Из блога Netflix Technology
Много лет основной целью системы персональных рекомендаций Netflix было выбрать правильные фильмы — и вовремя предложить их пользователям. С тысячами фильмов в каталоге и разносторонними предпочтениями клиентов на сотнях миллионов аккаунтов критически важно рекомендовать точные фильмы каждому из них. Но работа системы рекомендаций на этом не заканчивается. Что можно сказать о новом и незнакомом фильме, который вызовет ваш интерес? Как вас убедить, что он достоин просмотра? Очень важно ответить на эти вопросы, чтобы помочь людям открывать для себя новый контент, особенно незнакомые фильмы.
Один из вариантов решения проблемы — принять в учёт картинки или обложки для фильмов. Если картинка выглядит убедительно, то она служит толчком и неким визуальным «доказательством», что фильм достоин просмотра. На ней может быть изображён известный вам актёр, захватывающий момент вроде автомобильной погони или драматическая сцена, передающая суть фильма или сериала. Если мы покажем идеальную обложку фильма на вашей домашней странице (как говорится, картинка стоит тысячи слов), то возможно, только возможно, вы решитесь выбрать этот фильм. Это просто ещё одна вещь, в которой Netflix отличается от традиционных медиа: у нас не один продукт, а более 100 млн разных продуктов, а каждый из пользователей получает персональные рекомендации и персональные обложки.

Главная страница Netflix без обложек. Так исторически наши алгоритмы рекомендаций видели страницу
В предыдущей работе мы обсуждали, как найти одну идеальную обложку для каждого фильма для всех пользователей. С помощью алгоритмов многоруких бандитов мы искали лучшую обложку для конкретного фильма или сериала, например, «Очень странные дела» (Stranger Things). Эта картинка обеспечивала максимальное количество просмотров от максимального количества наших пользователей. Но учитывая невероятное разнообразие вкусов и предпочтений — не лучше ли будет подобрать оптимальную картинку для каждого из зрителей, чтобы подчеркнуть аспекты фильма, важные конкретно для него?

Обложки научно-фантастического сериала «Очень странные дела», каждую из которых наш алгоритм персонализации выбрал для более чем 5% показов. Разные картинки показывают широту тем в сериале и выходят за пределы того, что способна показать единственная обложка
Для вдохновения, давайте пройдёмся по вариантам, где персонализация обложек имеет смысл. Рассмотрим следующие примеры, где у разных пользователей разные истории просмотренных фильмов. Слева по три фильма, которые человек посмотрел в прошлом. Справа от стрелки — обложка, которую мы будем ему рекомендовать.
Попробуем подобрать персональную картинку для фильма «Умница Уилл Хантинг». Здесь мы можем вывести решение исходя из того, в какой степени пользователь предпочитает разные жанры и тематику. Если человек смотрел много романтических фильмов, то «Умница Уилл Хантинг» может привлечь его внимание картинкой Мэтта Дэймона и Минни Драйвер. А если человек смотрел много комедий, то может заинтересоваться этим фильмом, увидев изображение Робби Уильямса, известного комедийного актёра.

В другом случае представим, как разные предпочтения относительно актёрского состава могут повлиять на персонализацию обложки для «Криминального чтива». Если пользователь смотрел много фильмов с Умой Турман, то он с большей вероятностью положительно отреагирует на обложку «Криминального чтива» с Умой. В то же время фанат Джона Траволты может больше заинтересоваться просмотром фильма, если увидит Джона на обложке.

Конечно, не все задачи персонализации обложки решаются настолько просто. Так что не будем полагаться на вручную прописанные правила, а положимся на сигналы из данных. В целом, с помощью персонализации обложек мы помогаем каждому отдельному изображению проложить наилучший путь к каждому пользователю, тем самым улучшая качество работы сервиса.
Мы в Netflix алгоритмически адаптируем многие аспекты работы сайта персонально для каждого пользователя, в том числе ряды на главной странице, фильмы для этих рядов, галереи для показа, наши сообщения и так далее. Каждый новый аспект, который мы подвергаем персонализации, выдвигает новые вызовы. Персонализация обложек — не исключение, здесь свои уникальные проблемы.
Одна из проблем в том, что мы можем использовать только единственный экземпляр изображения для показа пользователю. По контрасту, типичные настройки рекомендаций позволяют демонстрировать пользователю разные варианты, так что мы можем постепенно изучить его предпочтения исходя из сделанных выборов. Это означает, что выбор картинки — проблема курицы и яйца в замкнутом цикле: человек выбирает фильмы только с картинками, которые мы решили подобрать для него. Что мы пытаемся понять — так это когда показ конкретной обложки подтолкнул человека к просмотру фильма (или нет), а когда человек посмотрел бы фильм (или нет) независимо от обложки. Поэтому персонализация обложек сочетает вместе разные алгоритмы. Конечно, для правильной персонализации обложек нужно собрать много данных, чтобы найти сигналы о том, какие конкретные экземпляры обложек имеют значительное преимущество над остальными для конкретного пользователя.
Другая проблема — понять влияние изменения обложки, которую мы показываем пользователю в разных сессиях. Уменьшает ли изменение обложки узнаваемость фильма и усложняет ли его визуальный поиск, например, если пользователь раньше заинтересовался фильмом, но ещё не посмотрел его? Или же изменение обложки способствует изменению решения благодаря улучшенному подбору картинки? Очевидно, если мы нашли лучшую обложку для этого человека — следует её использовать; но постоянные изменения могут запутать пользователя. Изменяющиеся картинки вызывают проблему атрибуции, поскольку становится неясно, какая обложка вызвала интерес к фильму у пользователя.
Далее, есть проблема понимания, как взаимодействуют между собой обложки на одной странице или в одной сессии. Может быть, жирный крупный план главного героя эффективен для фильма, потому что выделяется среди других обложек на странице. Но если у всех обложек будут похожие характеристики, то страница в целом потеряет свою привлекательность. Может быть недостаточно рассмотрения каждой обложки в отдельности и нужно продумать о выборе разнообразного набора обложек на странице или в течение сессии. Кроме соседних обложек, эффективность каждой конкретной обложки может зависеть ещё от того, какие ещё факты и ресурсы (например, синопсис, трейлеры и проч.) мы показываем для этого фильма. Появляются разнообразные сочетания, в которых каждый объект подчёркивает дополнительные аспекты фильма, повышая шансы положительно воздействовать на зрителя.
Для эффективной персонализации требуется хороший набор обложек для каждого фильма. Это значит, что требуются различные ресурсы, каждый из которых привлекательный, информативный и показательный для фильма, чтобы избежать «кликбейта». Набор изображений для фильма также должен быть достаточно разнообразным, чтобы покрыть широкую потенциальную аудиторию, заинтересованную в разных аспектах контента. В конце концов, насколько привлекательна и информативна конкретная обложка — зависит от индивидуального человека, который её видит. Поэтому нужны художественные работы, подчёркивающие не только разную тематику в фильме, но и разную эстетику. Наши группы художников и дизайнеров как могут стараются создать картинки, разнообразные по всем параметрам. Они принимают в учёт и алгоритмы персонализации, выбирающие картинки во время креативного процесса их создания.
Наконец, у инженеров задача обеспечить персонализацию обложек в большом масштабе. Сайт активно использует изображения — и поэтому на нём много картинок. Так что персонализация каждого ресурса означает обработку в пике более 20 млн запросов в секунду с маленькой задержкой. Такая система должна быть надёжной: неправильный рендеринг обложки в нашем UI значительно ухудшит впечатление от сайта. Наш движок персонализации также должен быстро реагировать на выход новых фильмов, то есть быстро осваивать персонализацию в ситуации холодного старта. Затем после запуска алгоритм должен непрерывно адаптироваться, поскольку эффективность обложек может изменяться со временем — это зависит и от жизненного цикла фильма, и от изменения вкусов зрителей.
Движок рекомендаций Netflix во многом работает на алгоритмах машинного обучения. Традиционно мы собираем много данных об использовании сервиса пользователями. Затем запускаем новый алгоритм машинного обучения на этом пакете данных. Затем тестируем его в продакшне через A/B-тесты на случайной выборке пользователей. Такие тесты позволяют убедиться, что новый алгоритм лучше, чем текущая система в продакшне. Пользователям в группе A дают текущую систему в продакшне, а пользователям в группе B — результат работы нового алгоритма. Если группа B демонстрирует большее вовлечение в работу сервиса Netflix, то мы выкатываем новый алгоритм на всю аудиторию. К сожалению, при таком подходе многие пользователи в течение долгого времени не могут пользоваться новой системой, как показано на иллюстрации внизу.

Чтобы уменьшить период времени недоступности нового сервиса, мы отказались от пакетного метода машинного обучения в пользу онлайнового метода. Для персонализации обложек мы используем конкретный фреймворк машинного обучения — контекстных бандитов (contextual bandits). Вместо ожидания сбора полного пакета данных, ожидания обучения модели, а затем ожидания завершения A/B-тестов, контекстные бандиты быстро определяют оптимальный выбор обложки фильма для каждого пользователя и контекста. Вкратце, контекстные бандиты — это класс алгоритмов машинного обучения в онлайне, которые компенсируют затраты на сбор данных обучения, необходимых для непрерывного обучения непредвзятой модели, преимуществами применения обученной модели в контексте каждого пользователя. В нашей предыдущей работе по выбору оптимальных обложек без персонализации использовались неконтекстные бандиты, которые находили лучшую обложку независимо от контекста. В случае с персонализацией учитывается контекст конкретного пользователя, поскольку каждый из них по-разному воспринимает каждое изображение.
Ключевое свойство контекстных бандитов — то, что они уменьшают период недоступности сервиса. На высоком уровне данные для обучения контекстного бандита поступают посредством внедрения управляемой рандомизации в предсказания обученной модели. Схемы рандомизации могут быть разной сложности: от простых эпсилон-жадных алгоритмов с равномерным распределением случайности до схем замкнутого цикла, которые адаптивно изменяют степень рандомизации, которая является функцией неопределённости параметров модели. Мы в широком смысле называем этот процесс изучением данных. Выбор стратегии для изучения зависит от количества обложек-кандидатов в наличии и количества пользователей, для которых развёртывается система. С таким изучением данных требуется записывать в журнал информацию о рандомизации каждого выбора обложки. Этот журнал позволяет корректировать искажённые отклонения от выбора и, таким образом, беспристрастно выполнять автономную оценку модели, как описано ниже.
Изучение данных с контекстными бандитами обычно имеет свою цену, поскольку выбор обложки во время пользовательской сессии с некоторой вероятностью может не совпадать с самой оптимальной предсказанной обложкой для этой сессии. Как такая рандомизация влияет на впечатление от работы с сайтом (а следовательно, и на наши метрики)? На базе из более 100 млн пользователей потери из-за изучения данных обычно очень малы и амортизируются на большой пользовательской базе, поскольку каждый пользователь неявно помогает обеспечить обратную связь для обложек в небольшой части каталога. Это делает ничтожными потери из-за изучения данных в расчёте на каждого пользователя, что важно принимать в учёт при выборе контекстных бандитов для ключевого аспекта взаимодействия пользователя с сайтом. Рандомизация и изучении данных с контекстными бандитами были бы менее привлекательны в случае бóльших потерь.
В нашей онлайновой схеме изучения мы получаем набор данных для обучения, где для каждого элемента набора взаимосвязанных данных (пользователь, фильм, обложка) указано, привёл ли такой выбор к решению посмотреть фильм или нет. Более того, мы можем контролировать процесс изучения таким образом, чтобы выбор обложек не слишком часто изменялся. Это даёт более чёткую атрибуцию привлекательности конкретной обложки для пользователя. Мы также тщательно следим за показателями и избегаем «кликбейта» при обучении модели рекомендовать определённые обложки, в результате которых пользователь начинает просмотр фильма, но в итоге остаётся неудовлетворённым.
В этой настройке онлайнового обучения мы тренируем модель контекстуального бандита выбирать лучшую обложку для каждого пользователя в зависимости от его контекста. Обычно у нас есть несколько десятков обложек-кандидатов на каждый фильм. Для обучения модели мы можем упростить проблему, сделав ранжирование обложек. Даже с таким упрощением мы по-прежнему получаем информацию о предпочтениях пользователя, поскольку каждая обложка-кандидат нравится одним пользователям и не нравится другим. Эти предпочтения используются для предсказания эффективности каждой триады (пользователь, фильм, обложка). Наилучшие предсказания с изучением данных даёт грамотный баланс моделей обучения с учителем или контекстных бандитов с методами оценки Томпсона (Thompson Sampling), LinUCB или байесовскими.
В контекстных моделях контекст обычно представлен как вектор признака, который используется как входные данные модели. На роль признаков подходят многие сигналы. В частности, это многие атрибуты пользователя: просмотренные фильмы, жанры фильмов, взаимодействие пользователя с конкретным фильмом, его страна, язык, используемое устройство, время дня и день недели. Поскольку алгоритм выбирает обложки вместе с движком рекомендации фильмов, мы также можем использовать сигналы о том, что различные алгоритмы рекомендаций думают о названии, независимо от обложки.
Важным соображением является то, что некоторые изображения очевидно сами по себе лучше других в пуле кандидатов. Мы отмечаем общую долю просмотров (take rates) для всех изображений в изучении данных. Эти коэффициенты попросту представляют собой количество качественных просмотров, поделенное на количество показов. В нашей предыдущей работе по выбору обложек без персонализации изображение выбиралось по общему коэффициенту эффективности для всей аудитории. В новой модели контекстной персонализации общий коэффициент по-прежнему важен и учитывается при подборе обложки для конкретного пользователя.
После вышеописанного обучения модели она используется для ранжирования изображений в каждом контексте. Модель предсказывает вероятность просмотра фильма для данной обложки в данном контексте пользователя. По этим вероятностям мы сортируем набор обложек-кандидатов и выбираем ту, которая даёт самую большую вероятность. Её мы показываем конкретному пользователю.
Наши алгоритмы контекстных бандитов перед выкатыванием в онлайн сначала оцениваются в офлайне с помощью техники, известной как повтор (replay) [1]. Этот метод позволяет ответить на гипотетические вопросы на основании записей в логе изучения данных (рис. 1). Другими словами, мы можем в офлайне сравнить, что бы происходило в исторических сессиях в разных сценариях при использовании разных алгоритмов непредвзятым способом
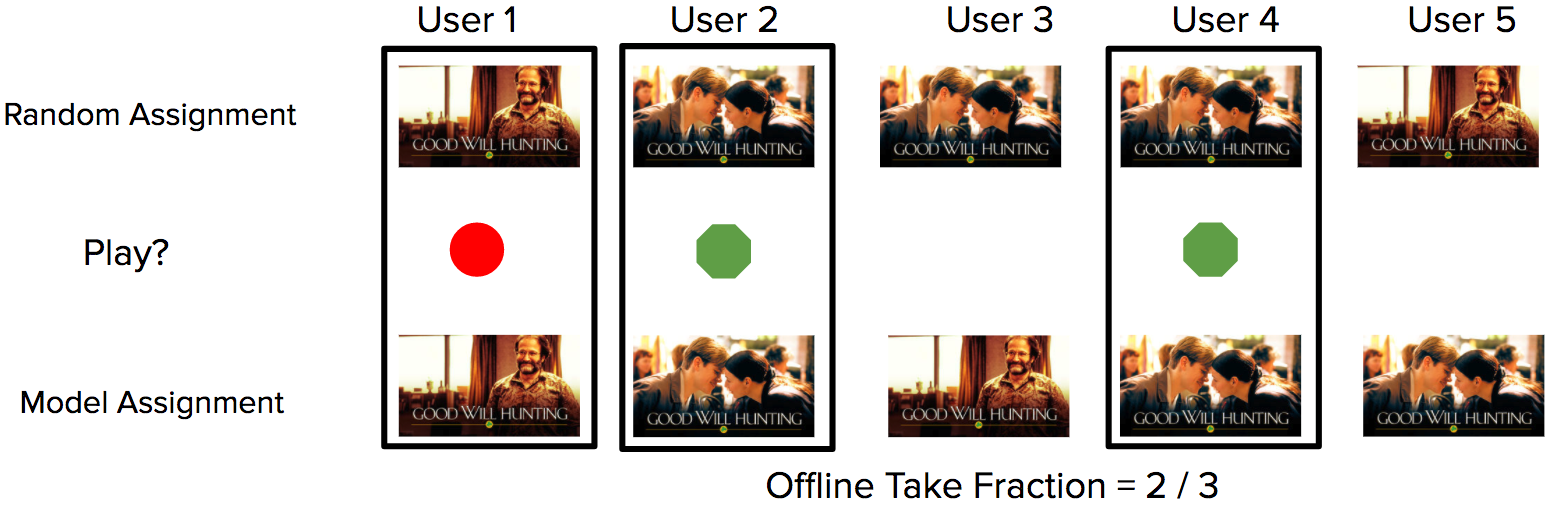
Рис. 1. Простой пример вычисления метрики replay на основании данных из лога. Каждому пользователю назначается случайное изображение (верхний ряд). Система регистрирует в логе показ обложки и факт, запустил пользователь фильм на воспроизведение (зелёный кружок) или нет (красный). Метрика для новой модели рассчитывается путём сопоставления профилей, где случайные назначения и назначения модели одинаковы (чёрный квадрат) и рассчитывая в этом подмножестве долю успешных запусков (take fraction).
Метрика replay показывает, насколько изменится процент пользователей, запустивших фильм, при использовании нового алгоритма по сравнению с алгоритмом, который используется сейчас в продакшне. Для обложек нас интересует несколько метрик, в том числе доля успешных запусков, описанная выше. На рис. 2 показано, как контекстный бандит помогает увеличить долю запусков в каталоге по сравнению со случайным выбором или неконтекстным бандитом.

Рис. 2: Средняя доля запусков (чем больше, тем лучше) для разных алгоритмов на основании метрики replay из лога изучения данных по изображениям. Правило Random (зелёным) выбирает одну картинку случайным образом. Простой алгоритм Bandit (жёлтым) выбирает изображение с самой большой долей запусков. Алгоритмы контекстных бандитов (голубой и розовый) используют контекст для подбора разных изображений разным пользователям.

Рис. 3: Пример контекстного выбора изображения в зависимости от типа профиля. «Комедийный» соответствует профилю, который смотрит преимущественно комедии. Аналогично «романтичный» профиль смотрит преимущественно романтичные фильмы. Контекстный бандит выбирает изображение Робина Уильямса, известного комедийного актёра, для склонных к комедиям профилей, в то же время выбирая изображение целующейся пары для профилей, более склонных к романтике.
После офлайновых экспериментов с многими разными моделями мы определили те, которые демонстрируют значительное увеличение метрики replay — и в итоге запустили A/B-тестирование для сравнения наиболее многообещающих контекстных бандитов персонализации по сравнению с бандитами без персонализации. Как и ожидалось, персонализация сработала и привела к значительному росту наших ключевых метрик. Мы также увидели разумную корреляцию между офлайновой метрикой replay и онлайновыми показателями. Онлайновые результаты дали ещё и несколько интересных инсайтов. Например, персонализация показала больший эффект в случае, если пользователь раньше не сталкивался с фильмом. Это имеет смысл: логично предположить, что обложка важнее для людей, менее знакомых с фильмом.
Используя этот подход мы предприняли первые шаги по персонализации подбора обложек для наших рекомендаций и на сайте. Результатом стало значимое улучшение в том, как пользователи находят новый контент… так что мы выкатили систему для всех! Этот пример — первый пример персонализации не только того, что мы рекомендуем нашим пользователям, но и того, как мы это рекомендуем. Но есть много возможностей расширить и улучшить первоначальный подход. Это в том числе разработка алгоритмов для холодного старта, когда персонализация новых обложек и новых фильмов осуществляется максимально быстро, например, с применением техник машинного зрения. Другая возможность — расширение подхода персонализации на другие типы используемых обложек и на другие информационные фрагменты в описании фильма: синопсисы, метаданные и трейлеры. Есть и более широкая проблема: помочь художникам и дизайнерам определить, какие новые обложки нужно добавить в набор, чтобы сделать фильм ещё более привлекательным для разных типов аудитории.
[1] L. Li, W. Chu, J. Langford, X. Wang, “Unbiased Offline Evaluation of Contextual-bandit-based News Article Recommendation Algorithms” в сборнике Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, New York, NY, USA, 2011, стр. 297–306.
Много лет основной целью системы персональных рекомендаций Netflix было выбрать правильные фильмы — и вовремя предложить их пользователям. С тысячами фильмов в каталоге и разносторонними предпочтениями клиентов на сотнях миллионов аккаунтов критически важно рекомендовать точные фильмы каждому из них. Но работа системы рекомендаций на этом не заканчивается. Что можно сказать о новом и незнакомом фильме, который вызовет ваш интерес? Как вас убедить, что он достоин просмотра? Очень важно ответить на эти вопросы, чтобы помочь людям открывать для себя новый контент, особенно незнакомые фильмы.
Один из вариантов решения проблемы — принять в учёт картинки или обложки для фильмов. Если картинка выглядит убедительно, то она служит толчком и неким визуальным «доказательством», что фильм достоин просмотра. На ней может быть изображён известный вам актёр, захватывающий момент вроде автомобильной погони или драматическая сцена, передающая суть фильма или сериала. Если мы покажем идеальную обложку фильма на вашей домашней странице (как говорится, картинка стоит тысячи слов), то возможно, только возможно, вы решитесь выбрать этот фильм. Это просто ещё одна вещь, в которой Netflix отличается от традиционных медиа: у нас не один продукт, а более 100 млн разных продуктов, а каждый из пользователей получает персональные рекомендации и персональные обложки.
Главная страница Netflix без обложек. Так исторически наши алгоритмы рекомендаций видели страницу
В предыдущей работе мы обсуждали, как найти одну идеальную обложку для каждого фильма для всех пользователей. С помощью алгоритмов многоруких бандитов мы искали лучшую обложку для конкретного фильма или сериала, например, «Очень странные дела» (Stranger Things). Эта картинка обеспечивала максимальное количество просмотров от максимального количества наших пользователей. Но учитывая невероятное разнообразие вкусов и предпочтений — не лучше ли будет подобрать оптимальную картинку для каждого из зрителей, чтобы подчеркнуть аспекты фильма, важные конкретно для него?
Обложки научно-фантастического сериала «Очень странные дела», каждую из которых наш алгоритм персонализации выбрал для более чем 5% показов. Разные картинки показывают широту тем в сериале и выходят за пределы того, что способна показать единственная обложка
Для вдохновения, давайте пройдёмся по вариантам, где персонализация обложек имеет смысл. Рассмотрим следующие примеры, где у разных пользователей разные истории просмотренных фильмов. Слева по три фильма, которые человек посмотрел в прошлом. Справа от стрелки — обложка, которую мы будем ему рекомендовать.
Попробуем подобрать персональную картинку для фильма «Умница Уилл Хантинг». Здесь мы можем вывести решение исходя из того, в какой степени пользователь предпочитает разные жанры и тематику. Если человек смотрел много романтических фильмов, то «Умница Уилл Хантинг» может привлечь его внимание картинкой Мэтта Дэймона и Минни Драйвер. А если человек смотрел много комедий, то может заинтересоваться этим фильмом, увидев изображение Робби Уильямса, известного комедийного актёра.
В другом случае представим, как разные предпочтения относительно актёрского состава могут повлиять на персонализацию обложки для «Криминального чтива». Если пользователь смотрел много фильмов с Умой Турман, то он с большей вероятностью положительно отреагирует на обложку «Криминального чтива» с Умой. В то же время фанат Джона Траволты может больше заинтересоваться просмотром фильма, если увидит Джона на обложке.
Конечно, не все задачи персонализации обложки решаются настолько просто. Так что не будем полагаться на вручную прописанные правила, а положимся на сигналы из данных. В целом, с помощью персонализации обложек мы помогаем каждому отдельному изображению проложить наилучший путь к каждому пользователю, тем самым улучшая качество работы сервиса.
Проблемы
Мы в Netflix алгоритмически адаптируем многие аспекты работы сайта персонально для каждого пользователя, в том числе ряды на главной странице, фильмы для этих рядов, галереи для показа, наши сообщения и так далее. Каждый новый аспект, который мы подвергаем персонализации, выдвигает новые вызовы. Персонализация обложек — не исключение, здесь свои уникальные проблемы.
Одна из проблем в том, что мы можем использовать только единственный экземпляр изображения для показа пользователю. По контрасту, типичные настройки рекомендаций позволяют демонстрировать пользователю разные варианты, так что мы можем постепенно изучить его предпочтения исходя из сделанных выборов. Это означает, что выбор картинки — проблема курицы и яйца в замкнутом цикле: человек выбирает фильмы только с картинками, которые мы решили подобрать для него. Что мы пытаемся понять — так это когда показ конкретной обложки подтолкнул человека к просмотру фильма (или нет), а когда человек посмотрел бы фильм (или нет) независимо от обложки. Поэтому персонализация обложек сочетает вместе разные алгоритмы. Конечно, для правильной персонализации обложек нужно собрать много данных, чтобы найти сигналы о том, какие конкретные экземпляры обложек имеют значительное преимущество над остальными для конкретного пользователя.
Другая проблема — понять влияние изменения обложки, которую мы показываем пользователю в разных сессиях. Уменьшает ли изменение обложки узнаваемость фильма и усложняет ли его визуальный поиск, например, если пользователь раньше заинтересовался фильмом, но ещё не посмотрел его? Или же изменение обложки способствует изменению решения благодаря улучшенному подбору картинки? Очевидно, если мы нашли лучшую обложку для этого человека — следует её использовать; но постоянные изменения могут запутать пользователя. Изменяющиеся картинки вызывают проблему атрибуции, поскольку становится неясно, какая обложка вызвала интерес к фильму у пользователя.
Далее, есть проблема понимания, как взаимодействуют между собой обложки на одной странице или в одной сессии. Может быть, жирный крупный план главного героя эффективен для фильма, потому что выделяется среди других обложек на странице. Но если у всех обложек будут похожие характеристики, то страница в целом потеряет свою привлекательность. Может быть недостаточно рассмотрения каждой обложки в отдельности и нужно продумать о выборе разнообразного набора обложек на странице или в течение сессии. Кроме соседних обложек, эффективность каждой конкретной обложки может зависеть ещё от того, какие ещё факты и ресурсы (например, синопсис, трейлеры и проч.) мы показываем для этого фильма. Появляются разнообразные сочетания, в которых каждый объект подчёркивает дополнительные аспекты фильма, повышая шансы положительно воздействовать на зрителя.
Для эффективной персонализации требуется хороший набор обложек для каждого фильма. Это значит, что требуются различные ресурсы, каждый из которых привлекательный, информативный и показательный для фильма, чтобы избежать «кликбейта». Набор изображений для фильма также должен быть достаточно разнообразным, чтобы покрыть широкую потенциальную аудиторию, заинтересованную в разных аспектах контента. В конце концов, насколько привлекательна и информативна конкретная обложка — зависит от индивидуального человека, который её видит. Поэтому нужны художественные работы, подчёркивающие не только разную тематику в фильме, но и разную эстетику. Наши группы художников и дизайнеров как могут стараются создать картинки, разнообразные по всем параметрам. Они принимают в учёт и алгоритмы персонализации, выбирающие картинки во время креативного процесса их создания.
Наконец, у инженеров задача обеспечить персонализацию обложек в большом масштабе. Сайт активно использует изображения — и поэтому на нём много картинок. Так что персонализация каждого ресурса означает обработку в пике более 20 млн запросов в секунду с маленькой задержкой. Такая система должна быть надёжной: неправильный рендеринг обложки в нашем UI значительно ухудшит впечатление от сайта. Наш движок персонализации также должен быстро реагировать на выход новых фильмов, то есть быстро осваивать персонализацию в ситуации холодного старта. Затем после запуска алгоритм должен непрерывно адаптироваться, поскольку эффективность обложек может изменяться со временем — это зависит и от жизненного цикла фильма, и от изменения вкусов зрителей.
Подход контекстных бандитов
Движок рекомендаций Netflix во многом работает на алгоритмах машинного обучения. Традиционно мы собираем много данных об использовании сервиса пользователями. Затем запускаем новый алгоритм машинного обучения на этом пакете данных. Затем тестируем его в продакшне через A/B-тесты на случайной выборке пользователей. Такие тесты позволяют убедиться, что новый алгоритм лучше, чем текущая система в продакшне. Пользователям в группе A дают текущую систему в продакшне, а пользователям в группе B — результат работы нового алгоритма. Если группа B демонстрирует большее вовлечение в работу сервиса Netflix, то мы выкатываем новый алгоритм на всю аудиторию. К сожалению, при таком подходе многие пользователи в течение долгого времени не могут пользоваться новой системой, как показано на иллюстрации внизу.
Чтобы уменьшить период времени недоступности нового сервиса, мы отказались от пакетного метода машинного обучения в пользу онлайнового метода. Для персонализации обложек мы используем конкретный фреймворк машинного обучения — контекстных бандитов (contextual bandits). Вместо ожидания сбора полного пакета данных, ожидания обучения модели, а затем ожидания завершения A/B-тестов, контекстные бандиты быстро определяют оптимальный выбор обложки фильма для каждого пользователя и контекста. Вкратце, контекстные бандиты — это класс алгоритмов машинного обучения в онлайне, которые компенсируют затраты на сбор данных обучения, необходимых для непрерывного обучения непредвзятой модели, преимуществами применения обученной модели в контексте каждого пользователя. В нашей предыдущей работе по выбору оптимальных обложек без персонализации использовались неконтекстные бандиты, которые находили лучшую обложку независимо от контекста. В случае с персонализацией учитывается контекст конкретного пользователя, поскольку каждый из них по-разному воспринимает каждое изображение.
Ключевое свойство контекстных бандитов — то, что они уменьшают период недоступности сервиса. На высоком уровне данные для обучения контекстного бандита поступают посредством внедрения управляемой рандомизации в предсказания обученной модели. Схемы рандомизации могут быть разной сложности: от простых эпсилон-жадных алгоритмов с равномерным распределением случайности до схем замкнутого цикла, которые адаптивно изменяют степень рандомизации, которая является функцией неопределённости параметров модели. Мы в широком смысле называем этот процесс изучением данных. Выбор стратегии для изучения зависит от количества обложек-кандидатов в наличии и количества пользователей, для которых развёртывается система. С таким изучением данных требуется записывать в журнал информацию о рандомизации каждого выбора обложки. Этот журнал позволяет корректировать искажённые отклонения от выбора и, таким образом, беспристрастно выполнять автономную оценку модели, как описано ниже.
Изучение данных с контекстными бандитами обычно имеет свою цену, поскольку выбор обложки во время пользовательской сессии с некоторой вероятностью может не совпадать с самой оптимальной предсказанной обложкой для этой сессии. Как такая рандомизация влияет на впечатление от работы с сайтом (а следовательно, и на наши метрики)? На базе из более 100 млн пользователей потери из-за изучения данных обычно очень малы и амортизируются на большой пользовательской базе, поскольку каждый пользователь неявно помогает обеспечить обратную связь для обложек в небольшой части каталога. Это делает ничтожными потери из-за изучения данных в расчёте на каждого пользователя, что важно принимать в учёт при выборе контекстных бандитов для ключевого аспекта взаимодействия пользователя с сайтом. Рандомизация и изучении данных с контекстными бандитами были бы менее привлекательны в случае бóльших потерь.
В нашей онлайновой схеме изучения мы получаем набор данных для обучения, где для каждого элемента набора взаимосвязанных данных (пользователь, фильм, обложка) указано, привёл ли такой выбор к решению посмотреть фильм или нет. Более того, мы можем контролировать процесс изучения таким образом, чтобы выбор обложек не слишком часто изменялся. Это даёт более чёткую атрибуцию привлекательности конкретной обложки для пользователя. Мы также тщательно следим за показателями и избегаем «кликбейта» при обучении модели рекомендовать определённые обложки, в результате которых пользователь начинает просмотр фильма, но в итоге остаётся неудовлетворённым.
Обучение модели
В этой настройке онлайнового обучения мы тренируем модель контекстуального бандита выбирать лучшую обложку для каждого пользователя в зависимости от его контекста. Обычно у нас есть несколько десятков обложек-кандидатов на каждый фильм. Для обучения модели мы можем упростить проблему, сделав ранжирование обложек. Даже с таким упрощением мы по-прежнему получаем информацию о предпочтениях пользователя, поскольку каждая обложка-кандидат нравится одним пользователям и не нравится другим. Эти предпочтения используются для предсказания эффективности каждой триады (пользователь, фильм, обложка). Наилучшие предсказания с изучением данных даёт грамотный баланс моделей обучения с учителем или контекстных бандитов с методами оценки Томпсона (Thompson Sampling), LinUCB или байесовскими.
Потенциальные сигналы
В контекстных моделях контекст обычно представлен как вектор признака, который используется как входные данные модели. На роль признаков подходят многие сигналы. В частности, это многие атрибуты пользователя: просмотренные фильмы, жанры фильмов, взаимодействие пользователя с конкретным фильмом, его страна, язык, используемое устройство, время дня и день недели. Поскольку алгоритм выбирает обложки вместе с движком рекомендации фильмов, мы также можем использовать сигналы о том, что различные алгоритмы рекомендаций думают о названии, независимо от обложки.
Важным соображением является то, что некоторые изображения очевидно сами по себе лучше других в пуле кандидатов. Мы отмечаем общую долю просмотров (take rates) для всех изображений в изучении данных. Эти коэффициенты попросту представляют собой количество качественных просмотров, поделенное на количество показов. В нашей предыдущей работе по выбору обложек без персонализации изображение выбиралось по общему коэффициенту эффективности для всей аудитории. В новой модели контекстной персонализации общий коэффициент по-прежнему важен и учитывается при подборе обложки для конкретного пользователя.
Выбор изображения
После вышеописанного обучения модели она используется для ранжирования изображений в каждом контексте. Модель предсказывает вероятность просмотра фильма для данной обложки в данном контексте пользователя. По этим вероятностям мы сортируем набор обложек-кандидатов и выбираем ту, которая даёт самую большую вероятность. Её мы показываем конкретному пользователю.
Оценка эффективности
Офлайн
Наши алгоритмы контекстных бандитов перед выкатыванием в онлайн сначала оцениваются в офлайне с помощью техники, известной как повтор (replay) [1]. Этот метод позволяет ответить на гипотетические вопросы на основании записей в логе изучения данных (рис. 1). Другими словами, мы можем в офлайне сравнить, что бы происходило в исторических сессиях в разных сценариях при использовании разных алгоритмов непредвзятым способом
Рис. 1. Простой пример вычисления метрики replay на основании данных из лога. Каждому пользователю назначается случайное изображение (верхний ряд). Система регистрирует в логе показ обложки и факт, запустил пользователь фильм на воспроизведение (зелёный кружок) или нет (красный). Метрика для новой модели рассчитывается путём сопоставления профилей, где случайные назначения и назначения модели одинаковы (чёрный квадрат) и рассчитывая в этом подмножестве долю успешных запусков (take fraction).
Метрика replay показывает, насколько изменится процент пользователей, запустивших фильм, при использовании нового алгоритма по сравнению с алгоритмом, который используется сейчас в продакшне. Для обложек нас интересует несколько метрик, в том числе доля успешных запусков, описанная выше. На рис. 2 показано, как контекстный бандит помогает увеличить долю запусков в каталоге по сравнению со случайным выбором или неконтекстным бандитом.
Рис. 2: Средняя доля запусков (чем больше, тем лучше) для разных алгоритмов на основании метрики replay из лога изучения данных по изображениям. Правило Random (зелёным) выбирает одну картинку случайным образом. Простой алгоритм Bandit (жёлтым) выбирает изображение с самой большой долей запусков. Алгоритмы контекстных бандитов (голубой и розовый) используют контекст для подбора разных изображений разным пользователям.
| Тип профиля | Оценка изображения А | Оценка изображения B |
|---|---|---|
| Комедийный | 5,7 | 6,3 |
| Романтичный | 7,2 | 6,5 |
Рис. 3: Пример контекстного выбора изображения в зависимости от типа профиля. «Комедийный» соответствует профилю, который смотрит преимущественно комедии. Аналогично «романтичный» профиль смотрит преимущественно романтичные фильмы. Контекстный бандит выбирает изображение Робина Уильямса, известного комедийного актёра, для склонных к комедиям профилей, в то же время выбирая изображение целующейся пары для профилей, более склонных к романтике.
Онлайн
После офлайновых экспериментов с многими разными моделями мы определили те, которые демонстрируют значительное увеличение метрики replay — и в итоге запустили A/B-тестирование для сравнения наиболее многообещающих контекстных бандитов персонализации по сравнению с бандитами без персонализации. Как и ожидалось, персонализация сработала и привела к значительному росту наших ключевых метрик. Мы также увидели разумную корреляцию между офлайновой метрикой replay и онлайновыми показателями. Онлайновые результаты дали ещё и несколько интересных инсайтов. Например, персонализация показала больший эффект в случае, если пользователь раньше не сталкивался с фильмом. Это имеет смысл: логично предположить, что обложка важнее для людей, менее знакомых с фильмом.
Заключение
Используя этот подход мы предприняли первые шаги по персонализации подбора обложек для наших рекомендаций и на сайте. Результатом стало значимое улучшение в том, как пользователи находят новый контент… так что мы выкатили систему для всех! Этот пример — первый пример персонализации не только того, что мы рекомендуем нашим пользователям, но и того, как мы это рекомендуем. Но есть много возможностей расширить и улучшить первоначальный подход. Это в том числе разработка алгоритмов для холодного старта, когда персонализация новых обложек и новых фильмов осуществляется максимально быстро, например, с применением техник машинного зрения. Другая возможность — расширение подхода персонализации на другие типы используемых обложек и на другие информационные фрагменты в описании фильма: синопсисы, метаданные и трейлеры. Есть и более широкая проблема: помочь художникам и дизайнерам определить, какие новые обложки нужно добавить в набор, чтобы сделать фильм ещё более привлекательным для разных типов аудитории.
Ссылки
[1] L. Li, W. Chu, J. Langford, X. Wang, “Unbiased Offline Evaluation of Contextual-bandit-based News Article Recommendation Algorithms” в сборнике Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, New York, NY, USA, 2011, стр. 297–306.

