В этой статье рассказывается, как писать синтаксические анализаторы с помощью этой небольшой библиотеки на с++.
Обычно, текст на машинном языке состоит из предложений, те — из подпредложений, а те, в свою очередь, из подподпредложений, и так вплоть до символов.
Например, элемент xml состоит из открывающего тега, содержимого и закрывающего тега. —> Открывающий тег состоит из '<', имени тега, возможно пустого списка атрибутов и '>'. —> Закрывающий тег состоит из '</', имени тега и '>'. —> Атрибут состоит из имени, знаков '=', '"', строки символов и снова '"'. —> Содержимое в свою очередь тоже может содержать элементы. —> И т.д. Таким образом, после разбора получается синтаксическое дерево.
Такие языки удобно описывать формой Бэкуса-Наура (БНФ), где каждый нетерминал соответствует некоторому предложению языка. Когда мы пишем программы, мы обычно разбиваем их на функции и подфункции, и раз мы собрались писать синтаксический анализатор, пусть каждому нетерминалу БНФ соответствует одна функция нашего анализатора, и пусть каждая такая функция:
Например для БНФ вида
А для предложения БНФ вида
(Кажется это называется синтаксический анализ с возвратами)
Не всякий текст, удовлетворяющий БНФ нам может подходить. Например элемент языка xml может описываться так:
Терминальные функции могут выглядеть например так:
Пока что мы делали синтаксический анализ строки. Но заметим, что для всех типов вышеперечисленных функций достаточно forward итераторов.
Зададимся целью создать класс-поток, предоставляющий forward итераторы, и хранящий в памяти файл не целиком а небольшими кусочками. Тогда, если сделать функции разбора шаблонными, то их можно будет использовать и со строкамии, и с потоками. (Что и сделано в «base_parse.h» для терминальных (и около того )функций.) Но сначала внесем некоторые разъяснения в идеологию unix «все есть файл»: Бывают файлы располагающиеся на диске — их можно читать несколько раз и с любой позиции (назовем их random-access файлами ). А бывают потоки, перенаправленные из других программ, идущие по сети или от пользователя с клавиатуры (назовем их forward потоками). Такие потоки можно читать только за один проход. (fixme) По этому, что бы можно было работать и с тем и с другим, зададимся целью создать класс-поток, читающий файл за один проход, предоставляющий forward итераторы, и хранящий в памяти файл не целиком а небольшими кусочками.
Для input итераторов такие потоки реализованы очень давно, по сути в себе содержат только один input итератор, и внутри себя содержат один буфер, по которому движется этот итератор, и когда он подходит к концу буфера, в этот буфер загружается следующий кусок файла, а итератор начинает двигаться с начала обновленного буфера.

Forward итераторы отличаются от input итераторов тем, что их можно копировать. Для потока с forward итераторами решением будет список буферов. Как только какой-нибудь итератор выходит за пределы самого правого буфера, в список добавляется новый буфер, и заполняется непосредственно из файла блоком данных. Но постепенно так в память загрузится весь файл, а мы этого не хотим. Сделаем так, чтоб удалялись все буфера, находящиеся левее буфера на котором находится самый левый (отстающий) итератор. Но мы не будем каждому буферу сопоставлять список итераторов, находящихся на нем, а будем сопоставлять всего лишь их количество (подсчет итераторов). Как только какой-нибудь буфер узнает, что на нем осталось 0 итераторов и что он самый левый, тогда удаляется он и все соседние буфера правее него, на которых тоже 0 итераторов.

Получается, каждый итератор должен содержать:
Когда итератор доходит до границы буфера, он смотрит, есть ли в списке буферов следующий, если его нет — загружает его, на предыдущем буфере уменьшает счетчик итераторов, а на следующем увеличивает. Если на предыдущем буфере осталось 0 итераторов — он удаляется. Если итератор дошел до конца файла — он только отвязывается от предыдущего буфера и переходит в состояние «конец файла». При копировании итератора — увеличивается счетчик итераторов на буфере на котором он находится, а при вызове деструктора итератора — счетчик уменьшается, и, опять же, если на буфере осталось 0 итераторов, то он и соседние справа буфера, на которых тоже 0 итераторов, — удаляются. Детали реализации смотри в «forward_stream.h».
У таких итераторов есть некоторые особенности использования, отличающие их от обычных итераторов. Так например, перед разрушением(деструктором) потока (хранящего список буферов и некоторую дополнительную информацию) должны быть разрушены все итераторы, т.к. при разрушении они будут обращаться к буферам в не зависимости от того, разрушены ли те в свою очередь или нет. Если мы один раз в результате вызова метода begin() получили первый итератор (и создали первый же буфер), и он ушел на столько, что первый буфер уже удален, мы не сможем снова получить итератор методом begin(). Также (как будет видно из следующего параграфа) у потока нет метода end(). В результате чего мной было принято решение сделать внутренний итератор в потоке, который инициализируется при инициализации всего потока, и ссылку на который можно получить методом iter(). Также при использовании в алгоритмах не стоит лишний раз копировать итераторы, т.к. в памяти хранятся буфера от самого левого до самого правого итератора, и в случае больших файлов это может привести к большому расходу памяти.
В качестве бонуса, есть различные типы буферов: простые (basic_simple_buffer), с вычислением строки-столбца по итератору (basic_adressed_buffer), планируется сделать буфер, осуществляющий перекодировку между различными кодировками. В связи с чем поток параметризуется типом буфера.
Конец сишной строки определяется нулевым символом. Это означает, что пока мы движемся по строке, чтобы обнаружить ее конец, нам надо не сравнивать указатель с другим указателем (как это традиционно делается в STL), а надо проверять значение, указываемое нашим указателем. С файлами примерно такая же ситуация: при посимвольном вводе char-ов мы получаем int-ы, и т.к. у них диапозон значений больше, мы опять же тестируем каждый символ на равенство EOF. Масла в огонь добавляет тот факт, что для forward потоков, поступающих в реальном времени, положение конца файла заранее неизвестно.
Эту информацию можно обобщить, сделав функцию atend(it), которая для указателей по строке будет выглядеть так:
А для итераторов по потоку она будет возвращать true, когда итератор указывает на конец файла.
Для интерактивного взаимодействия с пользователем (через stdin) блочная буферизация не подходит, т.к. в блоке чаще всего помещается несколько строк, и после ввода одной строки программа продолжает ожидать ввода от пользователя, т.к. блок все еще не заполнен. Для этого необходима строковая буферизация, когда буфер заполняется символами вплоть до символа перевода строки. В этой библиотеке можно выбрать тип буферизации при помощи выбора типа файла, от которого инициализируется поток (basic_block_file_on_FILE или string_file_on_FILE).
strin — внутренний итератор потока над stdin'ом со строковой буферизацией.
Для неинтерактивных файлов при создании потока создается итератор, указывающий на первый символ, а значит загружается первый буфер. Для strin'а это не допустимо, т.к. программист может захотеть что-то выполнить или вывести на экран до того как программма перейдет в режим ожидания ввода строки.
По этому строковые файлы при заполнении первого буфера выдают фиктивную строку "\n". Для ее прочтения существует функция start_read_line(it), после выполнения которой программа переходит в режим ожидания ввода строки после чего можно произвести синтаксический анализ этой строки, не выводя при этом итераторы за пределы следующего символа '\n'.
Поле анализа прграммист может захотеть опять что-то вывести на экран, и если после этого ему опять понадобятся данные от пользователя, то перед их получением снова следует вызвать start_read_line(strin).
Т.о. получается цикл:
Конечно это костыль, и можно было бы сделать итераторы, которые требуют загрузки буфера только при разыменовании, но это привело бы к дополнительным проверкам при разименовании и просто усложнению всей системы…
Что бы пользователю не приходилось каждый раз заново писать терминальные функции, они в «base_parse.h» уже реализованы. Сейчас они реализованы (кроме обработки плавающих чисел) в общем виде, в дальнейшам планируется специализировать их с использованием строковых функций (таких как strcmp, strstr, strchr, strspn, strcspn) для указателей по строкам и для итераторов по потокам. Также они позволяют пользователю почти не думать о конце файла, и просто задают стиль кода.
Ниже представлена краткая сводка базовых функций парсинга, возвращаемые значиния и статистика их использования при реализации двух тестовых парсеров.
Т.к. через имя функции удобно возвращать код ошибки или сообщение об ошибке, что бы текст парсеров выглядел более очевидно, я сделал специальные макросы:
Хотя вполне возможно сделать какой-нибудь класс, хранящий эту информацию и преобразуемый к bool соответствующим образом.
Вообще я противник неконстантных ссылок, и считаю, что аргументы, которые функция должна изменить, должны передаваться в нее по указателю а не по ссылке, что бы при вызове это было видно, но всвязи с тем, что операторы для указателей на что бы то ни было перегружать нельзя, специально для совместимости с operator>>() (парочка таких определена в «strin.h») я итераторы везде передаю по ссылке (а возвращаемые значения по указателю).
На данный момент имеется два примера использования этих функций: calc.cpp и winreg.cpp.
Таким образом для написания парсера не требуется умения обращаться с другими программами генерации парсеров. Каждый нетерминал БНФ взаимнооднозначно переводится в функцию, которая, конечно, громоздковата по сравнению с описанием в БНФ (это можно в дальнейшем исправить, сделав функцию, делающую разбор по регулярному выражению, аналогично как в <boost/xpressive>), но зато в нее можно добавить любую проверку и обработку данных. Все это можно делать как со строками, так и с потоками в одинаковой форме. Поток ввода по умолчанию готов к вводу по умолчанию, а операторы >>, аналогичные таким же из стандартной библиотеки, дают возможность использовать эту библиотеку вместо стандартной библиотеки ввода.
Как с помощью forward_stream делать токенезацию, я попробую рассказать и показать в следующей статье.
Обычно, текст на машинном языке состоит из предложений, те — из подпредложений, а те, в свою очередь, из подподпредложений, и так вплоть до символов.
Например, элемент xml состоит из открывающего тега, содержимого и закрывающего тега. —> Открывающий тег состоит из '<', имени тега, возможно пустого списка атрибутов и '>'. —> Закрывающий тег состоит из '</', имени тега и '>'. —> Атрибут состоит из имени, знаков '=', '"', строки символов и снова '"'. —> Содержимое в свою очередь тоже может содержать элементы. —> И т.д. Таким образом, после разбора получается синтаксическое дерево.
Такие языки удобно описывать формой Бэкуса-Наура (БНФ), где каждый нетерминал соответствует некоторому предложению языка. Когда мы пишем программы, мы обычно разбиваем их на функции и подфункции, и раз мы собрались писать синтаксический анализатор, пусть каждому нетерминалу БНФ соответствует одна функция нашего анализатора, и пусть каждая такая функция:
- пытается разобрать это предложение с заданной позиции
- возвращает, удалось ли ей это сделать
- возвращает позицию, где закончился разбор или произошла ошибка
- а также, возможно, возвращает некоторые дополнительные данные, которые мы хотим получить в результате разбора
Например для БНФ вида
expr ::= expr1 expr2 expr3 будем писать такую функцию:bool read_expr(char *& p, ....){
if(!read_expr1(p, ....))
return false;
//функция read_expr1() оставляет p там, где завершился разбор expr1
//так что никаких манипуляций с p в данном месте не требуется
if(!read_expr2(p, ....))
return false;
if(!read_expr3(p, ....))
return false;
/*обработку возвращаемых значений добавить по вкусу*/
return true;
}
А для предложения БНФ вида
expr ::= expr1 | expr2 | expr3 — функцию:bool read_expr(const char *& p, ....){
const char * l = p;
if(read_expr1(p, ....))
return true;
//p может указывать на точку, где произошла ошибка при разборе expr1
p = l;
if(read_expr2(p, ....))
return true;
p = l;
if(read_expr3(p, ....))
return true;
return false;
/*обработку возвращаемых значений добавить по вкусу*/
}
(Кажется это называется синтаксический анализ с возвратами)
Не всякий текст, удовлетворяющий БНФ нам может подходить. Например элемент языка xml может описываться так:
element ::= '<'identifier'>'some_data'</'identifier'>' , но это предложение будет действительно элементом, только если идентификаторы совпадают. Такие (или аналогичные) проверки можно легко добавлять в функции разбора.Терминальные функции могут выглядеть например так:
bool read_fix_char(const char *& it, char c){
if(!*it) return false;//конец строки
if(*it!=c) return false;//не тот символ
//в случае неудачи указатель останется на месте
it++; //в случае удачи перейдет к следующему символу
return true;
}
bool read_fix_str(const char * & it, const ch_t * s){
while(*it)//пока не конец строки
if(!*s)
return true;
else if(*it!=*s)
return false;
//в случае неудачи указатель будет указывать на отличающийся символ
else
it++, s++;
if(!*s) return true;
return false;//конец строки оказался раньше ожидаемого
}
Пока что мы делали синтаксический анализ строки. Но заметим, что для всех типов вышеперечисленных функций достаточно forward итераторов.
forward stream
Зададимся целью создать класс-поток, предоставляющий forward итераторы, и хранящий в памяти файл не целиком а небольшими кусочками. Тогда, если сделать функции разбора шаблонными, то их можно будет использовать и со строкамии, и с потоками. (Что и сделано в «base_parse.h» для терминальных (и около того )функций.) Но сначала внесем некоторые разъяснения в идеологию unix «все есть файл»: Бывают файлы располагающиеся на диске — их можно читать несколько раз и с любой позиции (назовем их random-access файлами ). А бывают потоки, перенаправленные из других программ, идущие по сети или от пользователя с клавиатуры (назовем их forward потоками). Такие потоки можно читать только за один проход. (fixme) По этому, что бы можно было работать и с тем и с другим, зададимся целью создать класс-поток, читающий файл за один проход, предоставляющий forward итераторы, и хранящий в памяти файл не целиком а небольшими кусочками.
Для input итераторов такие потоки реализованы очень давно, по сути в себе содержат только один input итератор, и внутри себя содержат один буфер, по которому движется этот итератор, и когда он подходит к концу буфера, в этот буфер загружается следующий кусок файла, а итератор начинает двигаться с начала обновленного буфера.
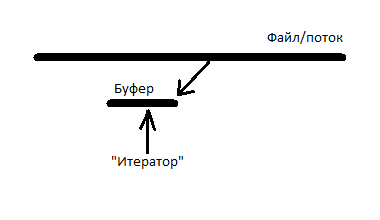
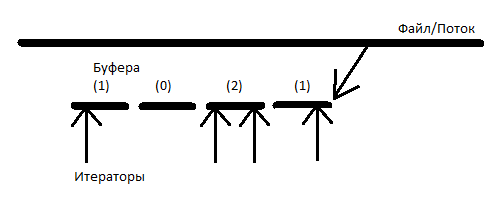
Forward итераторы отличаются от input итераторов тем, что их можно копировать. Для потока с forward итераторами решением будет список буферов. Как только какой-нибудь итератор выходит за пределы самого правого буфера, в список добавляется новый буфер, и заполняется непосредственно из файла блоком данных. Но постепенно так в память загрузится весь файл, а мы этого не хотим. Сделаем так, чтоб удалялись все буфера, находящиеся левее буфера на котором находится самый левый (отстающий) итератор. Но мы не будем каждому буферу сопоставлять список итераторов, находящихся на нем, а будем сопоставлять всего лишь их количество (подсчет итераторов). Как только какой-нибудь буфер узнает, что на нем осталось 0 итераторов и что он самый левый, тогда удаляется он и все соседние буфера правее него, на которых тоже 0 итераторов.
Получается, каждый итератор должен содержать:
- указатель на символ (который будет возвращаться при разыменовании)
- указатель на конец массива символов в буфере (с ним происходит сравнение при перемещении итератора)
- итератор по списку буферов (для доступа к данным буфера, а через них к данным всего потока).
Когда итератор доходит до границы буфера, он смотрит, есть ли в списке буферов следующий, если его нет — загружает его, на предыдущем буфере уменьшает счетчик итераторов, а на следующем увеличивает. Если на предыдущем буфере осталось 0 итераторов — он удаляется. Если итератор дошел до конца файла — он только отвязывается от предыдущего буфера и переходит в состояние «конец файла». При копировании итератора — увеличивается счетчик итераторов на буфере на котором он находится, а при вызове деструктора итератора — счетчик уменьшается, и, опять же, если на буфере осталось 0 итераторов, то он и соседние справа буфера, на которых тоже 0 итераторов, — удаляются. Детали реализации смотри в «forward_stream.h».
У таких итераторов есть некоторые особенности использования, отличающие их от обычных итераторов. Так например, перед разрушением(деструктором) потока (хранящего список буферов и некоторую дополнительную информацию) должны быть разрушены все итераторы, т.к. при разрушении они будут обращаться к буферам в не зависимости от того, разрушены ли те в свою очередь или нет. Если мы один раз в результате вызова метода begin() получили первый итератор (и создали первый же буфер), и он ушел на столько, что первый буфер уже удален, мы не сможем снова получить итератор методом begin(). Также (как будет видно из следующего параграфа) у потока нет метода end(). В результате чего мной было принято решение сделать внутренний итератор в потоке, который инициализируется при инициализации всего потока, и ссылку на который можно получить методом iter(). Также при использовании в алгоритмах не стоит лишний раз копировать итераторы, т.к. в памяти хранятся буфера от самого левого до самого правого итератора, и в случае больших файлов это может привести к большому расходу памяти.
В качестве бонуса, есть различные типы буферов: простые (basic_simple_buffer), с вычислением строки-столбца по итератору (basic_adressed_buffer), планируется сделать буфер, осуществляющий перекодировку между различными кодировками. В связи с чем поток параметризуется типом буфера.
atend()
Конец сишной строки определяется нулевым символом. Это означает, что пока мы движемся по строке, чтобы обнаружить ее конец, нам надо не сравнивать указатель с другим указателем (как это традиционно делается в STL), а надо проверять значение, указываемое нашим указателем. С файлами примерно такая же ситуация: при посимвольном вводе char-ов мы получаем int-ы, и т.к. у них диапозон значений больше, мы опять же тестируем каждый символ на равенство EOF. Масла в огонь добавляет тот факт, что для forward потоков, поступающих в реальном времени, положение конца файла заранее неизвестно.
Эту информацию можно обобщить, сделав функцию atend(it), которая для указателей по строке будет выглядеть так:
bool atend(const char * p)
{ return !*p; }
А для итераторов по потоку она будет возвращать true, когда итератор указывает на конец файла.
strin
Для интерактивного взаимодействия с пользователем (через stdin) блочная буферизация не подходит, т.к. в блоке чаще всего помещается несколько строк, и после ввода одной строки программа продолжает ожидать ввода от пользователя, т.к. блок все еще не заполнен. Для этого необходима строковая буферизация, когда буфер заполняется символами вплоть до символа перевода строки. В этой библиотеке можно выбрать тип буферизации при помощи выбора типа файла, от которого инициализируется поток (basic_block_file_on_FILE или string_file_on_FILE).
strin — внутренний итератор потока над stdin'ом со строковой буферизацией.
Для неинтерактивных файлов при создании потока создается итератор, указывающий на первый символ, а значит загружается первый буфер. Для strin'а это не допустимо, т.к. программист может захотеть что-то выполнить или вывести на экран до того как программма перейдет в режим ожидания ввода строки.
По этому строковые файлы при заполнении первого буфера выдают фиктивную строку "\n". Для ее прочтения существует функция start_read_line(it), после выполнения которой программа переходит в режим ожидания ввода строки после чего можно произвести синтаксический анализ этой строки, не выводя при этом итераторы за пределы следующего символа '\n'.
Поле анализа прграммист может захотеть опять что-то вывести на экран, и если после этого ему опять понадобятся данные от пользователя, то перед их получением снова следует вызвать start_read_line(strin).
Т.о. получается цикл:
while(true){
cout << "приглашение" <<endl;
start_read_line(strin); //явный запрос ввести строку
analys(strin);
}
Конечно это костыль, и можно было бы сделать итераторы, которые требуют загрузки буфера только при разыменовании, но это привело бы к дополнительным проверкам при разименовании и просто усложнению всей системы…
Базовые функции парсинга
Что бы пользователю не приходилось каждый раз заново писать терминальные функции, они в «base_parse.h» уже реализованы. Сейчас они реализованы (кроме обработки плавающих чисел) в общем виде, в дальнейшам планируется специализировать их с использованием строковых функций (таких как strcmp, strstr, strchr, strspn, strcspn) для указателей по строкам и для итераторов по потокам. Также они позволяют пользователю почти не думать о конце файла, и просто задают стиль кода.
Ниже представлена краткая сводка базовых функций парсинга, возвращаемые значиния и статистика их использования при реализации двух тестовых парсеров.
size_t n
ch_t c
ch_t * s
func_obj bool is(c) //наподобие bool isspace(c)
span spn //см выше
bispan bspn //см выше
func_obj err pf(it*) //наподобие int read_spc(it*)
func_obj err pf(it*, rez*)
len - кол-во символов, добавлненных в *pstr
. возвращаемое значение в случае реализованность
название аргументы рег.выр. если EOF если не EOF статистика использования
int read_until_eof (it&) .*$ 0 0 1 OK
int read_until_eof (it&, pstr*) .*$ len len OK
int read_fix_length (it&, n) .{n} -1 0 OK
int read_fix_length (it&, n, pstr*) .{n} -(1+len) 0 2 OK
int read_fix_str (it&, s) str -(1+len) 0 или (1+len) 9 OK
int read_fix_char (it&, c) c -1 0 или 1 11 OK
int read_charclass (it&, is) [ ] -1 0 или 1 OK
int read_charclass (it&, spn) [ ] -1 0 или 1 OK
int read_charclass (it&, bspn) [ ] -1 0 или 1 OK
int read_charclass_s (it&, is, pstr*) [ ] -1 0 или 1 OK
int read_charclass_s (it&, spn, pstr*) [ ] -1 0 или 1 1 OK
int read_charclass_s (it&, bspn, pstr*) [ ] -1 0 или 1 5 OK
int read_charclass_c (it&, is, ch*) [ ] -1 0 или 1 OK
int read_charclass_c (it&, spn, ch*) [ ] -1 0 или 1 1 OK
int read_charclass_c (it&, bspn, ch*) [ ] -1 0 или 1 OK
int read_c (it&, ch*) . -1 0 5 OK
int read_while_charclass (it&, is) [ ]* -(1+len) len OK
int read_while_charclass (it&, spn) [ ]* -(1+len) len 2 OK
int read_while_charclass (it&, bspn) [ ]* -(1+len) len OK
int read_while_charclass (it&, is, pstr*) [ ]* -(1+len) len OK
int read_while_charclass (it&, spn, pstr*) [ ]* -(1+len) len OK
int read_while_charclass (it&, bspn, pstr*) [ ]* -(1+len) len 1 OK
int read_until_charclass (it&, is) .*[ ]<- -(1+len) len OK
int read_until_charclass (it&, spn) .*[ ]<- -(1+len) len 1 OK
int read_until_charclass (it&, bspn) .*[ ]<- -(1+len) len OK
int read_until_charclass (it&, is, pstr*) .*[ ]<- -(1+len) len OK
int read_until_charclass (it&, spn, pstr*) .*[ ]<- -(1+len) len 2 OK
int read_until_charclass (it&, bspn, pstr*) .*[ ]<- -(1+len) len OK
int read_until_char (it&, c) .*c -(1+len) len OK
int read_until_char (it&, c, pstr*) .*c -(1+len) len OK
<- - говорит о том, что что после прочтения последнего символа итератор стоит не после него а на нем
int read_until_str (it&, s) .*str -(1+len) len 2 OK
int read_until_str (it&, s, pstr*) .*str -(1+len) len 1 OK
int read_until_pattern (it&, pf) .*( ) -(1+len) len OK
int read_until_pattern (it&, pf, rez*) .*( ) -(1+len) len OK
int read_until_pattern_s (it&, pf, pstr*) .*( ) -(1+len) len OK
int read_until_pattern_s (it&, pf, pstr*, rez*) .*( ) -(1+len) len OK
ch_t c
ch_t * s
func_obj bool is(c) //наподобие bool isspace(c)
span spn //см выше
bispan bspn //см выше
func_obj err pf(it*) //наподобие int read_spc(it*)
func_obj err pf(it*, rez*)
len - кол-во символов, добавлненных в *pstr
. возвращаемое значение в случае реализованность
название аргументы рег.выр. если EOF если не EOF статистика использования
int read_line (it&, s) .*[\r\n]<- -1 или len len OK
int read_line (it&) .*[\r\n]<- -1 или len len 1 OK
int start_read_line (it&) .*(\n|\r\n?) -1 0 или 1 8 OK
<- - говорит о том, что что после прочтения последнего символа итератор стоит не после него а на нем
int read_spc (it&) [:space:] -(1+len) len OK
int read_spcs (it&) [:space:]* -(1+len) len 5 OK
int read_s_fix_str (it&, s) [:space:]*str -(1+len) 0 или len 1 OK
int read_s_fix_char (it&, c) [:space:]*c -1 0 или 1 8 OK
int read_s_charclass (it&, is) [:space:][ ] -1 0 или 1 OK
int read_s_charclass_s (it&, is, pstr*) [:space:][ ] -1 0 или 1 OK
int read_s_charclass_c (it&, is, pc*) [:space:][ ] -1 0 или 1 2 OK
int read_bln (it&) [:blank:] -(1+len) len OK
int read_blns (it&) [:blank:]* -(1+len) len 1 OK
int read_b_fix_str (it&, s) [:blank:]*str -(1+len) 0 или len OK
int read_b_fix_char (it&, c) [:blank:]*c -1 0 или 1 OK
int read_b_charclass (it&, is) [:blank:][ ] -1 0 или 1 OK
int read_b_charclass_s (it&, is, pstr*) [:blank:][ ] -1 0 или 1 OK
int read_b_charclass_c (it&, is, pc*) [:blank:][ ] -1 0 или 1 OK
int_t может быть : long, long long, unsigned long, unsigned long long - для специализаций
[:digit:] ::= [0-"$(($ss-1))"]
sign ::= ('+'|'-')
int ::= spcs[sign]spcs[:digit:]+
. специализация для
. [w]char char16/32 stream_string
. возвращаемое значение в случае реализованность
название аргументы рег.выр. неудача переполнение статистика использования
int read_digit (it&, int ss, int_t*) [:digit:] 1 -1(EOF) 1 OK
int read_uint (it&, int ss, int_t*) [:digit:]+ 1 -1 1 OK
int read_sign_uint (it&, int ss, int_t*) [sign][:digit:]+ 1 -1 OK
int read_sign_s_uint (it&, int ss, int_t*) [sign]spcs[:digit:]+ 1 -1 1 OK
int read_int (it&, int ss, int_t*) spcs[sign]spcs[:digit:]+ 1 -1 1 OK OK
int read_dec (it&, int_t*) int#[:digit:]=[0-9] 1 -1 1 OK OK
int read_hex (it&, int_t*) int#[:digit:]=[:xdigit:] 1 -1 OK OK
int read_oct (it&, int_t*) int#[:digit:]=[0-7] 1 -1 OK OK
int read_bin (it&, int_t*) int#[:digit:]=[01] 1 -1 OK OK
Т.к. через имя функции удобно возвращать код ошибки или сообщение об ошибке, что бы текст парсеров выглядел более очевидно, я сделал специальные макросы:
#define r_if(expr) if((expr)==0)
#define r_while(expr) while((expr)==0)
#define r_ifnot(expr) if(expr)
#define r_whilenot(expr) while(expr)
/*
r_ifnot(err=read_smth(it))//если что-то не прочитано
return err;
*/
//следующие используются совместно с read_while_sm и read_until
#define rm_if(expr) if((expr)>=0) //типа рег. выр. '.*' * - multiple -> m
#define rm_while(expr) while((expr)>=0)
#define rm_ifnot(expr) if((expr)<0)
#define rm_whilenot(expr) while((expr)<0)
#define rp_if(expr) if((expr)>0) //типа рег. выр. '.+' + - plus -> p
#define rp_while(expr) while((expr)>0)
#define rp_ifnot(expr) if((expr)<=0)
#define rp_whilenot(expr) while((expr)<=0)
/*
rm_if(read_until_char(it,'\n'))//если прочитано 0 или более символов и символ \n
rp_if(read_until_char(it,'\n'))//если прочитано 1 или более символов и символ \n
*/
Хотя вполне возможно сделать какой-нибудь класс, хранящий эту информацию и преобразуемый к bool соответствующим образом.
Вообще я противник неконстантных ссылок, и считаю, что аргументы, которые функция должна изменить, должны передаваться в нее по указателю а не по ссылке, что бы при вызове это было видно, но всвязи с тем, что операторы для указателей на что бы то ни было перегружать нельзя, специально для совместимости с operator>>() (парочка таких определена в «strin.h») я итераторы везде передаю по ссылке (а возвращаемые значения по указателю).
На данный момент имеется два примера использования этих функций: calc.cpp и winreg.cpp.
Таким образом для написания парсера не требуется умения обращаться с другими программами генерации парсеров. Каждый нетерминал БНФ взаимнооднозначно переводится в функцию, которая, конечно, громоздковата по сравнению с описанием в БНФ (это можно в дальнейшем исправить, сделав функцию, делающую разбор по регулярному выражению, аналогично как в <boost/xpressive>), но зато в нее можно добавить любую проверку и обработку данных. Все это можно делать как со строками, так и с потоками в одинаковой форме. Поток ввода по умолчанию готов к вводу по умолчанию, а операторы >>, аналогичные таким же из стандартной библиотеки, дают возможность использовать эту библиотеку вместо стандартной библиотеки ввода.
Как с помощью forward_stream делать токенезацию, я попробую рассказать и показать в следующей статье.
