
Написать сетевой сервис на Go очень просто: в стандартной библиотеке есть куча инструментов, а если чего-то и не хватает, то на Github есть много модных библиотек для удовлетворения большинства нужд.
Но что, если необходимо написать с десяток разных сервисов, работающих в одной инфраструктуре?
Если каждый демон будет использовать все свежие разнообразные «смузи»-технологии, получится «зоопарк», который сложно и дорого поддерживать, не говоря уже о добавлении в них новой функциональности.
У нас в Badoo крутятся >30 самописных демонов, написанных на разных языках, и ~10 из них – на Go. Все эти демоны работают на порядка 300 серверах. Как мы к этому пришли, не получив в итоге «зоопарк», как админы с мониторингом умудряются спать спокойно, не ограничивая при этом никого в смузи, а девелоперы, QA и релизеры живут дружно и до сих пор не переругались – читайте под катом.
В Badoo Go впервые появился примерно в 2014 году, когда перед нами встала задача быстро написать демон, который ищет пересечения между координатами пользователей. Тогда последняя версия Go была 1.3, и поэтому мы долго боролись с GC-паузами, о чём даже сделали доклад на Go-митапе у нас в офисе.
С тех пор у нас появляется всё больше и больше демонов, написанных на Go. В основном это то, что раньше было бы написано на C, но порой и то, что не так хорошо ложится на PHP (например, наш асинхронный прокси или планировщик ресурсов нашего «облака»).
Все запросы от клиентских приложений у нас обслуживает PHP, который ходит в наши разнообразные самописные и несамописные сервисы. Упрощённо это выглядит так:
Хотя из этого правила и есть некоторые исключения, в целом для всех наших демонов на Go справедливо следующее:
- Они не «торчат наружу» в интернет
- Основной «пользователь» демона – код на PHP.
Все наши демоны вне зависимости от языка их написания выглядят одинаково «извне» с точки зрения протокола, логов, статистики, деплоя и прочего. Это упрощает жизнь админам, релиз-инженерам, QA и PHP-разработчикам.
Поэтому с одной стороны, многие подходы, которые мы используем для демонов на Go, были продиктованы уже существующими подходами к написанию демонов на C/ C++, а с другой стороны, многое из этой статьи справедливо не только для Go, но и для любого нашего демона.
Ниже я расскажу, как устроены наши основные инфраструктурные части и как они отражаются в Go-коде.
Протокол
Когда речь заходит о клиент-серверном взаимодействии, встаёт вопрос о протоколе. Мы взяли за основу Google Protobuf. Наш протокол похож на упрощённую версию gRPC, поэтому нам неоднократно задавали вопросы из разряда «зачем нужно было изобретать велосипед?». Скорее всего, сегодня мы бы действительно воспользовались gRPC, но в те времена (2008 год) его ещё не существовало, а менять одно на другое сейчас нет никакого смысла.
Protobuf заворачивает в бинарное представление только тело сообщения и при этом не сохраняет его тип. Поэтому каждый раз, когда клиент обращается к серверу с запросом, сервер должен понять, какое это именно protobuf-сообщение и какой метод необходимо выполнить. Для этого перед protobuf-сообщением мы добавляем идентификатор типа сообщения и длину сообщения. Идентификатор однозначно даёт понять, какой именно GPB-message пришёл, а длина позволяет сразу же аллоцировать буфер нужного размера.
В итоге один вызов в терминах протокола выглядит так:
- 4 байта – длина сообщения N (число в network byte order);
- 4 байта – идентификатор типа сообщения (тоже);
- N байтов – тело сообщения.
Для того чтобы и клиент, и сервер имели одинаковую информацию об идентификаторах сообщений, мы их так же храним в proto-файле в виде enum’ов со специальными именами request_msgid и response_msgid. Например:
enum request_msgid {
REQUEST_RUN = 1;
REQUEST_STATS = 2;
}
// в общем случае на один request могут быть разные response, и наоборот
enum response_msgid {
RESPONSE_GENERIC = 1; // например, таким response у нас может ответить любой метод, обычно мы это используем для передачи ошибок
RESPONSE_RUN = 2;
RESPONSE_STATS = 3;
}
message request_run {
// ...
}
message response_run {
// ...
}
message request_stats {
// ...
}
// ...За всю эту протокольную часть отвечает наша библиотека, которую мы называем gpbrpc. Её можно грубо разделить на две части:
- одна часть – это кодогенератор, который на основе
request_msgidиresponse_msgidгенерирует карты соответствий id => message, шаблоны методов-обработчиков, карты их вызовов с приведением типов и ещё некоторый необходимый нам код; - вторая часть занимается разбором всех этих данных, пришедших по сети, и вызовом соответствующих им методов-обработчиков.
Кодогенератор из первой части реализован в виде плагина к Google Protobuf.
Примерно так выглядит автоматически сгенерированный обработчик для приведённого выше proto-файла:
// интерфейс, содержащий совокупность методов, сгенерированных из proto-файла
type GpbrpcInterface interface {
RequestRun(rctx gpbrpc.RequestT, request *RequestRun) gpbrpc.ResultT
RequestStats(rctx gpbrpc.RequestT, request *RequestStats) gpbrpc.ResultT
}
func (GpbrpcType) Dispatch(rctx gpbrpc.RequestT, s interface{}) gpbrpc.ResultT {
service := s.(GpbrpcInterface)
switch RequestMsgid(rctx.MessageId) {
case RequestMsgid_REQUEST_RUN:
r := rctx.Message.(*RequestRun)
return service.RequestRun(rctx, r)
case RequestMsgid_REQUEST_STATS:
r := rctx.Message.(*RequestStats)
return service.RequestStats(rctx, r)
}
}
// в закомментированном виде генерируются шаблоны будущих методов-обработчиков
/*
func ($receiver$) RequestRun(rctx gpbrpc.RequestT, request *$proto$.RequestRun) gpbrpc.ResultT {
// ...
}
func ($receiver$) RequestStats(rctx gpbrpc.RequestT, request *$proto$.RequestStats) gpbrpc.ResultT {
// ...
}
*/gogo/protobuf
В документации к Protobuf Google рекомендует использовать эту библиотеку для Go. Но, к сожалению, она генерирует плохо ложащийся на GC-код. Пример из документации:
message Test {
required string label = 1;
optional int32 type = 2 [default=77];
}превращается в
type Test struct {
Label *string `protobuf:"bytes,1,req,name=label" json:"label,omitempty"`
Type *int32 `protobuf:"varint,2,opt,name=type,def=77" json:"type,omitempty"`
}Каждое поле структуры стало указателем. Это необходимо для optional-полей: для них нужно различать случай отсутствия поля от случая, когда в поле содержится нулевое значение.
Даже если вам это не нужно, библиотека не позволяет управлять наличием указателей в сгенерированном коде. Но не всё так плохо: у неё есть форк gogoprotobuf, в котором это поддерживается. Для этого необходимо указать соответствующие опции в proto-файле:
message Test {
required string label = 1 [(gogoproto.nullable) = false];
optional int32 type = 2 [(gogoproto.nullable) = false];
}Избавление от указателей было особенно актуально для Go до версии 1.5, когда GC-паузы были гораздо длиннее. Но и сейчас это может дать весомый прирост (иногда в разы) к производительности нагруженных сервисов.
Кроме nullable, библиотека позволяет добавлять большое количество других опций генерации, влияющих как на производительность, так и на удобство получаемого кода. Например, gostring сохраняет текущую структуру со значениями в синтаксисе Go, что может быть удобно для отладки или написания тестов.
Подходящий набор опций зависит от конкретной ситуации. Мы почти всегда используем как минимум nullable, sizer_all, unsafe_marshaler_all, unsafe_unmarshaler_all. Кстати, опции, имеющие вариант с суффиксом _all, можно применить сразу ко всему файлу, не дублируя их на каждое поле:
option (gogoproto.sizer_all) = true;
message Test {
required string label = 1;
optional int32 type = 2;
}JSON
В Google Protobuf прекрасно практически всё, но поскольку это бинарный протокол, его сложно отлаживать.
Если нужно найти проблемы на уровне взаимодействия готового клиента и сервера, то можно, например, воспользоваться gpbs-dissector для Wireshark. Но это не подходит в случае разработки новой функциональности, для которой ещё нет ни клиента, ни сервера.
По сути, чтобы написать какой-то тестовый запрос в сервис, нужен клиент, который сможет завернуть его в бинарное сообщение. Писать такой тестовый клиент для каждого демона хоть и не очень сложно, но неудобно и рутинно. Поэтому наш gpbrpc умеет обрабатывать и JSON-подобное представление протокола на другом, отличном от gpb-интерфейса, порту. Вся обвязка для этого генерируется автоматически (подобным образом, как описано выше для protobuf).
В результате в консоли можно написать запрос в текстовом виде и тут же получить ответ. Это удобно для отладки.
pmurzakov@shell1.mlan:~> echo 'run {"url":"https://graph.facebook.com/?id=http%3A%2F%2Fhabrahabr.ru","task_hash":"a"}' | netcat xtc1.mlan 9531
run {
"task_hash": "a",
"task_status": 2,
"response": {
"http_status": 200,
"body": "{\"og_object\":{\"id\":\"627594553918401\",\"description\":\"Хабрахабр – самое крупное в Рунете сообщество людей, занятых в индустрии высоких технологий. Уникальная аудитория, свежая информация, конструктивное общение и коллективное творчество – всё это делает Хабрахабр самым оригинальным IT-проектом в России.\",\"title\":\"Лучшие публикации за сутки / Хабрахабр\",\"share\":{\"comment_count\":0,\"share_count\":2456},\"id\":\"http:\\/\\/habrahabr.ru\"}",
"response_time_ms": 179
}
}Если ответ объёмный, и из него нужно выбрать какую-то часть или просто необходимо его как-то преобразовать, можно воспользоваться консольной утилитой jq.
Конфиги
Вообще к конфигам обычно предъявляют два основных требования:
- удобочитаемость;
- возможность описать структуру.
Чтобы не вводить для этого ещё новых сущностей, мы воспользовались тем, что уже есть: protobuf – структура, читаемость – его JSON-представление.
У нас уже есть вся обвязка для protobuf и генераторы парсеров его JSON-представления для дебага (см. предыдущий раздел). Остаётся только добавить proto-файл для конфига и «скормить» его этому разборщику.
На самом деле, всё чуточку сложнее: так как нам важно максимально стандартизировать разные демоны, в конфиге существует часть, которая одинакова для всех демонов. Она описывается общим protobuf-сообщением. Итоговый конфиг – это совокупность стандартизированной части и того, что специфично для конкретного демона.
Этот подход хорошо ложится на embedding:
type FullConfig struct {
badoo.ServiceConfig
yourdaemon.Config
}Пример для наглядности. Общая часть:
message service_config {
message daemon_config_t {
message listen_t {
required string proto = 1;
required string address = 2;
optional bool pinba_enabled = 4;
}
repeated listen_t listen = 1;
required string service_name = 2;
required string service_instance_name = 3;
optional bool daemonize = 4;
optional string pid_file = 5;
optional string log_file = 6;
optional string http_pprof_addr = 7; // net/http/pprof + expvar address
optional string pinba_address = 8;
// ...
}
}Часть для конкретного демона:
message config {
optional uint32 workers_count = 1 [default = 4000];
optional uint32 max_queue_length = 2 [default = 50000];
optional uint32 max_idle_conns_per_host = 4 [default = 1000];
optional uint32 connect_timeout_ms = 5 [default = 2000];
optional uint32 request_timeout_ms = 7 [default = 10000];
optional uint32 keep_alive_ms = 8 [default = 30000];
}В итоге JSON-конфиг выглядит примерно так:
{
"daemon_config": {
"listen": [
{ "proto": "xtc-gpb", "address": "0.0.0.0:9530" },
{ "proto": "xtc-gpb/json", "address": "0.0.0.0:9531" },
{ "proto": "service-stats-gpb", "address": "0.0.0.0:9532" },
{ "proto": "service-stats-gpb/json", "address": "0.0.0.0:9533" },
],
"service_name": "xtc",
"service_instance_name": "1.mlan",
"daemonize": false,
"pinba_address": "pinbaxtc1.mlan:30002",
"http_pprof_addr": "0.0.0.0:9534",
"pid_file": "/local/xtc/run/xtc.pid",
"log_file": "/local/xtc/logs/xtc.log",
},
// специфичная для конкретного демона часть
"workers_count": 4000,
"max_queue_length": 50000,
"max_idle_conns_per_host": 1000,
"connect_timeout_ms": 2000,
"handshake_timeout_ms": 2000,
"request_timeout_ms": 10000,
"keep_alive_ms": 30000,
}В listen перечисляются все порты, которые будет слушать демон. Первые два элемента с типами xtc-gpb и xtc-gpb/json – для портов того самого gpbrpc и его JSON-представления, о которых я писал выше. А с service-stats-gpb и service-stats-gpb/json мы собираем статистику, о которой пойдёт речь далее.
Статистика
При сборе статистики (как и в случае со стандартизированной частью конфига) нам важно, чтобы каждый демон писал как минимум основные метрики: количество обслуженных запросов, потребление CPU и памяти, сетевой трафик и т. д. Эта типовая статистика собирается с порта service-stats-gpb, она одинакова для всех демонов.
Запрос статистики, по сути, ничем не отличается от обычного запроса к демону, поэтому мы применяем всё те же подходы: статистика описана в терминах gpbrpc, как и обычные запросы. Обработчики этой “стандартизированной” статистики уже есть в нашем фреймворке, поэтому их не нужно писать каждый раз для очередного демона.
По аналогии с конфигами, кроме одинаковой для всех демонов статистики, каждый демон может отдавать ещё и специфичную конкретно для него.
Раз в минуту PHP-клиент-сборщик статистики подключается к демону, запрашивает значения и сохраняет их в time-series-хранилище. На основе этих данных мы строим такие графики:

Значения для пяти первых графиков собираются автоматически со всех демонов, на остальных представлены значения, специфичные для конкретного демона.
У нас принято считать, что статистики много не бывает, и мы стараемся получать максимальное количество данных, чтобы потом было проще разбираться с проблемами и изменениями в них. Поэтому в конфиге можно увидеть параметр pinba_address, это адрес сервера Pinba, в который демон также отправляет статистику.
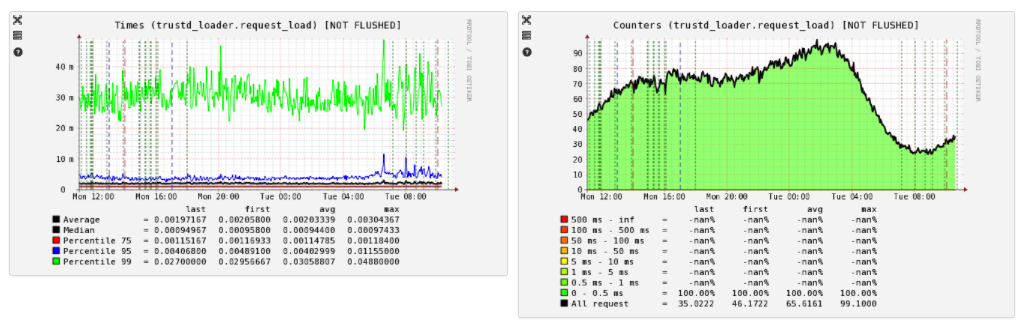
Из Pinba мы строим графики по распределению времени ответа:
Дебаг и профилирование
Ещё в конфиге можно заметить параметр http_pprof_addr. Это порт net/http/pprof – встроенного в Go инструмента, который позволяет легко профилировать код. О нём написано много статей (например, эта и эта), поэтому я не буду останавливаться на подробностях его работы.
Мы оставляем pprof даже в продакшн-сборках демонов. Он не даёт практически никакого оверхеда, пока им не пользуются, но добавляет гибкость: в любой момент можно подключиться и понять, что происходит и на что конкретно тратятся ресурсы.
Кроме того, мы используем expvar, он позволяет одной строкой кода сделать доступными значения любых переменных демона по HTTP в JSON-виде:
expvar.Publish("varname", expvar.Func(func() interface{} { return somevariable }))По умолчанию HTTP-обработчик expvar добавляется в DefaultServeMux и доступен по адресу http://yourhost/debug/vars. Пакет при подключении обладает сайд-эффектом. Он автоматически публикует со всеми параметрами командную строку, при помощи которой был запущен бинарник, а также результат runtime.ReadMemStats().
Осторожно! ReadMemStats() сейчас может приводить к stop-the-world на длительное время, если выделено много памяти. Мой коллега Марко Кевац создал тикет на эту тему, и в версии 1.9 это должно быть исправлено.
Кроме стандартных значений, все наши демоны публикуют ещё множество отладочной информации, наиболее важная – это:
- конфиг, с которым запущен демон;
- значения всех счётчиков статистики, о которой я писал выше;
- данные о том, как был собран бинарник.
С первыми двумя пунктами, я думаю, всё понятно. Последний же даёт информацию о версии Go, под которую был собран демон, хеше git-коммита, времени сборки и другие полезные данные о сборке.
Пример:

Мы делаем это с помощью генерации при сборке файла version.go, в который записывается вся эта информация. Но аналогичного эффекта можно добиться и при помощи ldflags -X.
Логи
В качестве логгера мы используем logrus со своим кастомным форматтером. Файлы логов при помощи Rsyslog и Logstash собираются в Elasticsearch и впоследствии выводятся в дашборде Kibana (ELK).
О том, почему мы выбрали именно эти решения, и о других деталях сборки логов мы уже писали в этой статье, поэтому я не буду повторяться.
Воркфлоу, тесты и прочее
Вся работа ведётся в JIRA. Каждый тикет – отдельная ветка. Для каждой ветки из тикетов TeamCity собирает бинарник. Для сборки мы используем GNU Make, так как, кроме непосредственно компиляции, нам нужно сгенерировать version.go и код для gpbrpc из proto-файлов, а также выполнить ещё ряд задач.
Мы используем Go 1.5 Vendor Experiment, чтобы иметь возможность положить код зависимостей в директорию vendor. Но, к сожалению, пока мы делаем это простым добавлением всех файлов зависимостей в наш репозиторий. В планах есть использование какой-нибудь утилиты для вендоринга. Перспективной выглядит dep, остаётся только дождаться её стабилизации.
После того как тикет проходит ревью, за него берутся ребята из QA-команды. Они пишут функциональные тесты на новые фичи демона и проверяют регрессию. Тесты пишутся на PHP, поскольку в большинстве случаев именно он является клиентом демона в продакшне. Тем самым мы гарантируем, что, если что-то работает в тестах, это будет работать и на продакшне.
Что касается тестов на Go, то они являются опциональными и пишутся по необходимости. Но мы работаем над этим и планируем писать больше тестов на Go (см. постскриптум).
Из тикетов, проверенных QA и готовых к релизу, TeamCity собирает билдовую ветку. Когда она готова к выкладке, разработчик заходит в специальный интерфейс и финиширует её. При этом билдовая ветка мёржится в мастер, и в JIRA-проекте админов создаётся тикет на выкладку.

Шаблон демона
Написать новый демон в наших условиях просто, но тем не менее это требует некоторых шаблонных действий: нужно создать структуру директорий, сделать proto-файл для клиент-серверного протокола, конфиг и proto-файл к нему, написать код старта сервера на основе gpbrpc и прочее. Чтобы не заморачиваться с этим каждый раз, мы сделали репозиторий с шаблонным демоном, в котором есть небольшой bash-скрипт, который на его основе делает новый полноценный демон по этому шаблону.
Заключение
В результате мы получили то, что, даже когда в новом демоне ещё не написано ни строчки кода, он уже готов к нашей инфраструктуре:
- одинаковым образом конфигурируется;
- пишет статистику и логи;
- общается по такому же производительному (protobuf) и легко читаемому (JSON) протоколу, как и остальные демоны (в том числе написанные на других языках);
- одинаковым образом обслуживается и мониторится.
Это позволяет нам не тратить ресурсы разработчиков и при этом получать предсказуемые и легкоподдерживаемые сервисы.
На этом всё. А как вы пишете демоны на Go? Добро пожаловать в комментарии!
P. S. Пользуясь случаем, хочу сказать, что мы ищем таланты.
Многое уже написано на Go, но ещё больше предстоит написать, поскольку мы хотим развивать это направление. И мы ищем толкового человека, который может нам в этом помочь.
Если вы – Go-разработчик и немного знаете C/C++, пишите mkevac в личку или на почту: m.kevac@corp.badoo.com (в его команду мы присматриваем коллегу).
