Примеры использования и тестирование потоко-безопасного указателя и contention-free shared-mutex
В этой статье мы покажем: дополнительные оптимизации, примеры использования и тестирование разработанного нами потоко-безопасного указателя с оптимизированным разделяемым мьютексом contfree_safe_ptr<T> – это эквивалентно safe_ptr<T, contention_free_shared_mutex<>>
В конце покажем сравнительные графики тестов нашего thread-safe указателя и одних из лучших lock-free алгоритмов из libCDS на процессорах Intel Core i5/i7, Xeon, 2 x Xeon.
Три связанные статьи:
- Делаем любой объект потокобезопасным
- Ускоряем std::shared_mutex в 10 раз
- Потокобезопасный std::map с производительностью lock-free map
→ Моя статья на английском
→ Примеры и тесты из всех трех статей
Вы можете найти библиотеку libCDS с которой мы будем сравнивать наше решение по ссылке: github.com/khizmax/libcds
Во всех тестах в этой статье используется данный commit из libCDS: github.com/khizmax/libcds/tree/5e2a9854b0a8625183818eb8ad91e5511fed5898
Различная гранулярность блокировок
Сначала покажем, как оптимально использовать shared-mutex, на примере работы с таблицей (массив структур). Обратимся к опыту промышленных СУБД. Например, в СУБД MSSQL применяются блокировки различной гранулярности – блокировка: одной или нескольких строк, страницы, экстента (extent), одной секции таблицы, индекса, всей таблицы, всей базы данных. https://technet.microsoft.com/en-us/library/ms189849(v=sql.105).aspx
Действительно, если мы долго работаем с одной строкой и нам важно, чтобы в это время строка не была изменена другим потоком, то нет необходимости все это время блокировать всю таблицу – достаточно заблокировать только 1 строку.
- Блокируем всю таблицу разделяемой блокировкой (shared)
- Ищем нужную строку или несколько строк
- Затем блокируем найденную строку
- Разблокируем таблицу
- И работаем с заблокированной строкой
Тогда другие потоки смогут параллельно работать с остальными строками.
До сих пор мы использовали только блокировку на уровне таблицы, т.е. блокировали одну или несколько таблиц.
Или автоматически блокировались все таблицы, используемые в выражении – до его полного завершения.
(*safe_map_1)["apple"].first = "fruit"; // locked Table-1 (safe_map_1) // unlocked Table-1 safe_map_1->at("apple").second = safe_map_1->at("apple").second * 2; // locked Table-1 (safe_map_1) // unlocked Table-1 safe_map_1->at("apple").second = safe_map_2->at("apple").second*2; // locked Table-1(safe_map_1) and Table-2(safe_map_2) // unlocked Table-1 and Table-2
В других случаях мы вручную блокировали одну или несколько таблиц используя RAII-объекты блокировки до окончания области видимости (block scope) этих блокировок (пока они не будут уничтожены):
{ std::lock_guard<decltype(safe_map_1)> lock(safe_map_1); // locked Table-1 (safe_map_1) (*safe_map_1)["apple"].first = "fruit"; safe_map_1->at("apple").second = safe_map_1->at("apple").second * 2; // unlocked Table-1 } { lock_timed_any_infinity lock_all(safe_map_1, safe_map_2); // locked Table-1(safe_map_1) and Table-2(safe_map_2) safe_map_1->at("apple").second = safe_map_2->at("apple").second*2; //locked Table-1(safe_map_1) and Table-2(safe_map_2) safe_map_1->at("potato").second = safe_map_2->at("potato").second*2; //locked Table-1(safe_map_1) and Table-2(safe_map_2) // unlocked Table-1 and Table-2 }
Давайте рассмотрим пример, в котором случайным образом будем выбирать индекс для вставки, затем случайным образом одну из четырех операций (insert, delete, update, read) и выполнять её над потоко-безопасным объектом с типом contfree_safe_ptr<std::map>.
Пример: [37] coliru.stacked-crooked.com/a/5b68b65bf2c5abeb
В этом случае мы будем накладывать следующие блокировки на таблицу:
- Insert – eXclusive lock
- Delete – eXclusive lock
- Update – eXclusive lock
- Read – Shared lock
Для операций Update или Read мы делаем:
- Блокируем всю таблицу (xlock для Update, slock для Read)
- Ищем нужную строку, читаем или изменяем её
- Разблокируем таблицу
Код одной итерации нашего примера-1:
int const rnd_index = index_distribution(generator); // 0 - container_size int const num_op = operation_distribution(generator);// insert_op, update_op, delete_op, read_op switch (num_op) { case insert_op: { safe_map->emplace(rnd_index, (field_t(rnd_index, rnd_index))); // insert with X-lock on Table break; } case delete_op: { size_t erased_elements = safe_map->erase(rnd_index); // erase with X-lock on Table } break; case update_op: { auto x_safe_map = xlock_safe_ptr(safe_map); // X-lock on Table auto it = x_safe_map->find(rnd_index); if (it != x_safe_map->cend()) { it->second.money += rnd_index; // still X-lock on Table (must necessarily be) } } break; case read_op: { auto s_safe_map = slock_safe_ptr(safe_map); // S-lock on Table auto it = s_safe_map->find(rnd_index); if (it != s_safe_map->cend()) { volatile int money = it->second.money; // still S-lock on Table (must necessarily be) // volatile here only to avoid optimization for unused money-variable } } break; default: std::cout << "\n wrong way! \n"; break; }
Теперь сделаем так, чтобы во время операции Update таблица блокировалась блокировкой чтения (shared), вместо блокировки изменения (exclusive). Это сильно ускорит операции Update при использовании нашего «write contention free shared mutex», который мы разработали ранее.
В этом случае множество потоков смогут одновременно проводить операции Update и Read над одной таблицей. Например, один поток читает одну строку, а другой поток изменяет другую строку. Но если один поток пытается изменить ту же строку, которую читает другой поток, то чтобы избежать Data-races мы должны блокировать саму строку при её чтении и при её изменении.
Пример: [38] coliru.stacked-crooked.com/a/89f5ebd2d96296d3
Теперь для операций Update или Read мы делаем:
- Блокируем всю таблицу разделяемой блокировкой (shared)
- Ищем нужную строку или несколько строк
- Затем блокируем найденную строку (xlock для Update, slock для Read)
- И работаем с заблокированной строкой (X/S-lock) и заблокированной таблицей (S-lock)
- Разблокируем строку
- Разблокируем таблицу
Diff — что мы поменяли:

Код одной итерации нашего примера-2:
int const rnd_index = index_distribution(generator); // 0 - container_size int const num_op = operation_distribution(generator);// insert_op, update_op, delete_op, read_op switch (num_op) { case insert_op: { safe_map->emplace(rnd_index, (field_t(rnd_index, rnd_index))); // insert with X-lock on Table break; } case delete_op: { size_t erased_elements = safe_map->erase(rnd_index); // erase with X-lock on Table } break; case update_op: { auto s_safe_map = slock_safe_ptr(safe_map); // S-lock on Table auto it = s_safe_map->find(rnd_index); if (it != s_safe_map->cend()) { auto x_field = xlock_safe_ptr(it->second); x_field->money += rnd_index; // X-lock on field, still S-lock on Table (must necessarily be) } } break; case read_op: { auto s_safe_map = slock_safe_ptr(safe_map); // S-lock on Table auto it = s_safe_map->find(rnd_index); if (it != s_safe_map->cend()) { auto s_field = slock_safe_ptr(it->second); volatile int money = s_field->money; // S-lock on field, still S-lock on Table (must necessarily be) // volatile here only to avoid optimization for unused money-variable } } break; default: std::cout << "\n wrong way! \n"; break; }
Здесь для потоко-безопасной работы со строкой мы использовали safe_obj. Внутри safe_obj<T> содержится объект типа T, а не указатель на него, как в safe_ptr<T>. Следовательно, при использовании safe_obj не требуется отдельно выделять память под сам объект и изменять атомарный счетчик ссылок, как это требуется в safe_ptr. Поэтому операции Insert и Delete выполняются намного быстрее с safe_obj, чем с safe_ptr.
Стоит отметить, что при копировании safe_obj – копируется не указатель на объект, а копируется сам объект, при этом предварительно заблокировав исходный и конечный safe_obj.
Примечание: Строго говоря, мы блокируем не всю строку, а все поля строки за исключением индекса строки по которому мы ищем. Поэтому мы назвали наш объект field, а не row. А также, чтобы акцентировать внимание на том, что таким образом мы можем блокировать не только одну строку, но даже отдельные поля в одной строке, если разместить их в отдельных safe_obj-объектах. Это позволило бы разным потокам блокировать разные поля и работать с ними параллельно.
Теперь у нас используются следующие блокировки для разных операций:

Этот пример очень быстрый для большого количества коротких по времени операций. Но мы все ещё удерживаем блокировку чтения (shared) на таблице в процессе изменения или чтения строки (field). И если у нас редкие, но очень долгие операции над строками таблицы, то все это долгое время будет удерживаться блокировка на всей таблице.
Однако, если по логике вашей задачи не важно, что строка может быть удалена одним потоком, в то время пока другой поток читает или изменяет эту же строку, то нам достаточно блокировать таблицу только на время поиска строки. А чтобы избежать обращения к освобожденной памяти, когда другой поток удалил строку, то нам необходимо использовать std::shared_ptr<T> — указатель с атомарным потоко-безопасным счетчиком ссылок. В этом случае память будет освобождена только когда ни один поток не будет иметь указателей на эту строку.
Вместо safe_obj мы будем использовать safe_ptr для защиты строки. Это позволит нам скопировать указатель на строку и использовать потоко-безопасный счетчик ссылок в std::shared_ptr<T> который содержится в safe_ptr.
Пример: [39] coliru.stacked-crooked.com/a/f2a051abfbfd2716
Теперь для операций Update или Read мы делаем:
- Блокируем всю таблицу разделяемой блокировкой (shared)
- Ищем нужную строку или несколько строк
- Затем блокируем найденную строку (xlock для Update, slock для Read)
- Разблокируем таблицу
- И работаем с заблокированной строкой (X/S-lock) так долго, сколько этого требуется
- Разблокируем строку
Diff — что мы поменяли:

Пример-3:
int const rnd_index = index_distribution(generator); // 0 - container_size int const num_op = operation_distribution(generator);// insert_op, update_op, delete_op, read_op safe_ptr_field_t safe_nullptr; switch (num_op) { case insert_op: { safe_map->emplace(rnd_index, (field_t(rnd_index, rnd_index))); // insert with X-lock on Table break; } case delete_op: { size_t erased_elements = safe_map->erase(rnd_index); // erase with X-lock on Table } break; case update_op: { auto pair_result = [&]() { auto s_safe_map = slock_safe_ptr(safe_map); // S-lock on Table auto it = s_safe_map->find(rnd_index); if (it != s_safe_map->cend()) return std::make_pair(it->second, true); // found else return std::make_pair(safe_nullptr, false); // null-value }(); // unlock Table if(pair_result.second) { auto x_field = xlock_safe_ptr(pair_result.first); // X-lock on field x_field->money += rnd_index; // if a long time is read } // unlock field } break; case read_op: { auto pair_result = [&]() { auto s_safe_map = slock_safe_ptr(safe_map); // S-lock on Table auto it = s_safe_map->find(rnd_index); if (it != s_safe_map->cend()) return std::make_pair(it->second, true); // found else return std::make_pair(safe_nullptr, false); // null-value }(); // unlock Table if(pair_result.second) { auto s_field = slock_safe_ptr(pair_result.first); // S-lock on field volatile int money = s_field->money; // if a long time is read // volatile here only to avoid optimization for unused money-variable } // unlock field } break; default: std::cout << "\n wrong way! \n"; break; }
Хорошо спроектированные многопоточные программы используют короткие обращения к разделяемым объектам, поэтому в дальнейшем мы будем использовать не последний, а предпоследний пример для коротких операций чтения.
Недостатки Execute Around Idiom
Давайте рассмотрим возможные проблемы и покритикуем наш код. В предыдущей главе мы рассмотрели достаточно удобный и высокопроизводительный пример, явно задавая тип блокирования для операций Update и Read, используя функции:
- slock_safe_ptr() – только для чтения
- xlock_safe_ptr() – для чтения и изменения
Здесь блокировка удерживается до конца жизни объекта lock_obj, возвращенного этими функциями: auto lock_obj = slock_safe_ptr(sf_p);
Однако, для операций Insert и Delete использовались неявные блокировки, т.е. наш объект safe_ptr<std::map> блокировался автоматически используя идиому Execute Around Pointer, и разблокировался сразу после окончания операции Insert или Delete.
Пример: [40] coliru.stacked-crooked.com/a/89f5ebd2d96296d3
Но вы можете забыть использовать явные блокировки на операциях Update и Read. В этом случае safe_ptr<std::map> будет разблокирован сразу после окончания операции поиска, а далее вы продолжите использовать:
- найденный итератор, который может быть инвалидирован другим потоком
- или найденный элемент, который может быть удален другим потоком
Чтобы частично решить эту проблему, вместо safe_ptr<> и safe_obj<>, вы можете использовать safe_hide_ptr<> и safe_hide_obj<> – они не используют Execute Around Pointer и вы сможете обратиться к членам класса только после явной блокировки:
safe_hide_obj<field_t, spinlock_t> field_hide_tmp; //safe_obj<field_t, spinlock_t> &field_tmp = field_hide_tmp; // conversion denied - compile-time error //field_hide_tmp->money = 10; // access denied - compile-time error auto x_field = xlock_safe_ptr(field_hide_tmp); // locked until x_field is alive x_field->money = 10; // access granted
Пример: [41] coliru.stacked-crooked.com/a/d65deacecfe2636b
Если раньше вы могли ошибиться и написать следующий – ошибочный код:
auto it = safe_map->find(rnd_index); // X-lock, find(), X-unlock if (it != s_safe_map->cend()) volatile int money = it->second ->money; // X-lock, operator=(), X-unlock
То теперь такое обращение не скомпилируется и потребует явного блокирования объектов – правильный код:
auto s_safe_map = slock_safe_ptr(safe_map); // S-lock on Table auto it = s_safe_map->find(rnd_index); if (it != s_safe_map->cend()) { auto s_field = slock_safe_ptr(it->second); volatile int money = s_field->money; // S-lock on field, still S-lock on Table // volatile here only to avoid optimization for unused money-variable } // S-unlock Table, S-unlock field
Однако у вас до сих пор остается опасность использования блокировок, как временных объектов – не правильно:
auto it = slock_safe_ptr(safe_map)->find(rnd_index); // S-lock, find(), S-unlock if (it != s_safe_map->cend()) { volatile int money = slock_safe_ptr(it->second)->money; // S-lock, =, S-unlock }
У вас появляется выбор:
- Использовать safe_ptr и safe_obj для возможности явно или автоматические (Execute Around Idiom) блокировать ваш объект
- Или использовать safe_hide_ptr и safe_hide_obj оставляя только возможность явно блокировать ваш объект
Это решать вам, что выбрать:
- использовать удобную автоматическую блокировку (Execute Around Idiom)
- или немного сократить возможность ошибки обязав явно блокировать объект
Кроме того, в стандарт C++17 планируется внести для std::map<> следующие функции:
- insert_or_assign() – если есть элемент то присвоить, если нет то вставить
- try_emplace() – если элемента нет, то создать элемент
- merge() – слить 2 map в 1
- extract() – получить элемент, и удалить его из map
Введение подобных функций позволяет выполнить часто используемые составные операции без использования итераторов – в этом случае использование Execute Around Idiom всегда будет гарантировать потоко-безопасность данных операций. Вообще, уход от итераторов для всех контейнеров (кроме массивов std::array и std::vector) – это большая помощь в построении многопоточных программ. Чем реже вы используете итераторы, тем меньше шансов, что вы обратитесь к итератору инвалидированному этим или другим потоком. Но сама идея итераторов не противоречит идее многопоточности, например, СУБД (Oracle, MSSQL) поддерживают курсоры (аналоги итераторов) и разные уровни изоляции транзаций (различная консистентность многопоточности).
Но чтобы вы не выбрали: использовать Execute Around Idiom, использовать явные блокировки для safe_hide_ptr, отказаться от них и использовать стандартные блокировки std::mutex… или вообще писать собственные lock-free алгоритмы – у вас всегда остается много возможностей сделать ошибку.

Секционируем таблицу – ещё повышаем производительность
Вернемся опять к опыту промышленных реляционных СУБД. Например, в СУБД для повышения производительности может использоваться секционирование таблицы. В этом случае вместо всей таблицы можно блокировать только используемую партицию (partition): https://technet.microsoft.com/en-us/library/ms187504(v=sql.105).aspx
Хотя в СУБД для операций Delete и Insert обычно не блокируется вся таблица, и для операций Delete это верно всегда. Но для операций Insert есть возможность осуществления очень быстрой загрузки данных в таблицу, обязательным условием которой является эксклюзивное блокирование таблицы:
- MS SQL (dbcc traceon (610, -1)): INSERT INTO sales_hist WITH (TABLOCKX)
- Oracle: INSERT /*+ APPEND */ INTO sales_hist
https://docs.oracle.com/cd/E18283_01/server.112/e17120/tables004.htm#i1009887
Locking Considerations with Direct-Path INSERT
During direct-path INSERT, the database obtains exclusive locks on the table (or on all partitions of a partitioned table). As a result, users cannot perform any concurrent insert, update, or delete operations on the table, and concurrent index creation and build operations are not permitted. Concurrent queries, however, are supported, but the query will return only the information before the insert operation.
Т.к. наша задача создать максимально быстрый многопоточный контейнер, то мы тоже блокировали контейнер целиком на операциях Insert/Delete. Но теперь давайте попробуем блокировать только часть нашего контейнера.
Попробуем реализовать собственный секционированный упорядоченный ассоциативный массив partitioned_map и посмотрим насколько увеличиться производительность. Будем блокировать в нем только необходимую в данный момент секцию.
По смыслу это: std::map< safe_ptr<std::map<>> >
Здесь первый std::map будет константным и будет содержать секции (sub-tables).
Это будет очень упрощенный пример, где количество секций задается в конструкторе и далее не изменяется.
Каждая из секций представляет собой потоко-безопасный ассоциативный массив safe_ptr<std::map<>>.
Для максимальной производительности – количество секций и их диапазоны должны быть такими, чтобы вероятность обращения к каждой секции была одинакова. Если у вас диапазон ключей 0 – 1000000, и вероятность запросов read/update/insert/delete к началу диапазона больше, чем к концу диапазона – то и секций с малым значением ключа должно быть больше, а их диапазоны меньше. Например, 3 секции: [0 – 100000], [100001 – 400000], [400001 – 1000000].
Но мы в наших примерах будем считать, что ключи запросов имеют равномерное распределение.
Диапазоны секций можно задавать двумя вариантами:
- safe_map_partitioned_t<std::string, int> safe_map { «a», «f», «k», «p», «u» };
safe_map_partitioned_t<int, int> (0, 100000, 10000);
// задаем границы значений 0 – 100000 и шаг для каждой секции 10000
Если при обращении к контейнеру ключ выходит за границы секций, то запрос обратится к ближайшей секции – т.е. программа будет работать правильно.
Пример: [42] coliru.stacked-crooked.com/a/fc148b08eb4b0580
Так же для максимальной производительности необходимо использовать реализованный нами ранее «contention-free shared-mutex» внутри safe_ptr<>, т.е. по смыслу это: std::map< contfree_safe_ptr<std::map<>> >
Возьмем код из предыдущего примера и добавим код contfree_safe_ptr из предыдущей главы.
Заменим: safe_map_partitioned_t<std::string, std::pair<std::string, int>>
На: safe_map_partitioned_t<std::string, std::pair<std::string, int>, contfree_safe_ptr >
Пример: [43] coliru.stacked-crooked.com/a/23a1f7a3982063a1
Этот класс safe_map_partitioned_t<> мы сделали «Just for fun», т.е. не рекомендуется использовать его в реальных программах. Мы только показали пример – как вы можете реализовывать собственные алгоритмы основываясь на указателе contfree_safe_ptr<> и блокировке contention_free_shared_mutex<>.
Как использовать
Сначала скачайте файл safe_ptr.h из корня репозитория: github.com/AlexeyAB/object_threadsafe
Затем включите этот файл в свой cpp-файл: #include "safe_ptr.h"
Как оптимальный вариант использования мы остановимся на Примере-2 показанном выше — это просто и высоко-производительно:
struct field_t { int money, time; field_t(int m, int t) : money(m), time(t) {} field_t() : money(0), time(0) {} }; typedef safe_obj<field_t, spinlock_t> safe_obj_field_t; // thread-safe ordered std::map by using execute around pointer idiom with contention-free shared-lock contfree_safe_ptr< std::map<int, safe_obj_field_t > > safe_map_contfree; bool success_op; switch (num_op) { case insert_op: slock_safe_ptr(test_map)->find(rnd_index); // find for pre-cache to L1 with temprorary S-lock test_map->emplace(rnd_index, field_t(rnd_index, rnd_index)); break; case delete_op: slock_safe_ptr(test_map)->find(rnd_index); // find for pre-cache to L1 with temprorary S-lock success_op = test_map->erase(rnd_index); break; case read_op: { auto s_safe_map = slock_safe_ptr(test_map); // S-lock on Table (must necessarily be) auto it = s_safe_map->find(rnd_index); if (it != s_safe_map->cend()) { auto x_field = xlock_safe_ptr(it->second); volatile int money = x_field->money; // get value x_field->money += 10; // update value } } break; default: std::cout << "\n wrong way! \n"; break; }
Insert and delete — изменение map: Т.к. наша разделяемая блокировка slock_safe_ptr() максимально быстрая, то ещё до изменения (insert_op или delete_op) мы находим элемент, который нам надо удалить или ближайший к тому, который нам надо вставить, используя slock_safe_ptr(), которая разблокируется немедленно после операции find(). Мы не используем напрямую результат этой операции, но это холостая операция подсказывает процессору какие данные необходимо закэшировать в кэш-L1 для последующего изменения map. Далее мы делаем test_map->emplace() для вставки или test_map->erase() для удаления и эти операции автоматически вызывают exclusive-lock на время их выполнения. Insert/delete — происходят быстро потому, что почти все данные уже находятся в кэше данного ядра, так же большой плюс — у нас нет необходимости в непрерывном повышении shared-lock до exclusive-lock (это могло бы сильно увеличить шанс взаимоблокировки deadlock — вечного зависания программы).
Read and update — (чтение map) и чтение или изменения одного элемента: То что мы называем чтение (read_op) в нашем конкретном примере — это чтение и последующее изменение одного элемента из map (одна строка из map). До чтения мы накладываем разделяемую блокировку slock_safe_ptr() на map, так что другие потоки не могут удалить или заменить ни один элемент в map. И удерживая разделяемую блокировку пока существует объект s_safe_map, мы находим нужный элемент и накладываем эксклюзивную блокировку xlock_safe_ptr() только на один этот элемент, затем читаем его и изменяем. После этого, когда мы покидаем область видимости {}, то объект x_field уничтожается первым и эксклюзивная блокировка снимается с элемента, а затем уничтожается объект s_safe_map и снимается разделяемая блокировка с map.
Компилятор позволяет нам делать любые операции с test_map — читать или изменять его и вызывать любые его методы — в этом случае автоматически накладывается эксклюзивная блокировка.
Но компилятор позволит вам только читать объект, который объявлен как константный или который присвоен константной ссылке auto const& some_ptr = test_map;, например, вы сможете вызвать some_ptr->find(); и автоматически будет наложена разделяемая блокировка (shared lock) на все время выполнения выражения, но для константной ссылки вы не сможете выполнить следующее
Аналогичное поведение для явной блокировки slock_safe_ptr(test_map), вы сможете выполнить slock_safe_ptr(test_map)->find();, но при попытке скомпилировать slock_safe_ptr(test_map)->emplace(); — будет ошибка. Все это гарантирует правильный автоматический выбор блокировок и правильную работу многопоточной программы.
Все это и даже больше описано в первой статье.
Сравнение производительности полученных реализаций safe_ptr
Подведем промежуточные результаты. Покажем насколько улучшалась производительность за счет наших оптимизаций.
Приведем графики производительности – количества миллионов операций в секунду (MOps), при разном проценте операций модификации 0 – 90%. При модификации с равной вероятностью будет выполняться одна из трех операций: insert, delete, update (хотя операция Update и не изменяет само дерево std::map, а лишь изменяет одну из его строк). Например, при 15% модификаций – это будут операции: 5% insert, 5% delete, 5% update, 85% read. Используемый компилятор: g++ 4.9.2 (Linux Ubuntu) x86_64
Вы можете скачать данный бенчмарк для Linux (GCC 4.9.2) и Windows (MSVS2015): github.com/AlexeyAB/object_threadsafe/tree/master/benchmark
Для компиляции в Clang++ 3.8.0 под Linux вы должны изменить Makefile.
Приведем пример тестирования на 16 потоках для одного серверного процессора Intel Xeon E5-2660 v3 2.6 GHz. В первую очередь нас интересует оранжевая линия: safe<map,contfree>&rowlock.
Если у вас установлено более одно CPU, то командная строка для запуска:
numactl --localalloc --cpunodebind=0 ./benchmark 16
Если установлен один CPU, то просто запустите: ./benchmark
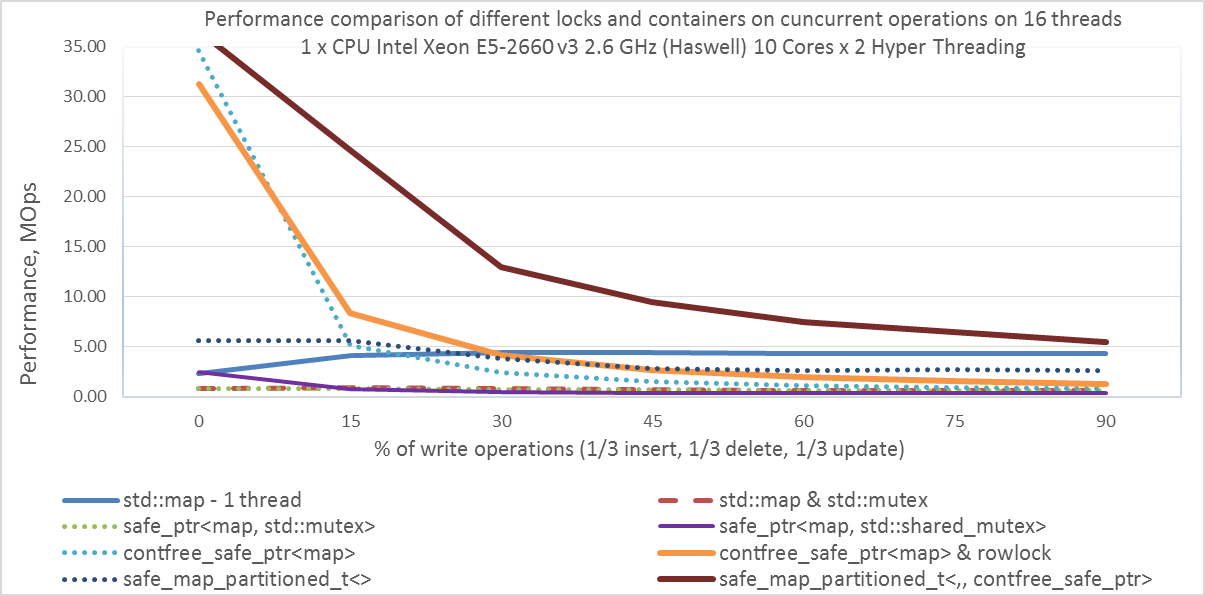
Вывод:
- Интересно, что наша разделяемая contfree-блокировка в contfree_safe_ptr<map> работает значительно быстрее, чем стандартный std::shared_mutex в составе safe_ptr<map,std::shared_mutex>
- Так же интересно, что начиная с 15% изменений std::mutex быстрее, чем std::shared_mutex (а именно safe_ptr<map,std::mutex> быстрее, чем safe_ptr<map,std::shared_mutex>)
- И любопытный момент, что начиная с 30% изменений производительность std:map – 1 thread выше производительности contfree_safe_ptr<map>&rowlock. Но реальные задачи не состоят только из операций с ассоциативным массивом и синхронизаций потоков. Обычно меж-поточный обмен данными составляет лишь небольшую часть задачи, а основная часть хорошо распараллеливается на множество ядер.
- Показывает хорошую производительность секционированный ассоциативный массив safe_map_partitioned<,,contfree_safe_ptr>, но его стоит использовать, только «Just-for-fun» — если необходимое число секций и их диапазоны известны заранее.
- При 15% изменений, наш shared-mutex (в составе contfree_safe_ptr<map> & rowlock) показывает производительность 8.37 Mops, что в 10 раз быстрее, чем стандартный std::shared_mutex (в составе safe_ptr<map, std::shared_mutex>), который показывает только 0.74 Mops.
Наша блокировка «contention-free shared-mutex» работает для любого количества потоков: для первых 70 потоков как contention-free, а для последующих как exclusive-lock. Как видим из графиков, даже «exclusive-lock» std::mutex работает быстрее, чем std::shared_mutex при 15% изменений.
Так же приведем график медианной задержки в микросекундах, т.е. половина запросов имеют задержку меньше этого значения.
В коде теста main.cpp вы должны установить: const bool measure_latency = true;
Командная строка для запуска: numactl --localalloc --cpunodebind=0 ./benchmark 16
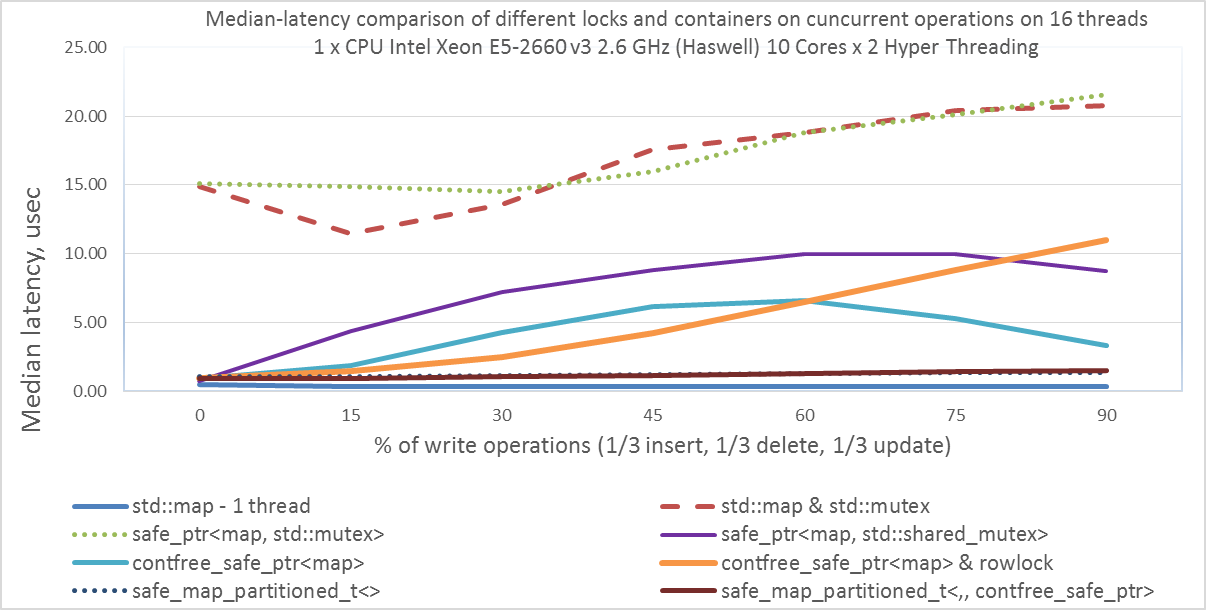
- Интересно, что std::map & std::mutex колеблется вокруг safe_ptr<map,std::mutex>, т.е. в целом использование safe_ptr<> не добавляет каких-то дополнительных накладных расходов, и не снижает производительность.
- Так же интересно, что начиная с 60% изменений, contfree_safe_ptr<map>&rowlock показывает задержку больше, чем contfree_safe_ptr<map>. Но из предыдущего графика мы видели, что общая производительность все равно выше у contfree_safe_ptr<map>&rowlock для любого процента операций модификации.
Сравнение производительности contfree_safe_ptr<std::map> и контейнеров из CDS-lib на разных desktop-CPU
Сравнение производительности на разных desktop-CPU, используя все ядра.
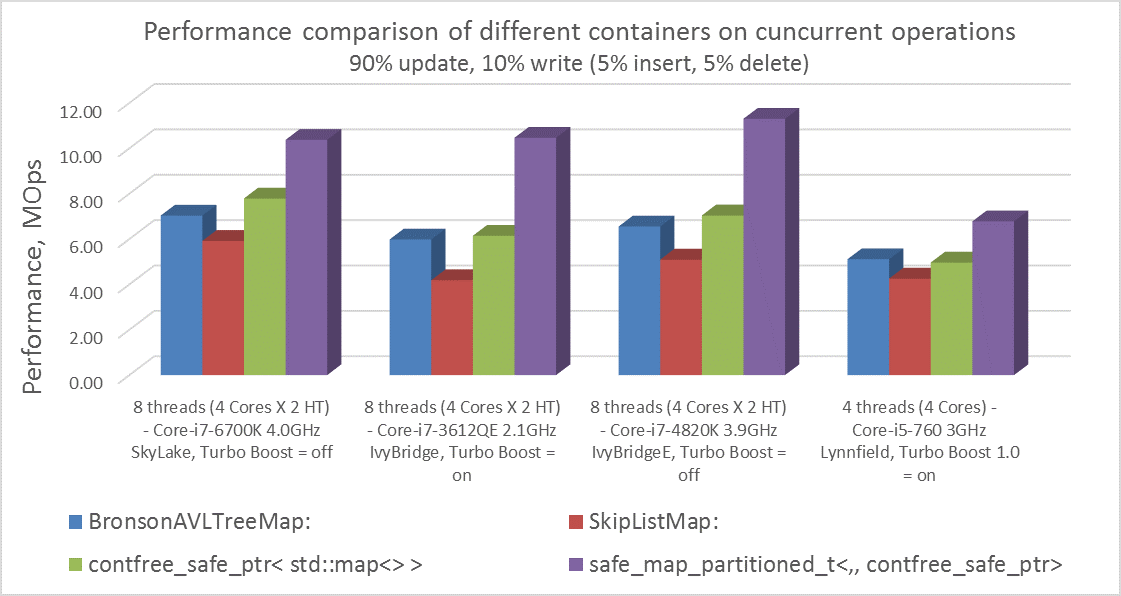
- Интересно, что для ноутбуков и настольных компьютеров contfree_safe_ptr<map> показывает производительность выше, чем любой из lock-free-map контейнеров из CDS-lib.
- А наша «Just-for-fun» версия ассоциативного контейнера с постоянным числом секций safe_map_partitioned<,,contfree_safe_ptr> показывает выигрыш производительности в среднем в 1.7 раза.
Сравнение производительности contfree_safe_ptr<std::map> и контейнеров из CDS-lib на server-CPU
Сравнение производительности разных многопоточных ассоциативных массивов на одном серверном CPU, используя разное количество потоков.
Вы можете скачать данный бенчмарк для Linux (GCC 4.9.2) и Windows (MSVS2015): github.com/AlexeyAB/object_threadsafe/tree/master/CDS_test
Для компиляции в Clang++ 3.8.0 под Linux вы должны изменить Makefile.
Если у вас несколько процессоров Xeon на одной материнской плате, то результат данного теста можно воспроизвести, запуская его следующим образом:
numactl --localalloc --cpunodebind=0 ./benchmark 16
Если установлен один CPU, то просто запустите: ./benchmark
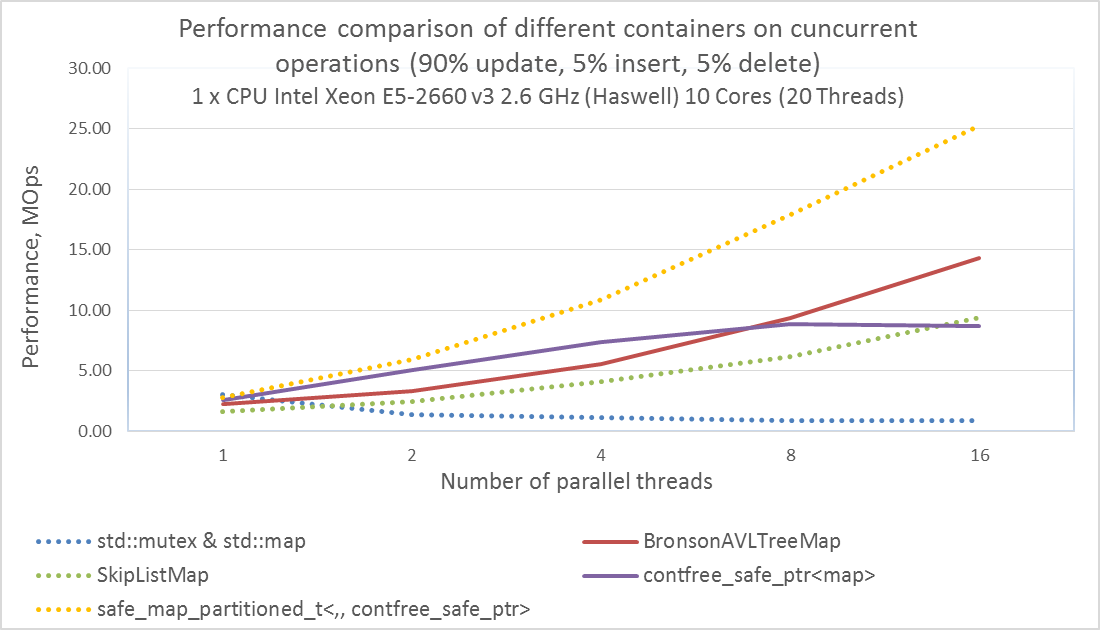
- Как видим, при использовании 16 и более параллельных потоков на одном процессоре, или при использовании более двух процессоров, lock-free контейнеры из CDS-lib показывают производительность лучше, чем contfree_safe_ptr<map>. Т.е. при большой конкуренции lock-free контейнеры лучше. Но даже если у вас больше 16 потоков, но в каждый момент времени одновременно к контейнеру обращаются не более 8 потоков, то contfree_safe_ptr<map> будет быстрее, чем lock-free контейнеры.
- Так же «Just-for-fun»-контейнер с константным числом секций safe_map_partitioned<,,contfree_safe_ptr> показывает лучшую производительность при любом количестве потоков, но его стоит использовать, только если необходимое число секций и их диапазоны известны заранее.
Медианная задержка – это время быстрее которого исполнялось 50% запросов.
В коде теста main.cpp вы должны установить: const bool measure_latency = true;
Командная строка для запуска: numactl --localalloc --cpunodebind=0 ./benchmark 16
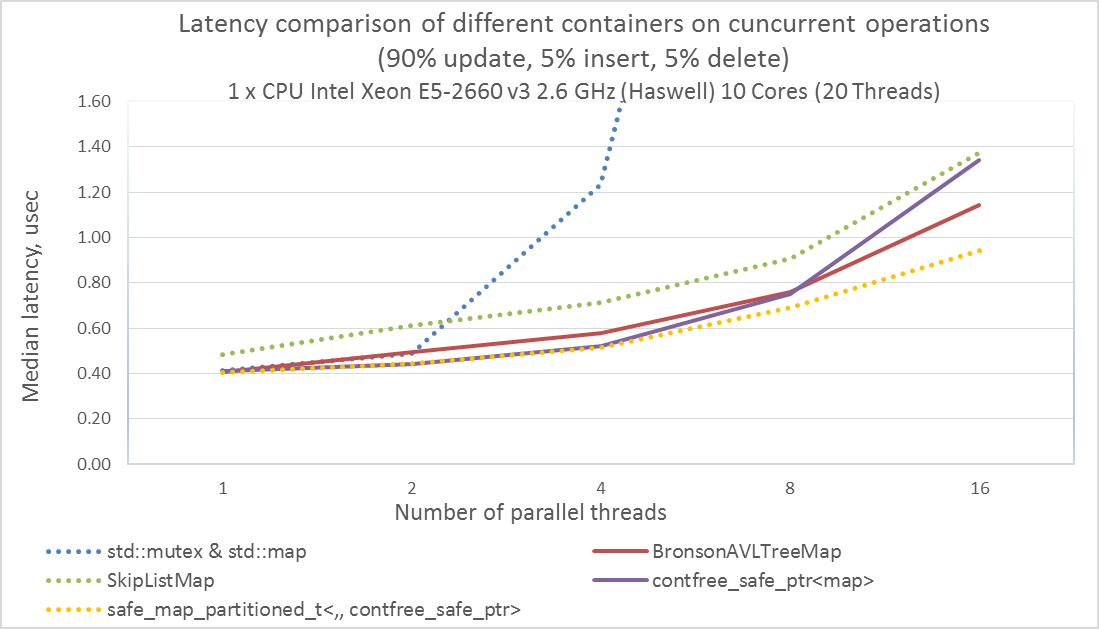
Медианная задержка у contfree_safe_ptr<map> также почти равна задержке lock-free контейнеров до 8 потоков одновременно конкурирующих потоках, но хуже при 16 конкурирующих потоках.
Производительность в реальных приложениях.
Реальные приложения не состоят лишь из обмена данными между потоками. Основная работа реальных приложений выполняется в каждом потоке отдельно и только изредка происходит обмен данными между потоками.
Для симуляцию реальной работы приложения добавим не оптимизируемый цикл for(volatile int i = 0; i < 9000; ++i); между каждым обращением к потоко-безопасному контейнеру. Вначале теста выполним этот цикл 100 000 раз и измерим среднее время выполнения данного цикла. На процессоре Intel Xeon E5-2686 v4 2.3 GHz эта симуляция реальной работы занимаем около 20.5 микросекунд.
Вы можете скачать этот бенчмарк для Linux (GCC 4.9.2) и Windows (MSVS2015) по ссылке: github.com/AlexeyAB/object_threadsafe/tree/master/Real_app_bench
Для компиляции в Clang++ 3.8.0 под Linux вы должны изменить Makefile.
Будем тестировать на 2-ух процессорном сервере: 2 x Intel Xeon E5-2686 v4 2.3 GHz (Broadwell) с общим числом ядер: 36 физических ядер и 72 логических ядра (Hyper Threading).
Для компиляции и запуска выполните:
cd libcds
make
cd…
make
./benchmark
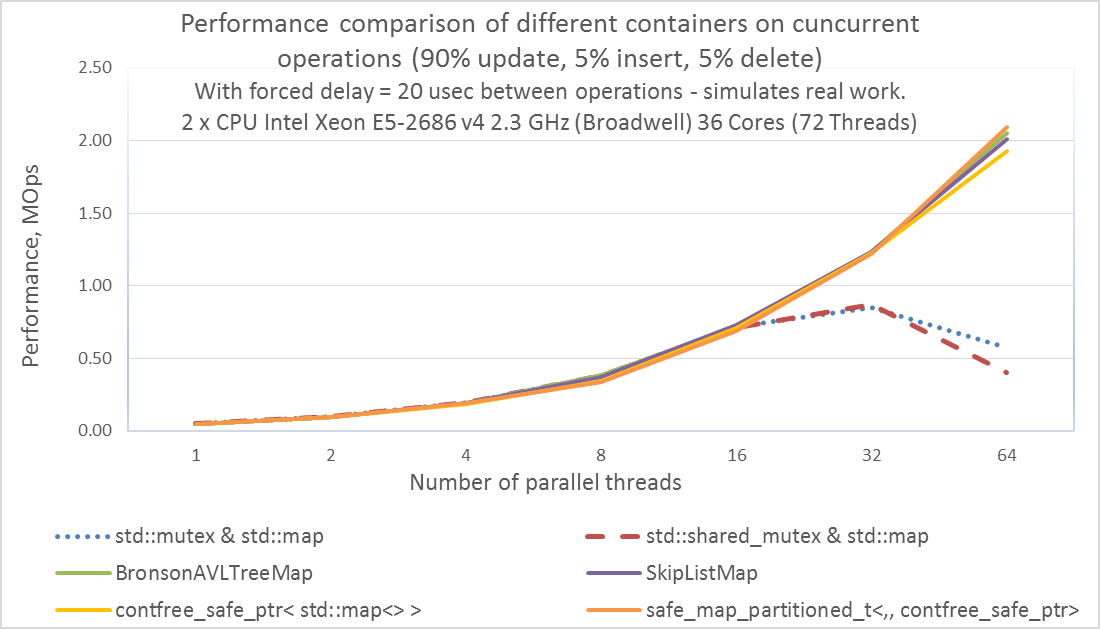
- Использование стандартных мьютексов std::mutex и std::shared_mutex для защиты std::map обеспечивает близкую производительность к lock-free-map контейнерам вплоть до 16 потоков. Но далее производительность std::mutex&std::map и std::shared_mutex&std::map начинают отставать, и после 32 потоков начинают снижаться.
- Использование нашего оптимизированного потоко-безопасного указателя contfree_safe_ptr< std::map<> > имеет производительность почти равную производительности lock-free-map контейнеров из библиотеки libCDS при любом количестве потоков от 1 до 64. Это справедливо при условии, что в реальных в реальных приложениях обмен между потоками происходит в среднем раз в 20 микросекунд или реже.
Для измерения медианной задержки — в коде теста main.cpp необходимо установить: const bool measure_latency = true;
Для запуска на Linux достаточно набрать: ./benchmark
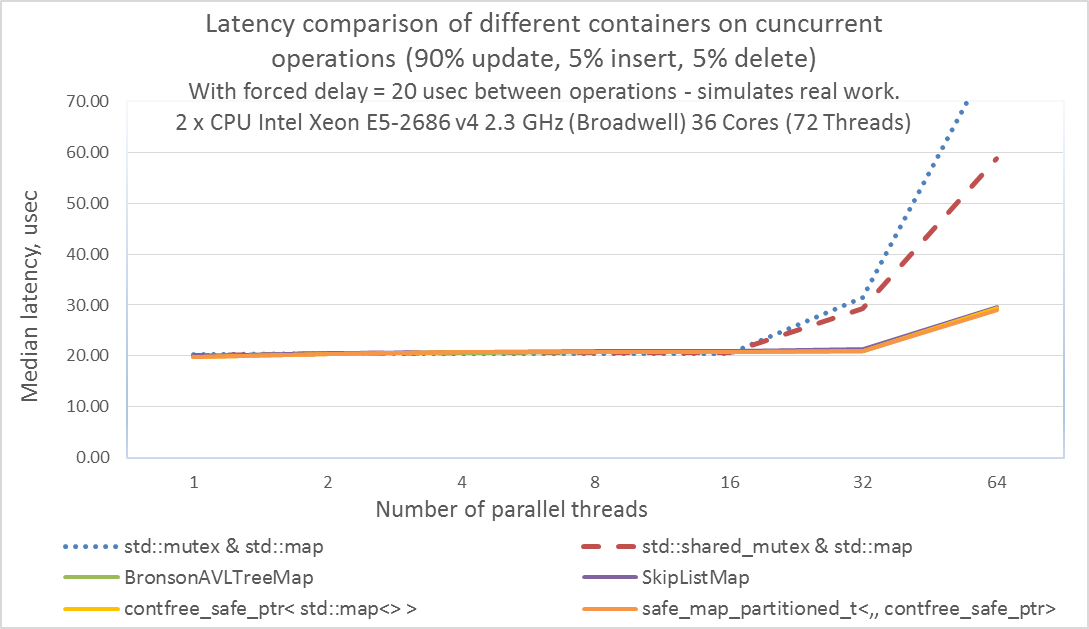
- Интересно, что при 64 потоках std::mutex имеет одновременно большую производительность и большую медианную задержку, чем у std::shared_mutex.
- Наш оптимизированный потоко-безопасный указатель contfree_safe_ptr<std::map<>> имеет такую же задержку как и lock-free-map контейнеры из libCDS при любом количестве потоков от 1 до 64. Это так же справедливо при условии, что в реальных в реальных приложениях обмен между потоками происходит раз в 20 микросекунд или реже.
- Для 64 потоков латентность составляет 30 мкс, из которых 20 мкс — симуляция задержки реального приложения, а 10 мкс — многопоточная задержка. Таким образом, даже если многопоточная задержка составляет 30% от общей латентности, то наш потокобезопасный указатель contfree_safe_ptr<T> имеет ту же производительность (MOPS и медианная-задержка), что и lock-free контейнеры libCDS.
Более простые lock-free и wait-free контейнеры (queue, stack …) в libCDS имеют задержки заметно меньше, чем их реализации на любых блокировках.
Вывод:
- Если у вас высокая конкуренция потоков за один и тот же контейнер, т.е. в один момент времени к контейнеру в среднем обращаются более 8 потоков, то лучшим решением будет использовать контейнеры из библиотеки CDSlib: github.com/khizmax/libcds
- Если необходимый вам thread-safe контейнер есть в CDSlib – используйте его.
- Если у вас программа выполняет что-то ещё помимо обмена данными между потоками, а сам обмен между потоками занимает не более 30% от общего времени, то даже при использовании нескольких десятков потоков наш указатель contfree_safe_ptr<> будет быстрее, чем map-контейнеры из CDSlib.
- Если для обмена данными между потоками вы используете свой собственный контейнер или собственную структуру данных, которых нет в CDSlib, то простым и быстрым решением будет contfree_safe_ptr<T>. Это намного проще, чем написать lock-free реализацию методов для работы с собственной структурой данных.
Что было рассмотрено в этих статьях
В этих статьях мы детально рассмотрели последовательность выполнения конструкций языка C++ в одном потоке на примере Execute Around Pointer Idiom. А так же рассмотрели последовательность выполнения операций чтения и записи в многопоточных программах на примере Contention-free shared-mutex. И показали примеры высокопроизводительного использования lock-free алгоритмов из libCDS и lock-based алгоритмов разработанных нами.
Как результат, вы можете скачать файл safe_ptr.h, который содержит все классы и функции созданные в этих статьях: github.com/AlexeyAB/object_threadsafe
Хотели бы вы видеть алгоритмы разобранные в статье в доработанном виде в составе библиотеки boost?

