Начиная с 2018 года российский Центробанк (как регулятор) обязал некредитные финансовые организации (НФО), т.е. все предприятия финансового сектора экономики, кроме банков, а именно страховые, пенсионные фонды, проф. участники рынка ценных бумаг, управляющие компании, отчитываться перед ним в новом формате – согласно спецификации XBRL (а не excel или xml).
В объем надзорной (статистической) отчетности входит информация об учредителях и клиентах, объектах страхования, премиях и выплатах, депозитах и инвестициях, о контрагентах и т.д. и т.п. — реально сотни тысяч фактов. В связи с этим, для облегчения бюрократизма и соблюдения точности процедуры, расскажем о проекте автоматизации формирования отчетности в XBRL одной крупной НФО, в основу которого легло решение Fujitsu XBRL.

Помимо регулятора в формат XBRL перевели бухгалтерскую отчётность, как имеющую потенциально больше получателей, также налоговая, биржа и тендерные площадки. Следует помнить, что конечная цель Центробанка – перевести на XBRL и банки, чтобы иметь возможность проводить мониторинг максимально оперативно и глубоко.
XBRL — eXtensible Business Reporting Language, или «расширяемый язык деловой отчётности», – создан для моделирования форм отчётности и как формат для передачи регулятору показателей подотчётными компаниями.
Традиционно формы отчётности создавались одними людьми (методологами регулятора – Центробанка), заполнялись другими людьми (бухгалтерами подотчётных организаций) и проверялись третьими людьми (рядовыми специалистами ЦБ).
Объем отчетности увеличивается: количество показателей уже выросло до тысяч, вместе с этим подавать ее стали чаще. Например, банки отчитываются перед регулятором ежедневно. В таких условиях заполнять и обрабатывать отчетность вручную становится все затратнее, так что целесообразно в этих условиях использовать автоматизацию.
Интерфейс «человек – человек» заменяется интерфейсом «машина – машина», где нужна математически точная спецификация формата передаваемых данных, которым и стал XBRL.
Первая спецификация XBRL была создана около 20 лет назад американской ассоциацией сертифицированных бухгалтеров. Формат такой же расширяемый (eXtensible), как и лежащий в его основе XML; но если расширения XML –это различные языки разметки, то расширения XBRL –это модели различных предметных областей («доменов»). Например, модель Бухгалтерской Финансовой Отчётности / по МСФО или модель налоговых форм.
В основе языка XBRL, как и любого языка, лежит словарь (dictionary), т.е. перечень слов («концептов»), записанных латиницей и имеющих свои атрибуты (тип данных, принадлежность к категориям «на дату» / «за период» и дебит/кредит, флаг «абстрактности»).
Далее с помощью словаря предметной области моделируются все формы, составляющие отчётность.
Модель на языке XBRL –это в простейшем случае последовательность концептов языка, т.е. заданный порядок их следования. Сначала – активы, потом обязательства и капитал; сначала наличность, потом депозиты. Только так. Без пропусков и без лишних строк.
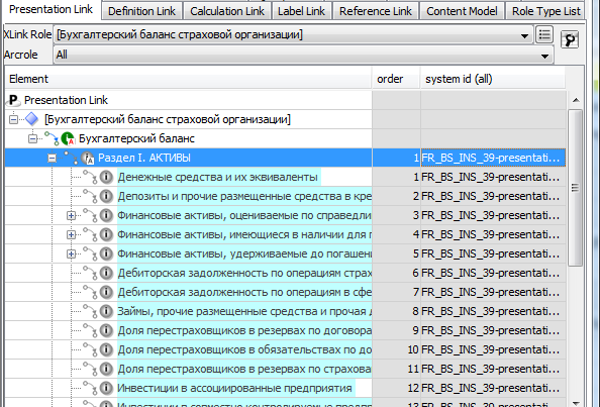
Типичная модель формы – это заданная в определённом порядке комбинация элементов и аналитических разрезов по геометрическим осям (X, Y и даже Z).
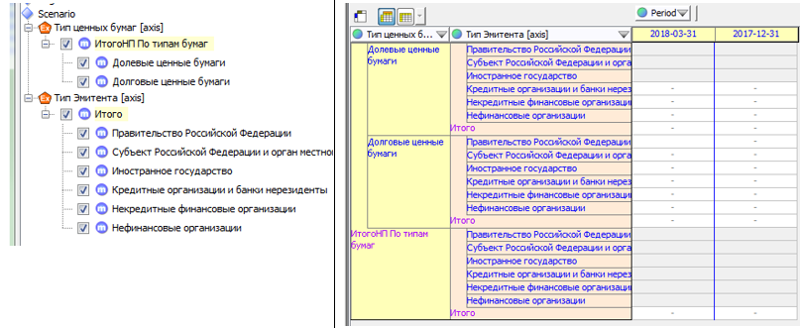
«Суперпозиция» аналитических разрезов и отчётных периодов «разложена» по осям X и Y.
До появления XBRL показатели в формах не были поименованы, и при добавлении нового показателя становилось сложно сравнить форму за старый период и новый.
Таким же образом «разъезжались» внутри и межформенные контроли, завязанные только на номера строк и столбцов. С новыми правками сложность увеличивается нелинейно. В XBRL же формулы в контролях состоят из поименованных переменных, поэтому контрольные соотношение вообще не нужно менять при изменении макетов форм.
Обычный подход вендора (чаще всего это 1С франчайзи, т.е. компании-партнеры 1С) к добавлению экспорта в XBRL заключается в том, чтобы промаркировать строки/столбцы в макетах отчётов и при экспорте выдавать последовательность значений концептов – «фактов». Результирующий инстанс (instance – «экземпляр/ отчет XBRL») затем валидируется на соответствие XML, XBRL (плюс на его фактах проверяются контрольные соотношения) с использованием свободного или коммерческого ПО (например, Arelle или Altova).
Сложность для такого вендора заключается в том, что при создании XBRL документа (как текстового файла) следует соблюсти все правила синтаксиса XBRL: отсутствие дубликатов фактов и «контекстов» и самое главное – соответствие таксономии. Факты в созданном отчете должны соответствовать таксономии по имени и типу, таблицы – по наличию обязательных аналитических разрезов. Усугубляют картину изменения в самой таксономии, которые обязательно нужно поддерживать наряду с прошлыми версиями (ЦБ может в любой момент попросить пересдать отчётность за прошлый период).
И если российские компании столкнулись с необходимостью поддержки XBRL в 2017 году, то Fujitsu имеет гораздо более долгую историю компетенций в XBRL. Она уходит корнями в 2006 год, когда все компании, входящие в листинг Токийской фондовой биржи (Tokyo Stock Exchange) обязали раскрывать свои ключевые показатели в XBRL.
Fujitsu имеет свой собственный, сертифицированный XBRL-процессор, используемый регуляторами многих европейских стран, который позволяет загружать таксономию в память и создавать отчёт XBRL не как текстовый файл, а как своеобразную объектную модель документа (DOM).
На основе этого процессора создан инструментарий, который могут использовать как подотчётные компании, так и регуляторы. ЦБ РФ также выбрал его для создания российской таксономии.
Если же речь идёт о более глубокой интеграции с учётными системами (автоматической конвертации отчётности в XBRL), то и здесь мы также используем более гибкий и мощный, 3-звенный подход.
От разработчиков учётной системы не требуется размечать каждый отчёт и поддерживать такую разметку. Обычно любой отчёт можно сохранить как Excel-файл, а для нас требуется сохранить его как простой вектор «ячеек» (row-col-value). Для примера иллюстрация ниже.
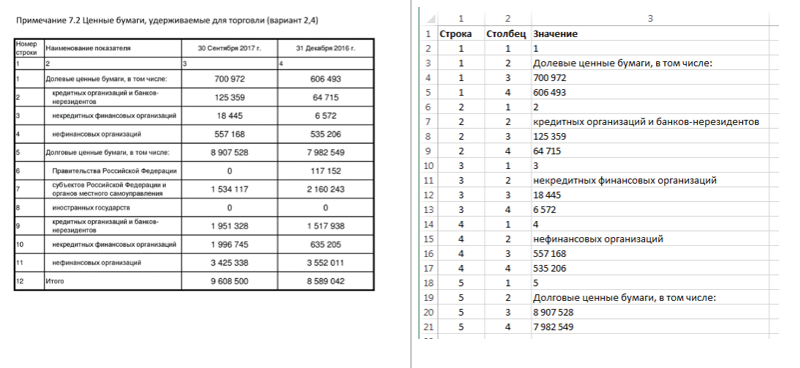
Таблица из 4 столбцов и 12 строк превращается в 48 ячеек. Такой нереляционный формат представления обеспечивает максимальную гибкость. Для каждого макета можно дополнительно ограничить область выгрузки, чтобы не включать заголовки строк и столбцов таблицы, шапку и подвал отчёта, что дополнительно ускоряет передачу данных в интеграционном решении.
Второе звено нашей архитектуры – это разметка актуальных форм заказчика. Ввиду того, что есть много разных учётных систем (стандартных конфигураций и собственных разработок 1С, «не-1С» типа SAP и Oracle), отчётные макеты различаются и координаты также будут отличаться. В общем-то, у каждого заказчика свои макеты (пример ниже).
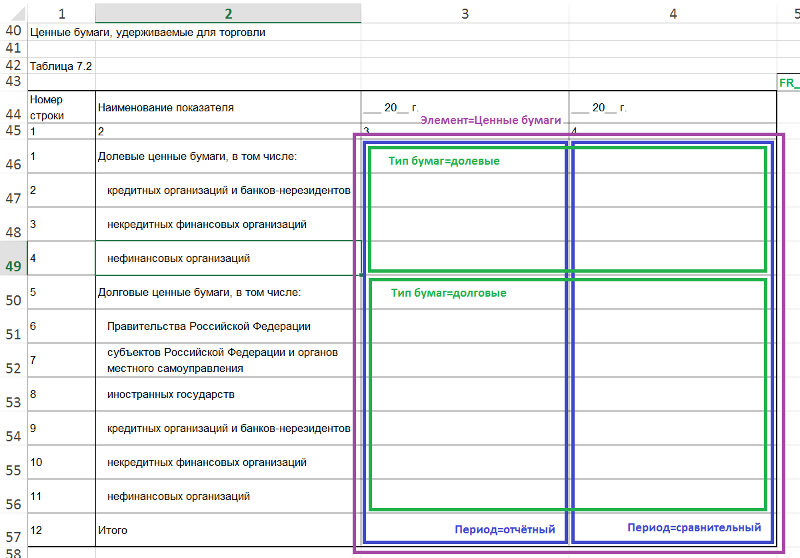
Цветом выделены области макета, соответствующие разным элементам таксономии. Такая разметка формализуется элементарным образом – сначала на птичьем языке, а потом в концептах таксономии:
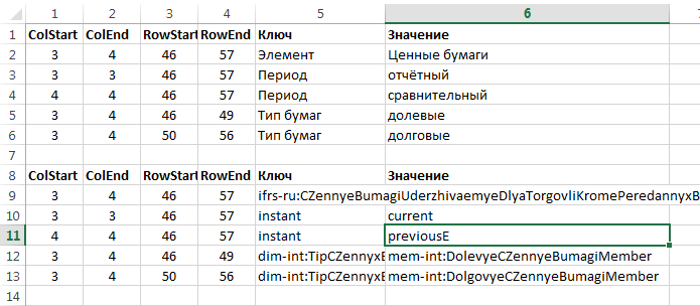
Причём если от заказчика к заказчику могут меняться координаты областей (первые 4 столбца), то элементы таксономии остаются общими для всех. Поэтому второе звено также весьма легкое и гибкое.
При этом если происходят изменения в макетах или таксономии, мы подгружаем маппинги как часть конфигурации (есть версионность), без изменения кода, и даже без перезапуска решения.
Такой механизм позволяет размечать даже те формы, которые нельзя смоделировать с помощью Table LinkBase –наиболее продвинутого расширения стандарта XBRL.
Пересечение фактов и маппингов используется третьим звеном. C помощью XBRL-процессора, который держит в памяти таксономию, мы создаём модель документа отчёта; а обо всех ошибках в процессе пишем в лог и предупреждаем пользователя.
Если это ошибки в данных (несовпадение типов или форматов, например) – разбирается бухгалтер; если ошибки в маппингах – разбирается аналитик. Таким образом, валидация происходит на самом раннем этапе и на уровне отдельных форм (а не только отчётности целиком). Разумеется, отчёт из памяти в любой момент может быть сохранён на диск.
Для пользователей процесс выглядит максимально просто. После закрытия периода в учётной системе бухгалтер формирует отчёт. В один клик он передаёт его в XBRL, также как может передать на печать. После этого в web-интерфейсе бухгалтер видит html-рендер того же отчёта (основанный на слое TableLinkbase таксономии, чтобы убедиться, что данные «легли») и видит, есть ли ошибки и если есть, то какие.
Весь объём отчетности (N таблиц) может быть разделён руководителем между несколькими ответственными бухгалтерами и специалистами. Если какие-то формы отсутствуют в учётной системе, ответственные могут загрузить их из Excel, которые «разрезаются» специальным программным инструментом на вектор фактов аналогично иллюстрации №3. Когда все таблицы «готовы» без критичных ошибок, руководитель скачивает финальный отчёт и загружает его в личный кабинет на сайте ЦБ.
Вот такое вот получилось глубоко интегрированное решение. Не требует дополнительных этапов конвертации и покрывает весь объем отчётности.
Многие вендоры были вынуждены в кратчайшие сроки включать поддержку XBRL в своих решениях, так что приглашаю аналитиков и программистов обсудить здесь наболевшие вопросы.
В объем надзорной (статистической) отчетности входит информация об учредителях и клиентах, объектах страхования, премиях и выплатах, депозитах и инвестициях, о контрагентах и т.д. и т.п. — реально сотни тысяч фактов. В связи с этим, для облегчения бюрократизма и соблюдения точности процедуры, расскажем о проекте автоматизации формирования отчетности в XBRL одной крупной НФО, в основу которого легло решение Fujitsu XBRL.
Помимо регулятора в формат XBRL перевели бухгалтерскую отчётность, как имеющую потенциально больше получателей, также налоговая, биржа и тендерные площадки. Следует помнить, что конечная цель Центробанка – перевести на XBRL и банки, чтобы иметь возможность проводить мониторинг максимально оперативно и глубоко.
Краткое введение в XBRL
XBRL — eXtensible Business Reporting Language, или «расширяемый язык деловой отчётности», – создан для моделирования форм отчётности и как формат для передачи регулятору показателей подотчётными компаниями.
Традиционно формы отчётности создавались одними людьми (методологами регулятора – Центробанка), заполнялись другими людьми (бухгалтерами подотчётных организаций) и проверялись третьими людьми (рядовыми специалистами ЦБ).
Объем отчетности увеличивается: количество показателей уже выросло до тысяч, вместе с этим подавать ее стали чаще. Например, банки отчитываются перед регулятором ежедневно. В таких условиях заполнять и обрабатывать отчетность вручную становится все затратнее, так что целесообразно в этих условиях использовать автоматизацию.
Интерфейс «человек – человек» заменяется интерфейсом «машина – машина», где нужна математически точная спецификация формата передаваемых данных, которым и стал XBRL.
Первая спецификация XBRL была создана около 20 лет назад американской ассоциацией сертифицированных бухгалтеров. Формат такой же расширяемый (eXtensible), как и лежащий в его основе XML; но если расширения XML –это различные языки разметки, то расширения XBRL –это модели различных предметных областей («доменов»). Например, модель Бухгалтерской Финансовой Отчётности / по МСФО или модель налоговых форм.
В основе языка XBRL, как и любого языка, лежит словарь (dictionary), т.е. перечень слов («концептов»), записанных латиницей и имеющих свои атрибуты (тип данных, принадлежность к категориям «на дату» / «за период» и дебит/кредит, флаг «абстрактности»).
Далее с помощью словаря предметной области моделируются все формы, составляющие отчётность.
Модель на языке XBRL –это в простейшем случае последовательность концептов языка, т.е. заданный порядок их следования. Сначала – активы, потом обязательства и капитал; сначала наличность, потом депозиты. Только так. Без пропусков и без лишних строк.
Типичная модель формы – это заданная в определённом порядке комбинация элементов и аналитических разрезов по геометрическим осям (X, Y и даже Z).
«Суперпозиция» аналитических разрезов и отчётных периодов «разложена» по осям X и Y.
До появления XBRL показатели в формах не были поименованы, и при добавлении нового показателя становилось сложно сравнить форму за старый период и новый.
Таким же образом «разъезжались» внутри и межформенные контроли, завязанные только на номера строк и столбцов. С новыми правками сложность увеличивается нелинейно. В XBRL же формулы в контролях состоят из поименованных переменных, поэтому контрольные соотношение вообще не нужно менять при изменении макетов форм.
Решение Fujitsu XBRL
Обычный подход вендора (чаще всего это 1С франчайзи, т.е. компании-партнеры 1С) к добавлению экспорта в XBRL заключается в том, чтобы промаркировать строки/столбцы в макетах отчётов и при экспорте выдавать последовательность значений концептов – «фактов». Результирующий инстанс (instance – «экземпляр/ отчет XBRL») затем валидируется на соответствие XML, XBRL (плюс на его фактах проверяются контрольные соотношения) с использованием свободного или коммерческого ПО (например, Arelle или Altova).
Сложность для такого вендора заключается в том, что при создании XBRL документа (как текстового файла) следует соблюсти все правила синтаксиса XBRL: отсутствие дубликатов фактов и «контекстов» и самое главное – соответствие таксономии. Факты в созданном отчете должны соответствовать таксономии по имени и типу, таблицы – по наличию обязательных аналитических разрезов. Усугубляют картину изменения в самой таксономии, которые обязательно нужно поддерживать наряду с прошлыми версиями (ЦБ может в любой момент попросить пересдать отчётность за прошлый период).
И если российские компании столкнулись с необходимостью поддержки XBRL в 2017 году, то Fujitsu имеет гораздо более долгую историю компетенций в XBRL. Она уходит корнями в 2006 год, когда все компании, входящие в листинг Токийской фондовой биржи (Tokyo Stock Exchange) обязали раскрывать свои ключевые показатели в XBRL.
Fujitsu имеет свой собственный, сертифицированный XBRL-процессор, используемый регуляторами многих европейских стран, который позволяет загружать таксономию в память и создавать отчёт XBRL не как текстовый файл, а как своеобразную объектную модель документа (DOM).
На основе этого процессора создан инструментарий, который могут использовать как подотчётные компании, так и регуляторы. ЦБ РФ также выбрал его для создания российской таксономии.
Если же речь идёт о более глубокой интеграции с учётными системами (автоматической конвертации отчётности в XBRL), то и здесь мы также используем более гибкий и мощный, 3-звенный подход.
От разработчиков учётной системы не требуется размечать каждый отчёт и поддерживать такую разметку. Обычно любой отчёт можно сохранить как Excel-файл, а для нас требуется сохранить его как простой вектор «ячеек» (row-col-value). Для примера иллюстрация ниже.
Таблица из 4 столбцов и 12 строк превращается в 48 ячеек. Такой нереляционный формат представления обеспечивает максимальную гибкость. Для каждого макета можно дополнительно ограничить область выгрузки, чтобы не включать заголовки строк и столбцов таблицы, шапку и подвал отчёта, что дополнительно ускоряет передачу данных в интеграционном решении.
Второе звено нашей архитектуры – это разметка актуальных форм заказчика. Ввиду того, что есть много разных учётных систем (стандартных конфигураций и собственных разработок 1С, «не-1С» типа SAP и Oracle), отчётные макеты различаются и координаты также будут отличаться. В общем-то, у каждого заказчика свои макеты (пример ниже).
Цветом выделены области макета, соответствующие разным элементам таксономии. Такая разметка формализуется элементарным образом – сначала на птичьем языке, а потом в концептах таксономии:
Причём если от заказчика к заказчику могут меняться координаты областей (первые 4 столбца), то элементы таксономии остаются общими для всех. Поэтому второе звено также весьма легкое и гибкое.
При этом если происходят изменения в макетах или таксономии, мы подгружаем маппинги как часть конфигурации (есть версионность), без изменения кода, и даже без перезапуска решения.
Выбор такой схемы интеграции был навеян механизмом «RC-coding», применяемым в некоторых европейских таксономиях. Наряду с «человеческими» концептами каждая строка и каждый столбец отчёта помечены ещё и числовыми кодами, т.е. все диапазоны уже пронумерованы создателями таксономии. В таксономии ЦБ РФ этот слой также присутствует, но ещё не на всех таблицах.
Такой механизм позволяет размечать даже те формы, которые нельзя смоделировать с помощью Table LinkBase –наиболее продвинутого расширения стандарта XBRL.
Пересечение фактов и маппингов используется третьим звеном. C помощью XBRL-процессора, который держит в памяти таксономию, мы создаём модель документа отчёта; а обо всех ошибках в процессе пишем в лог и предупреждаем пользователя.
Если это ошибки в данных (несовпадение типов или форматов, например) – разбирается бухгалтер; если ошибки в маппингах – разбирается аналитик. Таким образом, валидация происходит на самом раннем этапе и на уровне отдельных форм (а не только отчётности целиком). Разумеется, отчёт из памяти в любой момент может быть сохранён на диск.
Ядро XBRL-процессора написано на Java, на Java же пишем и мы. А вообще-то все методы ядра доступны через API и для .NET.
Прочие технологии достаточно стандартны: пользовательский интерфейс на React JS; поэтому бухгалтеры могут работать с системой просто через браузер (что актуально в крупных компаниях, где строгие правила безопасности к установкам ПО).
При этом есть и интеграция с Active Directory. Фронт и бэк связаны через REST API; он же используется для интеграции с учётными системами. Методы автоматически документируются с использованием Swagger.
Для пользователей процесс выглядит максимально просто. После закрытия периода в учётной системе бухгалтер формирует отчёт. В один клик он передаёт его в XBRL, также как может передать на печать. После этого в web-интерфейсе бухгалтер видит html-рендер того же отчёта (основанный на слое TableLinkbase таксономии, чтобы убедиться, что данные «легли») и видит, есть ли ошибки и если есть, то какие.
Весь объём отчетности (N таблиц) может быть разделён руководителем между несколькими ответственными бухгалтерами и специалистами. Если какие-то формы отсутствуют в учётной системе, ответственные могут загрузить их из Excel, которые «разрезаются» специальным программным инструментом на вектор фактов аналогично иллюстрации №3. Когда все таблицы «готовы» без критичных ошибок, руководитель скачивает финальный отчёт и загружает его в личный кабинет на сайте ЦБ.
В заключении
Вот такое вот получилось глубоко интегрированное решение. Не требует дополнительных этапов конвертации и покрывает весь объем отчётности.
Многие вендоры были вынуждены в кратчайшие сроки включать поддержку XBRL в своих решениях, так что приглашаю аналитиков и программистов обсудить здесь наболевшие вопросы.

