
Вступление
Так сложилось, что я живу в коттеджном поселке, где нет центрального отопления, а значит, каждый греет свою квартиру самостоятельно. Чаще всего для этих целей используются газовые котлы, метод достаточно дешевый, жаловаться не на что, но есть одна тонкость. Для корректной работы газового котла (внезапно) необходимо наличие газа в трубе.
Возможно, так ведут себя не все котлы, но наш отключается даже при кратковременном перебое с подачей газа и не включается обратно, если подача восстановится. Если кто-то есть дома, то это не проблема, нажал кнопку и котел греет дальше, но если вдруг так сложилось, что мы решили всей семьей поехать в отпуск, а на дворе зима, хорошая такая, чтоб -20°C, то последствия могут быть плачевными.
Решение простое — оставить ключи родственникам/друзьям/соседям, чтобы они могли приехать и включить котел, случись какая-нибудь неприятность. Хорошо, если есть сосед, который будет каждый день заходить и проверять, всё ли в порядке. А если нет? Или он тоже решит уехать куда-нибудь на выходные?
Итак, я решил наладить выкладывание показаний счётчика куда-нибудь в Интернет, чтоб я мог находясь где-нибудь в дальней поездке периодически проверять, тратится ли газ, а если вдруг перестанет тратиться, то срочно звонить родственникам/друзьям/соседям (или кому там я оставил ключи), чтобы приехали и нажали кнопку.
Конечно, после простого выкладывания показаний в Интернет я решил не останавливаться на достигнутом и замутил ещё распознавание показаний и графическое представление, об этом читайте в части 2 данного топика.
Часть 1. Снятие показаний со счетчика и выкладывание их в Интернет
Здесь надо оговориться, что счётчики бывают в природе совершенно разные, некоторые из них имеют специальные шины и интерфейсы для автоматизированного съема показаний. Если у Вас такой, то дальше, наверное, можно не читать. Но у меня самый обычный без подобных интерфейсов (по крайней мере, я не нашёл, может, плохо искал), модель GALLUS iV PSC. Поэтому остается один вариант — визуальный съём показаний. В сети предлагают готовые решения, но они стоят немалых денег, а главное, это совсем не спортивно, поэтому будем делать всё сами.
Что нам понадобиться?
Для снятия показаний со счетчика с последующей отправкой этих показаний в интернет нам понадобится любой ненужный android смартфон. Я, например, использовал для этих целей Samsung Galaxy S III (SCH-I535). Да, наверное, не у каждого читателя есть валяющийся без дела с-третий галакси, но нужно понимать, что требования к смартфону не так уж и велики:
- он должен загружаться
- должна работать камера
- должен работать WiFi
Вот, собственно и все, наличие работающего экрана, тач-скрина, микрофона, динамика и т.п. совершенно не требуется. Данный факт значительно снижает стоимость.
Имея хобби покупать на ebay разные битые телефоны и собирать из них работающие, я легко нашел у себя в загашнике материнскую плату от sgs3 с неработающим микрофоном (~$10), а также б/у-шную камеру (~$10) и китайскую батарейку (~300р). Также для удобства крепления батарейки к плате использовал фрейм с битым дисплеем.

Сначала думал обойтись только материнской платой и камерой, но оказалось, что даже при подключении к зарядке плата не включается без батарейки, поэтому пришлось ещё добавить фрейм и батарейку. Но и в этом случае бюджет получился порядка $30, если использовать аппараты попроще sgs3, то можно уложиться и в меньшую сумму.
Правда, у такого решения есть и свои минусы, смартфон без дисплея и тачскрина не так удобно настраивать, поэтому немного расскажу о том, как пришлось решать эту проблему.
Настройка аппарата
Будем исходить из наихудшего сценария. Предположим, что нет ни дисплея, ни тачскрина, на смартфоне отсутствует root, adb отладка отключена, прошивка неизвестна.
Реанимация
Внимание! Дальнейшая инструкция подходит для аппарата Samsung Galaxy S III (SCH-I535), если у Вас другой смартфон, то действия могут отличаться.
Предполагается, что Вы хорошо знакомы с такими понятиями как adb, прошивки и пр.
Чтобы привести смартфон в более-менее известное нам состояние для начала прошьем стоковую прошивку VRBMB1 отсюда используя Odin. Не буду подробно описывать, как это делается, в Интернете полно инструкций, как пользоваться Odin-ом. Odin в нашем случае хорош тем, что с ним легко работать не используя экран смартфона, нужно только включить смартфон в режиме загрузки (Vol Down+Home+Power — подержать несколько секунд, затем Vol Up, подключить по usb к винде и всё, дальше дело Odin-а).
После того, как Odin прошьет сток, телефон загрузит систему, отключаем его от usb и вынимаем батарейку, чтобы он выключился. Эту операцию нужно делать каждый раз после завершения прошивки Odin-ом, чтобы начинать следующую операцию с выключенного состояния.
Далее шьем CWM recovery и root по инструкции. Если вкратце, то так:
- Через Odin прошиваем кастомный бутчейн VRALEC.bootchain.tar.md5
- Через Odin прошиваем CWM recovery
- Через CWM recovery прошиваем SuperSU_Bootloader_FIXED.zip. В инструкции написано, что zip нужно закинуть на sd-карту, но ввиду отсутствия экрана проще это сделать через sideload:
Включаем тело зажав Vol Up+Home+Power — держим несколько секунд, потом еще секунд 5 загрузка, попадаем в режим CWM-recovery.
Проверяем это, набрав в консоли в ubuntuadb devices(тело, само собой должно быть подключено по usb и должен быть установлен adb —sudo apt-get install android-tools-adb):
malefic@lepeshka:~$ adb devices List of devices attached 64cb5c59 recovery
Если видим последнюю строчку, значит все в порядке, жмем на девайсе Vol Down, Vol Down, Power — переходим в режим adb sideload (по крайней мере в версии CWM из инструкции это вторая строчка сверху), остается только набрать в консоли ubuntu:
malefic@lepeshka:~$ adb sideload SuperSU_Bootloader_FIXED.zip sending: 'sideload' 100%
и root улетает на девайс, после чего не забываем выключать девайс, вытащив из него батарейку. - Через Odin прошиваем стоковый бутчейн, соответствующий поставленной до этого стоковой прошивке VRBMB1_Bootchain.tar.md5
Далее нам нужно включить usb-отладку на смартфоне, для этого запускаем смартфон в режим CWM-recovery, проверяем:
malefic@lepeshka:~$ adb devices List of devices attached 64cb5c59 recovery
Монтируем system:
malefic@lepeshka:~$ adb shell mount -o rw -t ext4 /dev/block/platform/msm_sdcc.1/by-name/system /system
Добавляем строчку в /system/build.prop:
malefic@lepeshka:~$ adb shell "echo \"persist.service.adb.enable=1\" >> /system/build.prop"
Перезагружаем:
malefic@lepeshka:~$ adb reboot
Ждем загрузки, проверяем в терминале статус adb:
malefic@lepeshka:~$ adb devices List of devices attached 64cb5c59 device
Бинго! Отладка включена, давайте посмотрим, что там у нас творится на смартфоне, для этого запускаем AndroidScreenCast с помощью Java Web Start и видим:
Это экран активации симкарты Verizon, у меня такой симки нет, поэтому я просто пропускаю активацию, действуя по инструкции:
на экране выбора языка последовательно касаемся на экране левый нижний угол (над кнопкой экстренный вызов), правый нижний угол, левый нижний, правый нижний и громкость+
А именно:
malefic@lepeshka:~$ adb shell input tap 10 1150 malefic@lepeshka:~$ adb shell input tap 710 1150 malefic@lepeshka:~$ adb shell input tap 10 1150 malefic@lepeshka:~$ adb shell input tap 710 1150
затем нажимаю на смартфоне кнопку Vol Up, теперь видим:
Ставим галочку и нажимаем ОК:
malefic@lepeshka:~$ adb shell input tap 50 600 malefic@lepeshka:~$ adb shell input tap 650 600
Свайпаем, чтобы разлочить экран:
malefic@lepeshka:~$ adb shell input swipe 100 100 500 100
Теперь нужно поставить какой-нибудь vnc-сервер для Android, например, Android VNC Server. Устанавливаем его на смартфон:
malefic@lepeshka:~$ adb install droid+VNC+server+v1.1RC0.apk 4055 KB/s (2084419 bytes in 0.501s) pkg: /data/local/tmp/droid+VNC+server+v1.1RC0.apk Success
Будим смартфон, так как он скорее всего уснул, пока мы устанавливали vnc-сервер, и свайпаем, чтоб разлочить экран:
malefic@lepeshka:~$ adb shell input keyevent 26 malefic@lepeshka:~$ adb shell input swipe 100 100 500 100
Запускаем vnc-сервер:
malefic@lepeshka:~$ adb shell am start -a android.intent.action.Main -n org.onaips.vnc/.MainActivity
Жмем ОК:
malefic@lepeshka:~$ adb shell input tap 50 900

Жмем Start:
malefic@lepeshka:~$ adb shell input tap 350 300
Жмем предоставить доступ:
malefic@lepeshka:~$ adb shell input tap 600 1000

Отлично, теперь пробрасываем порты через adb:
malefic@lepeshka:~$ adb forward tcp:5801 tcp:5801 malefic@lepeshka:~$ adb forward tcp:5901 tcp:5901
и заходим на смартфон через браузер или любимый vnc клиент.
Далее работаем как с обычным Android телефоном, только через компьютер, удобно сразу настроить WiFi подключение, тогда можно будет заходить по vnc через WiFi, а не держать телефон всё время подключенным к компьютеру (ведь газовый счётчик не всегда расположен в непосредственной близости от компьютера).
Теперь, когда взаимодействие с девайсом полностью налажено, можно перейти к настройке фотосъемки и публикации данных в Интернет.
Периодическая фотосъемка
Устанавливаем приложение Tasker, создаем в нем временной профиль с 00:00 до 23:59 каждые 30 минут выполнять действие — делать фото. Параметры съемки подбираем наиболее подходящие для расположения телефона и счётчика. У меня это макросъемка с обязательной вспышкой.
Вот так, собственно, я расположил свой телефон (вид сверху):

Картонная коробка, привязанная к счетчику веревочкой, в ней живет смартфон, упаковка от яиц там для фиксации смартфона в вертикальном положении. Затем я ещё доработал конструкцию с помощью скотча и картона, чтобы вспышка не била напрямую в циферблат, это дает серьезные блики, мешающие распознаванию. Сверху закрыл все крышкой, чтобы внутри было темно, иначе при ярком внешнем освещении не всегда правильно срабатывает автофокус.
В настройках смартфона в средствах разработчика обязательно надо поставить галочку, чтоб смартфон не засыпал при подключенной зарядке, а то в какой-то момент он перестает фотографировать и продолжает только если его потревожить.
Выкладываем в Интернет
Для перемещения отснятых изображений счётчика в Интернет я использовал первое попавшееся приложение — FolderSync Lite. Оно умеет синхронизировать папку на смартфоне с папкой, например, на Google диске.
Таким образом, я теперь могу из любой точки мира, где есть Интернет, зайти в свой Google диск и проверить, что газовый котёл работает в штатном режиме.
Часть 2. Распознавание показаний
Итак, после отправки показаний счётчика в Интернет, меня заинтересовала возможность автоматического распознавания показаний. Это позволит:
- проводить статистический анализ потребления газа
- автоматически отслеживать перебои с подачей газа (с возможностью предупреждения по e-mail или sms)
В качестве языка разработки был выбран python, для работы с изображениями использовалась библиотека OpenCV.
Вот код основной программы, которая запускается по крону раз в час:
import sys import os from models import getImage, sess from gdrive import getImagesFromGDrive, createImageFromGDriveObject if __name__ == '__main__': # получаем список новых фото с гугл диска images, http = getImagesFromGDrive() # поочередно обрабатываем их в цикле for img_info in images: # скачиваем изображение img = createImageFromGDriveObject (img_info, http) file_name = img_info['title'] # ищем запись в базе try: dbimage = getImage(os.path.basename(file_name)) dbimage.img = img dbimage.download_url = img_info["downloadUrl"] dbimage.img_link = img_info['webContentLink'].replace('&export=download','') except ValueError as e: print e continue # распознаем показания dbimage.identifyDigits() # сохраняем данные в базу sess.commit()
Здесь используются функции, код которых я выложу ниже:
getImagesFromGDrive— функция, возвращающая список ещё не распознанных изображений с Google ДискаcreateImageFromGDriveObject— функция, скачивающая само изображение и преобразующая его в формат OpenCVgetImage— функция ищет запись об изображении в базе данных, если таковой нет, то создает еёidentifyDigits— метод, распознающий показания на данном изображенииhttp— авторизованный клиент для доступа к Google Диску, подробно про доступ к API Диска читаем здесьsess— объект подключения к базе данных, используется библиотека SQL Alchemy
Работа с Google Диском
Первое, что мы делаем, это получаем с Google Диска список изображений:
import os from datetime import tzinfo, timedelta, date from dateutil.relativedelta import relativedelta from apiclient.discovery import build from models import getLastRecognizedImage def getImagesFromGDrive(): # определяем id папки Google Диска, в которой лежат изображения FOLDER_ID = '0B5mI3ROgk0mJcHJKTm95Ri1mbVU' # создаем объект авторизованного клиента http = getAuthorizedHttp() # объект сервиса Диска drive_service = build('drive', 'v2', http=http) # для начала удаляем с Диска все изображения старше месяца, они нам уже не интересны month_ago = date.today() + relativedelta( months = -1 ) q = "'%s' in parents and mimeType = 'image/jpeg' and trashed = false and modifiedDate<'%s'" % (FOLDER_ID, month_ago.isoformat()) files = drive_service.files().list(q = q, maxResults=1000).execute() for image in files.get('items'): drive_service.files().trash(fileId=image['id']).execute() # теперь делаем запрос к базе, возвращающий последнее распознанное изображение last_image = getLastRecognizedImage() # получаем с Диска список изображений, дата изменения которых больше даты съемки последнего распознанного изображения page_size = 1000 result = [] pt = None # так как API Диска не позволяет за раз получить более 1000 изображений, # то скачиваем список постранично по 1000 штук и складываем в один массив while True: q = "'%s' in parents and trashed = false and mimeType = 'image/jpeg' and modifiedDate>'%s'" % (FOLDER_ID, last_image.check_time.replace(tzinfo=TZ()).isoformat('T')) files = drive_service.files().list(q = q, maxResults=page_size, pageToken=pt).execute() result.extend(files.get('items')) pt = files.get('nextPageToken') if not pt: break # переворачиваем список, чтобы обработка шла в порядке времени съемки result.reverse() return result, http
Авторизованный клиент Диска создается следующим образом:
import httplib2 import ConfigParser from oauth2client.client import OAuth2WebServerFlow from oauth2client.file import Storage def getAuthorizedHttp(): # достаем из файла config.ini записанные там CLIENT_ID и CLIENT_SECRET config = ConfigParser.ConfigParser() config.read([os.path.dirname(__file__)+'/config.ini']) CLIENT_ID = config.get('gdrive','CLIENT_ID') CLIENT_SECRET = config.get('gdrive','CLIENT_SECRET') # OAuth 2.0 scope that will be authorized. # Check https://developers.google.com/drive/scopes for all available scopes. OAUTH_SCOPE = 'https://www.googleapis.com/auth/drive' # Redirect URI for installed apps REDIRECT_URI = 'urn:ietf:wg:oauth:2.0:oob' # в файле client_secrets.json будем хранить токен storage = Storage(os.path.dirname(__file__) + '/client_secrets.json') credentials = storage.get() # если в файле ничего нет, то запускаем процедуру авторизации if not credentials: # Perform OAuth2.0 authorization flow. flow = OAuth2WebServerFlow(CLIENT_ID, CLIENT_SECRET, OAUTH_SCOPE, REDIRECT_URI) authorize_url = flow.step1_get_authorize_url() # выводим в консоль ссылку, по которой надо перейти для авторизации print 'Go to the following link in your browser: ' + authorize_url # запрашиваем ответ code = raw_input('Enter verification code: ').strip() credentials = flow.step2_exchange(code) # сохраняем токен storage.put(credentials) # создаем http клиент и авторизуем его http = httplib2.Http() credentials.authorize(http) return http
Для получения CLIENT_ID и CLIENT_SECRET в Google Developers Console нужно создать проект и для этого проекта в разделе APIs & auth — Credentials — OAuth нажать CREATE NEW CLIENT ID, там выбрать Installed application — Other:

При первом запуске скрипт напишет в консоли url по которому нужно перейти, чтобы получить токен, вставляем его в адресную строку браузера, разрешаем доступ приложения к Google Диску, копируем выданный гуглом верификационный код из браузера и отдаем скрипту. После этого скрипт сохранит все необходимое в файл
client_secrets.json и при последующих запусках не будет ничего спрашивать.Функция скачивания изображения предельно проста:
import cv2 import numpy as np def downloadImageFromGDrive (downloadUrl, http=None): if http==None: http = getAuthorizedHttp() # Скачиваем изображение resp, content = http.request(downloadUrl) # Создаем объект изображения OpenCV img_array = np.asarray(bytearray(content), dtype=np.uint8) return cv2.imdecode(img_array, cv2.IMREAD_COLOR) def createImageFromGDriveObject (img_info, http=None): return downloadImageFromGDrive(img_info['downloadUrl'], http)
Поиск показаний на фото
Первое, что необходимо сделать, после того, как мы получили фото, это найти на нём цифры, которые мы будем распознавать. Этим занимается метод
extractDigitsFromImage:def extractDigitsFromImage (self): img = self.img
Изначально фото выглядит вот так:

Поэтому сначала мы его поворачиваем, чтобы оно приобрело нужную ориентацию.
# вращаем на 90 градусов h, w, k = img.shape M = cv2.getRotationMatrix2D((w/2,h/2),270,1) img = cv2.warpAffine(img,M,(w,h))

# обрезаем черные поля, появившиеся после вращения img = img[0:h, (w-h)/2:h+(w-h)/2] h, w, k = img.shape
Теперь рассмотрим кусочек изображения, обведённый красной рамкой. Он достаточно уникален в пределах всего фото, можно использовать его для поиска циферблата. Я положил его в файл
sample.jpg и написал следующий код для нахождения его координат:# загружаем искомый кусочек фото из файла sample = cv2.imread(os.path.dirname(__file__)+"/sample.jpg") sample_h, sample_w, sample_k = sample.shape # ищем наилучшее совпадение его с фото res = cv2.matchTemplate(img,sample,cv2.TM_CCORR_NORMED) min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # вычисляем координаты центра наилучшего совпадения x_center = max_loc[0] + sample_w/2 y_center = max_loc[1] + sample_h/2 # этот небольшой кусок кода обрезает левую часть фото, если найденная точка оказалось слишком справа, # чтобы циферблат оказался примерно по середине фото if x_center>w*0.6: img = img[0:h, 0.2*w:w] h, w, k = img.shape x_center = x_center-0.2*w

Точкой на рисунке обозначены найденные координаты, то, что мы и хотели. Далее запускаем алгоритм поиска границ, предварительно переведя изображение в серые тона. 100 и 200 — значения пороговых значений, подобранные эмпирически.
# переводим изображение в градации серого gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) # ищем границы алгоритмом Canny edges = cv2.Canny(gray, 100, 200)
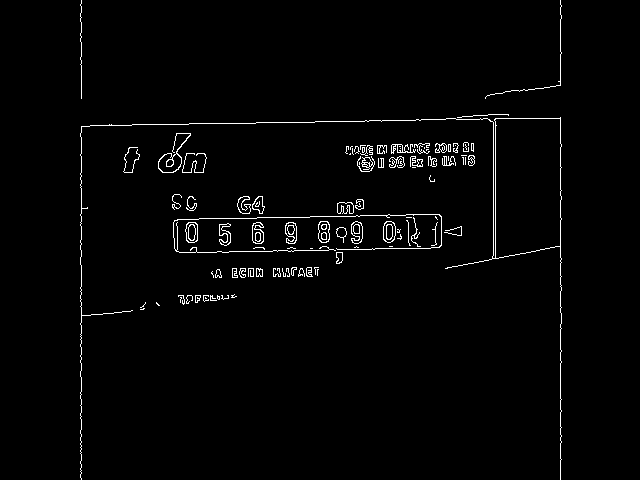
Теперь запускаем алгоритм поиска линий на полученном изображении с границами. Кроме самого изображения метод
HoughLines также принимает в качестве параметров величины шагов поиска по расстоянию и углу поворота и пороговое значение отвечающее за минимальное кол-во точек, которые должны образовать линию. Чем меньше этот порог, тем больше линий найдёт алгоритм.# находим прямые линии lines = cv2.HoughLines(edges, 1, np.pi/180, threshold=100)

Из всех найденных линий рассматриваем только более-менее горизонтальные и находим две наиболее приближенные к обнаруженному ранее центру (одну сверху, другую снизу).
# инициализируем необходимые переменные rho_below = rho_above = np.sqrt(h*h+w*w) line_above = None line_below = None for line in lines: rho,theta = line[0] sin = np.sin(theta) cos = np.cos(theta) # выбрасываем не горизонтальные линии if (sin<0.7): continue # вычисляем ро для линии параллельной текущей линии, но проходящей через "центральную" точку rho_center = x_center*cos + y_center*sin # сравниваем с ближайшей линией сверху if rho_center>rho and rho_center-rho<rho_above: rho_above = rho_center-rho line_above = {"rho":rho, "theta":theta, "sin":sin, "cos":cos} # сравниваем с ближайшей линией снизу if rho_center<rho and rho-rho_center<rho_below: rho_below = rho-rho_center line_below = {"rho":rho, "theta":theta, "sin":sin, "cos":cos} # проверяем, обе ли линии успешно найдены if line_below==None or line_above==None: mylogger.warn("No lines found") return False # проверяем, что найденные линии находятся не очень далеко друг от друга if rho_below/rho_above>1.7 or rho_below/rho_above<0.6: mylogger.warn("Wrong lines found: %f" % (rho_below/rho_above)) return False

Поворчиваем изображение так, чтобы найденные линии стали совсем горизонтальными:
# поворачиваем M = cv2.getRotationMatrix2D((0,(line_below["rho"]-line_above["rho"])/2+line_above["rho"]),line_above["theta"]/np.pi*180-90,1) img = cv2.warpAffine(img,M,(w,h))

Теперь обрежем все, что находится за найденными линиями:
# обрезаем img = img[line_above["rho"]:line_below["rho"], 0:w] h, w, k = img.shape

Далее нам нужно найти левый и правый край циферблата, переводим изображение в черно-белое:
# бинаризируем изображение gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) thres = cv2.adaptiveThreshold(gray,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 31, 2)

Правый край ищем по той же технологии, что и «центральную» точку, шаблон обведён красной рамкой:
sample_right = cv2.imread(os.path.dirname(__file__)+"/sample_right.jpg",cv2.IMREAD_GRAYSCALE) # определяем наилучшее совпадение с шаблоном res = cv2.matchTemplate(thres,sample_right,cv2.TM_CCORR_NORMED) min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # вычисляем правую границу x_right = max_loc[0]-6
Для поиска левой границы применим преобразование закрытия для удаления шума:
# удаляем шум kernel = np.ones((7,7),np.uint8) thres = cv2.morphologyEx(thres, cv2.MORPH_CLOSE, kernel)

Далее будем перебирать все пиксели начиная с самого левого, пока не встретиться черный, это и будет левый край:
# ищем левый край x_left=0 while x_left<w : if thres[h/2,x_left]==0: break x_left+=1

Обрежем изображение по левому и правому краю:
# обрезаем слева и справа img = img[:, x_left:x_right] h, w, k = img.shape
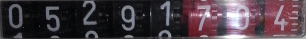
Проведём небольшую проверку, что найденное изображение по соотношению сторон соответствует циферблату:
# проверяем соотношение сторон if float(w)/float(h)<6.5 or float(w)/float(h)>9.5: mylogger.warn("Image has bad ratio: %f" % (float(w)/float(h))) return False self.digits_img = img return True
Разбиение на цифры
Разбиением выделенного предыдущей функцией циферблата на отдельные цифры занимается метод
splitDigits:def splitDigits (self): # проверяем, если циферблат ещё не выделен, то делаем это if None == self.digits_img: if not self.extractDigitsFromImage(): return False img = self.digits_img h, w, k = img.shape
Для начала просто разрежем наш циферблат на 8 равных частей:

Обрабатывать будем только первые 7 частей, так как 8-я цифра постоянно крутится, её бесполезно распознавать.
Каждую часть переводим в ч/б цвет используя метод
adaptiveThreshold, параметры подобраны эмпирически:# разбиваем циферблат на 8 равных частей и обрабатываем каждую часть for i in range(1,8): digit = img[0:h, (i-1)*w/8:i*w/8] dh, dw, dk = digit.shape # переводим в ч/б digit_gray = cv2.cvtColor(digit,cv2.COLOR_BGR2GRAY) digit_bin = cv2.adaptiveThreshold(digit_gray,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 9, 0)

Немного удаляем шум с помощью преобразования открытия (используется ядро всего 2х2). Без этого можно было бы и обойтись, но иногда это помогает отрезать от цифры большие белые куски подсоединённые тонкими перемычками:
# удаляем шум kernel = np.ones((2,2),np.uint8) digit_bin = cv2.morphologyEx(digit_bin, cv2.MORPH_OPEN, kernel)

Запускаем алгоритм поиска контуров
# ищем контуры other, contours, hierarhy = cv2.findContours(digit_bin.copy(),cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)

Далее выбросим все слишком маленькие контуры и контуры по краям изображения, потом найдём самый большой контур из оставшихся:
# анализируем контуры biggest_contour = None biggest_contour_area = 0 for cnt in contours: M = cv2.moments(cnt) # пропускаем контуры со слишком маленькой площадью if cv2.contourArea(cnt)<30: continue # пропускаем контуры со слишком маленьким периметром if cv2.arcLength(cnt,True)<30: continue # находим центр масс контура cx = M['m10']/M['m00'] cy = M['m01']/M['m00'] # пропускаем контур, если центр масс находится где-то с краю if cx/dw<0.3 or cx/dw>0.7: continue # находим наибольший контур if cv2.contourArea(cnt)>biggest_contour_area: biggest_contour = cnt biggest_contour_area = cv2.contourArea(cnt) biggest_contour_cx = cx biggest_contour_cy = cy # если не найдено ни одного подходящего контура, то помечаем цифру не распознанной if biggest_contour==None: digit = self.dbDigit(i, digit_bin) digit.markDigitForManualRecognize (use_for_training=False) mylogger.warn("Digit %d: no biggest contour found" % i) continue

Самый большой контур это и есть наша цифра, выбросим всё, что лежит за его пределами с помощью наложения маски:
# убираем всё, что лежит за пределами самого большого контура mask = np.zeros(digit_bin.shape,np.uint8) cv2.drawContours(mask,[biggest_contour],0,255,-1) digit_bin = cv2.bitwise_and(digit_bin,digit_bin,mask = mask)

Теперь опишем вокруг каждой цифры прямоугольник стандартного размера с центром в центре масс контура:
# задаем параметры описывающего прямоугольника rw = dw/2.0 rh = dh/1.4 # проверяем, чтобы прямоугольник не выходил за пределы изображения if biggest_contour_cy-rh/2 < 0: biggest_contour_cy = rh/2 if biggest_contour_cx-rw/2 < 0: biggest_contour_cx = rw/2

Обрезаем изображение по прямоугольнику и масштабируем до заданного размера, у меня это
digit_base_h = 24, digit_base_w = 16. Результат сохраняем в базу.# вырезаем прямоугольник digit_bin = digit_bin[int(biggest_contour_cy-rh/2):int(biggest_contour_cy+rh/2), int(biggest_contour_cx-rw/2):int(biggest_contour_cx+rw/2)] # изменяем размер на стандартный digit_bin = cv2.resize(digit_bin,(digit_base_w, digit_base_h)) digit_bin = cv2.threshold(digit_bin, 128, 255, cv2.THRESH_BINARY)[1] # сохраняем в базу digit = self.dbDigit(i, digit_bin) return True

Распознавание цифр
Вот метод
identifyDigits, который вызывается из основной программы для каждого изображения:def identifyDigits(self): # если число уже распознано, то ничего не делаем if self.result!='': return True # если цифры ещё не выделены if len(self.digits)==0: # если изображение не задано, то ничего не получится if self.img == None: return False # выделяем цифры if not self.splitDigits(): return False # утверждаем изменения в базу, которые сделаны при выделении цифр sess.commit() # пытаемся распознать каждую цифру for digit in self.digits: digit.identifyDigit() # получаем текстовые значения цифр str_digits = map(str,self.digits) # если хотя бы одна цифра не распознана, то показание также не может быть распознано if '?' in str_digits: return False # склеиваем все цифры для получения числа self.result = ''.join(str_digits) return True
Тут все тривиально, кроме метода
identifyDigit:def identifyDigit (self): # если цифра уже распознана, то ничего не делаем if self.result!='?': return True if not KNN.recognize(self): # если не удалось распознать цифру, то помечаем её для ручной обработки self.markDigitForManualRecognize() # если это 7-я цифра, то считаем её равной "0", так как это последняя цифра и не критичная, а часто бывает, что она не распознается if self.i==7: self.result = 0 return True return False else: self.use_for_training = True return True
Метод
identifyDigit тоже тривиален, распознавание происходит в методе KNN.recognize, используется алгоритм поиска ближайших соседей из OpenCV:@staticmethod def recognize(dbdigit): # тренируем, если ещё не тренирован if not KNN._trained: KNN.train() # проверяем размер изображения, если не правильный, то не пытаемся распознать h,w = dbdigit.body.shape if h!=digit_base_h or w!=digit_base_w: dbdigit.markDigitForManualRecognize(use_for_training=False) mylogger.warn("Digit %d has bad resolution: %d x %d" % (dbdigit.i,h,w)) return False # преобразуем двумерное бинарное изображение в одномерный массив sample = dbdigit.body.reshape(digit_base_h*digit_base_w).astype(np.float32) test_data = np.array([sample]) # запускаем метод определения ближайших соседей, кол-во соседей - 5 knn = KNN.getKNN() ret,result,neighbours,dist = knn.find_nearest(test_data,k=5) # фильтруем вероятно неверные результаты if result[0,0]!=neighbours[0,0]: # результат не равен наиболее похожей цифре dbdigit.markDigitForManualRecognize() return False if neighbours[0,1]!=neighbours[0,0] or neighbours[0,2]!=neighbours[0,0]: # три наиболее похожих цифры не равны между собой dbdigit.markDigitForManualRecognize() return False if dist[0,0]>3000000 or dist[0,1]>3500000 or dist[0,2]>4000000: # расхождения с тремя наиболее похожими цифрами слишком большие dbdigit.markDigitForManualRecognize() return False # если всё в порядке, то считаем распознавание удачным и сохраняем результат dbdigit.result = str(int(ret)) return True
Тренировка описана в методе
KNN.train:@staticmethod def getKNN(): # метод обеспечивает единстенную инициализацию объекта cv2.KNearest if KNN._knn==None: KNN._knn = cv2.KNearest() return KNN._knn @staticmethod def train(): knn = KNN.getKNN() # достаем из базы распознанные цифры для тренировки train_digits = sess.query(Digit).filter(Digit.result!='?').filter_by(use_for_training=True).all() train_data = [] responses = [] for dbdigit in train_digits: h,w = dbdigit.body.shape # пропускаем цифры плохого размера if h*w != digit_base_h*digit_base_w: continue # преобразуем в одномерный массив sample = dbdigit.body.reshape(digit_base_h*digit_base_w).astype(np.float32) train_data.append(sample) responses.append(int(dbdigit.result)) # тренируем KNN knn.train(np.array(train_data), np.array(responses)) KNN._trained = True
Привожу выдержку из файла
models.py, если у читателя остались вопросы по работе некоторых использованных, но не описанных функций.Отсутствующие в статье описания функций и методов
import datetime from sqlalchemy import Column, Integer, String, Text, Boolean, ForeignKey, DateTime, PickleType from sqlalchemy.orm import relationship from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker import base64 import cv2 import numpy as np import os import logging import sys dbengine = create_engine('sqlite:///' + os.path.dirname(__file__) + '/../db/images.db', echo=False) Session = sessionmaker(bind=dbengine) sess = Session() Base = declarative_base() # image class class Image(Base): __tablename__ = 'images' id = Column(Integer, primary_key=True) file_name = Column(String) img_link = Column(Text) download_url = Column(Text) check_time = Column(DateTime) result = Column(String(8)) digits = relationship("Digit", backref="image") img = None # source image digits_img = None # cropped source image def __init__(self, file_name): self.file_name = file_name self.check_time = datetime.datetime.strptime(file_name, "gaz.%Y-%m-%d.%H.%M.%S.jpg") self.result = "" def __repr__(self): return "<Image ('%s','%s','%s')>" % (self.id, self.file_name, self.result) def dbDigit(self, i, digit_img): digit = sess.query(Digit).filter_by(image_id=self.id).filter_by(i=i).first() if not digit: digit = Digit(self, i, digit_img) sess.add(digit) else: digit.body = digit_img return digit ## некоторый код остутствует # digit class class Digit(Base): __tablename__ = 'digits' id = Column(Integer, primary_key=True) image_id = Column(Integer, ForeignKey("images.id")) i = Column(Integer) body = Column(PickleType) result = Column(String(1)) use_for_training = Column(Boolean) def __init__(self, image, i, digit_img): self.image_id = image.id self.i = i self.body = digit_img self.markDigitForManualRecognize() def __repr__(self): return "%s" % self.result def markDigitForManualRecognize (self, use_for_training=False): self.result = '?' self.use_for_training = use_for_training def getEncodedBody (self): enc = cv2.imencode('.png',self.body)[1] b64 = base64.b64encode(enc) return b64 ## некоторый код остутствует Base.metadata.create_all(bind=dbengine) # function to get Image object by file_name and img def getImage(file_name): image = sess.query(Image).filter_by(file_name=file_name).first() if not image: image = Image(file_name) sess.add(image) # store image object to base sess.commit() image.digits_img = None return image def getLastRecognizedImage(): return sess.query(Image).filter(Image.result!='').order_by(Image.check_time.desc()).first() def dgDigitById(digit_id): digit = sess.query(Digit).get(digit_id) return digit
Для анализа показаний и ручного распознавания я написал также небольшой web-интерфейс на фреймворке Flask. Приводить код я здесь не буду, кому интересно, тот может посмотреть его, а также весь остальной код на Github.
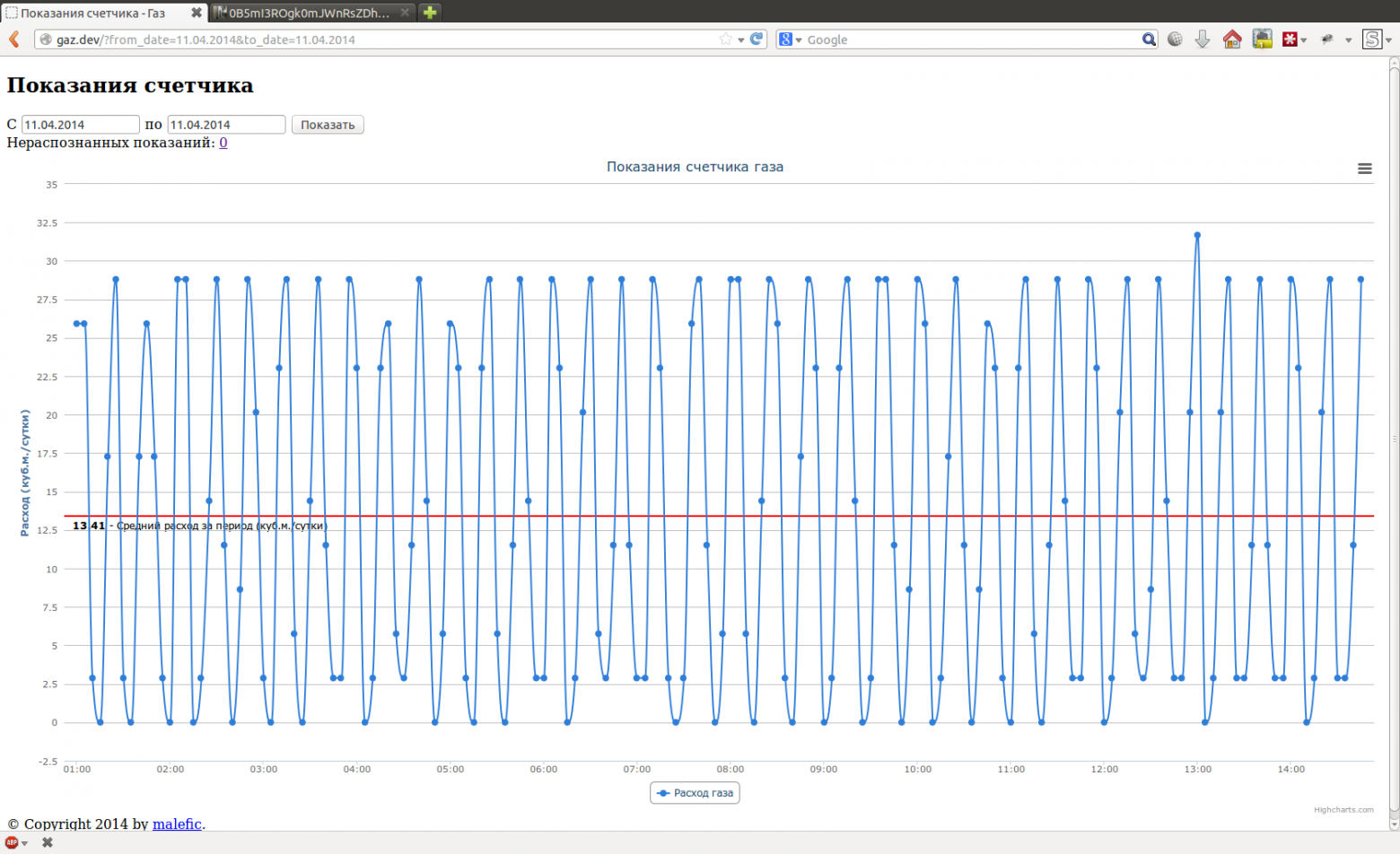
Интерфейс имеет всего две страницы, одна для просмотра показаний в виде графика, например, за день или за неделю:

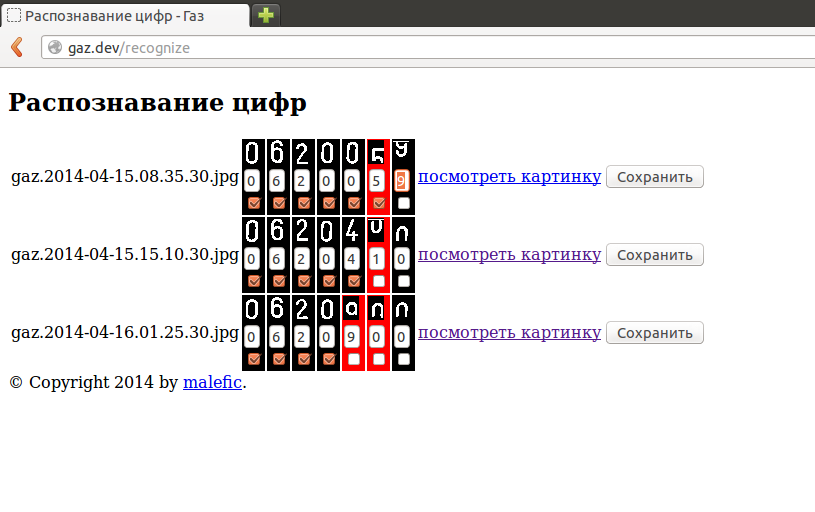
Вторая страница для ручного распознавания цифр. После того, как я руками вбил первые 20-30 показаний, робот стал довольно исправно распознавать показания сам. Изредка исключения все-таки встречаются и распознать цифру не удаётся, это чаще всего связано с вращением циферблата:



Тогда приходится вводить пропущенные цифры руками:
Либо можно такие показания просто игнорировать, они будут пропущены на графике, и ничего плохого не случится.
В планах ещё доработать скрипт, чтобы отправлял e-mail в случае совпадения нескольких последних показаний.
Вот и всё, о чём хотел рассказать, спасибо, если дочитали до конца.

