распределения в любое другое составляет метод обратного преобразования. Работает он следующим образом. Находится функция, обратная функции необходимого распределения, и в качестве аргумента передается в нее равномерно распределенная на отрезке (0, 1) случайная величина. На выходе получаем величину с требуемым распределением. Для наглядности привожу следующую картинку.
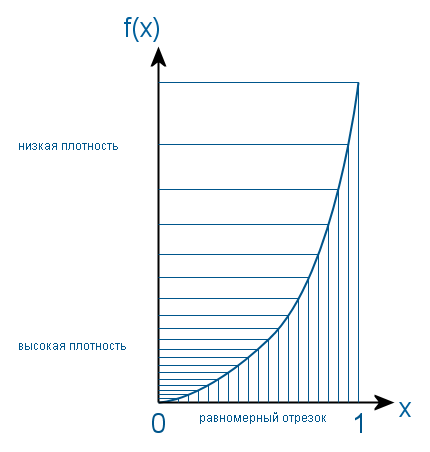
Таким образом, равномерный отрезок как бы размазывается в соответствии с новым распределением, проецируясь на другую ось через обратную функцию. Но проблема в том, что интеграл от плотности Гауссовского распределения вычисляется непросто, поэтому вышеперечисленным ученым пришлось схитрить.
Существует распределение хи-квадрат (распределение Пирсона), которое представляет собой распределение суммы квадратов k независимых нормальных случайных величин. И в случае, когда k = 2, это распределение является экспоненциальным.
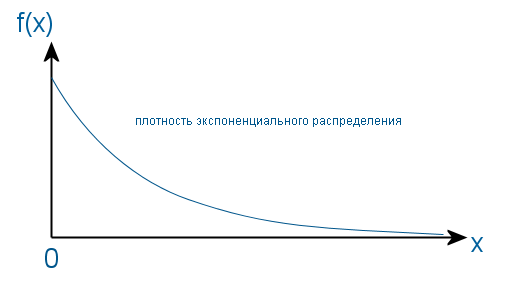
Это означает, что если у точки в прямоугольной системе координат будут случайные координаты X и Y, распределенные нормально, то после перевода этих координат в полярную систему (r, θ) квадрат радиуса (расстояния от начала координат до точки) будет распределен по экспоненциальному закону, так как квадрат радиуса — это сумма квадратов координат (по закону Пифагора). Плотность распределения таких точек на плоскости будет выглядеть следующим образом:
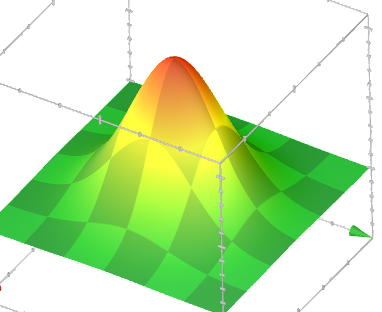
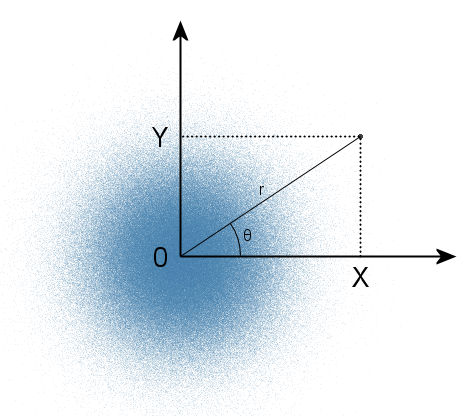
Так как она равноценна во всех направлениях, угол θ будет иметь равномерное распределение в диапазоне от 0 до 2π. Справедливо и обратное: если задать точку в полярной системе координат с помощью двух независимых случайных величин (угла, распределенного равномерно, и радиуса, распределенного экспоненциально), то прямоугольные координаты этой точки будут являться независимыми нормальными случайными величинами. А экспоненциальное распределение из равномерного получить уже гораздо проще, с помощью того же метода обратного преобразования. В этом и заключается суть полярного метода Бокса-Мюллера.
Теперь выведем формулы.
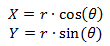 (1)
(1)
Для получения r и θ нужно сгенерировать две равномерно распределенные на отрезке (0, 1) случайные величины (назовем их u и v), распределение одной из которых (допустим v) необходимо преобразовать в экспоненциальное для получения радиуса. Функция экспоненциального распределения выглядит следующим образом:
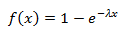
Обратная к ней функция:
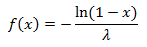
Так как равномерное распределение симметрично, то аналогично преобразование будет работать и с функцией
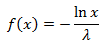
Из формулы распределения хи-квадрат следует, что λ = 0,5. Подставим в эту функцию λ, v и получим квадрат радиуса, а затем и сам радиус:
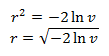
Угол получим, растянув единичный отрезок до 2π:
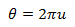
Теперь подставим r и θ в формулы (1) и получим:
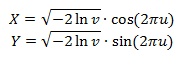 (2)
(2)
Эти формулы уже готовы к использованию. X и Y будут независимы и распределены нормально с дисперсией 1 и математическим ожиданием 0. Чтобы получить распределение с другими характеристиками достаточно умножить результат функции на среднеквадратическое отклонение и прибавить математическое ожидание.
Но есть возможность избавиться от тригонометрических функций, задав угол не прямо, а косвенно через прямоугольные координаты случайной точки в круге. Тогда через эти координаты можно будет вычислить длину радиус-вектора, а потом найти косинус и синус, поделив на нее x и y соответственно. Как и почему это работает?
Выберем случайную точку из равномерно распределенных в круге единичного радиуса и обозначим квадрат длины радиус-вектора этой точки буквой s:
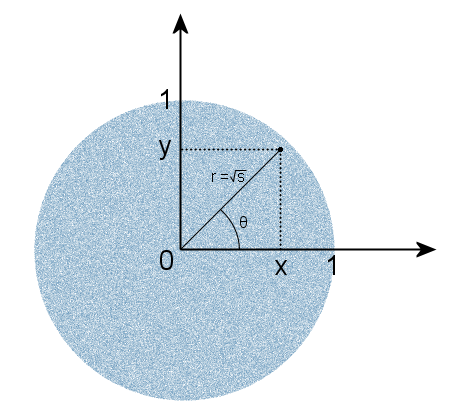
Выбор осуществляется заданием случайных прямоугольных координат x и y, равномерно распределенных в интервале (-1, 1), и отбрасыванием точек, которые не принадлежат кругу, а также центральной точки, в которой угол радиус-вектора не определен. То есть должно выполниться условие 0 < s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно — количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт — s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций — их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:

Получаем формулы, как в начале статьи. Недостаток этого метода — отбрасывание точек, не вошедших в круг. То есть использование только 78,5% сгенерированных случайных величин. На старых компьютерах отсутствие тригонометрических функций всё равно давало большое преимущество. Сейчас, когда одна команда процессора за мгновение вычисляет одновременно синус и косинус, думаю, эти методы могут еще посоревноваться.
Лично у меня остается еще два вопроса:
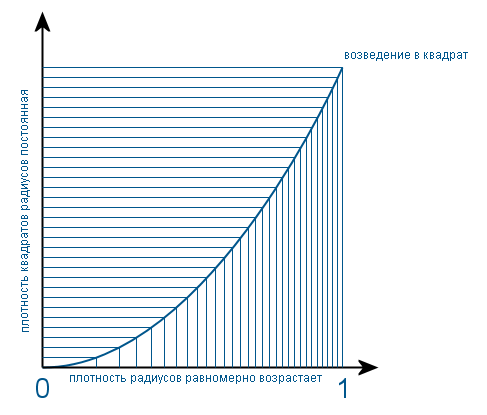
Так как s — это квадрат радиуса (для простоты радиусом я называю длину радиус-вектора, задающего положение случайной точки), то сначала выясним, как распределены радиусы. Так как круг заполнен равномерно, очевидно, что количество точек с радиусом r пропорционально длине окружности радиуса r. А длина окружности пропорциональна радиусу. Значит плотность распределения радиусов возрастает равномерно от центра окружности к её краям. А функция плотности имеет вид f(x) = 2x на интервале (0, 1). Коэффициент 2 для того, чтобы площадь фигуры под графиком равнялась единице. При возведении такой плотности в квадрат, она превращается в равномерную. Так как теоретически в данном случае для этого необходимо функцию плотности разделить на производную от функции преобразования (то есть от x2). А наглядно это происходит так:
Если аналогичное преобразование сделать для нормальной случайной величины, то функция плотности ее квадрата окажется похожей на гиперболу. А сложение двух квадратов нормальных случайных величин уже гораздо более сложный процесс, связанный с двойным интегрированием. И то, что в результате получится экспоненциальное распределение, лично мне тут остаётся проверить практическим методом или принять как аксиому. А кому интересно, предлагаю ознакомиться с темой поближе, почерпнув знаний из этих книжек:
В заключение приведу пример реализации генератора нормально распределенных случайных чисел на языке JavaScript:
Параметры mean (математическое ожидание) и dev (среднеквадратическое отклонение) не обязательны. Обращаю ваше внимание на то, что логарифм натуральный.
где Z0 и Z1 — искомые значения, s = u2 + v2, а u и v — равномерно распределенные на отрезке (-1, 1) случайные величины, подобранные таким образом, чтобы выполнялось условие 0 < s < 1.
Многие используют эти формулы, даже не задумываясь, а многие даже и не подозревают об их существовании, так как пользуются готовыми реализациями. Но есть люди, у которых возникают вопросы: «Откуда взялась эта формула? И почему получается сразу пара величин?». Далее я постараюсь дать наглядный ответ на эти вопросы.
Для начала напомню, что такое плотность вероятности, функция распределения случайной величины и обратная функция. Допустим, есть некая случайная величина, распределение которой задано функцией плотности f(x), имеющей следующий вид:
Это означает, что вероятность того, что значение данной случайной величины окажется в интервале (A, B), равняется площади затененной области. И как следствие, площадь всей закрашенной области должна равняться единице, так как в любом случае значение случайной величины попадет в область определения функции f.
Функция распределения случайной величины является интегралом от функции плотности. И в данном случае ее примерный вид будет такой:
Тут смысл в том, что значение случайной величины будет меньше чем A с вероятностью B. И как следствие, функция никогда не убывает, а ее значения лежат в отрезке [0, 1].
Обратная функция — это функция, которая возвращает аргумент исходной функции, если в нее передать значение исходной функции. Например, для функции x2 обратной будет функция извлечения корня, для sin(x) это arcsin(x) и т.д.
Так как большинство генераторов псевдослучайных чисел на выходе дают только равномерное распределение, то часто возникает необходимость его преобразования в какое-либо другое. В данном случае в нормальное Гауссовское:
Основу всех методов преобразования равномерного распределения в любое другое составляет метод обратного преобразования. Работает он следующим образом. Находится функция, обратная функции необходимого распределения, и в качестве аргумента передается в нее равномерно распределенная на отрезке (0, 1) случайная величина. На выходе получаем величину с требуемым распределением. Для наглядности привожу следующую картинку.
Таким образом, равномерный отрезок как бы размазывается в соответствии с новым распределением, проецируясь на другую ось через обратную функцию. Но проблема в том, что интеграл от плотности Гауссовского распределения вычисляется непросто, поэтому вышеперечисленным ученым пришлось схитрить.
Существует распределение хи-квадрат (распределение Пирсона), которое представляет собой распределение суммы квадратов k независимых нормальных случайных величин. И в случае, когда k = 2, это распределение является экспоненциальным.
Это означает, что если у точки в прямоугольной системе координат будут случайные координаты X и Y, распределенные нормально, то после перевода этих координат в полярную систему (r, θ) квадрат радиуса (расстояния от начала координат до точки) будет распределен по экспоненциальному закону, так как квадрат радиуса — это сумма квадратов координат (по закону Пифагора). Плотность распределения таких точек на плоскости будет выглядеть следующим образом:
Так как она равноценна во всех направлениях, угол θ будет иметь равномерное распределение в диапазоне от 0 до 2π. Справедливо и обратное: если задать точку в полярной системе координат с помощью двух независимых случайных величин (угла, распределенного равномерно, и радиуса, распределенного экспоненциально), то прямоугольные координаты этой точки будут являться независимыми нормальными случайными величинами. А экспоненциальное распределение из равномерного получить уже гораздо проще, с помощью того же метода обратного преобразования. В этом и заключается суть полярного метода Бокса-Мюллера.
Теперь выведем формулы.
(1)Для получения r и θ нужно сгенерировать две равномерно распределенные на отрезке (0, 1) случайные величины (назовем их u и v), распределение одной из которых (допустим v) необходимо преобразовать в экспоненциальное для получения радиуса. Функция экспоненциального распределения выглядит следующим образом:
Обратная к ней функция:
Так как равномерное распределение симметрично, то аналогично преобразование будет работать и с функцией
Из формулы распределения хи-квадрат следует, что λ = 0,5. Подставим в эту функцию λ, v и получим квадрат радиуса, а затем и сам радиус:
Угол получим, растянув единичный отрезок до 2π:
Теперь подставим r и θ в формулы (1) и получим:
(2)Эти формулы уже готовы к использованию. X и Y будут независимы и распределены нормально с дисперсией 1 и математическим ожиданием 0. Чтобы получить распределение с другими характеристиками достаточно умножить результат функции на среднеквадратическое отклонение и прибавить математическое ожидание.
Но есть возможность избавиться от тригонометрических функций, задав угол не прямо, а косвенно через прямоугольные координаты случайной точки в круге. Тогда через эти координаты можно будет вычислить длину радиус-вектора, а потом найти косинус и синус, поделив на нее x и y соответственно. Как и почему это работает?
Выберем случайную точку из равномерно распределенных в круге единичного радиуса и обозначим квадрат длины радиус-вектора этой точки буквой s:
Выбор осуществляется заданием случайных прямоугольных координат x и y, равномерно распределенных в интервале (-1, 1), и отбрасыванием точек, которые не принадлежат кругу, а также центральной точки, в которой угол радиус-вектора не определен. То есть должно выполниться условие 0 < s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно — количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт — s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций — их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Получаем формулы, как в начале статьи. Недостаток этого метода — отбрасывание точек, не вошедших в круг. То есть использование только 78,5% сгенерированных случайных величин. На старых компьютерах отсутствие тригонометрических функций всё равно давало большое преимущество. Сейчас, когда одна команда процессора за мгновение вычисляет одновременно синус и косинус, думаю, эти методы могут еще посоревноваться.
Лично у меня остается еще два вопроса:
- Почему значение s распределено равномерно?
- Почему сумма квадратов двух нормальных случайных величин распределена экспоненциально?
Так как s — это квадрат радиуса (для простоты радиусом я называю длину радиус-вектора, задающего положение случайной точки), то сначала выясним, как распределены радиусы. Так как круг заполнен равномерно, очевидно, что количество точек с радиусом r пропорционально длине окружности радиуса r. А длина окружности пропорциональна радиусу. Значит плотность распределения радиусов возрастает равномерно от центра окружности к её краям. А функция плотности имеет вид f(x) = 2x на интервале (0, 1). Коэффициент 2 для того, чтобы площадь фигуры под графиком равнялась единице. При возведении такой плотности в квадрат, она превращается в равномерную. Так как теоретически в данном случае для этого необходимо функцию плотности разделить на производную от функции преобразования (то есть от x2). А наглядно это происходит так:
Если аналогичное преобразование сделать для нормальной случайной величины, то функция плотности ее квадрата окажется похожей на гиперболу. А сложение двух квадратов нормальных случайных величин уже гораздо более сложный процесс, связанный с двойным интегрированием. И то, что в результате получится экспоненциальное распределение, лично мне тут остаётся проверить практическим методом или принять как аксиому. А кому интересно, предлагаю ознакомиться с темой поближе, почерпнув знаний из этих книжек:
- Вентцель Е.С. Теория вероятностей
- Кнут Д.Э. Искусство Программирования, том 2
В заключение приведу пример реализации генератора нормально распределенных случайных чисел на языке JavaScript:
function Gauss() { var ready = false; var second = 0.0; this.next = function(mean, dev) { mean = mean == undefined ? 0.0 : mean; dev = dev == undefined ? 1.0 : dev; if (this.ready) { this.ready = false; return this.second * dev + mean; } else { var u, v, s; do { u = 2.0 * Math.random() - 1.0; v = 2.0 * Math.random() - 1.0; s = u * u + v * v; } while (s > 1.0 || s == 0.0); var r = Math.sqrt(-2.0 * Math.log(s) / s); this.second = r * u; this.ready = true; return r * v * dev + mean; } }; } g = new Gauss(); // создаём объект a = g.next(); // генерируем пару значений и получаем первое из них b = g.next(); // получаем второе c = g.next(); // снова генерируем пару значений и получаем первое из них
Параметры mean (математическое ожидание) и dev (среднеквадратическое отклонение) не обязательны. Обращаю ваше внимание на то, что логарифм натуральный.

