Почему изображение, масштабированное с бикубической интерполяцией, выглядит не как в Фотошопе. Почему одна программа ресайзит быстро, а другая — нет, хотя результат одинаковый. Какой метод ресайза лучше для увеличения, а какой для уменьшения. Что делают фильтры и чем они отличаются.
Вообще, это было вступлением к другой статье, но оно затянулось и вылилось в отдельный материал.

Этот человек сидит среди ромашек, чтобы привлечь ваше внимание к статье.
Для наглядного сравнения я буду использовать изображения одинакового разрешения 1920×1280 (одно, второе), которые буду приводить к размерам 330×220, 1067×667 и 4800×3200. Под иллюстрациями будет написано, сколько миллисекунд занял ресайз в то или иное разрешение. Цифры приведены лишь для понимания сложности алгоритма, поэтому конкретное железо или ПО, на котором они получены, не так важно.
Это самый примитивный и быстрый метод. Для каждого пикселя конечного изображения выбирается один пиксель исходного, наиболее близкий к его положению с учетом масштабирования. Такой метод дает пикселизированное изображение при увеличении и сильно зернистое изображение при уменьшении.

Вообще, качество и производительность любого метода уменьшения можно оценить по отношению количества пикселей, участвовавших в формировании конечного изображения, к числу пикселей в исходном изображении. Чем больше это отношение, тем скорее всего алгоритм качественнее и медленнее. Отношение, равное одному, означает что как минимум каждый пиксель исходного изображения сделал свой вклад в конечное. Но для продвинутых методов оно может быть и больше одного. Дак вот, если например мы уменьшаем изображение методом ближайшего соседа в 3 раза по каждой стороне, то это соотношение равно 1/9. Т.е. большая часть исходных пикселей никак не учитывается.






Теоретическая скорость работы зависит только от размеров конечного изображения. На практике при уменьшении свой вклад вносят промахи кеша процессора: чем меньше масштаб, тем меньше данных используется из каждой загруженной в кеш линейки.
Метод осознанно применяется для уменьшения крайне редко, т.к. дает очень плохое качество, хотя и может быть полезен при увеличении. Из-за скорости и простоты реализации он есть во всех библиотеках и приложениях, работающих с графикой.
Аффинные преобразования — общий метод для искажения изображений. Они позволяют за одну операцию повернуть, растянуть и отразить изображение. Поэтому во многих приложениях и библиотеках, реализующих метод аффинных преобразований, функция изменения изображений является просто оберткой, рассчитывающей коэффициенты для преобразования.
Принцип действия заключается в том, что для каждой точки конечного изображения берется фиксированный набор точек исходного и интерполируется в соответствии с их взаимным положением и выбранным фильтром. Количество точек тоже зависит от фильтра. Для билинейной интерполяции берется 2x2 исходных пикселя, для бикубической 4x4. Такой метод дает гладкое изображение при увеличении, но при уменьшении результат очень похож на ближайшего соседа. Смотрите сами: теоретически, при бикубическом фильтре и уменьшении в 3 раза отношение обработанных пикселей к исходным равно 4² / 3² = 1,78. На практике результат значительно хуже т.к. в существующих реализациях окно фильтра и функция интерполяции не масштабируются в соответствии с масштабом изображения, и пиксели ближе к краю окна берутся с отрицательными коэффициентами (в соответствии с функцией), т.е. не вносят полезный вклад в конечное изображение. В результате изображение, уменьшенное с бикубическим фильтром, отличается от изображения, уменьшенного с билинейным, только тем, что оно еще более четкое. Ну а для билинейного фильтра и уменьшения в три раза отношение обработанных пикселей к исходным равно 2² / 3² = 0.44, что принципиально не отличается от ближайшего соседа. Фактически, аффинные преобразования нельзя использовать для уменьшения более чем в 2 раза. И даже при уменьшении до двух раз они дают заметные эффекты лесенки для линий.
Теоретически, должны быть реализации именно аффинных преобразований, масштабирующие окно фильтра и сам фильтр в соответствии с заданными искажениями, но в популярных библиотеках с открытым исходным кодом я таких не встречал.






Время работы заметно больше, чем у ближайшего соседа, и зависит от размера конечного изображения и размера окна выбранного фильтра. От промахов кеша уже практически не зависит, т.к. исходные пиксели используются как минимум по двое.
Мое скромное мнение, что использование этого способа для произвольного уменьшения изображений попросту является багом, потому что результат получается очень плохой и похож на ближайшего соседа, а ресурсов на этот метод нужно значительно больше. Тем не менее, этот метод нашел широкое применение в программах и библиотеках. Самое удивительное, что этот способ используется во всех браузерах для метода канвы
Кроме того, именно этот метод используется видеокартами для отрисовки трехмерных сцен. Но разница в том, что видеокарты для каждой текстуры заранее подготавливают набор уменьшенных версий (mip-уровней), и для окончательной отрисовки выбирается уровень с таким разрешением, чтобы уменьшение текстуры было не более двух раз. Кроме этого, для устранения резкого скачка при смене mip-уровня (когда текстурированный объект приближается или отдаляется), используется линейная интерполяция между соседними mip-уровнями (это уже трилинейная фильтрация). Таким образом для отрисовки каждого пикселя трехмерного объекта нужно интерполировать между 2³ пикселями. Это дает приемлемый для быстро движущейся картинки результат за время, линейное относительно конечного разрешения.
С помощью этого метода создаются те самые mip-уровни, с помощью него (если сильно упростить) работает полноэкранное сглаживание в играх. Его суть в разбиении исходного изображения по сетке пикселей конечного и складывании всех исходных пикселей, приходящихся на каждый пиксель конечного в соответствии с площадью, попавшей под конечный пиксель. При использовании этого метода для увеличения, на каждый пиксель конечного изображения приходится ровно один пиксель исходного. Поэтому результат для увеличения равен ближайшему соседу.


Можно выделить два подвида этого метода: с округлением границ пикселей до ближайшего целого числа пикселей и без. В первом случае алгоритм становится малопригодным для масштабирования меньше чем в 3 раза, потому что на какой-нибудь один конечный пиксель может приходиться один исходный, а на соседний — четыре (2x2), что приводит к диспропорции на локальном уровне. В то же время алгоритм с округлением очевидно можно использовать в случаях, когда размер исходного изображения кратен размеру конечного, или масштаб уменьшения достаточно мал (версии разрешением 330×220 почти не отличаются). Отношение обработанных пикселей к исходным при округлении границ всегда равно единице.






Подвид без округления дает отличное качество при уменьшении на любом масштабе, а при увеличении дает странный эффект, когда большая часть исходного пикселя на конечном изображении выглядит однородной, но на краях видно переход. Отношение обработанных пикселей к исходным без округления границ может быть от единицы до четырех, потому что каждый исходный пиксель вносит вклад либо в один конечный, либо в два соседних, либо в четыре соседних пикселя.






Производительность этого метода для уменьшения ниже, чем у аффинных преобразований, потому что в расчете конечного изображения участвуют все пиксели исходного. Версия с округлением до ближайших границ обычно быстрее в несколько раз. Также возможно создать отдельные версии для масштабирования в фиксированное количество раз (например, уменьшение в 2 раза), которые будут еще быстрее.
Данный метод используется в функции
Этот метод похож на аффинные преобразования тем, что используются фильтры, но имеет не фиксированное окно, а окно, пропорциональное масштабу. Например, если размер окна фильтра равен 6, а размер изображения уменьшается в 2,5 раза, то в формировании каждого пикселя конечного изображения принимает участие (2,5 * 6)² = 225 пикселей, что гораздо больше, чем в случае суперсемплинга (от 9 до 16). К счастью, свертки можно считать в 2 прохода, сначала в одну сторону, потом в другую, поэтому алгоритмическая сложность расчета каждого пикселя равна не 225, а всего (2,5 * 6) * 2 = 30. Вклад каждого исходного пикселя в конечный как раз определяется фильтром. Отношение обработанных пикселей к исходным целиком определяется размером окна фильтра и равно его квадрату. Т.е. для билинейного фильтра это отношение будет 4, для бикубического 16, для Ланцоша 36. Алгоритм прекрасно работает как для уменьшения, так и для увеличения.






Скорость работы этого метода зависит от всех параметров: размеров исходного изображения, размера конечного изображения, размера окна фильтра.
Именно этот метод реализован в ImageMagick, GIMP, в текущей версии Pillow с флагом ANTIALIAS.
Одно из преимуществ этого метода в том, что фильтры могут задаваться отдельной функцией, никак не привязанной к реализации метода. При этом функция самого фильтра может быть достаточно сложной без особой потери производительности, потому что коэффициенты для всех пикселей в одном столбце и для всех пикселей в одной строке считаются только один раз. Т.е. сама функция фильтра вызывается только (m + n) * w раз, где m и n — размеры конечного изображения, а w — размер окна фильтра. И наклепать этих функций можно множество, было бы математическое обоснование. В ImageMagick, например, их 15. Вот как выглядят самые популярные:
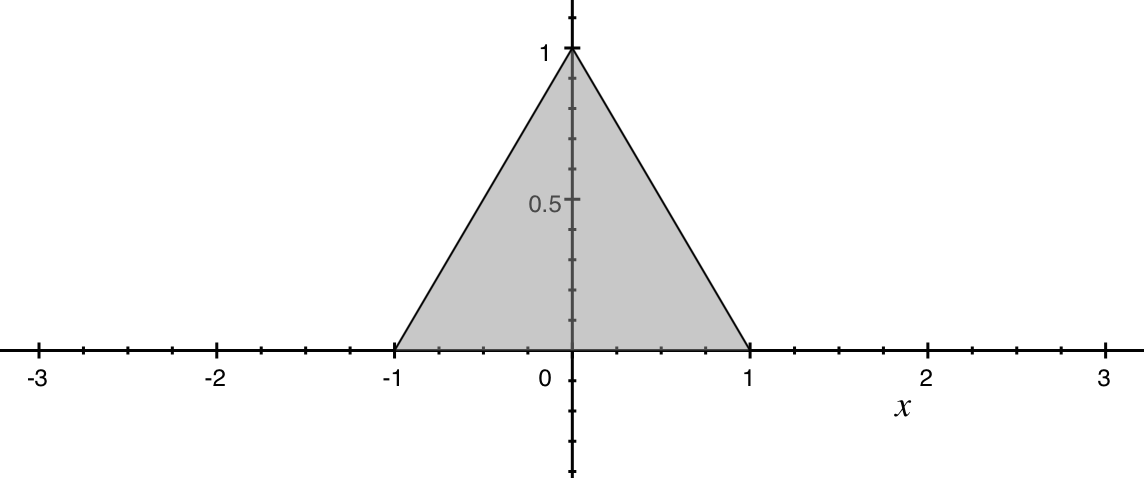
Билинейный фильтр (
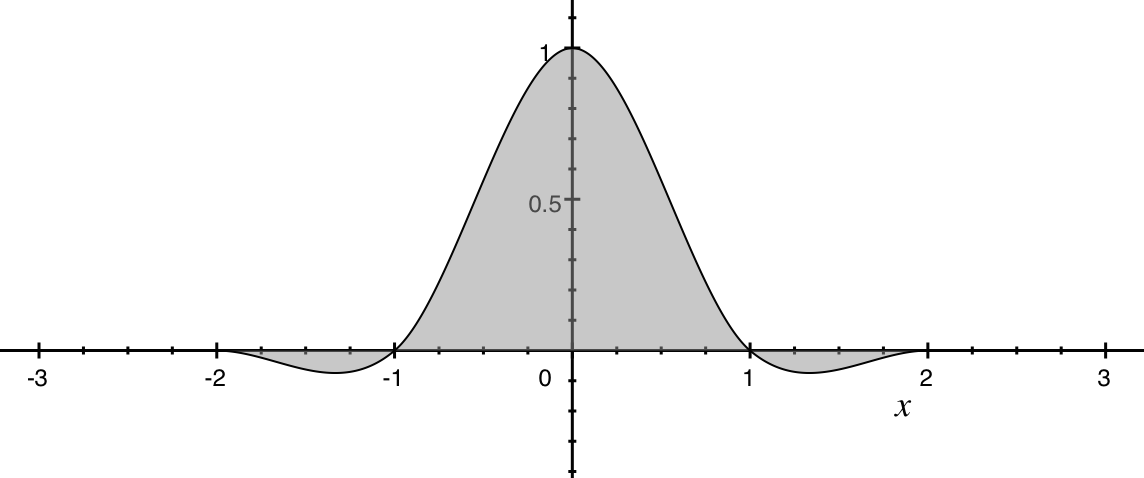
Бикубический фильтр (
Фильтр Ланцоша (
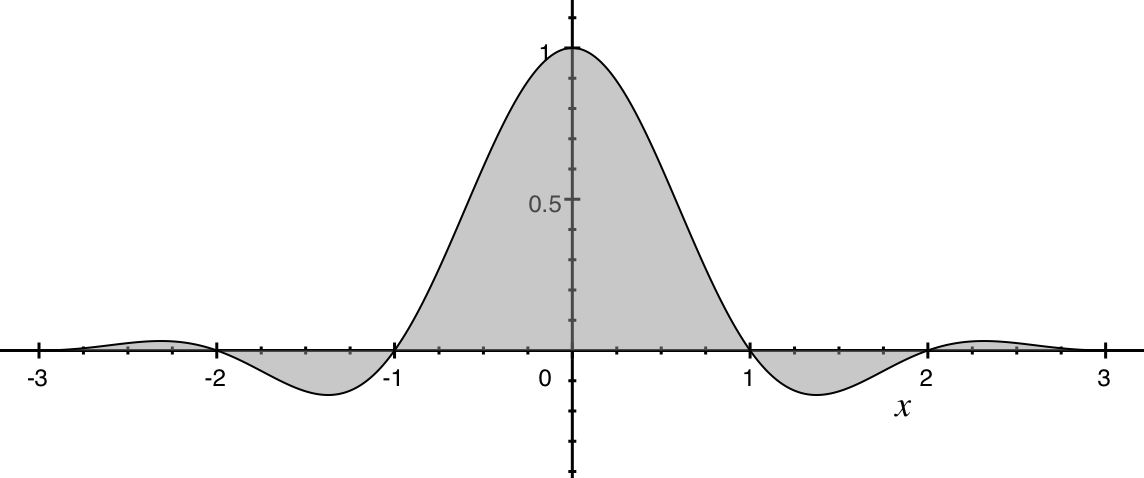
Примечательно, что некоторые фильтры имеют зоны отрицательных коэффициентов (как например бикубический фильтр или фильтр Ланцоша). Это нужно для придания переходам на конечном изображении резкости, которая была на исходном.
Вообще, это было вступлением к другой статье, но оно затянулось и вылилось в отдельный материал.
Этот человек сидит среди ромашек, чтобы привлечь ваше внимание к статье.
Для наглядного сравнения я буду использовать изображения одинакового разрешения 1920×1280 (одно, второе), которые буду приводить к размерам 330×220, 1067×667 и 4800×3200. Под иллюстрациями будет написано, сколько миллисекунд занял ресайз в то или иное разрешение. Цифры приведены лишь для понимания сложности алгоритма, поэтому конкретное железо или ПО, на котором они получены, не так важно.
Ближайший сосед (Nearest neighbor)
Это самый примитивный и быстрый метод. Для каждого пикселя конечного изображения выбирается один пиксель исходного, наиболее близкий к его положению с учетом масштабирования. Такой метод дает пикселизированное изображение при увеличении и сильно зернистое изображение при уменьшении.
Вообще, качество и производительность любого метода уменьшения можно оценить по отношению количества пикселей, участвовавших в формировании конечного изображения, к числу пикселей в исходном изображении. Чем больше это отношение, тем скорее всего алгоритм качественнее и медленнее. Отношение, равное одному, означает что как минимум каждый пиксель исходного изображения сделал свой вклад в конечное. Но для продвинутых методов оно может быть и больше одного. Дак вот, если например мы уменьшаем изображение методом ближайшего соседа в 3 раза по каждой стороне, то это соотношение равно 1/9. Т.е. большая часть исходных пикселей никак не учитывается.
1920×1280 → 330×220 = 0,12 ms1920×1280 → 1067×667 = 1,86 ms1920×1280 → 4800×3200 = 22,5 msТеоретическая скорость работы зависит только от размеров конечного изображения. На практике при уменьшении свой вклад вносят промахи кеша процессора: чем меньше масштаб, тем меньше данных используется из каждой загруженной в кеш линейки.
Метод осознанно применяется для уменьшения крайне редко, т.к. дает очень плохое качество, хотя и может быть полезен при увеличении. Из-за скорости и простоты реализации он есть во всех библиотеках и приложениях, работающих с графикой.
Аффинные преобразования (Affine transformations)
Аффинные преобразования — общий метод для искажения изображений. Они позволяют за одну операцию повернуть, растянуть и отразить изображение. Поэтому во многих приложениях и библиотеках, реализующих метод аффинных преобразований, функция изменения изображений является просто оберткой, рассчитывающей коэффициенты для преобразования.
Принцип действия заключается в том, что для каждой точки конечного изображения берется фиксированный набор точек исходного и интерполируется в соответствии с их взаимным положением и выбранным фильтром. Количество точек тоже зависит от фильтра. Для билинейной интерполяции берется 2x2 исходных пикселя, для бикубической 4x4. Такой метод дает гладкое изображение при увеличении, но при уменьшении результат очень похож на ближайшего соседа. Смотрите сами: теоретически, при бикубическом фильтре и уменьшении в 3 раза отношение обработанных пикселей к исходным равно 4² / 3² = 1,78. На практике результат значительно хуже т.к. в существующих реализациях окно фильтра и функция интерполяции не масштабируются в соответствии с масштабом изображения, и пиксели ближе к краю окна берутся с отрицательными коэффициентами (в соответствии с функцией), т.е. не вносят полезный вклад в конечное изображение. В результате изображение, уменьшенное с бикубическим фильтром, отличается от изображения, уменьшенного с билинейным, только тем, что оно еще более четкое. Ну а для билинейного фильтра и уменьшения в три раза отношение обработанных пикселей к исходным равно 2² / 3² = 0.44, что принципиально не отличается от ближайшего соседа. Фактически, аффинные преобразования нельзя использовать для уменьшения более чем в 2 раза. И даже при уменьшении до двух раз они дают заметные эффекты лесенки для линий.
Теоретически, должны быть реализации именно аффинных преобразований, масштабирующие окно фильтра и сам фильтр в соответствии с заданными искажениями, но в популярных библиотеках с открытым исходным кодом я таких не встречал.
1920×1280 → 330×220 = 6.13 ms1920×1280 → 1067×667 = 17.7 ms1920×1280 → 4800×3200 = 869 msВремя работы заметно больше, чем у ближайшего соседа, и зависит от размера конечного изображения и размера окна выбранного фильтра. От промахов кеша уже практически не зависит, т.к. исходные пиксели используются как минимум по двое.
Мое скромное мнение, что использование этого способа для произвольного уменьшения изображений попросту является багом, потому что результат получается очень плохой и похож на ближайшего соседа, а ресурсов на этот метод нужно значительно больше. Тем не менее, этот метод нашел широкое применение в программах и библиотеках. Самое удивительное, что этот способ используется во всех браузерах для метода канвы
drawImage() (наглядный пример), хотя для простого отображения картинок в элементе используются более аккуратные методы (кроме IE, в нем для обоих случаев используются аффинные преобразования). Помимо этого, такой метод используется в OpenCV, текущей версии питоновской библиотеки Pillow (об этом я надеюсь написать отдельно), в Paint.NET.Кроме того, именно этот метод используется видеокартами для отрисовки трехмерных сцен. Но разница в том, что видеокарты для каждой текстуры заранее подготавливают набор уменьшенных версий (mip-уровней), и для окончательной отрисовки выбирается уровень с таким разрешением, чтобы уменьшение текстуры было не более двух раз. Кроме этого, для устранения резкого скачка при смене mip-уровня (когда текстурированный объект приближается или отдаляется), используется линейная интерполяция между соседними mip-уровнями (это уже трилинейная фильтрация). Таким образом для отрисовки каждого пикселя трехмерного объекта нужно интерполировать между 2³ пикселями. Это дает приемлемый для быстро движущейся картинки результат за время, линейное относительно конечного разрешения.
Суперсемплинг (Supersampling)
С помощью этого метода создаются те самые mip-уровни, с помощью него (если сильно упростить) работает полноэкранное сглаживание в играх. Его суть в разбиении исходного изображения по сетке пикселей конечного и складывании всех исходных пикселей, приходящихся на каждый пиксель конечного в соответствии с площадью, попавшей под конечный пиксель. При использовании этого метода для увеличения, на каждый пиксель конечного изображения приходится ровно один пиксель исходного. Поэтому результат для увеличения равен ближайшему соседу.
Можно выделить два подвида этого метода: с округлением границ пикселей до ближайшего целого числа пикселей и без. В первом случае алгоритм становится малопригодным для масштабирования меньше чем в 3 раза, потому что на какой-нибудь один конечный пиксель может приходиться один исходный, а на соседний — четыре (2x2), что приводит к диспропорции на локальном уровне. В то же время алгоритм с округлением очевидно можно использовать в случаях, когда размер исходного изображения кратен размеру конечного, или масштаб уменьшения достаточно мал (версии разрешением 330×220 почти не отличаются). Отношение обработанных пикселей к исходным при округлении границ всегда равно единице.
1920×1280 → 330×220 = 7 ms1920×1280 → 1067×667 = 15 ms1920×1280 → 4800×3200 = 22,5 msПодвид без округления дает отличное качество при уменьшении на любом масштабе, а при увеличении дает странный эффект, когда большая часть исходного пикселя на конечном изображении выглядит однородной, но на краях видно переход. Отношение обработанных пикселей к исходным без округления границ может быть от единицы до четырех, потому что каждый исходный пиксель вносит вклад либо в один конечный, либо в два соседних, либо в четыре соседних пикселя.
1920×1280 → 330×220 = 19 ms1920×1280 → 1067×667 = 45 ms1920×1280 → 4800×3200 = 112 msПроизводительность этого метода для уменьшения ниже, чем у аффинных преобразований, потому что в расчете конечного изображения участвуют все пиксели исходного. Версия с округлением до ближайших границ обычно быстрее в несколько раз. Также возможно создать отдельные версии для масштабирования в фиксированное количество раз (например, уменьшение в 2 раза), которые будут еще быстрее.
Данный метод используется в функции
gdImageCopyResampled() библиотеки GD, входящей в состав PHP, есть в OpenCV (флаг INTER_AREA), Intel IPP, AMD Framewave. Примерно по такому же принципу работает libjpeg, когда открывает изображения в уменьшенном в несколько раз виде. Последнее позволяет многим приложениям открывать изображения JPEG заранее уменьшенными в несколько раз без особых накладных расходов (на практике libjpeg открывает уменьшенные изображения даже немного быстрее полноразмерных), а затем применять другие методы для ресайза до точных размеров. Например, если нужно отресайзить JPEG разрешением 1920×1280 в разрешение 330×220, можно открыть оригинальное изображение в разрешении 480×320, а затем уменьшить его до нужных 330×220.Свертки (Convolution)
Этот метод похож на аффинные преобразования тем, что используются фильтры, но имеет не фиксированное окно, а окно, пропорциональное масштабу. Например, если размер окна фильтра равен 6, а размер изображения уменьшается в 2,5 раза, то в формировании каждого пикселя конечного изображения принимает участие (2,5 * 6)² = 225 пикселей, что гораздо больше, чем в случае суперсемплинга (от 9 до 16). К счастью, свертки можно считать в 2 прохода, сначала в одну сторону, потом в другую, поэтому алгоритмическая сложность расчета каждого пикселя равна не 225, а всего (2,5 * 6) * 2 = 30. Вклад каждого исходного пикселя в конечный как раз определяется фильтром. Отношение обработанных пикселей к исходным целиком определяется размером окна фильтра и равно его квадрату. Т.е. для билинейного фильтра это отношение будет 4, для бикубического 16, для Ланцоша 36. Алгоритм прекрасно работает как для уменьшения, так и для увеличения.
1920×1280 → 330×220 = 76 ms1920×1280 → 1067×667 = 160 ms1920×1280 → 4800×3200 = 1540 msСкорость работы этого метода зависит от всех параметров: размеров исходного изображения, размера конечного изображения, размера окна фильтра.
Именно этот метод реализован в ImageMagick, GIMP, в текущей версии Pillow с флагом ANTIALIAS.
Одно из преимуществ этого метода в том, что фильтры могут задаваться отдельной функцией, никак не привязанной к реализации метода. При этом функция самого фильтра может быть достаточно сложной без особой потери производительности, потому что коэффициенты для всех пикселей в одном столбце и для всех пикселей в одной строке считаются только один раз. Т.е. сама функция фильтра вызывается только (m + n) * w раз, где m и n — размеры конечного изображения, а w — размер окна фильтра. И наклепать этих функций можно множество, было бы математическое обоснование. В ImageMagick, например, их 15. Вот как выглядят самые популярные:
Билинейный фильтр (
bilinear или triangle в ImageMagick)Бикубический фильтр (
bicubic, catrom в ImageMagick)Фильтр Ланцоша (
Lanczos)Примечательно, что некоторые фильтры имеют зоны отрицательных коэффициентов (как например бикубический фильтр или фильтр Ланцоша). Это нужно для придания переходам на конечном изображении резкости, которая была на исходном.


{kind=link}
{kind=link}