
Помимо того, что Splunk может собирать логи практически из любых источников и строить аналитические отчеты, дашборды, алерты на основе встроенного языка поисковых запросов SPL, о котором мы писали в предыдущих статьях, Splunk еще имеет очень большую базу бесплатных аддонов и приложений.
Сегодня мы рассмотрим одно из самых популярных, с точки зрения пользователей, приложений — Splunk Machine Learning Toolkit.
Сразу скажу, что Splunk Machine Learning Toolkit узко специализирован на задачи и типы данных характерные для Splunk. Он поддерживает только алгоритмы обучения без учителя, и имеет очень конкретное применение.
Так как Splunk в первую очередь ориентирован на машинные данные, то и кейсы реализованные в Machine Learning Toolkit направленны на эту специфику. Далее мы подробно рассмотрим каждый кейс, но сначала кратко про установку.
Где взять?
Само приложение бусплатно доступно для скачивания на Splunkbase, но так как все Machine Learning алгоритмы крутятся на Python, то перед установкой вам потребуется установить Python for Scientific Computing Add-on, о так же бесплатен и устанавливается легко и быстро. Все инструкции здесь.
Возможности применения
Splunk в этом приложении реализовал 6 кейсов применения возможностей Machine Learning с базовыми статистическими алгоритмами:
1. Predict Numeric Fields
Этот модуль делает прогнозирование значений числовых полей, на основе комбинации значений других полей в этом событии.
Пример:
Мы имеем данные о количестве пользователей, использующих различные информационные системы (CRM, CloudDrive, WebMail, Remote Access и другие) в рамках компании за каждый день.
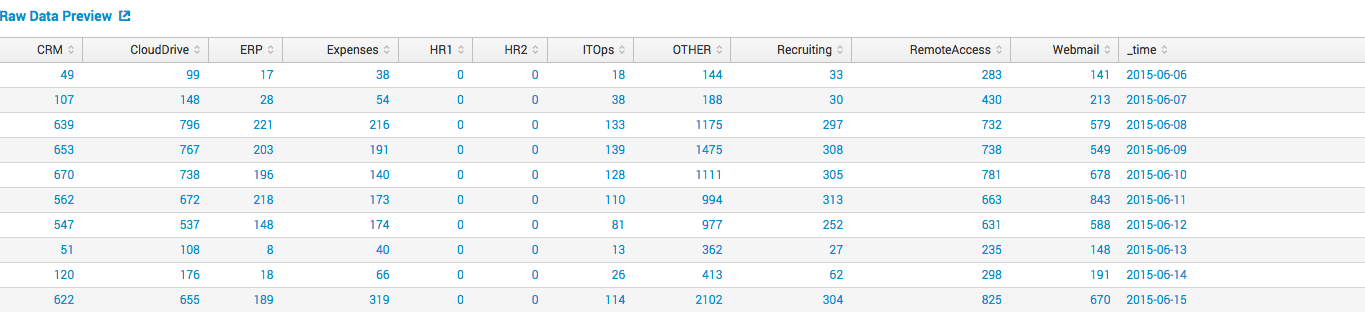
Все эти данные Splunk легко может собрать и организовать в табличку как на картинке. Мы хотим спрогнозировать количество VPN пользователей на основе данных из других полей (CRM, CloudDrive, HR1, WebMail), для этого мы можем построить модель на основе линейной регрессии.
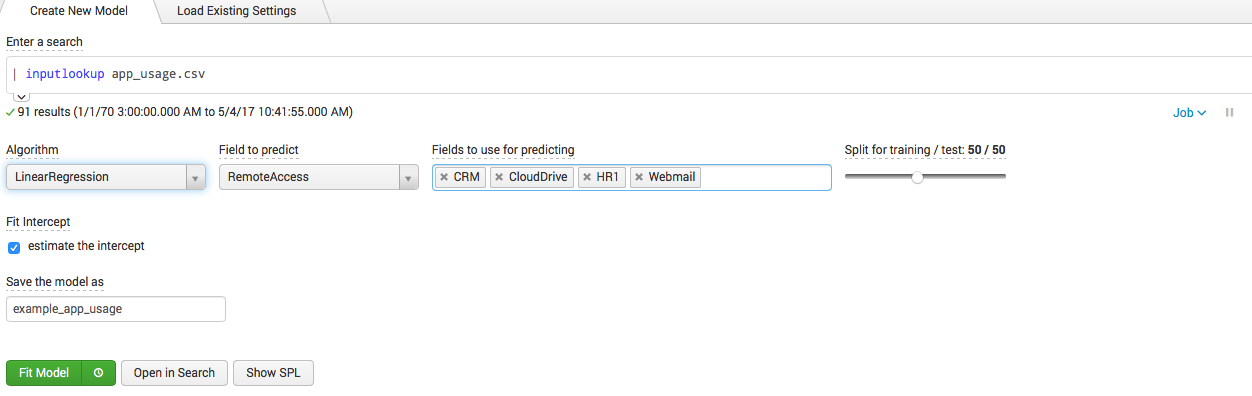
Понятно, что мы можем менять зависимые поля, и сам алгоритм. Помимо линенйной регрессии есть еще несколько популярных алгоритмов.

После чего нажимаем fit model и получаем все выкладки, причем как формате таблицы,
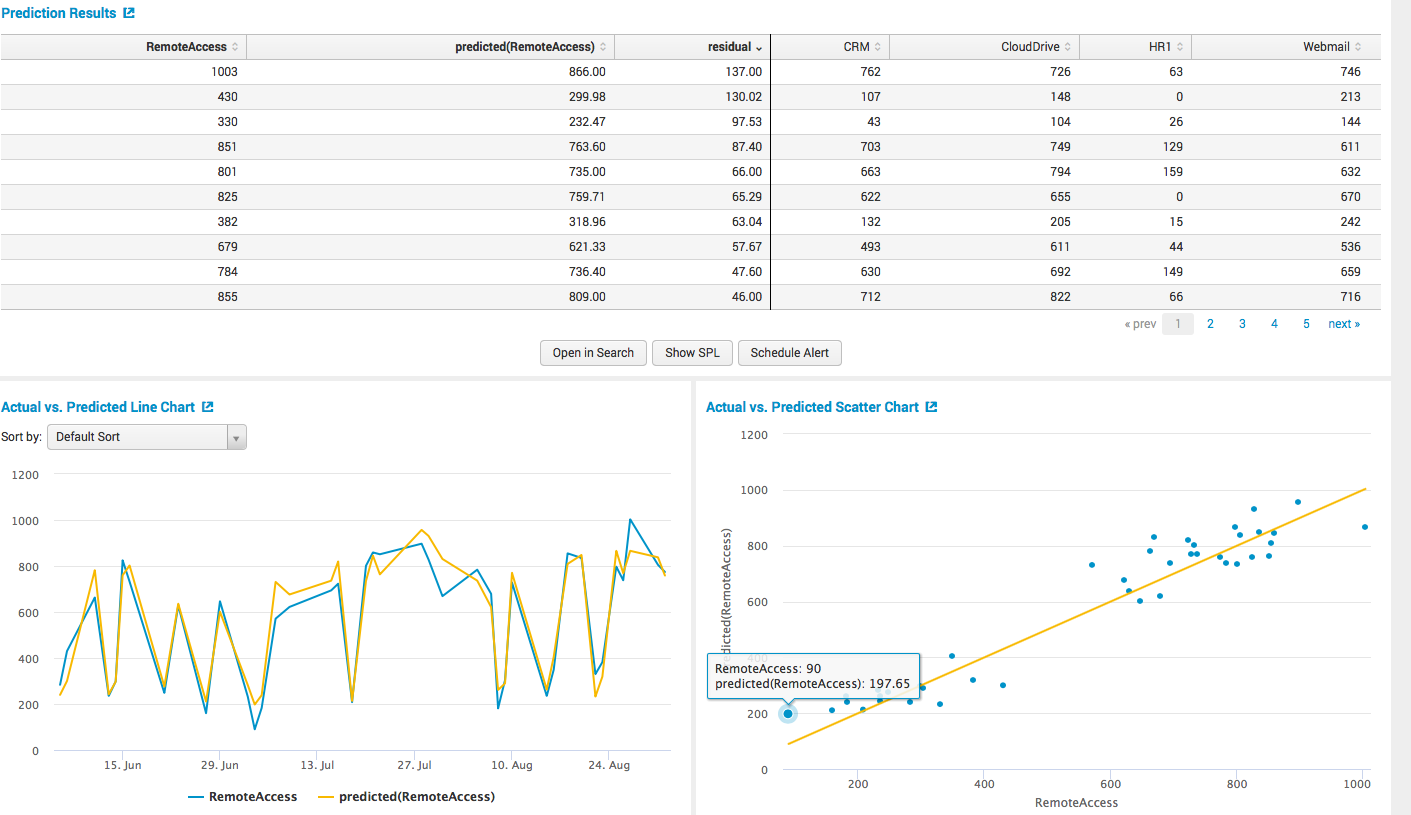
так и графически.
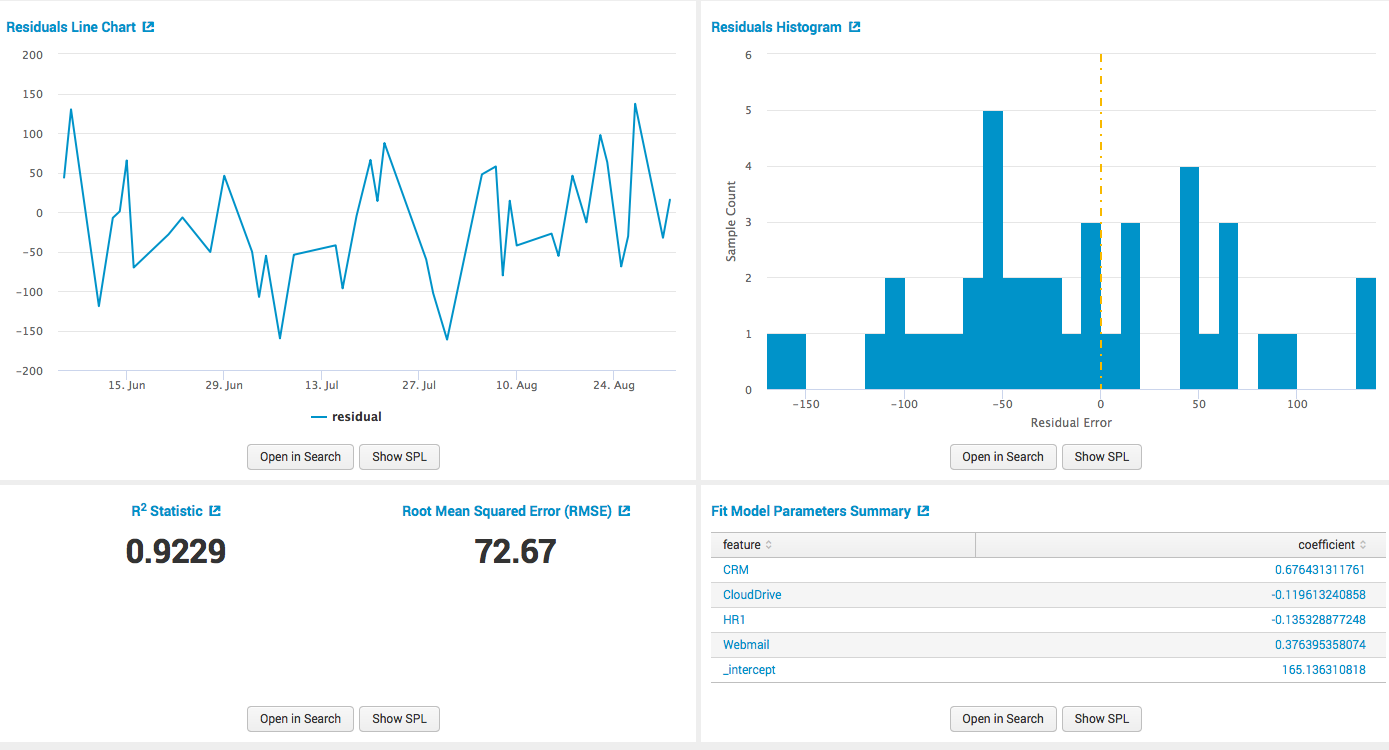
Дальше, когда мы построили модель, мы можем применять ее результаты в других запросах, выносить на дашбодры, строить по ним алерты и прочее.
2. Detect Numeric Outliers
Данный модуль выявляет аномальные значения на основе предыдущих данных по этому полю.
Пример:
У нас есть данные о максимальном времени ответа сервера на запросы клиентов за каждые 10 минут, которые Splunk легко собирает с сервера или серверов и представляет в виде таблички:
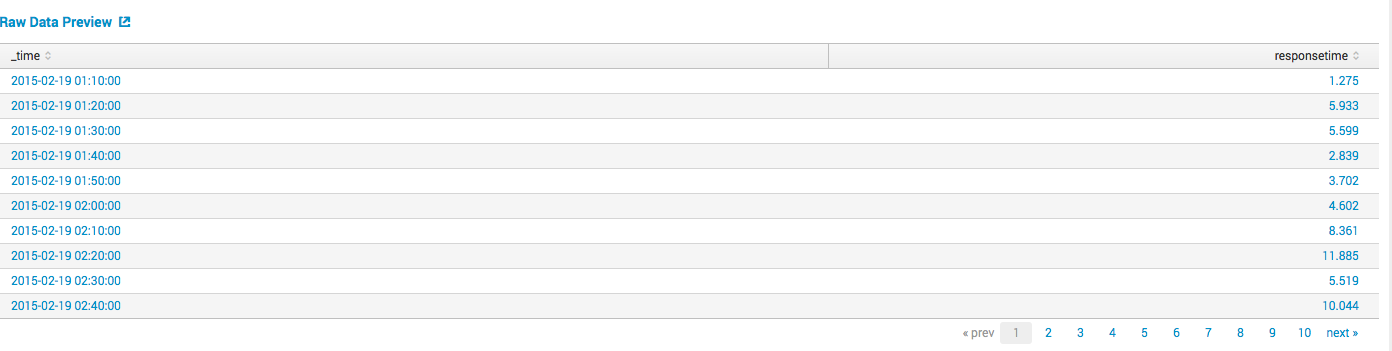
Мы хотим найти аномалии, то есть события когда время отклика было очень долгим, ну или очень быстрым, на основе исторических данных. Splunk предлагает три меры вариации для выявления аномалий (SD — Standard Deviation, IQR — Interquartile Range, mad- Median Absolute Deviation). Построим модель на основе стандартного отклонения:

После чего получаем результаты:
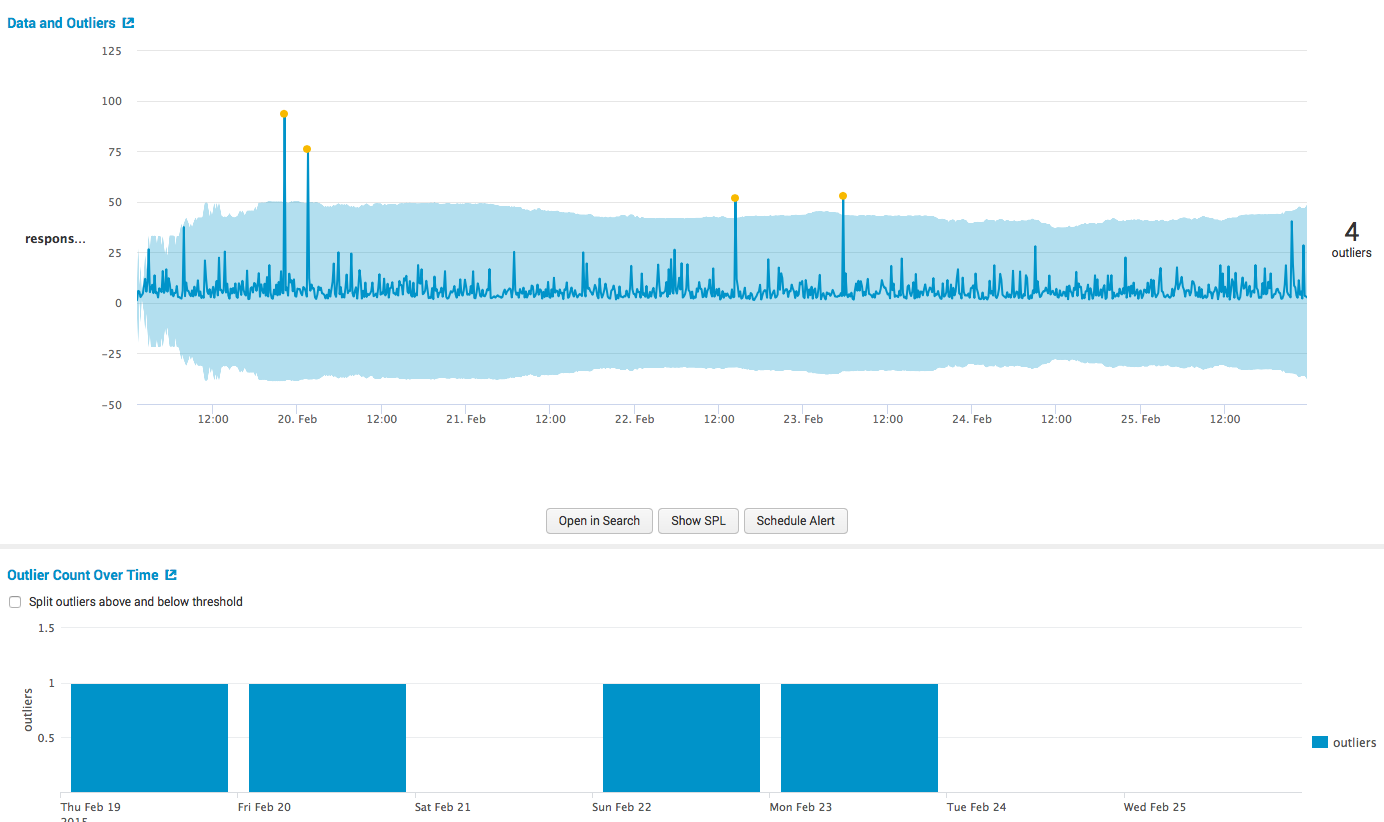
и основные выкладки, как в табличном так и в графическом виде.
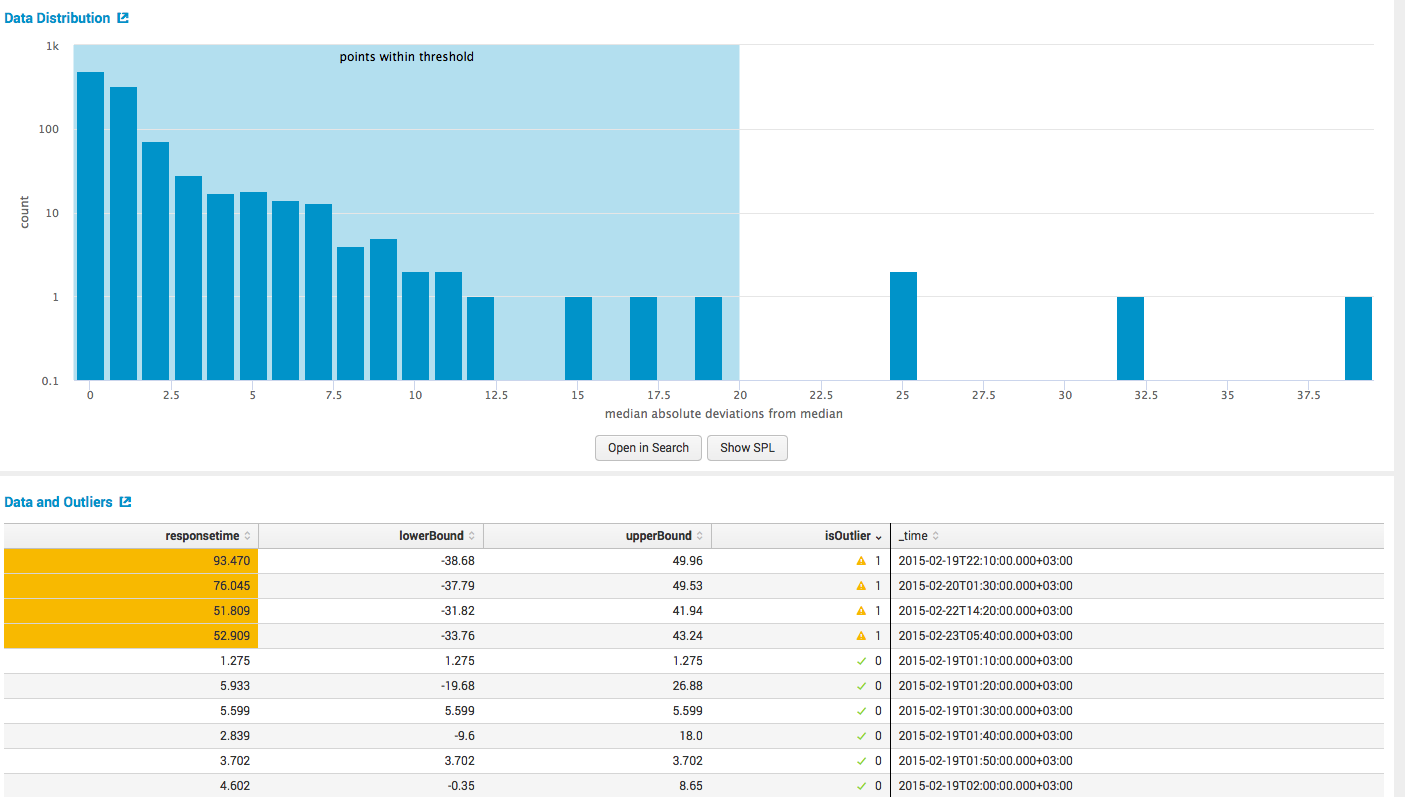
3. Forecast Time Series
Данный модуль предназначен для прогнозирования временных рядов, то есть на основе прошлых данных спрогнозировать будущие.
Основные алгоритмы следующие:
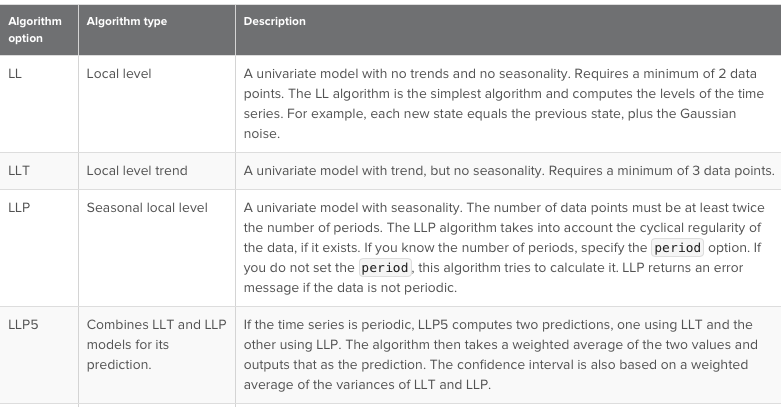
Пример:
У нас есть данные о количестве пересылаемого трафика пользователем, или сервером или шлюзом, по сути не важно откуда.
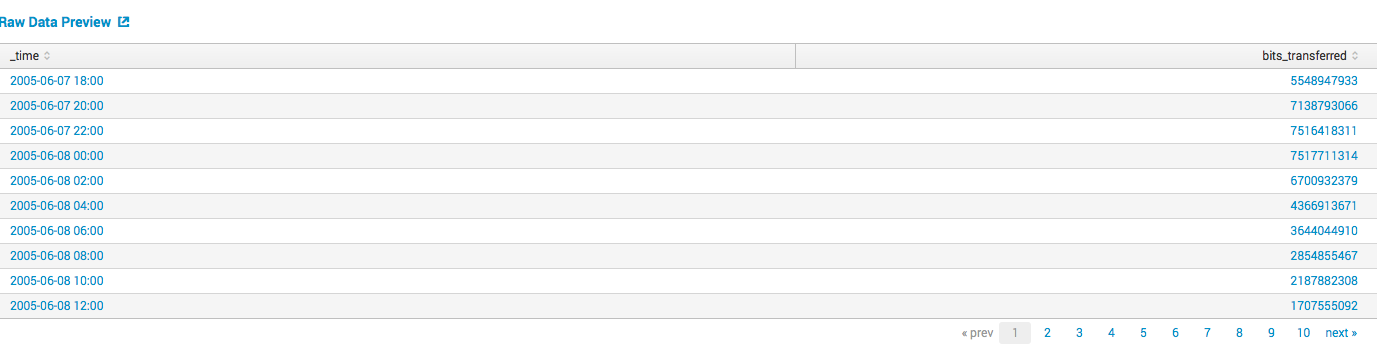
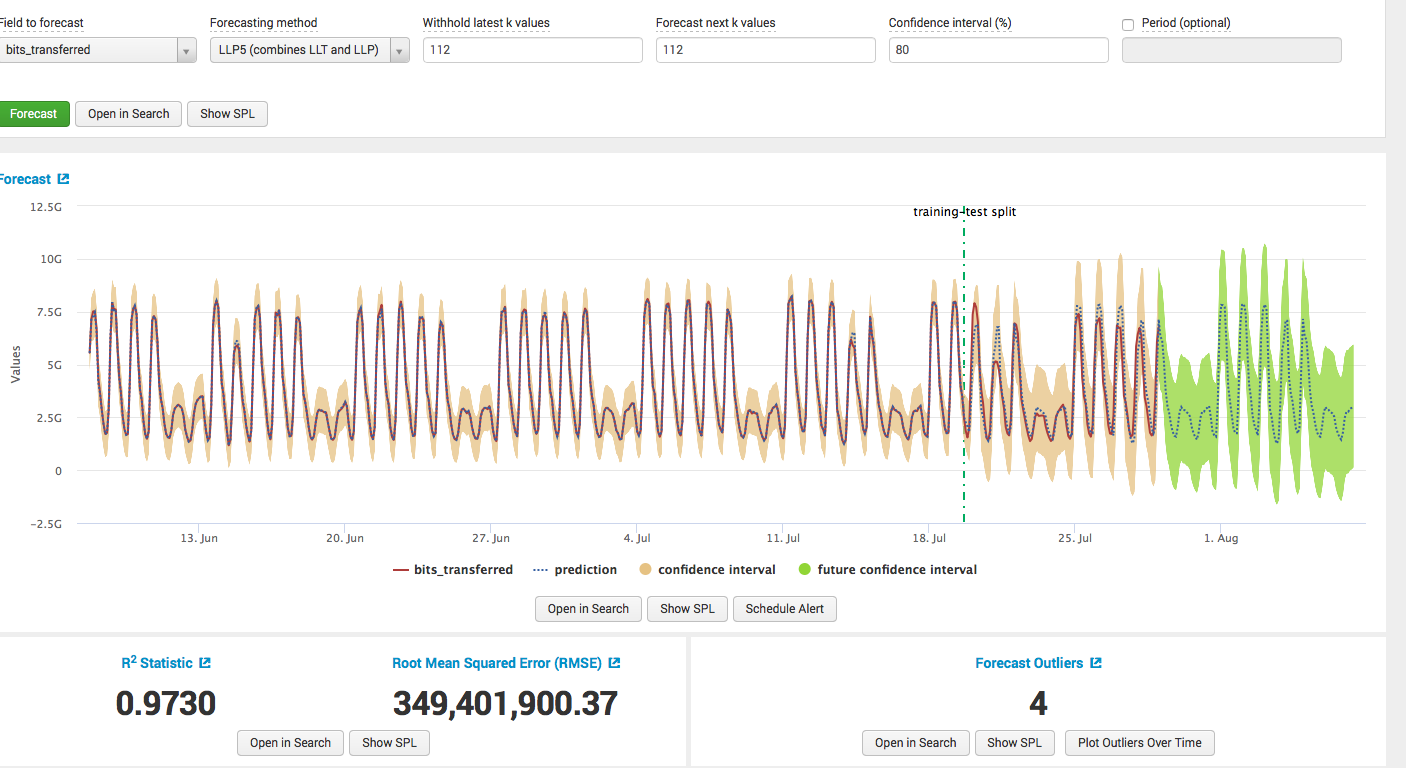
Мы хотим спрогнозировать количество трафика в будущем.
Строим модель: выбираем алгоритм, выбираем обучающую выборку, выбираем количество значений для прогноза, и получаем результаты с выкладками о качестве модели.
4. Predict Categorical Fields
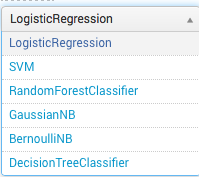
Данный модуль предназначен для прогнозирования категориальной, то есть качественной переменной на основе других полей в этом событии.
Основные алгоритмы следующие (описание здесь):
Пример:
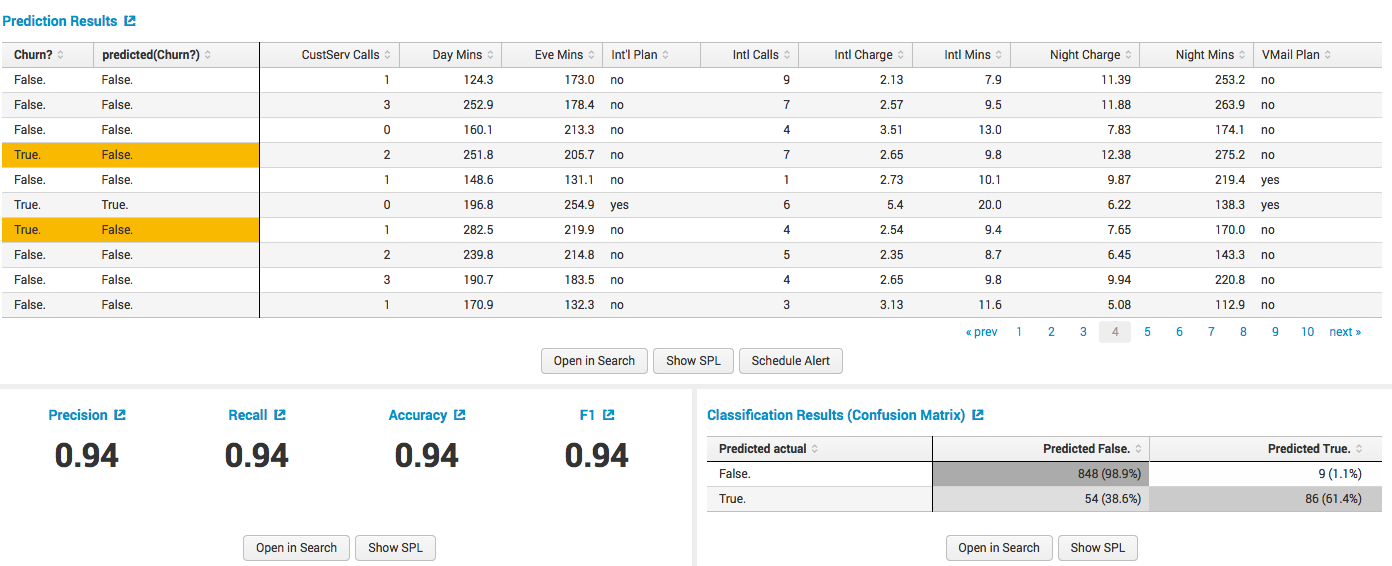
Есть данные телеком оператора с информацией о клиентах (количество внутренних и внешних вызовов, стоимость, ночные звонки, наличие специальных тарифов и прочее). Главное, что есть в этих данных — это поле Churn?, которое показывает ушел от нас клиент или остался. Именно его мы и хотим прогнозировать, на основе вышеперечисленных полей.
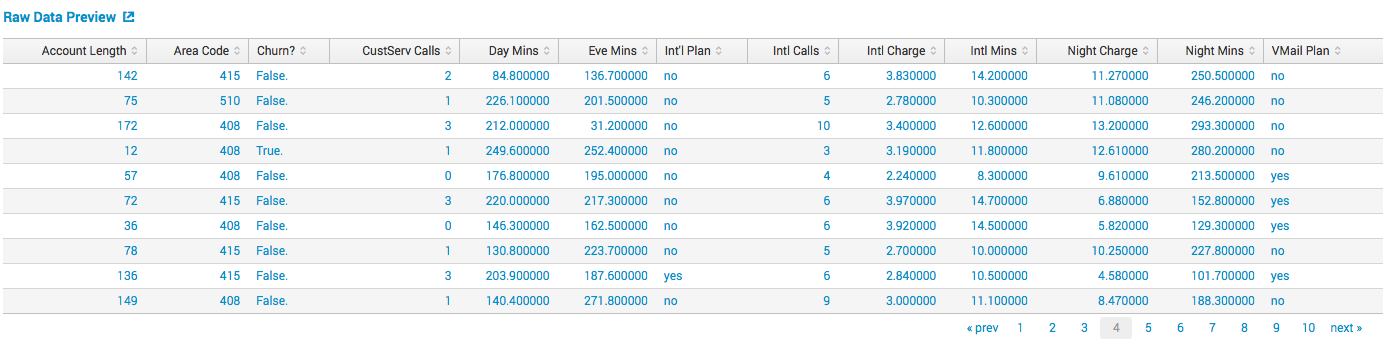
Строим модель: выбираем алгоритм, выбираем зависимые переменные, размер обучающей выборки и прочее возможные параметры в зависимости от алгоритма:

Получаем результаты обучения с данными о качестве модели:
5. Detect Categorical Outliers
Модуль предназначенный для поиска аномалий на основе анализа значений полей в событии, алгоритм определения аномалий здесь.
Пример:
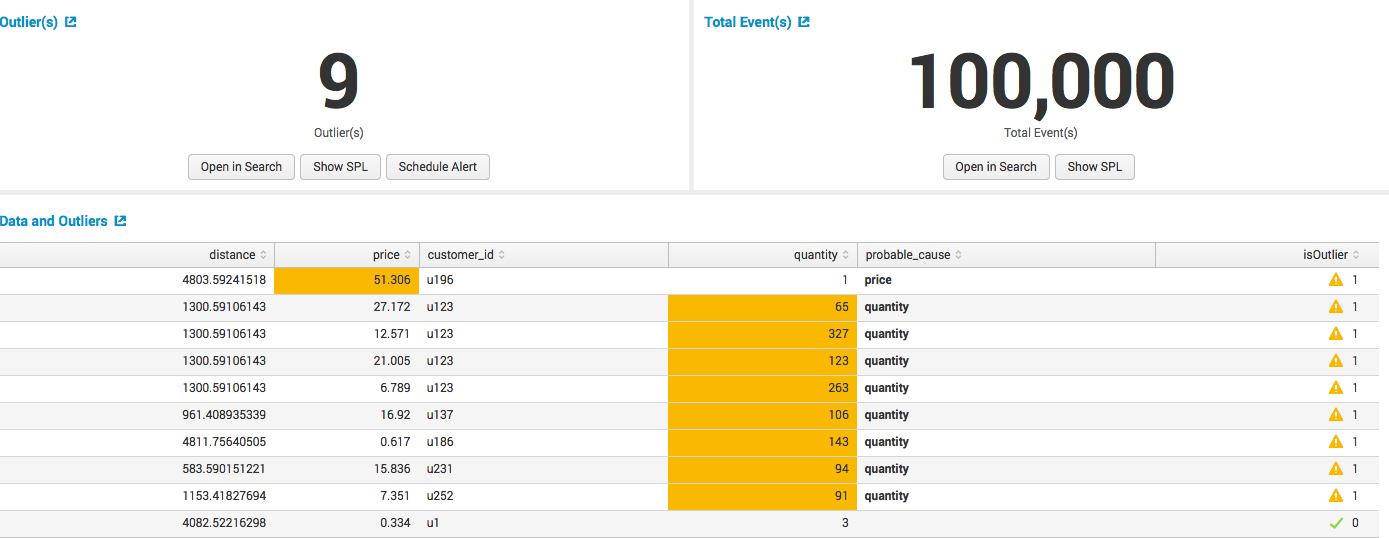
У нас есть данные с информацией о покупках в супермаркете и мы хотим найти аномальные транзакции.

Выбираем поля по которым мы хотим определять аномалии:
Получаем результат с найденными аномалиями:
6. Cluster Numeric Events
Модуль, позволяющий производить кластеризацию событий. Наверно самый слабый модуль, с точки зрения популярности использования.
Пример:
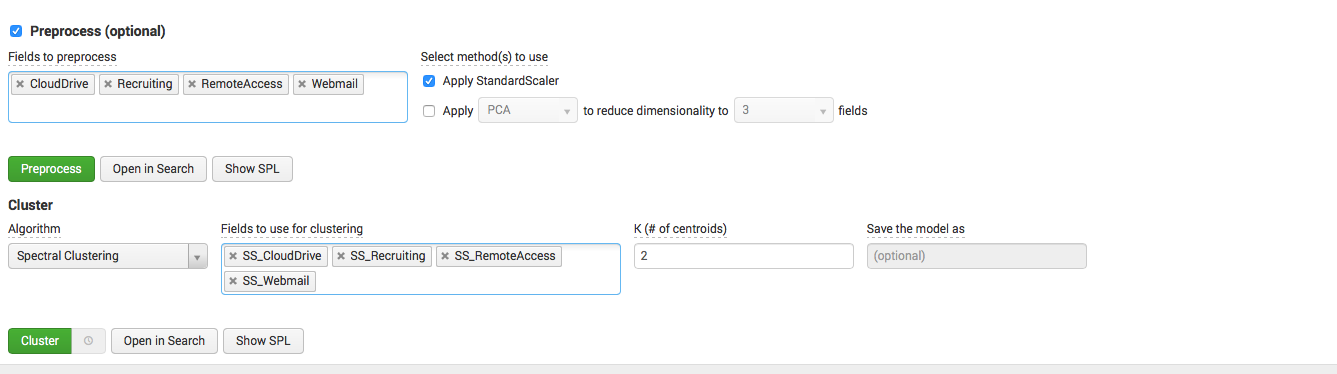
У нас есть данные из примера 1 о количестве пользователей, использующих различные информационные системы. Мы хотим определить кластеризовать их.
Модель: выбираем поля для кластеризации, нормализуем их, выбираем алгоритм и зависимые поля, а также указываем количество кластеров.
Смотрим, что получилось:
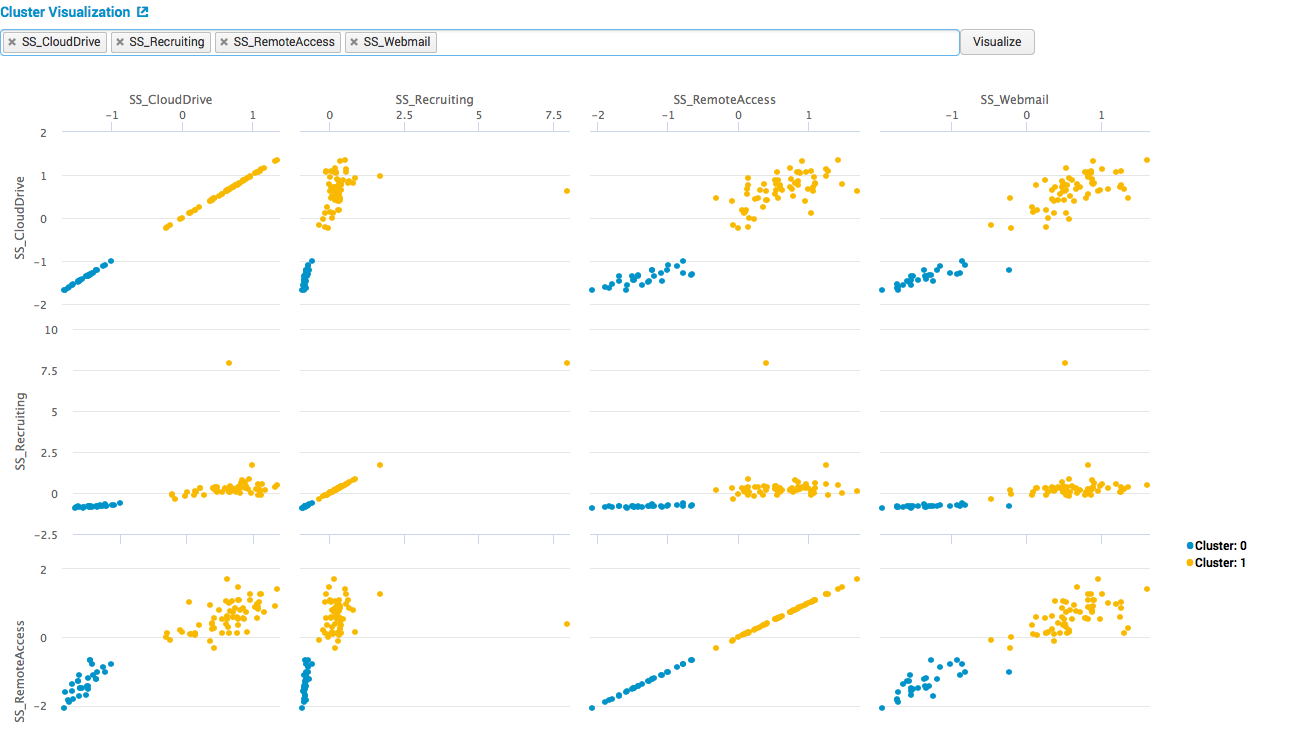
На картинках видим 2 четких кластера, дальше если заниматься интерпретацией результатов можно понять, что первый кластер — это будни, и много пользователей во выбранных системах, второй — выходные дни, и мало пользователей.
Слабость этого модуля также заключается в том, что в нем нет никаких метрик качества построения модели.
Итоги
- Splunk очень хорош тем, что все эти таблички, которые мы получаем на вход в каждую модель он создает сам из огромного количества логов из различных систем, что на самом деле не очень просто (он их собирает, и хранит, и предобрабатывает)
- Если вам нужен быстрый статистический анализ, то есть базовые операции Machine Learning — никуда ходить не надо
- Это не конечный результат, дальше может быть отдельный workflow, алертинг например, или уход в дашборд
- У Splunk открытый API и если Вам не хватает алгоритмов, то можно их подгрузить из открытых Python библиотек, информация как это сделать тут
- Splunk может также отдать результаты наружу, например по тому же API

