Завтра будут официальные пресс-релизы о слиянии старожила Silicon Valley, компании MIPS, с молодой AI компанией Wave Computing. Информация об этом событии просочилась в СМИ вчера, и вскоре CNet, Forbes, EE Times и куча хайтек-сайтов вышла со статьями об этом событии. Поэтому сегодня Derek Meyer, президент объединенной компании (на фото снизу справа), сказал «ладно, распостраняйте инфо среди друзей» и я решил написать пару слов о технологиях и людях, связанных с этим событием.
Главный инвестор в MIPS и Wave — миллиардер Dado Banatao (на фото снизу в центре слева), который еще в 1980-х основал компанию Chips & Technoilogies, которая делала чипсеты для ранних персоналок. В Wave+MIPS есть и другие знаменитости, например Стивен Джонсон (на фото справа вверху), автор самого популярного C-компилятора начала 1980-х годов. MIPS хорошо известен и в России. В руках дизайнерши Смрити (на фото слева) плата из Зеленограда, где находятся лицензиаты MIPS Элвис-НеоТек и Байкал Электроникс.
Wave уже выпустила чип, который состоит из тысяч вычислительных блоков, по сути упрощенных процессоров. Эта конструкция оптимизирована для очень быстрых вычислений нейронных сетей. У Wave есть компилятор, который превращает dataflow граф в файл конфигурации для этой структуры.
Объединенная компания создаст чип, который состоит из смеси таких вычислительных блоков и многопоточных ядер MIPS. Сейчас Wave продает свою технологию в виде ящика для дата-центров, для вычислений нейронных сетей в облаке. Следующие чипы будут использоваться во встроенных устройствах.
Нейронные сети традиционно представляют в виде dataflow-графа. Это граф, в узлах которого находятся константы, переменные и арифметические операции над скалярами, векторами и матрицами:

Компания Google создала библиотеку TensorFlow, которая является API-ем для строительства таких графов и запуска вычислений на сетке — как обычного inference, так и тренировки с помощью backpropfgftion. Этот API чаще всего используется вместе с питоном, код на котором выглядит вот так:

При этом питон в примере выше использует переопределение арифметических операций, которые на самом деле не вычисляют, а строят граф в памяти. На C код для строительства графа в TensorFlow выглядит так:

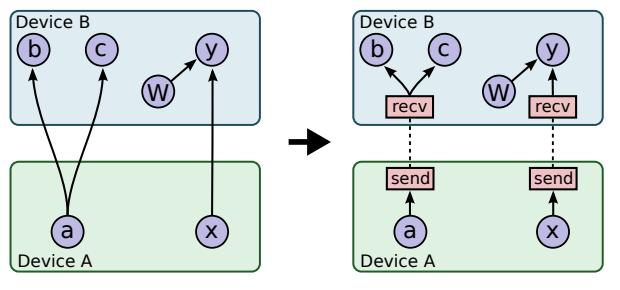
В Гугле у меня есть знакомый украинский программист Михаил Симбирский, который использует TensorFlow на питоне. Гугловские нейросети используются например для анализа поведения пользователей с целью таргетирования им рекламы. Некоторые вычисления для тренировки нейросетей в гугле занимают дни и недели, несмотря на то, что гуглы используют NVidia GPU и собственные гугловские акселераторы. Это дело непростое, так как передача данных между процессорами и GPU отнимает много времени:
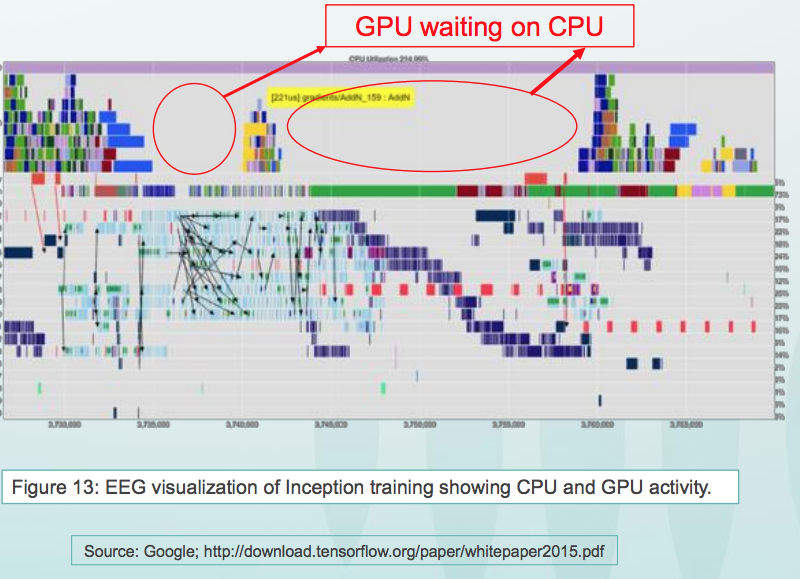
Одна из проблем конструкции из процессоров и GPU заключается в том, что GPU подолгу простаивает:
Другая проблема — недостаточная пропускная способность интерфейсов к памяти. Wave в комбинации с MIPS собирается решить и одну и другую проблему. В новых изделиях не процессор будет использовать акселератор как сопроцессор, а они будут работать вместе.
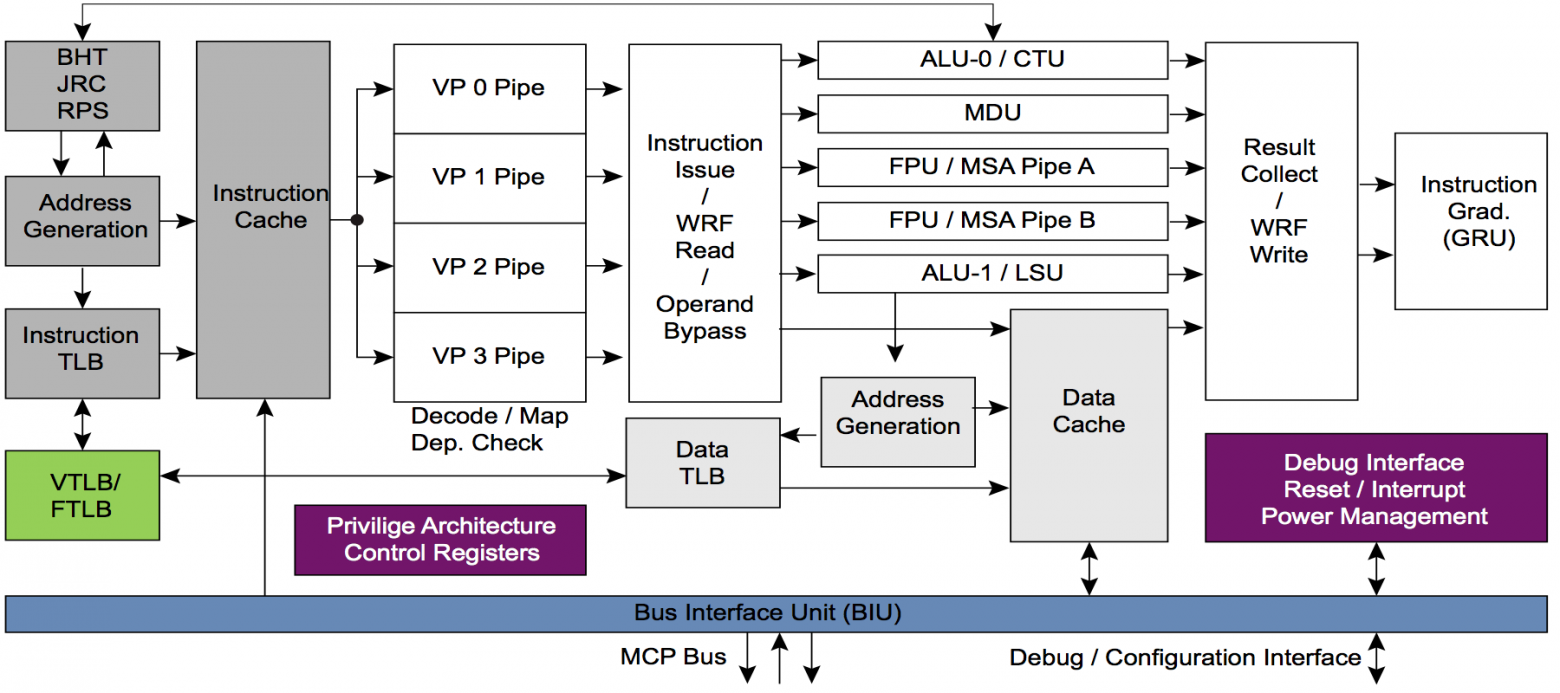
Для этого ядра MIPS будут модифицироваться, чтобы в конечном итоге создать стандартную аппаратную платформу для AI. Преимущество ядер MIPS I6400/I6500 («Самурай/Даймио») и MIPS I7200 (которое лицензировал MediaTek) — это многопоточность. Многопоточности у ARM нет. Вот как выглядит многопоточный конвейер у ядра MIPS I6400:
А теперь внимание вопрос к самым сообразительным комментаторам: какое, по-вашему, преимущество дает многопоточность для комбинации из CPU и аппаратного акселератора? В частности акселератора от Wave, который является вариантом так называемого CGRA — Coarse Grained Reconfigurable Array — крупнозернистых реконфигурируемых массивов.
Если вы знакомы с FPGA (Field Programmable Gate Array) / ПЛИС (Программируемые Логические Интегральные Схемы), то идея CGRA в чем-то похожа, но они работают не с отдельными битами, а с целыми шинами по 8-64 бита и в каждой ячейке есть ALU, а для нескольких ячеек — арифметический сопроцессор. Вот так выглядит все иерархия:
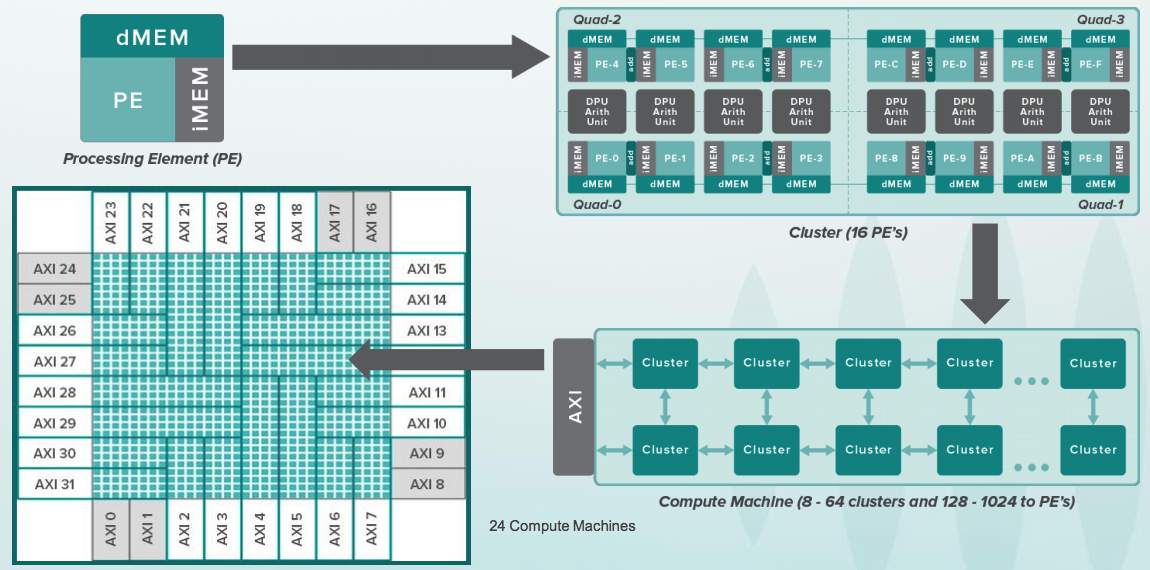
А вот так выглядит одна реконфигурируемая ячейка. У нее есть небольшой буфер с инструкциями, которые напоминают простые команды 8-битных аккумуляторных микроконтроллеров, например 6502 который стоял в первых компьютерах Apple. При этом, процессоры в древних Apple работали с частотой пару мегагерц, а ячейки в CGRA работают с частотой несколько гигагерц. Кроме этого в Apple процессор был один, а тут таких ячеек 16 тысяч:

Кристалл у Wave получается понятно огромный, поэтому приходится использовать локально-синхронные схемы с тактовым сигналом на каждую группу из ячеек. Но самая большая проблема — это не аппаратная, а программная. Граф для вычисления сетки приходится раскидывать на эту кучу устройств с точным знанием, в каком цикле будет что вычисляться. Это называется static scheduling. Поэтому Wave нанял кучу компиляторщиков, включая известнейшего зубра — Стивена Джонсона, который стоял у истоков вместе с Керниганом и Ричи. Вот что писал про Стивена Джонсона Деннис Ритчи:
В 1980-е Си быстро набирал популярность и компиляторы стали доступны практически на каждой машине и операционной системе; в частности, он стал популярным как язык программирования для персональных компьютеров, причем одновременно как для разработчиков коммерческого программного обеспечения для этих машин, так и для рядовых пользователей, увлекающихся программированием. В начале десятилетия практически каждый компилятор был основан на pcc Джонсона; к 1985 было уже много компиляторов, созданных независимыми разработчиками.Когда мне было 18 лет (в 1988 году) и я был студентом МФТИ, Стивен Джонсон был моим Богом. Я участвовал в разработке двух компиляторов на основе его Portable C Compiler. Один компилятор был для Электроники СС БИС, «Красного Крея», советского аналога векторного суперкомпьютера Cray-1. Второй компилятор был для Орбиты 20-700, встроенного компьютера в советских истребителях МиГ-29 и других начала 1980-х годов.
Поэтому я просто обязан был сфотографироваться с Стивеном Джонсоном. Он рассказал мне про другие тулы, которые он делал как для Unix, так и для автоматизации проектирования, автоматического профилирования и т.д.

И разумеется сфотографировался и с инвестором во все это дело Дадо Банатао. Давным-давно Дадо Банатао создал чипсет для первых писишек. Он отлаживал драйверы вместе с Балмером. «Иногда в комнату заходил Билл Гейтс, который нам мешал» — говорит Дадо Банатао. Теперь у него, согласно интернету, пять миллиардов долларов. Он самый известный хай-тек филлипинец, создает центр AI и ведет другие образовательные программы на своей родине.

Больше всего денег Дадо Банатао сделал на компании Marvell. Вот ее офис в Санта-Кларе в лучах вечернего солнца:

В Wave работает много людей которые раньше работали в MIPS. А некоторые из MIPS было в Silicon Graphics, так как MIPS был частью Silicon Graphics в 1990-е годы. В те времена процессоры MIPS стояли в графических станциях, которые использовались в Голливуде для съемок первых реалистичных графических фильмов типа «Парк Юрского Периода». Вот эти графические станции вместе с сибирской девушкой Ириной в Музее Истории Компьютеров в Маунтин-Вью, Калифорния:

В конце сегодняшнего парти в честь завтрашнего официального объявления и вчерашних публикаций в прессе состоялось поедание тортов и распивание шампанского:

Завтра будет много работы — от Verilog RTL (моих прямых обязанностей) до обсуждения архитектуры, приложений и даже разговоров с data scientist-ами (они себя ощущают из другой Вселенной, причем это взаимно и с электронщиками, и с компиляторщиками).
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Какие области искусственного интеллекта вас интересуют больше всего?
53.93%Приложения для распознавания изображений48
40.45%Приложения для анализа текста36
33.71%Приложения для самоуправляемых автомобилей30
31.46%Математика для AI28
22.47%Написание библиотек AI-алгоритмов20
29.21%Ускорение AI алгоритмов с помощью GPU26
15.73%Компиляторы из алгоритмов в dataflow граф14
13.48%Компиляторы из dataflow граф в конфигурацию CGRA12
26.97%Архитектура систем из процессоров и ускорителей24
17.98%Создание блоков ускорителей на уровне регистровых передач16
24.72%Физика очень больших чипов для AI22
5.62%Другое (рассказать в комментариях)5
Проголосовали 89 пользователей. Воздержались 26 пользователей.

