
Рис. 1. Незначительное изменение глифа (формы конкретной литеры) кодирует цифровую информацию за счёт двухмерной матрицы вариантов начертания. Каждая точка в двухмерной координатной сетке генерирует соответствующий уникальный глиф
Специалисты по стеганографии придумали новый способ прятать шифровки в открытом канале. В данном случае — в открытом тексте. По мнению изобретателей, кроме естественного применения в разведке эту технологию можно использовать для скрытого внедрения метаданных, таких как водяные знаки.
Недавно на Хабре рассказывалось про фингерпринтинг текста непечатаемыми символами. Новая техника FontCode более изощрённая, но по сути похожа. И здесь обнаружить скрытое сообщение не так просто, даже сложнее, чем непечатаемые пробелы. В этом тексте никаких невидимых символов нет, а слегка изменённую форму букв сложно заметить на глаз и уж точно невозможно расшифровать, если вы не знаете принцип кодирования/декодирования.
Суть метода вкратце изложена на схеме и подробно объясняется в научной работе.

Главная инновация — кодирование путём незначительного изменения формы глифа. Каждая точка в двухмерной координатной сетке генерирует соответствующий уникальный глиф, а систематическое изменение каждого глифа позволяет внедрить длинную цифровую последовательность в аналоговый текст.
Вторая часть технологии — распознавание искажённых глифов. Авторы научной работы представили распознавание глифов как проблему классификации изображений. Получив изображение с рядом искажённых глифов, цель состоит в том, чтобы классифицировать каждый входной глиф этой буквы как один из списка по кодовой книге. Для этой цели была обучена сверточная нейронная сеть (CNN) на каждой букве в определённом шрифте.
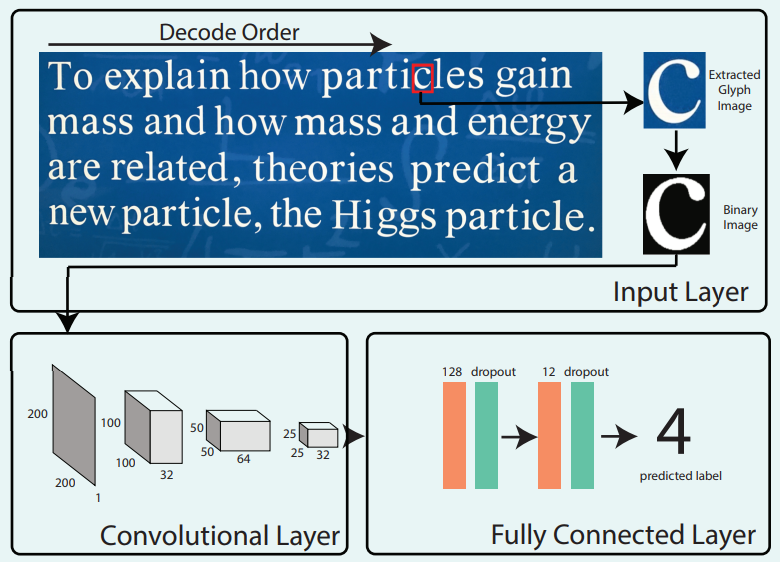
Чтобы распознать искажённый глиф каждой буквы с помощью CNN, изображение сначала предварительно обрабатывается c подготовкой данных для обучения нейросети, а также для уменьшения размерности обучающих данных. Область каждой буквы обрезается по рамке, установленной системой оптического распознавания символов. Затем осуществляется бинаризация области изображения с помощью классического алгоритма Otsu. Этот шаг помогает устранить влияние, вызванное различными условиями освещения и цветами фона. Наконец, размер области изображения изменяется до квадрата 200×200 пикселей. Такие чёрно-белые изображения 200×200 подаются для обучения в нейросеть. Обученная нейросеть способна распознавать изображения, непосредственно синтезированные или полученные с цифровых камер, то есть когда пользователь наводит камеру смартфона на текст со скрытой шифровкой, так же как он наводит камеру на QR-код. Соответственно, обучающие данные для CNN состояли из синтетических изображений и реальных фотографий. Эти синтетические данные были созданы фотореалистичным визуализатором с различными настройками экспозиции.
Схема кодирования предусматривает разбиение текста на блоки по пять символов. Каждому блоку назначается число от 0 до 255 в кодировке ASCII, которое внедряется в глифы путём изменения их формы. При декодировании выполняется обратная процедура, когда числа извлекаются из глифов.

При выборе глифов для стенографического внедрения цифр применяется схема кодирования с оценкой максимального правдоподобия и коррекцией ошибок на базе китайской теоремы об остатках 1700-летней давности. Это гарантирует восстановление оригинального сообщения с ограничением частоты ошибок не более установленной.
В каком-то смысле техника FontCode похожа на штрих-коды и QR-коды, ведь там полоски разной толщины или чёрно-белые квадраты кодируют цифровую информацию. Здесь примерно так же цифровая информация кодируется формой глифов.
Кроме стеганографического внедрения секретного послания в открытый текст FontCode допускает и использование шифрования. В этом случае отправитель и получатель должны предварительно согласовать секретный ключ для расшифровки сообщения. Шифровку можно спокойно передавать в открытом виде — через интернет или в виде бумажной распечатки. Человек видит обычный текст, а компьютер с системой OCR и специально обученной нейросетью распознаёт в этом тексте скрытое послание.
Научная работа с описанием технологии FontCode подготовлена для конференции SIGGRAPH, которая пройдёт в августе 2018 года в канадском Ванкувере.

