Рассказ о том как я участвовал в highloadcup (чемпионат для backend-разработчиков) от Mail.Ru, написал на php сервер обслуживающий 10000 RPS, но всё равно не получил победную футболку.

Итак начнём с футболки. Своё решение нужно было написать до первого сентября, а я дописал только шестого.
Первого сентября были подведены итоги, места распределены, всем кто уложился в тысячу секунд пообещали футболки. После этого организаторы позволили ещё неделю улучшать свои решения, но уже без призов. Этим временем я и воспользовался, чтобы переписать своё решение (на самом деле мне не хватило всего пару вечеров). Собственно футболка мне не положена, а жаль :(
Во время своей предыдущей статьи я сравнивал библиотеки на php для создания вебсокет-сервера тогда мне порекомендовали библиотеку swoole — она написана на C++ и устанавливается из pecl. К слову сказать, все эти библиотеки могут использоваться не только для создания вебсокет сервера, но подходят и просто для http-сервера. Этим я и решил воспользоваться.
Я взял библиотеку swoole, создал базу данных sqlite в памяти и сразу поднялся в первую двадцатку с результатом 159 секунд, потом меня сместили, я добавил кеш и уменьшил время до 79 секунд, попал назад в двадцатку, меня сместили, переписал с sqlite на swoole_table и уменьшил время до 47 секунд. Конечно до первых мест мне было далеко, но мне удалось обойти в таблице моих нескольких знакомых с решением на Go.
Так выглядит старая рейтинговая таблица сейчас:

Немного похвалы для Mail.Ru и можно идти дальше.
Благодаря этому замечательному чемпионату я более близко познакомился с библиотеками swoole, workerman, научился лучше оптимизировать php под высокие нагрузки, научился использовать yandex tank и многое другое. Продолжайте устраивать такие чемпионаты, соревновательность подстёгивает к изучению новой информации и прокачке навыков.
Для начала я взял swoole, потому что он написан C++ и однозначно должен работать быстрее workerman, который написан на php.
Я написал hello world код:
Запустил линуксовую консольную утилиту Apache Benchmark, которая делает 10к запросов в 10 потоков:
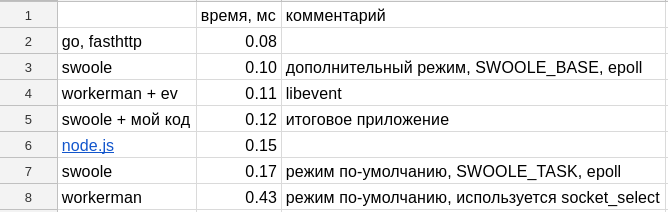
и получил время ответа 0.17 ms
После этого написал пример на workerman:
и получил 0.43 ms, т.е. результат в 3 раза хуже.
Но я не сдавался, установил библиотеку event:
Измерения показали 0.11 ms, т.е. workerman написанный на php и использующий libevent стал работать быстрее чем swoole написанный на C++. Я с помощью гуглтранслейта прочитал тонны документации на китайском. Но ничего не нашёл. К слову сказать обе библиотеки написаны китайцами и комментарии на китайском в коде библиотек для них — …
Теперь я понимаю, что чувствовали китайцы, когда читали мой код.
Я завёл тикет на гитхабе swoole с вопросом как такое может происходить.
Там мне порекомендовали использовать:
вместо:
Я воспользовался их советом и получил 0.10 ms, т.е. чуть-чуть быстрее чем workerman.
На этот момент у меня уже было готовое приложение на php, которое я уже не знал как оптимизировать, оно отвечало за 0.12 ms и решил переписать приложение на что-нибудь другое.
Попробовал node.js:
получил 0.15 ms, т.е. на 0.03 ms меньше чем моё готовое приложение на php
Взял fasthttp на go и получил 0.08 ms:
Итоговая таблица (таблица и все тесты на опубликованы на гитхабе):
За неделю до окончания конкурса условия немного усложнили:
Структура данных, которые нужно хранить — это 3 таблицы: users (1kk), locations (1kk) и visits (11kk).
Моё решение перестало укладываться в выделенные для него 4Гб. Пришлось искать варианты.
Для начала мне нужно было залить в память из json-файлов 11 миллионов записей.
Попробовал swoole_table, замерил потребление памяти — 2200 Мб
Попробовал ассоциативный массив, потребление памяти сильно больше — 6057 Мб
Попробовал SplFixedArray, потребление памяти немого меньше, чем у обычного массива — 5696 Мб
Решил отдельные свойства визита сохранять в отельные массивы, потому что текстовые ключи могут занимать в памяти много места, т.е. изменил такой код:
на такой:
потребление памяти при разбивке трёхмерного массива на двумерные составило — 2147 Мб, т.е. в 3 раза меньше. Т.о. имена ключей в трёхмерном массиве съедали 2/3 от всей занимаемой им памяти.
Решил использовать разбиение трёхмерного массива совместно с SplFixedArray и потребление памяти упало ещё в 3 раза составив 704 МБ
Ради интереса попробовал тоже самое на node.js и получил 780 Мб
Итоговая таблица (таблица и все тесты опубликованы на гитхабе):

Хотел попробовать apc_cache и redis, но у них ещё дополнительно память тратится на хранения имён ключей. В реальной жизни можно использовать, но для этого чемпионата вообще не вариант.
После всех оптимизаций общее время составило 404 секунд, что почти в 4 раза медленнее, чем первое место.
Ещё раз спасибо организаторам, которые не спали по ночам, перезагружали зависшие контейнеры, фиксили баги, допиливали сайт, отвечали в телеграмме на вопросы.
Актуальные итоговые таблицы и сходный код всех тестов опубликованы на гитхабе:
сравнение скорости работы разных вебсерверов
сравнение расхода памяти разными структурами
Другая моя сегодняшняя статья на Хабре: бесплатный сервер в облаке
Вступление
Итак начнём с футболки. Своё решение нужно было написать до первого сентября, а я дописал только шестого.
Первого сентября были подведены итоги, места распределены, всем кто уложился в тысячу секунд пообещали футболки. После этого организаторы позволили ещё неделю улучшать свои решения, но уже без призов. Этим временем я и воспользовался, чтобы переписать своё решение (на самом деле мне не хватило всего пару вечеров). Собственно футболка мне не положена, а жаль :(
Во время своей предыдущей статьи я сравнивал библиотеки на php для создания вебсокет-сервера тогда мне порекомендовали библиотеку swoole — она написана на C++ и устанавливается из pecl. К слову сказать, все эти библиотеки могут использоваться не только для создания вебсокет сервера, но подходят и просто для http-сервера. Этим я и решил воспользоваться.
Я взял библиотеку swoole, создал базу данных sqlite в памяти и сразу поднялся в первую двадцатку с результатом 159 секунд, потом меня сместили, я добавил кеш и уменьшил время до 79 секунд, попал назад в двадцатку, меня сместили, переписал с sqlite на swoole_table и уменьшил время до 47 секунд. Конечно до первых мест мне было далеко, но мне удалось обойти в таблице моих нескольких знакомых с решением на Go.
Так выглядит старая рейтинговая таблица сейчас:
Немного похвалы для Mail.Ru и можно идти дальше.
Благодаря этому замечательному чемпионату я более близко познакомился с библиотеками swoole, workerman, научился лучше оптимизировать php под высокие нагрузки, научился использовать yandex tank и многое другое. Продолжайте устраивать такие чемпионаты, соревновательность подстёгивает к изучению новой информации и прокачке навыков.
php vs node.js vs go
Для начала я взял swoole, потому что он написан C++ и однозначно должен работать быстрее workerman, который написан на php.
Я написал hello world код:
$server = new Swoole\Http\Server('0.0.0.0', 1080); $server->set(['worker_num' => 1,]); $server->on('Request', function($req, $res) {$res->end('hello world');}); $server->start();
Запустил линуксовую консольную утилиту Apache Benchmark, которая делает 10к запросов в 10 потоков:
ab -c 10 -n 10000 http://127.0.0.1:1080/
и получил время ответа 0.17 ms
После этого написал пример на workerman:
require_once DIR . '/vendor/autoload.php'; use Workerman\Worker; $http_worker = new Worker("http://0.0.0.0:1080"); $http_worker->count = 1; $http_worker->onMessage = function($conn, $data) {$conn->send("hello world");}; Worker::runAll();
и получил 0.43 ms, т.е. результат в 3 раза хуже.
Но я не сдавался, установил библиотеку event:
добавил в код:pecl install event
Worker::$eventLoopClass = '\Workerman\Events\Ev';
Итоговый код
require_once DIR . '/vendor/autoload.php'; use Workerman\Worker; Worker::$eventLoopClass = '\Workerman\Events\Ev'; $http_worker = new Worker("http://0.0.0.0:1080"); $http_worker->count = 1; $http_worker->onMessage = function($conn, $data) {$conn->send("hello world");}; Worker::runAll();
Измерения показали 0.11 ms, т.е. workerman написанный на php и использующий libevent стал работать быстрее чем swoole написанный на C++. Я с помощью гуглтранслейта прочитал тонны документации на китайском. Но ничего не нашёл. К слову сказать обе библиотеки написаны китайцами и комментарии на китайском в коде библиотек для них — …
Нормальная практика



Теперь я понимаю, что чувствовали китайцы, когда читали мой код.
Я завёл тикет на гитхабе swoole с вопросом как такое может происходить.
Там мне порекомендовали использовать:
$serv = new Swoole\Http\Server('0.0.0.0', 1080, SWOOLE_BASE);
вместо:
$serv = new Swoole\Http\Server('0.0.0.0', 1080);
Итоговый код
$serv = new Swoole\Http\Server('0.0.0.0', 1080, SWOOLE_BASE); $serv->set(['worker_num' => 1,]); $serv->on('Request', function($req, $res) {$res->end('hello world');}); $serv->start();
Я воспользовался их советом и получил 0.10 ms, т.е. чуть-чуть быстрее чем workerman.
На этот момент у меня уже было готовое приложение на php, которое я уже не знал как оптимизировать, оно отвечало за 0.12 ms и решил переписать приложение на что-нибудь другое.
Попробовал node.js:
const http = require('http'); const server = http.createServer(function(req, res) { res.writeHead(200); res.end('hello world'); }); server.listen(1080);
получил 0.15 ms, т.е. на 0.03 ms меньше чем моё готовое приложение на php
Взял fasthttp на go и получил 0.08 ms:
Hello world на fasthttp
package main import ( "flag" "fmt" "log" "github.com/valyala/fasthttp" ) var ( addr = flag.String("addr", ":1080", "TCP address to listen to") compress = flag.Bool("compress", false, "Whether to enable transparent response compression") ) func main() { flag.Parse() h := requestHandler if *compress { h = fasthttp.CompressHandler(h) } if err := fasthttp.ListenAndServe(*addr, h); err != nil { log.Fatalf("Error in ListenAndServe: %s", err) } } func requestHandler(ctx *fasthttp.RequestCtx) { fmt.Fprintf(ctx, "Hello, world!") }
Итоговая таблица (таблица и все тесты на опубликованы на гитхабе):
splfixedarray vs array
За неделю до окончания конкурса условия немного усложнили:
- объём данных увеличили в 10 раз
- количество запросов в секунду увеличили в 10 раз
Структура данных, которые нужно хранить — это 3 таблицы: users (1kk), locations (1kk) и visits (11kk).
Описание полей
User (Профиль):
id — уникальный внешний идентификатор пользователя. Устанавливается тестирующей системой и используется для проверки ответов сервера. 32-разрядное целое беззнаковое число.
email — адрес электронной почты пользователя. Тип — unicode-строка длиной до 100 символов. Уникальное поле.
first_name и last_name — имя и фамилия соответственно. Тип — unicode-строки длиной до 50 символов.
gender — unicode-строка m означает мужской пол, а f — женский.
birth_date — дата рождения, записанная как число секунд от начала UNIX-эпохи по UTC (другими словами — это timestamp).
Location (Достопримечательность):
id — уникальный внешний id достопримечательности. Устанавливается тестирующей системой. 32-разрядное целое беззнаковоее число.
place — описание достопримечательности. Текстовое поле неограниченной длины.
country — название страны расположения. unicode-строка длиной до 50 символов.
city — название города расположения. unicode-строка длиной до 50 символов.
distance — расстояние от города по прямой в километрах. 32-разрядное целое беззнаковое число.
Visit (Посещение):
id — уникальный внешний id посещения. 32-разрядное целое беззнакое число.
location — id достопримечательности. 32-разрядное целое беззнаковое число.
user — id путешественника. 32-разрядное целое беззнаковое число.
visited_at — дата посещения, timestamp.
mark — оценка посещения от 0 до 5 включительно. Целое число.
Моё решение перестало укладываться в выделенные для него 4Гб. Пришлось искать варианты.
Для начала мне нужно было залить в память из json-файлов 11 миллионов записей.
Попробовал swoole_table, замерил потребление памяти — 2200 Мб
Код загрузки данных
$visits = new swoole_table(11000000); $visits->column('id', swoole_table::TYPE_INT); $visits->column('user', swoole_table::TYPE_INT); $visits->column('location', swoole_table::TYPE_INT); $visits->column('mark', swoole_table::TYPE_INT); $visits->column('visited_at', swoole_table::TYPE_INT); $visits->create(); $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $visits->set($row['id'], $row); } $i++; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n";
Попробовал ассоциативный массив, потребление памяти сильно больше — 6057 Мб
Код загрузки данных
$visits = []; $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $visits[$row['id']] = $row; } $i++;echo "$i\n"; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n";
Попробовал SplFixedArray, потребление памяти немого меньше, чем у обычного массива — 5696 Мб
Код загрузки данных
$visits = new SplFixedArray(11000000); $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $visits[$row['id']] = $row; } $i++;echo "$i\n"; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n";
Решил отдельные свойства визита сохранять в отельные массивы, потому что текстовые ключи могут занимать в памяти много места, т.е. изменил такой код:
$visits[1] = ['user' => 153, 'location' => 17, 'mark' => 5, 'visited_at' => 1503695452];
на такой:
$visits_user[1] = 153; $visits_location[1] = 17; $visits_mark[1] = 5; $visits_visited_at[1] => 1503695452;
потребление памяти при разбивке трёхмерного массива на двумерные составило — 2147 Мб, т.е. в 3 раза меньше. Т.о. имена ключей в трёхмерном массиве съедали 2/3 от всей занимаемой им памяти.
Код загрузки данных
$user = $location = $mark = $visited_at = []; $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $user[$row['id']] = $row['user']; $location[$row['id']] = $row['location']; $mark[$row['id']] = $row['mark']; $visited_at[$row['id']] = $row['visited_at']; } $i++;echo "$i\n"; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n";
Решил использовать разбиение трёхмерного массива совместно с SplFixedArray и потребление памяти упало ещё в 3 раза составив 704 МБ
Код загрузки данных
$user = new SplFixedArray(11000000); $location = new SplFixedArray(11000000); $mark = new SplFixedArray(11000000); $visited_at = new SplFixedArray(11000000); $user_visits = []; $location_visits = []; $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $user[$row['id']] = $row['user']; $location[$row['id']] = $row['location']; $mark[$row['id']] = $row['mark']; $visited_at[$row['id']] = $row['visited_at']; if (isset($user_visits[$row['user']])) { $user_visits[$row['user']][] = $row['id']; } else { $user_visits[$row['user']] = [$row['id']]; } if (isset($location_visits[$row['location']])) { $location_visits[$row['location']][] = $row['id']; } else { $location_visits[$row['location']] = [$row['id']]; } } $i++;echo "$i\n"; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n";
Ради интереса попробовал тоже самое на node.js и получил 780 Мб
Код загрузки данных
const fs = require('fs'); global.visits = []; global.users_visits = []; global.locations_visits = []; let i = 1; let visitsData; while (fs.existsSync(`data/visits_${i}.json`) && (visitsData = JSON.parse(fs.readFileSync(`data/visits_${i}.json`, 'utf8')))) { for (y = 0; y < visitsData.visits.length; y++) { //visits[visitsData.visits[y]['id']] = visitsData.visits[y]; visits[visitsData.visits[y]['id']] = { user:visitsData.visits[y].user, location:visitsData.visits[y].location, mark:visitsData.visits[y].mark, visited_at:visitsData.visits[y].visited_at, //id:visitsData.visits[y].id, }; } i++; } global.gc(); console.log("memory usage: " + parseInt(process.memoryUsage().heapTotal/1000000));
Итоговая таблица (таблица и все тесты опубликованы на гитхабе):
Хотел попробовать apc_cache и redis, но у них ещё дополнительно память тратится на хранения имён ключей. В реальной жизни можно использовать, но для этого чемпионата вообще не вариант.
Послесловие
После всех оптимизаций общее время составило 404 секунд, что почти в 4 раза медленнее, чем первое место.
Ещё раз спасибо организаторам, которые не спали по ночам, перезагружали зависшие контейнеры, фиксили баги, допиливали сайт, отвечали в телеграмме на вопросы.
Актуальные итоговые таблицы и сходный код всех тестов опубликованы на гитхабе:
сравнение скорости работы разных вебсерверов
сравнение расхода памяти разными структурами
Другая моя сегодняшняя статья на Хабре: бесплатный сервер в облаке
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Участвовал ли ты в highloadcup?
7.65%я не backend разработчик28
34.7%не участвовал и не хотел127
49.18%хотел, но пропустил / поздно узнал / не было времени180
8.47%участвовал31
Проголосовали 366 пользователей. Воздержались 97 пользователей.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Хотел бы ты поучаствовать в следующем подобном чемпионате для backend разработчиков?
61.89%да229
15.41%нет57
22.7%да, но не буду84
Проголосовали 370 пользователей. Воздержались 70 пользователей.

